QWERTY: Training-Free Motion Control via Query-Warped Video Diffusion Transformers
Pith reviewed 2026-07-03 16:17 UTC · model grok-4.3
The pith
Warping the queries in video diffusion transformers enables training-free motion control comparable to fine-tuned models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
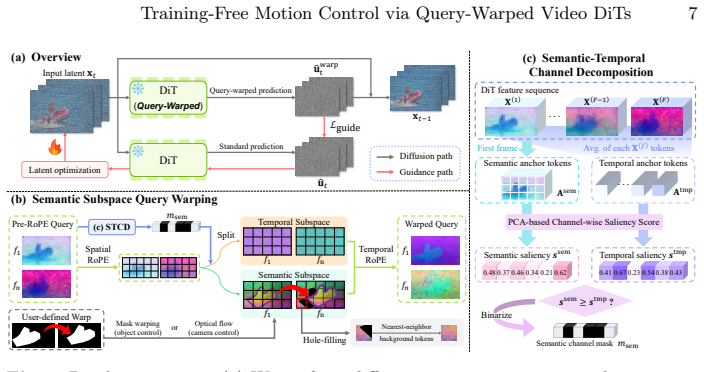
By warping the frame-invariant semantic subspace of queries in the 3D full attention of image-to-video DiTs, the noise predicted by the model naturally guides the diffusion trajectory toward the user-specified motion; leveraging this noise as self-guidance for latent optimization improves control stability and visual quality.
What carries the argument
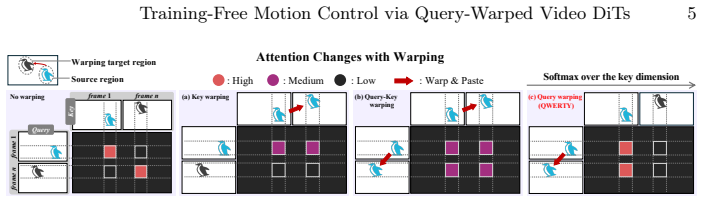
Query warping applied to the frame-invariant semantic subspace inside the 3D full attention, which incorporates user-specified object warping and optical flow to redirect the model's noise prediction.
If this is right
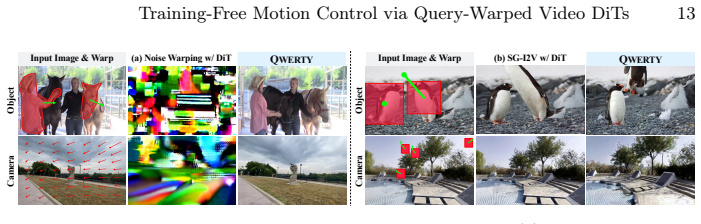
- QWERTY achieves the most effective motion control among existing training-free approaches on a recent image-to-video DiT.
- Performance reaches levels comparable to fine-tuning-based methods.
- Using the predicted noise as self-guidance for latent optimization improves both control stability and visual quality.
- The framework supports flexible motion control through arbitrary user-defined object warping and optical flow.
Where Pith is reading between the lines
- The query-warping technique might transfer to other transformer-based diffusion models for controlling attributes beyond motion.
- If the warping step can be made faster, the method could support interactive video editing sessions.
- Testing the approach on videos with multiple interacting objects would reveal whether the single-object warping assumption holds in more complex scenes.
Load-bearing premise
That warping the queries will make the predicted noise steer generation to the desired motion without breaking temporal coherence or overall visual quality.
What would settle it
A test video where the query-warped model produces motion that deviates from the supplied optical flow or object trajectories, or where visual quality drops below the unwarped baseline.
