A-TMA: Decoupling State-Aware Memory Failures in Long-Term Agent Memory
Pith reviewed 2026-07-03 14:00 UTC · model grok-4.3
The pith
Explicit state labels and evidence packets reduce ghost memory failures hidden by standard QA accuracy in long-term agent memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
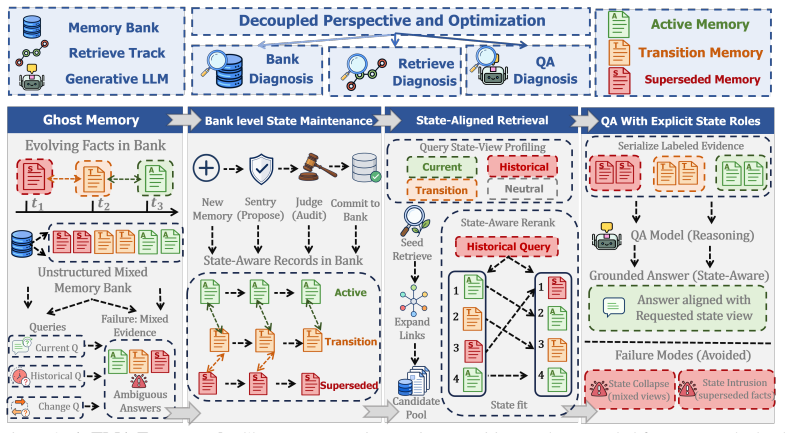
Ghost memory is a state coordination failure in which old, current, and transition facts remain mixed in the memory bank and during retrieval, leading the answer model astray. Memory systems should be understood and optimized at three distinct levels: bank maintenance, retrieval, and answer-time resolution. ATMA is a state-aware overlay that keeps superseded and transition records, builds evidence packets for the query's requested state view, and exposes current, historical, and transition labels to QA. Because final QA accuracy conceals where these failures occur, the authors introduce decoupled evaluation and the LTP benchmark to measure them directly.
What carries the argument
ATMA, a state-aware overlay that retains superseded and transition records in the bank, constructs evidence packets aligned to a query's state view, and supplies current/historical/transition labels to the QA model.
If this is right
- Keeping superseded and transition records prevents irreversible loss of change history in the memory bank.
- State-specific evidence packets limit retrieval of facts incompatible with the query's requested time view.
- Exposing state labels to QA lets the answer model resolve contradictions that would otherwise remain hidden.
- Decoupled evaluation at bank, retrieval, and answer levels reveals the precise location of memory failures.
- Improvements on LTP and LoCoMo indicate that state coordination can be added as an overlay to existing memory architectures.
Where Pith is reading between the lines
- The host-dependent nature of the gains implies that integration details between ATMA and different base memory systems will determine how widely the approach transfers.
- If state labels prove effective, future memory benchmarks may need to include explicit queries for current versus historical states rather than relying on overall accuracy.
- The three-level decoupling framework could be applied to other persistent-agent components such as planning or tool-use memory to isolate similar coordination failures.
Load-bearing premise
That explicit state labels and evidence packets will measurably reduce ghost memory failures on conflict-heavy queries without creating new retrieval or answer errors that offset the gains.
What would settle it
Running Graphiti+ATMA and several other base memory systems on the LTP benchmark and finding no increase, or a decrease, in conflict accuracy while standard QA accuracy stays flat or falls.
