SAB-LVLM: Significance-Aware Binarization for Large Vision-Language Models
Pith reviewed 2026-07-03 16:11 UTC · model grok-4.3
The pith
A modality-guided significance map improves 1-bit binarization accuracy for large vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
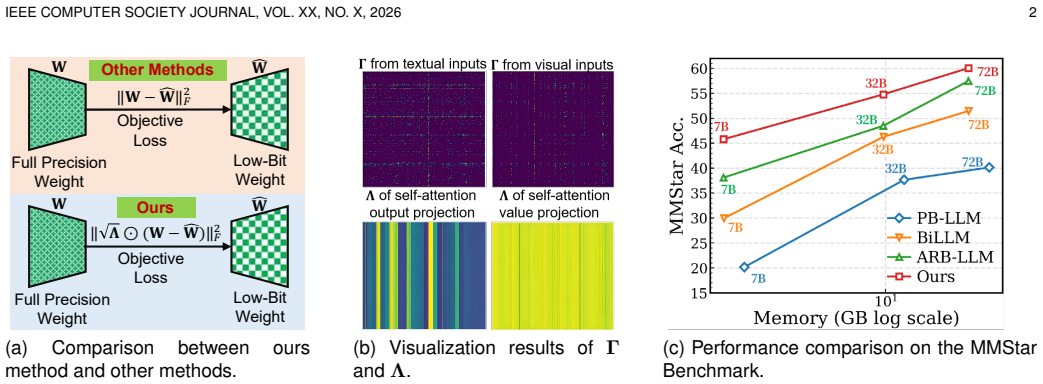
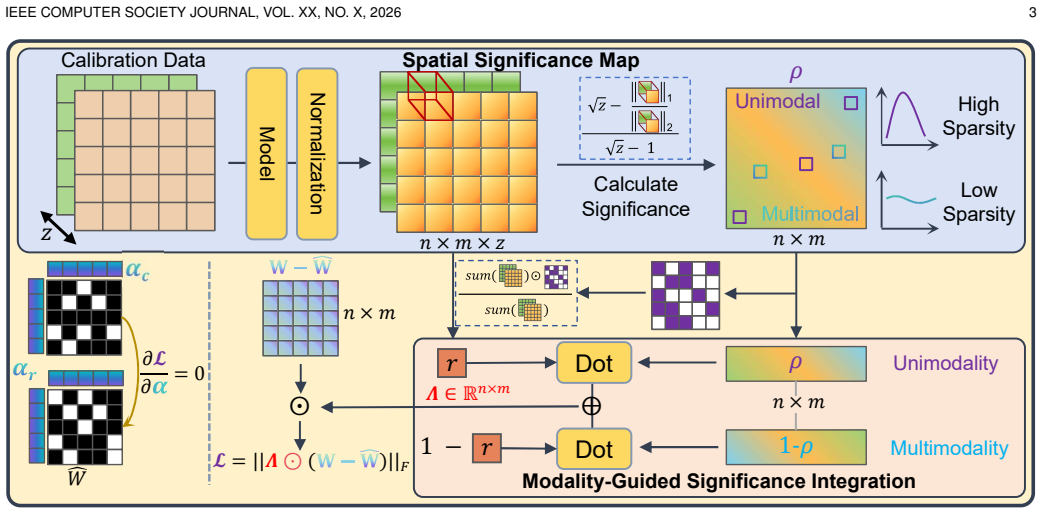
After constructing Hessian matrices separately on textual and visual inputs, a spatial significance map identifies weights activated under one modality versus across modalities; a modality-guided integration strategy then produces a significance-aware binarization map that is inserted into the binarization objective as an error reweighting term, and the map is optimized through an alternating significance-weighted update scheme, yielding higher accuracy than prior binary post-training quantization methods under an approximately 1-bit constraint.
What carries the argument
The significance-aware binarization map, formed by spatial significance mapping of Hessian-derived activations followed by modality-guided integration, which reweights the quantization error term.
If this is right
- Downstream multimodal tasks such as visual question answering retain higher accuracy after compression.
- Memory footprint and inference latency drop enough to allow deployment on edge devices.