Figures




read the original abstract
Video diffusion transformers (DiTs) generate high-fidelity and temporally coherent videos, yet motion control remains implicit, primarily relying on text prompts. As a result, achieving desired motion often requires extensive prompt engineering and repeated resampling. While fine-tuning models with additional spatial prompts (e.g., bounding boxes or point trajectories) enables explicit control, it demands substantial data curation and computation, and may compromise the generative capabilities of pretrained models. Consequently, training-free motion control using such spatial prompts has been explored in U-Net-based video diffusion models, but remains largely unexplored for DiTs. We introduce QWERTY, a training-free framework that enables flexible motion control in pretrained image-to-video DiTs via user-defined object warping and optical flow. We carefully manipulate the 3D full attention of DiTs by warping the frame-invariant semantic subspace of queries. We find that the noise predicted by the query-warped DiT naturally guides the diffusion trajectory toward the desired motion, and further show that leveraging this noise as self-guidance for latent optimization improves control stability and visual quality. Experiments show that QWERTY achieves the most effective motion control among existing training-free approaches on a recent image-to-video DiT, with performance comparable to fine-tuning-based methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces QWERTY, a training-free framework for explicit motion control in pretrained image-to-video Diffusion Transformers (DiTs). It manipulates the 3D full attention by warping the frame-invariant semantic subspace of queries according to user-specified object warping and optical flow. The central claim is that the resulting noise prediction naturally steers the diffusion trajectory toward the desired motion without additional training; the authors further propose using this noise as self-guidance for latent optimization to improve stability and quality. Experiments are reported to show that QWERTY outperforms existing training-free baselines on a recent image-to-video DiT while achieving performance comparable to fine-tuning-based methods.
Significance. If the empirical results hold under rigorous controls, the work would be significant for demonstrating an architecture-specific, training-free control mechanism that extends prior U-Net work to DiTs. It directly addresses the practical limitation of implicit motion control in high-fidelity video generators by leveraging the query subspace of 3D attention, potentially lowering the barrier to precise spatial control while preserving pretrained generative capabilities.
major comments (2)
- [Abstract, §3] Abstract and §3 (method description): the claim that 'the noise predicted by the query-warped DiT naturally guides the diffusion trajectory' is presented as an empirical finding rather than a derived property. Without an explicit derivation or ablation isolating the contribution of query warping from other factors (e.g., the optical-flow input or the self-guidance step), it is difficult to assess whether the observed steering is a general consequence of the manipulation or specific to the chosen DiT and prompts.
- [Experiments] Experiments section (implied by abstract claims): the assertion of 'most effective motion control among existing training-free approaches' and 'performance comparable to fine-tuning-based methods' requires the full set of baselines, metrics, and statistical controls to be inspectable. If the evaluation uses post-hoc selection of prompts or omits variance across random seeds, the comparative claim would be weakened.
minor comments (2)
- [§3] Notation for the warped query subspace and the precise definition of 'frame-invariant semantic subspace' should be formalized with an equation to avoid ambiguity when reproducing the attention modification.
- [Abstract] The abstract would benefit from one or two concrete quantitative results (e.g., a specific metric improvement over the strongest baseline) to ground the superiority claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation for minor revision. We address the major comments point-by-point below.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method description): the claim that 'the noise predicted by the query-warped DiT naturally guides the diffusion trajectory' is presented as an empirical finding rather than a derived property. Without an explicit derivation or ablation isolating the contribution of query warping from other factors (e.g., the optical-flow input or the self-guidance step), it is difficult to assess whether the observed steering is a general consequence of the manipulation or specific to the chosen DiT and prompts.
Authors: We acknowledge that the steering effect is presented as an empirical observation ('We find that...') rather than a formal derivation. A complete theoretical derivation of how query warping in 3D attention alters the noise prediction would require extensive analysis of DiT attention dynamics, which lies beyond the paper's scope. To strengthen the claim, the revised manuscript will include new ablations that isolate query warping (comparing warped vs. non-warped queries while holding optical flow and self-guidance constant) across multiple DiT variants and prompt sets. These will clarify the contribution of the manipulation. revision: partial
-
Referee: [Experiments] Experiments section (implied by abstract claims): the assertion of 'most effective motion control among existing training-free approaches' and 'performance comparable to fine-tuning-based methods' requires the full set of baselines, metrics, and statistical controls to be inspectable. If the evaluation uses post-hoc selection of prompts or omits variance across random seeds, the comparative claim would be weakened.