Figures
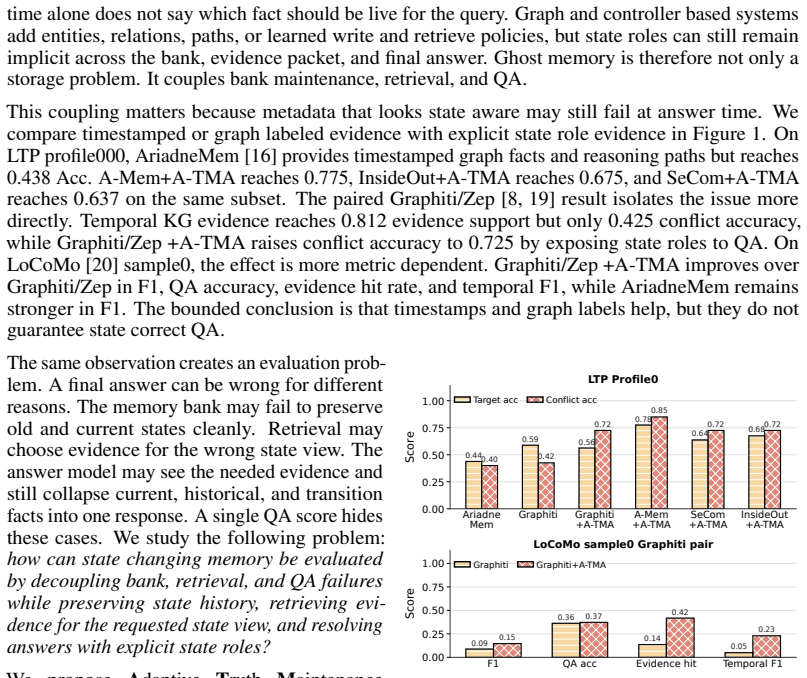
read the original abstract
Long term memory lets LLM agents act as persistent assistants, but user facts change. A useful memory system must know what is true now, what used to be true, and what changed. We study \emph{ghost memory}, a state coordination failure in which old, current, and transition facts coexist in the memory bank, remain mixed during retrieval, and mislead the answer model. We argue that memory systems should be understood and optimized from three levels: bank maintenance, retrieval, and answer time resolution. We propose ATMA, a state aware overlay for existing memory systems. ATMA keeps superseded and transition records in the bank, builds evidence packets for the query's requested state view, and exposes current, historical, and transition labels to QA. We further call for decoupled evaluation of bank, retrieval, and answer level failures, since final QA accuracy can hide where ghost memory occurs. To make this failure measurable, we build LTP (LoCoMo Temporal Plus), a conflict heavy benchmark for ghost memory, and evaluate on LoCoMo for long conversation generalization. On LTP, Graphiti+ATMA improves conflict accuracy by 0.240 absolute over Graphiti. On LoCoMo, Graphiti+ATMA raises temporal F1 from 0.0295 to 0.1705. The gains are host dependent, but they indicate that explicit state roles can reduce memory failures hidden by final QA accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines 'ghost memory' as a state-coordination failure in long-term agent memory where superseded, current, and transition facts coexist and mix during retrieval, misleading the answer model. It proposes ATMA, a state-aware overlay for existing memory systems that retains superseded and transition records, constructs evidence packets matched to the query's requested state view, and supplies current/historical/transition labels to the QA stage. The work advocates decoupled evaluation at bank, retrieval, and answer levels (since aggregate QA accuracy can obscure failure locations), introduces the LTP benchmark for conflict-heavy temporal evaluation, and reports that Graphiti+ATMA improves conflict accuracy by 0.240 on LTP and temporal F1 from 0.0295 to 0.1705 on LoCoMo.
Significance. If the central claim is supported by the missing decoupled metrics and ablations, the work would supply a concrete mechanism and evaluation protocol for handling state evolution in persistent agent memory, moving beyond aggregate QA scores that the paper itself identifies as insufficient.
major comments (2)
- [Abstract] Abstract: the paper explicitly states that 'final QA accuracy can hide where ghost memory occurs' and calls for decoupled bank/retrieval/answer metrics, yet reports only end-to-end numbers (conflict accuracy +0.240 on LTP; temporal F1 +0.141 on LoCoMo) with no per-state retrieval precision, superseded-record pollution counts, or ablation isolating the label/packet component; this directly undermines the claim that state labels and evidence packets are responsible for the observed gains.
- [Abstract] Evaluation (LTP and LoCoMo results): no implementation details, controls, or error analysis are supplied for the reported numeric gains, making it impossible to determine whether the improvements arise from the claimed state coordination or from incidental changes in retrieval volume or host prompting.
minor comments (2)
- [Title] Title uses 'A-TMA' while the abstract and text consistently use 'ATMA'; standardize notation.
- [Abstract] The term 'ghost memory' is introduced without a formal definition or equation; a precise characterization (e.g., a set-equation over memory-bank states) would strengthen the subsequent claims.