- Weights critical to one modality are protected while less relevant parameters are more aggressively binarized.
- The alternating update scheme converges to a solution that respects both cross-modal and layer-wise importance.
Where Pith is reading between the lines
- The same Hessian-plus-significance construction could be tested on other compression targets such as 2-bit or 4-bit quantization.
- The method might expose which layers or modalities are most sensitive to binarization errors in current LVLM architectures.
- Hardware-aware extensions could map the significance values directly to bit-allocation schedules on specific accelerators.
Load-bearing premise
The integrated significance map derived from separate modality Hessians accurately ranks which weights matter most for final task performance.
What would settle it
Running the same set of LVLM benchmarks and finding that SAB-LVLM produces equal or lower accuracy than a standard binary PTQ baseline at the same 1-bit rate.
Figures

read the original abstract
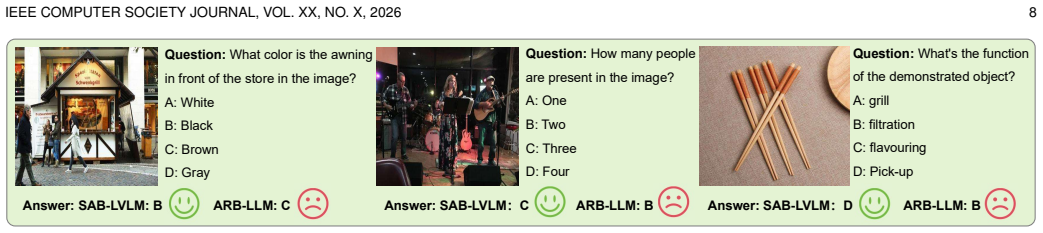
Large Vision-Language Models (LVLMs) have achieved remarkable progress in multimodal understanding, yet their enormous parameter scale and cross-modal computation incur substantial memory and latency overhead, severely limiting real-world deployment on resource-constrained devices. Binarization offers an attractive solution by drastically reducing storage and computational costs. However, existing binarization methods neglect the varying importance of weights across different layers and modalities. This causes parameters irrelevant to downstream tasks to be unnecessarily retained, whereas modality-critical weights may not be adequately optimized, resulting in significant performance degradation. To address these challenges, we develop a novel \underline{S}ignificance-\underline{A}ware \underline{B}inarization for \underline{L}arge \underline{V}ision-\underline{L}anguage \underline{M}odels (SAB-LVLM). Specifically, after constructing Hessian matrices for textual and visual inputs, we propose a spatial significance map to distinguish full-precision weights activated under a single modality from those activated across modalities. We then devise a modality-guided integration strategy to obtain the significance-aware binarization map, which measures weight significance across layers and modalities. Subsequently, this binarization map is incorporated into the binarization objective as an error reweighting term, and binarization fitting is performed through an alternating significance-weighted update scheme. Extensive experiments illustrate the superiority of our SAB-LVLM over existing binary PTQ methods under an approximately 1-bit compression constraint. Our code is accessible at https://github.com/LyuQi127/SAB_LVLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SAB-LVLM, a significance-aware binarization method for post-training quantization of large vision-language models at approximately 1-bit. After constructing separate Hessian matrices on textual and visual inputs, it introduces a spatial significance map to identify weights activated under single versus multiple modalities, followed by a modality-guided integration to produce a significance-aware binarization map. This map is used as an error reweighting term in the binarization objective, optimized via an alternating significance-weighted update scheme. The central claim is that this yields superior performance compared to existing binary PTQ methods under the 1-bit constraint.
Significance. If the empirical superiority holds, the work would address a practical bottleneck in deploying LVLMs on resource-constrained hardware by improving accuracy retention at extreme compression. The public code release at the cited GitHub repository is a positive factor for reproducibility and verification.
major comments (1)
- [Abstract] Abstract: the claim that 'Extensive experiments illustrate the superiority of our SAB-LVLM over existing binary PTQ methods' supplies no quantitative results, baseline comparisons, dataset names, metrics, or ablation studies, so it is impossible to assess whether the data support the central empirical claim.
minor comments (1)
- [Abstract] The abstract contains raw LaTeX commands (\underline) that should be rendered in the final manuscript.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comment. We address the concern about the abstract below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'Extensive experiments illustrate the superiority of our SAB-LVLM over existing binary PTQ methods' supplies no quantitative results, baseline comparisons, dataset names, metrics, or ablation studies, so it is impossible to assess whether the data support the central empirical claim.