Authors: The experiments section already includes all listed training-free and fine-tuning baselines evaluated with standard motion accuracy and perceptual quality metrics on a fixed prompt set (no post-hoc selection). Results are averaged over multiple random seeds with standard deviations reported. In the revision we will add an explicit supplementary table listing every baseline implementation detail, all metric definitions, the complete prompt list, and p-values from statistical significance tests to make the controls fully inspectable. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces QWERTY as a direct manipulation of 3D full attention queries in pretrained DiTs, with the claim that query warping causes predicted noise to steer diffusion trajectories presented as an empirical observation ('We find that...') rather than a derived result. No equations, fitted parameters, or self-citations appear in the provided text that would reduce any 'prediction' or central mechanism to the inputs by construction. Experiments are described as external validation against baselines, with no load-bearing step that collapses to tautology or renaming. This is the common case of a self-contained empirical method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:1412.69801412(6) (2014)
Adam, K.D.B.J., et al.: A method for stochastic optimization. arXiv preprint arXiv:1412.69801412(6) (2014)
-
[2]
arXiv preprint arXiv:2412.07750 (2024)
Atzmon, Y., Gal, R., Tewel, Y., Kasten, Y., Chechik, G.: Motion by queries: Identity-motion trade-offs in text-to-video generation. arXiv preprint arXiv:2412.07750 (2024)
-
[3]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Bai, J., He, T., Wang, Y., Guo, J., Hu, H., Liu, Z., Bian, J.: Uniedit: A unified tuning-free framework for video motion and appearance editing. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 10171–10180 (2025)
2025
-
[4]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Bochkovskii, A., Delaunoy, A., Germain, H., Santos, M., Zhou, Y., Richter, S.R., Koltun, V.: Depth pro: Sharp monocular metric depth in less than a second. arXiv preprint arXiv:2410.02073 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Burgert, R., Xu, Y., Xian, W., Pilarski, O., Clausen, P., He, M., Ma, L., Deng, Y., Li, L., Mousavi, M., et al.: Go-with-the-flow: Motion-controllable video diffusion models using real-time warped noise. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 13–23 (2025)
2025
-
[7]
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Chen, H., Xia, M., He, Y., Zhang, Y., Cun, X., Yang, S., Xing, J., Liu, Y., Chen, Q., Wang, X., et al.: Videocrafter1: Open diffusion models for high-quality video generation. arXiv preprint arXiv:2310.19512 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
arXiv preprint arXiv:2311.12886 (2023)
Dai, Z., Zhang, Z., Yao, Y., Qiu, B., Zhu, S., Qin, L., Wang, W.: Animateanything: Fine-grained open domain image animation with motion guidance. arXiv preprint arXiv:2311.12886 (2023)
-
[9]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Geng, D., Herrmann, C., Hur, J., Cole, F., Zhang, S., Pfaff, T., Lopez-Guevara, T., Aytar, Y., Rubinstein, M., Sun, C., et al.: Motion prompting: Controlling video generation with motion trajectories. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 1–12 (2025)
2025
-
[10]
arXiv preprint arXiv:2505.13344 (2025)
Gokmen, A.B., Ekin, Y., Bilecen, B.B., Dundar, A.: Ropecraft: Training-free mo- tion transfer with trajectory-guided rope optimization on diffusion transformers. arXiv preprint arXiv:2505.13344 (2025)
-
[11]
Google DeepMind: Veo 3: A generative video model by google deepmind.https: //aistudio.google.com/models/veo-3(2024), accessed: 2025-11-13
2024
-
[12]
In: The Twelfth International Conference on Learning Representations (2024)
Guo, Y., Yang, C., Rao, A., Liang, Z., Wang, Y., Qiao, Y., Agrawala, M., Lin, D., Dai, B.: Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. In: The Twelfth International Conference on Learning Representations (2024)