Simulated Author's Rebuttal
We thank the referee for highlighting the gap between the paper's advocacy for decoupled evaluation and the reported results. We agree the claims would be stronger with explicit per-component metrics and controls. Below we respond to each major comment and commit to revisions that address them directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the paper explicitly states that 'final QA accuracy can hide where ghost memory occurs' and calls for decoupled bank/retrieval/answer metrics, yet reports only end-to-end numbers (conflict accuracy +0.240 on LTP; temporal F1 +0.141 on LoCoMo) with no per-state retrieval precision, superseded-record pollution counts, or ablation isolating the label/packet component; this directly undermines the claim that state labels and evidence packets are responsible for the observed gains.
Authors: We acknowledge the inconsistency. Although the manuscript argues for bank/retrieval/answer decoupling and introduces LTP to surface ghost-memory failures, the presented results remain aggregate. In revision we will add (1) per-state retrieval precision, (2) superseded-record pollution counts at the bank level, and (3) an ablation that isolates the contribution of state labels plus evidence packets versus the host system alone. These additions will be placed in a new 'Decoupled Evaluation' subsection and will directly test whether the observed gains are attributable to the proposed mechanisms. revision: yes
-
Referee: [Abstract] Evaluation (LTP and LoCoMo results): no implementation details, controls, or error analysis are supplied for the reported numeric gains, making it impossible to determine whether the improvements arise from the claimed state coordination or from incidental changes in retrieval volume or host prompting.
Authors: The full manuscript contains an experimental-setup section, yet we agree it lacks the granularity needed to isolate causes. In the revision we will expand the evaluation to include: retrieval-volume-matched controls, host-prompting ablations, and a per-example error analysis that categorizes remaining failures by bank, retrieval, and answer stage. These controls will be reported alongside the existing LTP and LoCoMo numbers so readers can assess whether gains stem from state coordination. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper proposes the ATMA overlay system and reports empirical QA gains on LTP and LoCoMo benchmarks. No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations appear in the provided text. The central claims rest on experimental results rather than reducing to inputs by construction, and the call for decoupled metrics is an evaluation recommendation, not a circular derivation step.
Axiom & Free-Parameter Ledger
invented entities (1)
-
ghost memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Generative Agents: Interactive Simulacra of Human Behavior
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior.arXiv 11 preprint arXiv:2304.03442, 2023. doi: 10.48550/arXiv.2304.03442. URL https://arxiv. org/abs/2304.03442
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.03442 2023
-
[2]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
ReAct: Synergizing Reasoning and Acting in Language Models
doi: 10.48550/arXiv.2210.03629. URLhttps://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.03629
-
[4]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.arXiv preprint arXiv:2303.11366, 2023. doi: 10.48550/arXiv.2303.11366. URL https://arxiv.org/abs/ 2303.11366
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.11366 2023
-
[5]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023. doi: 10.48550/arXiv.2305.16291. URL https://arxiv.org/abs/2305.16291
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.16291 2023
-
[6]
A Survey on Large Language Model based Autonomous Agents
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Ji-Rong Wen. A survey on large language model based autonomous agents.arXiv preprint arXiv:2308.11432, 2023. doi: 10.48550/arXiv.2308.11432. URLhttps://arxiv.org/abs/2308.11432
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.11432 2023
-
[7]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready AI agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025. doi: 10.48550/arXiv.2504.19413. URL https://arxiv.org/ abs/2504.19413