Authors: We agree that the abstract, in its current form, provides only a high-level claim without supporting numbers, making it difficult for readers to evaluate the empirical contribution from the abstract alone. The full paper contains the requested details (comparisons against binary PTQ baselines on VQA, GQA and other multimodal benchmarks, accuracy and other metrics, and ablations on the significance map and modality-guided integration). To directly address the referee's point, we will revise the abstract to incorporate concise quantitative highlights from the experimental section. revision: yes
Circularity Check
No significant circularity; empirical method validated by experiments
full rationale
The paper introduces a significance-aware binarization technique for LVLMs that constructs Hessian matrices separately for textual and visual inputs, derives a spatial significance map, applies modality-guided integration to form a binarization weighting, and incorporates this as an error reweighting term in an alternating optimization scheme. The central claim is empirical superiority under 1-bit PTQ, demonstrated via experiments rather than any closed-form derivation or prediction. No equations, self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described method; the approach is self-contained against external benchmarks and does not reduce any result to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
D.-A. team, “Deepseek-v3 technical report,”arXiv preprint arxiv:2412.19437, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
OPT: Open Pre-trained Transformer Language Models
S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. T. Diab, X. Li, X. V . Lin, T. Mihaylov, M. Ott, S. Shleifer, K. Shuster, D. Simig, P . S. Koura, A. Sridhar, T. Wang, and L. Zettlemoyer, “Opt: Open pre-trained transformer language models,”arXiv preprint arxiv:2205.01068, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “Llama: Open and efficient foundation language models,”arXiv preprint arxiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “GPTQ: Ac- curate post-training compression for generative pretrained trans- formers,”arXiv preprint arXiv:2210.17323, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Stbllm: Breaking the 1-bit barrier with structured binary llms,
P . Dong, L. Li, D. Du, Y. Chen, Z. Tang, Q. Wang, W. Xue, W. Luo, Q. fei Liu, Y.-T. Guo, and X. Chu, “Stbllm: Breaking the 1-bit barrier with structured binary llms,”ArXiv, vol. abs/2408.01803, 2024
-
[6]
Mbq: Modality- balanced quantization for large vision-language models,
S. Li, Y. Hu, X. Ning, X. Liu, K. Hong, X. Jia, X. Li, Y. Yan, P . Ran, G. Dai, S. Yan, H. Yang, and Y. Wang, “Mbq: Modality- balanced quantization for large vision-language models,”arXiv preprint arxiv:2412.19509, 2025
-
[7]
Smoothquant: accurate and efficient post-training quantization for large language models,
G. Xiao, J. Lin, M. Seznec, H. Wu, J. Demouth, and S. Han, “Smoothquant: accurate and efficient post-training quantization for large language models,” inICML, ser. ICML’23. JMLR.org, 2023
2023
-
[8]
Squeezellm: Dense-and-sparse quanti- zation,
S. Kim, C. Hooper, A. Gholami, Z. Dong, X. Li, S. Shen, M. W. Mahoney, and K. Keutzer, “Squeezellm: Dense-and-sparse quanti- zation,”ArXiv, vol. abs/2306.07629, 2023
-
[9]
A simple and effective pruning approach for large language models,
M. Sun, Z. Liu, A. Bair, and J. Z. Kolter, “A simple and effective pruning approach for large language models,” inICLR, 2024
2024
-
[10]
DISP-LLM: Dimension-independent structural pruning for large language models,