2024
-
[13]
In: The Thirteenth International Conference on Learning Representations (2025)
He, H., Xu, Y., Guo, Y., Wetzstein, G., Dai, B., Li, H., Yang, C.: Cameractrl: En- abling camera control for video diffusion models. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[14]
Advances in neural information processing systems30(2017)
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017)
2017
- [15]
-
[16]
Training-Free Motion Control via Query-Warped Video DiTs 17 In: Proceedings of the Computer Vision and Pattern Recognition Conference
Huang, Y., Chen, Y., Ding, L., Zhang, X., Dai, W., Zou, J., Xiong, H., Tian, Q.: Im-zero: Instance-level motion controllable video generation in a zero-shot manner. Training-Free Motion Control via Query-Warped Video DiTs 17 In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 7265–7275 (2025)
2025
-
[17]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., Wang, Y., Chen, X., Wang, L., Lin, D., Qiao, Y., Liu, Z.: VBench: Comprehensive benchmark suite for video generative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jain, Y., Nasery, A., Vineet, V., Behl, H.: Peekaboo: Interactive video generation via masked-diffusion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8079–8088 (2024)
2024
-
[19]
In: European conference on computer vision
Karaev, N., Rocco, I., Graham, B., Neverova, N., Vedaldi, A., Rupprecht, C.: Cotracker: It is better to track together. In: European conference on computer vision. pp. 18–35. Springer (2024)
2024
-
[20]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
arXiv preprint arXiv:2503.16421 (2025)
Li, Q., Xing, Z., Wang, R., Zhang, H., Dai, Q., Wu, Z.: Magicmotion: Control- lable video generation with dense-to-sparse trajectory guidance. arXiv preprint arXiv:2503.16421 (2025)
-
[22]
arXiv preprint arXiv:2507.02857 (2025)
Li, Z., Luo, H., Shuai, X., Ding, H.: Anyi2v: Animating any conditional image with motion control. arXiv preprint arXiv:2507.02857 (2025)
-
[23]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ling, L., Sheng, Y., Tu, Z., Zhao, W., Xin, C., Wan, K., Yu, L., Guo, Q., Yu, Z., Lu, Y., et al.: Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22160–22169 (2024)
2024
-
[25]
In: The Thirteenth International Conference on Learning Representations
Ling, P., Bu, J., Zhang, P., Dong, X., Zang, Y., Wu, T., Chen, H., Wang, J., Jin, Y.: Motionclone: Training-free motion cloning for controllable video generation. In: The Thirteenth International Conference on Learning Representations
-
[26]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Latte: Latent Diffusion Transformer for Video Generation
Ma, X., Wang, Y., Jia, G., Chen, X., Liu, Z., Li, Y.F., Chen, C., Qiao, Y.: Latte: Latent diffusion transformer for video generation. arXiv preprint arXiv:2401.03048 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Miao, J., Wang, X., Wu, Y., Li, W., Zhang, X., Wei, Y., Yang, Y.: Large-scale video panoptic segmentation in the wild: A benchmark. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21033– 21043 (2022)
2022
-
[29]
arXiv preprint arXiv:2506.17220 (2025)
Nam, J., Son, S., Chung, D., Kim, J., Jin, S., Hur, J., Kim, S.: Emer- gent temporal correspondences from video diffusion transformers. arXiv preprint arXiv:2506.17220 (2025)
-
[30]
arXiv preprint arXiv:2411.04989 (2024)
Namekata, K., Bahmani, S., Wu, Z., Kant, Y., Gilitschenski, I., Lindell, D.B.: Sg-i2v: Self-guided trajectory control in image-to-video generation. arXiv preprint arXiv:2411.04989 (2024)
-
[31]
In: European Conference on Computer Vision
Niu, M., Cun, X., Wang, X., Zhang, Y., Shan, Y., Zheng, Y.: Mofa-video: Control- lable image animation via generative motion field adaptions in frozen image-to- video diffusion model. In: European Conference on Computer Vision. pp. 111–128. Springer (2024) 18 K. Choo et al
2024
-
[32]
com/index/video-generation-models-as-world-simulators/(2024), accessed: 2025-11-13