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.19413 2025
-
[8]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-Mem: Agentic memory for LLM agents. InAdvances in Neural Information Processing Systems, 2025. URLhttps://arxiv.org/abs/2502.12110. arXiv:2502.12110
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: A temporal knowledge graph architecture for agent memory, 2025. URL https://arxiv.org/ abs/2501.13956
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
MemoryBank: Enhancing Large Language Models with Long-Term Memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. MemoryBank: Enhancing large language models with long-term memory.arXiv preprint arXiv:2305.10250, 2023. doi: 10.48550/arXiv.2305.10250. URLhttps://arxiv.org/abs/2305.10250
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.10250 2023
-
[11]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems.arXiv preprint arXiv:2310.08560, 2023. doi: 10.48550/arXiv.2310.08560. URL https://arxiv.org/ abs/2310.08560
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.08560 2023
-
[12]
MEMORYLLM: Towards self-updatable large language models.arXiv preprint arXiv:2402.04624, 2024
Yu Wang, Yifan Gao, Xiusi Chen, Haoming Jiang, Shiyang Li, Jingfeng Yang, Qingyu Yin, Zheng Li, Xian Li, Bing Yin, Jingbo Shang, and Julian McAuley. MEMORYLLM: Towards self-updatable large language models.arXiv preprint arXiv:2402.04624, 2024. doi: 10.48550/ arXiv.2402.04624. URLhttps://arxiv.org/abs/2402.04624
-
[13]
MemOS: A Memory OS for AI System
Zhiyu Li, Chenyang Xi, Chunyu Li, Ding Chen, Boyu Chen, Shichao Song, Simin Niu, Hanyu Wang, Jiawei Yang, Chen Tang, Qingchen Yu, Jihao Zhao, et al. MemOS: A memory OS for AI system.arXiv preprint arXiv:2507.03724, 2025. doi: 10.48550/arXiv.2507.03724. URL https://arxiv.org/abs/2507.03724
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.03724 2025
-
[14]
Vicky Zhao, Lili Qiu, and Jianfeng Gao
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Xufang Luo, Hao Cheng, Dongsheng Li, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, and Jianfeng Gao. On memory construction and retrieval for personalized conversational agents.arXiv preprint arXiv:2502.05589, 2025. doi: 10.48550/arXiv.2502.05589. URLhttps://arxiv.org/abs/2502.05589
-
[15]
Augmenting language models with long-term memory.arXiv preprint arXiv:2306.07174, 2023
Weizhi Wang, Li Dong, Hao Cheng, Xiaodong Liu, Xifeng Yan, Jianfeng Gao, and Furu Wei. Augmenting language models with long-term memory.arXiv preprint arXiv:2306.07174, 2023. doi: 10.48550/arXiv.2306.07174. URLhttps://arxiv.org/abs/2306.07174. 12
-
[16]
M+: Extending MemoryLLM with scalable long-term memory.arXiv preprint arXiv:2502.00592, 2025
Yu Wang, Dmitry Krotov, Yuanzhe Hu, Yifan Gao, Wangchunshu Zhou, Julian McAuley, Dan Gutfreund, Rogerio Feris, and Zexue He. M+: Extending MemoryLLM with scalable long-term memory.arXiv preprint arXiv:2502.00592, 2025. doi: 10.48550/arXiv.2502.00592. URL https://arxiv.org/abs/2502.00592
-
[17]
AriadneMem: Threading the maze of lifelong memory for LLM agents, 2026
Wenhui Zhu, Xiwen Chen, Zhipeng Wang, Jingjing Wang, Xuanzhao Dong, Minzhou Huang, Rui Cai, Hejian Sang, Hao Wang, Peijie Qiu, Yueyue Deng, Prayag Tiwari, Brendan Hogan Rappazzo, and Yalin Wang. AriadneMem: Threading the maze of lifelong memory for LLM agents, 2026. URLhttps://arxiv.org/abs/2603.03290
-
[18]
Bernal Jimenez Gutierrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. HippoRAG: Neurobiologically inspired long-term memory for large language models.arXiv preprint arXiv:2405.14831, 2024. doi: 10.48550/arXiv.2405.14831. URL https://arxiv.org/abs/ 2405.14831
-
[19]
Yupeng Huo, Yaxi Lu, Zhong Zhang, Haotian Chen, and Yankai Lin. AtomMem: Learnable dynamic agentic memory with atomic memory operation.arXiv preprint arXiv:2601.08323,
-
[20]
doi: 10.48550/arXiv.2601.08323. URLhttps://arxiv.org/abs/2601.08323
-
[21]
Graphiti: Build temporal context graphs for ai agents
Zep AI. Graphiti: Build temporal context graphs for ai agents. https://github.com/ getzep/graphiti, 2024. Open-source temporal context graph engine underlying Zep, ac- cessed 2026-06-06
2024
-
[22]
Evaluating very long-term conversational memory of LLM agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 13851–13870, Bangkok, Thailand, August 2024. Association for Computational...