S. Gao, C.-H. Lin, T. Hua, Z. Tang, Y. Shen, H. Jin, and Y.-C. Hsu, “DISP-LLM: Dimension-independent structural pruning for large language models,” inNeurIPS, 2024
2024
-
[11]
DDK: Distilling domain knowledge for efficient large language models,
J. Liu, C. Zhang, J. Guo, Y. Zhang, H. Que, K. Deng, ZhiqiBai, J. Liu, G. Zhang, JiakaiWang, Y. Wu, C. Liu, J. Wang, L. Qu, W. Su, and B. Zheng, “DDK: Distilling domain knowledge for efficient large language models,” inNeurIPS, 2024
2024
-
[12]
MiniLLM: Knowledge distillation of large language models,
Y. Gu, L. Dong, F. Wei, and M. Huang, “MiniLLM: Knowledge distillation of large language models,” inICLR, 2024
2024
-
[13]
Compressing large language models using low rank and low precision decomposition,
R. Saha, N. Sagan, V . Srivastava, A. Goldsmith, and M. Pilanci, “Compressing large language models using low rank and low precision decomposition,” inNeurIPS, 2024
2024
-
[14]
LoRAPrune: Pruning meets low-rank parameter-efficient fine- tuning,
M. Zhang, H. Chen, C. Shen, Z. Yang, L. Ou, X. Yu, and B. Zhuang, “LoRAPrune: Pruning meets low-rank parameter-efficient fine- tuning,” 2024
2024
-
[15]
HBLLM: Wavelet-enhanced high- fidelity 1-bit quantization for LLMs,
N. CHEN, W. Ye, and Y. Jiang, “HBLLM: Wavelet-enhanced high- fidelity 1-bit quantization for LLMs,” inNeurIPS, 2025
2025
-
[16]
PB-LLM: Partially binarized large language models,
Z. Yuan, Y. Shang, and Z. Dong, “PB-LLM: Partially binarized large language models,” inICLR, 2024
2024
-
[17]
BiLLM: Pushing the limit of post-training quantization for LLMs,
W. Huang, Y. Liu, H. Qin, Y. Li, S. Zhang, X. Liu, M. Magno, and X. QI, “BiLLM: Pushing the limit of post-training quantization for LLMs,” inICML, 2024
2024
-
[18]
ARB-LLM: Alternating refined binarizations for large language models,
Z. Li, X. Yan, T. Zhang, H. Qin, D. Xie, J. Tian, zhongchao shi, L. Kong, Y. Zhang, and X. Yang, “ARB-LLM: Alternating refined binarizations for large language models,” inICLR, 2025
2025
-
[19]
SKIM: Any-bit quantization pushing the limits of post-training quantization,
R. Bai, B. Liu, and qiang liu, “SKIM: Any-bit quantization pushing the limits of post-training quantization,” inICML, 2025
2025
-
[20]
Sliderquant: Accurate post-training quantization for LLMs,
S. Wang, C. Li, Y. Kang, J. Fan, Z. Ou, and A. Yao, “Sliderquant: Accurate post-training quantization for LLMs,” inICLR, 2026
2026
-
[21]
{BRECQ}: Pushing the limit of post-training quanti- zation by block reconstruction,
Y. Li, R. Gong, X. Tan, Y. Yang, P . Hu, Q. Zhang, F. Yu, W. Wang, and S. Gu, “{BRECQ}: Pushing the limit of post-training quanti- zation by block reconstruction,” inICLR, 2021
2021
-
[22]
QA-loRA: Quantization-aware low- rank adaptation of large language models,
Y. Xu, L. Xie, X. Gu, X. Chen, H. Chang, H. Zhang, Z. Chen, X. ZHANG, and Q. Tian, “QA-loRA: Quantization-aware low- rank adaptation of large language models,” inICLR, 2024
2024
-
[23]
Quan- tized prompt for efficient generalization of vision-language mod- els,
T. Hao, X. Ding, J. Feng, Y. Yang, H. Chen, and G. Ding, “Quan- tized prompt for efficient generalization of vision-language mod- els,” inECCV, 2024
2024
-
[24]
Quantization without tears,
M. Fu, H. Yu, J. Shao, J. Zhou, K. Zhu, and J. Wu, “Quantization without tears,” inCVPR, 2025
2025
-
[25]
Rptq: Reorder-based post- training quantization for large language models,
Z. Yuan, L. Niu, J.-W. Liu, W. Liu, X. Wang, Y. Shang, G. Sun, Q. Wu, J. Wu, and B. Wu, “Rptq: Reorder-based post- training quantization for large language models,”arXiv preprint arxiv:2304.01089, 2023
-
[26]
Out- lier suppression+: Accurate quantization of large language models by equivalent and effective shifting and scaling,