OpenAI: Sora: Video generation models as world simulators.https://openai. com/index/video-generation-models-as-world-simulators/(2024), accessed: 2025-11-13
2024
-
[33]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Park, G.Y., Jeong, H., Lee, S.W., Ye, J.C.: Spectral motion alignment for video motion transfer using diffusion models. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 6398–6405 (2025)
2025
-
[34]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[35]
Pondaven, A., Siarohin, A., Tulyakov, S., Torr, P., Pizzati, F.: Video motion trans- ferwithdiffusiontransformers.In:ProceedingsoftheComputerVisionandPattern Recognition Conference. pp. 22911–22921 (2025)
2025
-
[36]
Qiu, H., Chen, Z., Wang, Z., He, Y., Xia, M., Liu, Z.: Freetraj: Tuning-free trajec- tory control in video diffusion models. arXiv preprint arXiv:2406.16863 (2024)
-
[37]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchical text- conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 1(2), 3 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[39]
Advances in neural information processing systems35, 36479–36494 (2022)
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text- to-image diffusion models with deep language understanding. Advances in neural information processing systems35, 36479–36494 (2022)
2022
-
[40]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Shi, Q., Wu, J., Bai, J., Zhang, J., Qi, L., Tong, Y., Li, X.: Decouple and track: Benchmarking and improving video diffusion transformers for motion transfer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10995–11005 (2025)
2025
-
[41]
In: ACM SIGGRAPH 2024 Conference Papers
Shi, X., Huang, Z., Wang, F.Y., Bian, W., Li, D., Zhang, Y., Zhang, M., Che- ung, K.C., See, S., Qin, H., et al.: Motion-i2v: Consistent and controllable image- to-video generation with explicit motion modeling. In: ACM SIGGRAPH 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[42]
Shi, Y., Xue, C., Liew, J.H., Pan, J., Yan, H., Zhang, W., Tan, V.Y., Bai, S.: Dragdiffusion: Harnessing diffusion models for interactive point-based image edit- ing.In:ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPattern Recognition. pp. 8839–8849 (2024)
2024
-
[43]
Neurocomputing568, 127063 (2024)
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y.: Roformer: Enhanced trans- former with rotary position embedding. Neurocomputing568, 127063 (2024)
2024
-
[44]
Advances in Neural Information Processing Systems 36, 1363–1389 (2023)
Tang, L., Jia, M., Wang, Q., Phoo, C.P., Hariharan, B.: Emergent correspon- dence from image diffusion. Advances in Neural Information Processing Systems 36, 1363–1389 (2023)
2023
-
[45]
In: European conference on computer vision
Teed, Z., Deng, J.: Raft: Recurrent all-pairs field transforms for optical flow. In: European conference on computer vision. pp. 402–419. Springer (2020)
2020
-
[46]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Unterthiner, T., Van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[47]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5294–5306 (2025) Training-Free Motion Control via Query-Warped Video DiTs 19
2025
-
[49]
arXiv preprint arXiv:2412.07721 (2024)
Wang, Z., Lan, Y., Zhou, S., Loy, C.C.: Objctrl-2.5 d: Training-free object control with camera poses. arXiv preprint arXiv:2412.07721 (2024)
-
[50]
In: ACM SIGGRAPH 2024 Conference Papers
Wang, Z., Yuan, Z., Wang, X., Li, Y., Chen, T., Xia, M., Luo, P., Shan, Y.: Mo- tionctrl: A unified and flexible motion controller for video generation. In: ACM SIGGRAPH 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[51]
In: European Conference on Computer Vision
Wu, W., Li, Z., Gu, Y., Zhao, R., He, Y., Zhang, D.J., Shou, M.Z., Li, Y., Gao, T., Zhang, D.: Draganything: Motion control for anything using entity representation. In: European Conference on Computer Vision. pp. 331–348. Springer (2024)
2024
-
[52]
In: The Thirteenth International Conference on Learning Representa- tions (2024)