-
[23]
$\delta$-mem: Efficient Online Memory for Large Language Models
Jingdi Lei, Di Zhang, Junxian Li, Weida Wang, Kaixuan Fan, Xiang Liu, Qihan Liu, Xiaoteng Ma, Baian Chen, and Soujanya Poria. δ-mem: Efficient online memory for large language models.arXiv preprint arXiv:2605.12357, 2026. doi: 10.48550/arXiv.2605.12357. URL https://arxiv.org/abs/2605.12357
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.12357 2026
-
[24]
MemTrace: Tracing and Attributing Errors in Large Language Model Memory Systems
Xinle Deng, Ruobin Zhong, Hujin Peng, Xiaoben Lu, Yanzhe Wu, Guang Li, Buqiang Xu, Yunzhi Yao, Jizhan Fang, Haoliang Cao, Junjie Guo, Yuan Yuan, Ziqing Ma, Yuanqiang Yu, Rui Hu, Baohua Dong, Hangcheng Zhu, and Ningyu Zhang. MemTrace: Tracing and attributing errors in large language model memory systems.arXiv preprint arXiv:2605.28732, 2026. doi: 10.48550/...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.28732 2026
-
[25]
MemTrace: Probing What Final Accuracy Misses in Long-Term Memory
Xianxuan Long, Zhikai Chen, Shenglai Zeng, Shouren Wang, Kai Guo, and Jiliang Tang. MemTrace: Probing what final accuracy misses in long-term memory.arXiv preprint arXiv:2606.17328, 2026. URLhttps://arxiv.org/abs/2606.17328
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
DynamicMem: A Long-Horizon Memory Benchmark in Real-World Settings
Wenya Xie, Shengming Zhou, Zelin Li, Pouya Parsa, Shuang Zhou, Xinheng Ding, Chin- may Arvind, Guanchu Wang, Vladimir Braverman, Ali Payani, Yantao Zheng, and Zirui Liu. DynamicMem: A long-horizon memory benchmark in real-world settings.arXiv preprint arXiv:2606.22877, 2026. doi: 10.48550/arXiv.2606.22877. URL https://arxiv.org/abs/ 2606.22877
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2606.22877 2026
-
[27]
MEMPROBE: Probing Long-Term Agent Memory via Hidden User-State Recovery
Enze Ma, Yufan Zhou, Wei-Chieh Huang, Jie Yang, Huanhuan Ma, Zixuan Wang, Chengze Li, Chunyu Miao, Philip S. Yu, and Zhen Wang. MEMPROBE: Probing long-term agent memory via hidden user-state recovery.arXiv preprint arXiv:2606.24595, 2026. doi: 10.48550/arXiv. 2606.24595. URLhttps://arxiv.org/abs/2606.24595
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2026
-
[28]
Are We Ready For An Agent-Native Memory System?
Wei Zhou, Xuanhe Zhou, Shaokun Han, Hongming Xu, Guoliang Li, Zhiyu Li, Feiyu Xiong, and Fan Wu. Are we ready for an agent-native memory system?arXiv preprint arXiv:2606.24775,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Are We Ready For An Agent-Native Memory System?
doi: 10.48550/arXiv.2606.24775. URLhttps://arxiv.org/abs/2606.24775
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2606.24775
-
[30]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench: A bilingual, multitask benchmark for long context understanding.arXiv preprint arXiv:2308.14508, 2023. doi: 10.48550/arXiv.2308.14508. URLhttps://arxiv.org/abs/2308.14508. 13
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.14508 2023
-
[31]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- MemEval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813, 2024. doi: 10.48550/arXiv.2410.10813. URL https://arxiv.org/abs/ 2410.10813
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.10813 2024
-
[32]
Lost in the Middle: How Language Models Use Long Contexts
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.arXiv preprint arXiv:2307.03172, 2023. doi: 10.48550/arXiv.2307.03172. URL https://arxiv.org/abs/ 2307.03172
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.03172 2023
-
[33]
REALM: Retrieval-Augmented Language Model Pre-Training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. REALM: Retrieval-augmented language model pre-training.arXiv preprint arXiv:2002.08909, 2020. doi: 10.48550/arXiv.2002.08909. URLhttps://arxiv.org/abs/2002.08909
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2002.08909 2002
-
[34]
Dense Passage Retrieval for Open-Domain Question Answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. arXiv preprint arXiv:2004.04906, 2020. doi: 10.48550/arXiv.2004.04906. URL https: //arxiv.org/abs/2004.04906
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2004.04906 2004
-
[35]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Na- man Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems, volume 33, pages 9459–9474, 2020. URL https://...