X. Wei, Y. Zhang, Y. Li, X. Zhang, R. Gong, J. Guo, and X. Liu, “Out- lier suppression+: Accurate quantization of large language models by equivalent and effective shifting and scaling,” inEMNLP, 2023
2023
-
[27]
Zeroquant: Efficient and affordable post-training quantization for large-scale transformers,
Z. Yao, R. Y. Aminabadi, M. Zhang, X. Wu, C. Li, and Y. He, “Zeroquant: Efficient and affordable post-training quantization for large-scale transformers,” inNeurIPS, A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho, Eds., 2022
2022
-
[28]
Awq: Activation-aware weight quantization for on-device llm compres- sion and acceleration,
J. Lin, J. Tang, H. Tang, S. Yang, G. Xiao, and S. Han, “Awq: Activation-aware weight quantization for on-device llm compres- sion and acceleration,” vol. 28, no. 4, pp. 12–17, Jan. 2025
2025
-
[29]
Owq: outlier-aware weight quantization for efficient fine-tuning and inference of large language models,
C. Lee, J. Jin, T. Kim, H. Kim, and E. Park, “Owq: outlier-aware weight quantization for efficient fine-tuning and inference of large language models,” ser. AAAI’24/IAAI’24/EAAI’24. AAAI Press, 2024
2024
-
[30]
Spqr: A sparse-quantized representation for near-lossless llm weight compression,
T. Dettmers, R. Svirschevski, V . Egiazarian, D. Kuznedelev, E. Frantar, S. Ashkboos, A. Borzunov, T. Hoefler, and D. Alistarh, “Spqr: A sparse-quantized representation for near-lossless llm weight compression,” inICLR, B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. Sun, Eds., vol. 2024, 2024, pp. 5733–5761
2024
-
[31]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,” 2019
2019
-
[32]
Q. Team, “Qwen3 technical report,”arXiv preprint arxiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P . Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-vl: A versatile vision-language model for un- derstanding, localization, text reading, and beyond,”arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Learning to model the world: A survey of world models in artificial intelligence,
J. Dong, Q. Lyu, B. Liu, X. Wang, W. Liang, D. Zhang, J. Tu, H. Li, H. Zhao, H. Ding, Y. Zhang, Z. Han, N. Sebe, F. S. Khan, S. Khan, M. Shah, P . Torr, M.-H. Yang, and D. Tao, “Learning to model the world: A survey of world models in artificial intelligence,” T echRxiv, 2026
2026
-
[35]
Lifelong embodied navigation learning,
X. Wang, J. Dong, B. Liu, Q. Lyu, L. Liu, and Z. Han, “Lifelong embodied navigation learning,”arXiv preprint arXiv:2603.06073, 2026
-
[36]
Blip-2: bootstrapping language-image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: bootstrapping language-image pre-training with frozen image encoders and large language models,” inICML, ser. ICML’23. JMLR.org, 2023
2023
-
[37]
InstructBLIP: Towards general-purpose vision-language models with instruction tuning,
W. Dai, J. Li, D. Li, A. Tiong, J. Zhao, W. Wang, B. Li, P . Fung, and S. Hoi, “InstructBLIP: Towards general-purpose vision-language models with instruction tuning,” inNeurIPS, 2023
2023
-
[38]
H. Liu, C. Li, Q. Wu, and Y. J. Lee, “Visual instruction tuning,” arXiv preprint arxiv:2304.08485, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Qwen2.5-vl,
Q. Team, “Qwen2.5-vl,” January 2025, technical blog post
2025
-
[40]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
W. Wang, Z. Gao, L. Gu, H. Pu, L. Cui, X. Wei, Z. Liu, L. Jing, S. Ye, J. Shaoet al., “Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency,”arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Docvqa: A dataset for vqa on document images,
M. Mathew, D. Karatzas, and C. V . Jawahar, “Docvqa: A dataset for vqa on document images,” inWACV, 2021, pp. 2199–2208
2021
-
[42]