Xiao, F., Liu, X., Wang, X., Peng, S., Xia, M., Shi, X., Yuan, Z., Wan, P., Zhang, D., Lin, D.: 3dtrajmaster: Mastering 3d trajectory for multi-entity motion in video generation. In: The Thirteenth International Conference on Learning Representa- tions (2024)
2024
-
[53]
Advances in Neural Information Processing Systems 37, 76115–76138 (2024)
Xiao, Z., Zhou, Y., Yang, S., Pan, X.: Video diffusion models are training-free mo- tion interpreter and controller. Advances in Neural Information Processing Systems 37, 76115–76138 (2024)
2024
-
[54]
In: European Conference on Computer Vision
Xing,J.,Xia,M.,Zhang,Y.,Chen,H.,Yu,W.,Liu,H.,Liu,G.,Wang,X.,Shan,Y., Wong, T.T.: Dynamicrafter: Animating open-domain images with video diffusion priors. In: European Conference on Computer Vision. pp. 399–417. Springer (2024)
2024
-
[55]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yatim, D., Fridman, R., Bar-Tal, O., Kasten, Y., Dekel, T.: Space-time diffu- sion features for zero-shot text-driven motion transfer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8466– 8476 (2024)
2024
-
[57]
arXiv preprint arXiv:2412.05355 (2024)
Yesiltepe, H., Meral, T.H.S., Dunlop, C., Yanardag, P.: Motionshop: Zero-shot motion transfer in video diffusion models with mixture of score guidance. arXiv preprint arXiv:2412.05355 (2024)
-
[58]
Yin, S., Wu, C., Liang, J., Shi, J., Li, H., Ming, G., Duan, N.: Dragnuwa: Fine- grainedcontrolinvideogenerationbyintegratingtext,image,andtrajectory.arXiv preprint arXiv:2308.08089 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Yu, S., Fang, J.Z., Zheng, J., Sigurdsson, G., Ordonez, V., Piramuthu, R., Bansal, M.: Zero-shot controllable image-to-video animation via motion decomposition. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 3332–3341 (2024)
2024
-
[60]
In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV)
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image dif- fusion models. In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 3813–3824. IEEE (2023)
2023
-
[61]
arXiv preprint arXiv:2501.07563 (2025)
Zhang, X., Duan, Z., Gong, D., Liu, L.: Training-free motion-guided video gen- eration with enhanced temporal consistency using motion consistency loss. arXiv preprint arXiv:2501.07563 (2025)
-
[62]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhang, Z., Liao, J., Li, M., Dai, Z., Qiu, B., Zhu, S., Qin, L., Wang, W.: Tora: Trajectory-oriented diffusion transformer for video generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2063–2073 (2025)
2063
-
[63]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhang, Z., Long, F., Qiu, Z., Pan, Y., Liu, W., Yao, T., Mei, T.: Motionpro: A precise motion controller for image-to-video generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 27957–27967 (2025)
2025
-
[64]
Zheng, D., Huang, Z., Liu, H., Zou, K., He, Y., Zhang, F., Zhang, Y., He, J., Zheng, W.S., Qiao, Y., Liu, Z.: VBench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness. arXiv preprint arXiv:2503.21755 (2025) Supplementary Material We recommend readers to watch the accompanying.mp4videos included in the supplementary material, as st...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
key-warping
and RoPECraft [10]. All other models are implemented using their official public repositories for a fair comparison. All experiments are conducted on a single NVIDIA RTX A6000 GPU with 48GB memory. Below, we describe the implementation details ofQwertyand the baseline methods. B.1 Our Method Qwertyis implemented on both the Wan 2.2 TI2V-5B [47] and CogVid...
-
[66]
ping- pong
The input data format was identical to that used for SG-I2V. Videos were generated at a fixed resolution of 576×1024. The number of generated frames matched the input sequence length, but sequences longer than 25 frames were truncated to 25 due to memory constraints. MotionClone.We follow the official MotionClone [25] implementation and only replace its A...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.