2020
-
[36]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-RAG: Learn- ing to retrieve, generate, and critique through self-reflection.arXiv preprint arXiv:2310.11511,
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
doi: 10.48550/arXiv.2310.11511. URLhttps://arxiv.org/abs/2310.11511
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.11511
-
[38]
Wenhao Yu, Hongming Zhang, Xiaoman Pan, Kaixin Ma, Hongwei Wang, and Dong Yu. Chain-of-note: Enhancing robustness in retrieval-augmented language models.arXiv preprint arXiv:2311.09210, 2023. doi: 10.48550/arXiv.2311.09210. URL https://arxiv.org/abs/ 2311.09210
-
[39]
Sentence-BERT: Sentence embeddings using siamese BERT-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using siamese BERT-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, pages 3982–3992, 2019. doi: 10.18653/v1/D19-1410. URL https: //aclanthology.org/D19-1410/
-
[40]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. URL https://openreview.net/forum? id=Bkg6RiCqY7
2019
-
[41]
Jihao Zhao, Ding Chen, Zhaoxin Fan, Kerun Xu, Mengting Hu, Bo Tang, Feiyu Xiong, and Zhiyu Li. Inside out: Evolving user-centric core memory trees for long-term personalized dialogue systems.arXiv preprint arXiv:2601.05171, 2026. doi: 10.48550/arXiv.2601.05171. URLhttps://arxiv.org/abs/2601.05171
-
[42]
B leu: a Method for Automatic Evaluation of Machine Translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. BLEU: A method for automatic evaluation of machine translation. InProceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, 2002. doi: 10.3115/1073083.1073135. URL https://aclanthology.org/P02-1040/. A Experimental Details A.1 Benchmark Protocol All ...
-
[43]
infer the requested state view: current, historical, change, or neutral
-
[44]
select and rank only the highest-priority candidate evidence rows for state-correct evidence construction
-
[45]
prefer direct state evidence over broad weak hops
-
[46]
keep transition evidence only when it helps answer a change-related or ambiguity-sensitive query
-
[47]
be concise: short reasons only
-
[48]
Before the update, how many hours per night did you sleep on average?
return strict JSON only. The user prompt is a JSON object with task=retrieve_control, the query, top_k, max_selected, the rule based query profile, the compact candidate list, the required output schema, and short instructions. The required output fields are query_mode, confidence, fallback_recommended, a selected list containing candidate_id, rank, role,...
-
[49]
Speaker Caroline says : I sleep about 7 hours per night on average
“Speaker Caroline says : I sleep about 7 hours per night on average.”
-
[50]
Speaker Caroline says : I sleep about 5 hours per night on average
“Speaker Caroline says : I sleep about 5 hours per night on average”
-
[51]
Speaker Caroline says : Wow! Did you see that band?
“Speaker Caroline says : Wow! Did you see that band?”
-
[52]
Speaker Melanie says : Wow, looks awesome! Did you join in?
“Speaker Melanie says : Wow, looks awesome! Did you join in?” QA serialization.Full A-TMA passes the same evidence with the requested historical state view, while the no-label variant passes the rows without explicit state roles. QA responses.Full A-TMA: “Before the update, Caroline slept about 5 hours per night on average.” Judge: correct, 1.0. No QA lab...
-
[56]
Speaker Caroline says : I drive about 4500 miles per year in my 14-year-old car
“Speaker Caroline says : I drive about 4500 miles per year in my 14-year-old car.” Retrieved evidence with controller (top rows)
-
[57]
Speaker Caroline says : I drive about 3000 miles per year in my 14-year-old car
“Speaker Caroline says : I drive about 3000 miles per year in my 14-year-old car”
-
[58]
Speaker Caroline says : Sounds fun! What was the best part? Do you do it often with the kids?
“Speaker Caroline says : Sounds fun! What was the best part? Do you do it often with the kids?”
-
[59]
Speaker Melanie says : Wow, sounds amazing! What was the event like? Those posters are great!
“Speaker Melanie says : Wow, sounds amazing! What was the event like? Those posters are great!”
-
[60]
Speaker Caroline says : I drive about 4500 miles per year in my 14-year-old car
“Speaker Caroline says : I drive about 4500 miles per year in my 14-year-old car.” QA responses.Shadow baseline: “4500 miles per year.” Judge: wrong, 0.0. Online controller: “3000 miles per year.” Judge: correct, 1.0. Run note.QA model:qwen2.5:3b; judge:qwen3:30b. The first trace isolates answer-side serialization: the retrieved rows are unchanged, but ex...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.