A. Das, S. Kottur, K. Gupta, A. Singh, D. Yadav, J. M. F. Moura, D. Parikh, and D. Batra, “Visual dialog,”arXiv preprint arxiv:1611.08669, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Modeling Context in Referring Expressions
L. Yu, P . Poirson, S. Yang, A. C. Berg, and T. L. Berg, “Modeling context in referring expressions,”arXiv preprint arxiv:1608.00272, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[44]
Realfred: An embodied instruction following benchmark in photo-realistic environments,
T. Kim, C. Min, B. Kim, J. Kim, W. Jeung, and J. Choi, “Realfred: An embodied instruction following benchmark in photo-realistic environments,” inECCV. Springer, 2024, pp. 346–364
2024
-
[45]
QBB: Quantization with binary bases for LLMs,
A. Bulat, Y. Ouali, and G. Tzimiropoulos, “QBB: Quantization with binary bases for LLMs,” inNeurIPS, 2024. IEEE COMPUTER SOCIETY JOURNAL, VOL. XX, NO. X, 2026 10
2024
-
[46]
Llm-qat: Data-free quantiza- tion aware training for large language models,
Z. Liu, B. Oguz, C. Zhao, E. Chang, P . Stock, Y. Mehdad, Y. Shi, R. Krishnamoorthi, and V . Chandra, “Llm-qat: Data-free quantiza- tion aware training for large language models,” inACLFindings, 2024, pp. 467–484
2024
-
[47]
Hawq: Hessian aware quantization of neural networks with mixed-precision,
Z. Dong, Z. Yao, A. Gholami, M. W. Mahoney, and K. Keutzer, “Hawq: Hessian aware quantization of neural networks with mixed-precision,” inICCV, 2019, pp. 293–302
2019
-
[48]
Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale,
T. Dettmers, M. Lewis, Y. Belkada, and L. Zettlemoyer, “Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale,”NeurIPS, vol. 35, pp. 30 318–30 332, 2022
2022
-
[49]
Microsoft coco: Common objects in context,
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P . Perona, D. Ramanan, P . Doll’ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inECCV. Springer, 2014, pp. 740–755
2014
-
[50]
Lmms-eval: Reality check on the evaluation of large multimodal models,
K. Zhang, B. Li, P . Zhang, F. Pu, J. A. Cahyono, K. Hu, S. Liu, Y. Zhang, J. Yang, C. Li, and Z. Liu, “Lmms-eval: Reality check on the evaluation of large multimodal models,” 2024
2024
-
[51]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P . Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, Y. Fan, K. Dang, M. Du, X. Ren, R. Men, D. Liu, C. Zhou, J. Zhou, and J. Lin, “Qwen2-vl: Enhancing vision- language model’s perception of the world at any resolution,”arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Are we on the right way for evaluating large vision-language models?
L. Chen, J. Li, X. Dong, P . Zhang, Y. Zang, Z. Chen, H. Duan, J. Wang, Y. Qiao, D. Lin, and F. Zhao, “Are we on the right way for evaluating large vision-language models?” inNeurIPS, 2024
2024
-
[53]
Towards vqa models that can read,
A. Singh, V . Natarajan, M. Shah, Y. Jiang, X. Chen, D. Batra, D. Parikh, and M. Rohrbach, “Towards vqa models that can read,” inCVPR, 2019, pp. 8309–8318
2019
-
[54]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis,
C. Fu, Y. Dai, Y. Luo, L. Li, S. Ren, R. Zhang, Z. Wang, C. Zhou, Y. Shen, M. Zhang, P . Chen, Y. Li, S. Lin, S. Zhao, K. Li, T. Xu, X. Zheng, E. Chen, C. Shan, R. He, and X. Sun, “Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis,” inCVPR, June 2025, pp. 24 108–24 118
2025
-
[55]
Thinking in space: How multimodal large language models see, remember, and recall spaces,
J. Yang, S. Yang, A. W. Gupta, R. Han, L. Fei-Fei, and S. Xie, “Thinking in space: How multimodal large language models see, remember, and recall spaces,” inCVPR, 2025, pp. 10 632–10 643
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.