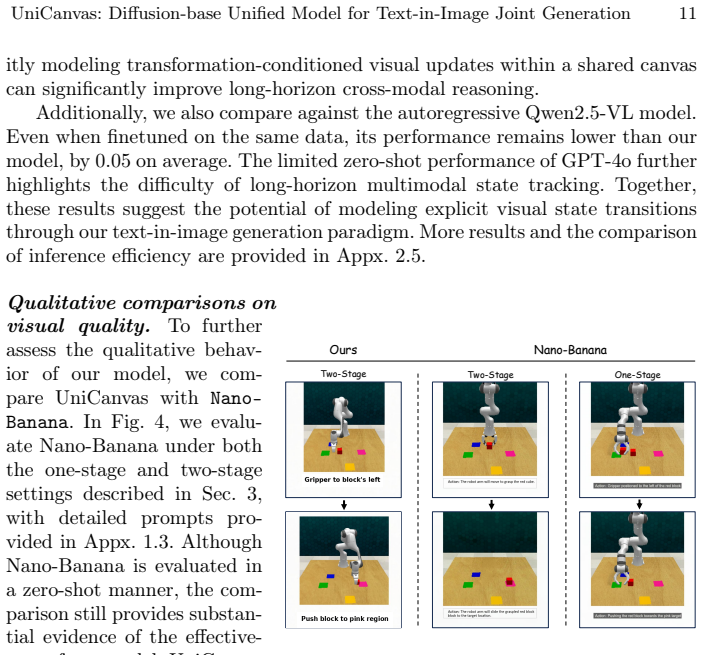
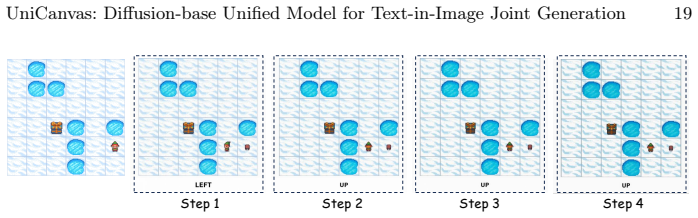
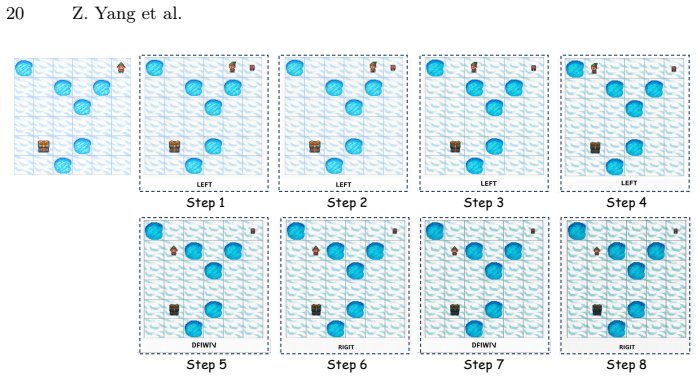
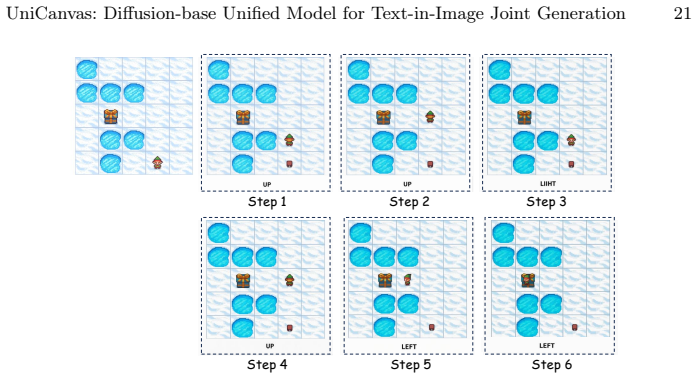
UniCanvas: A Diffusion-base Unified Model for Text-in-Image Joint Generation
Pith reviewed 2026-06-28 10:21 UTC · model grok-4.3
The pith
UniCanvas generates text and images together by rendering language as visual patterns on a shared pixel canvas.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
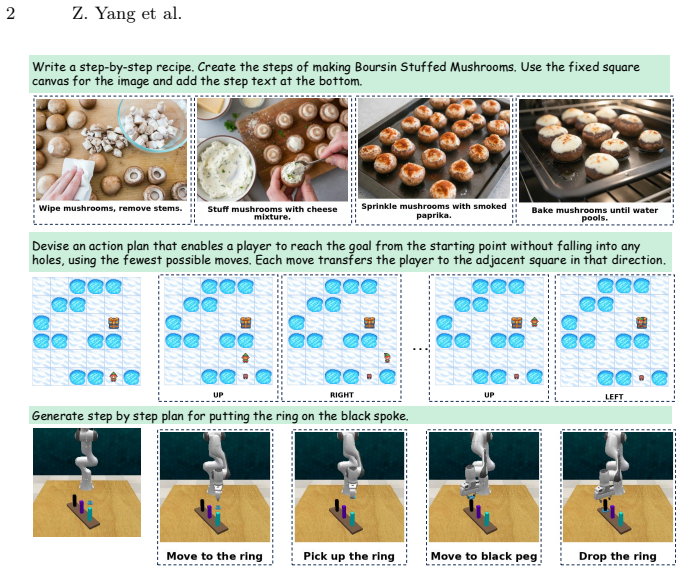
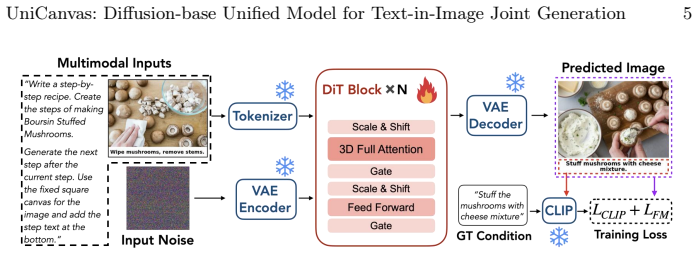
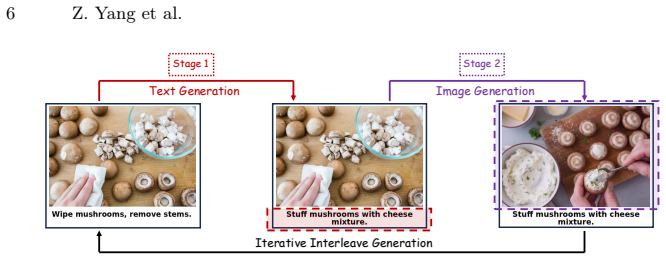
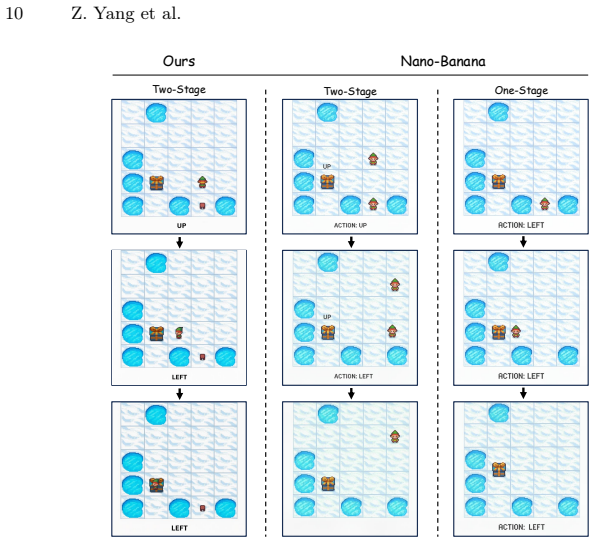
UniCanvas unifies diffusion models to generate interleaved multimodal contents through text-in-image generation, where the model learns to represent language as visual patterns inside images on a shared pixel canvas instead of producing discrete text tokens.
What carries the argument
The shared pixel canvas on which the diffusion model generates both images and text rendered as visual patterns.
If this is right
- The model produces coherent text embedded within images as part of a single synthesis process.
- Diffusion models become viable for unified multimodal generation without autoregressive components.
- Text-in-image generation establishes a new paradigm that improves performance over prior unified vision-language models.
Where Pith is reading between the lines
- The same canvas-based approach could be tested on generating structured visual elements such as charts or diagrams alongside natural images.
- If successful at scale, this method might reduce the need for hybrid architectures that combine separate text and image generators.
- Extensions to longer interleaved sequences could test whether the pixel-canvas representation maintains coherence across multiple sentences of embedded text.
Load-bearing premise
Representing language as visual patterns inside images on a shared pixel canvas enables the diffusion model to generate coherent text without separate discrete token mechanisms.
What would settle it
A side-by-side evaluation in which text rendered inside generated images is measurably less readable or coherent than text produced by models that use explicit token prediction would falsify the central claim.
Figures


read the original abstract
Recent years have seen remarkable progress in unified vision-language models handling both multimodal understanding and generation within a single architecture. While autoregressive VLMs can reason across modalities, they fail to generate high-quality images. In contrast, diffusion models produce photorealistic visuals yet struggle to generate coherent text, making it challenging to develop a single unified model that can seamlessly handle both visual and text generation. Recent advances suggest that language can be effectively embedded within visual representations, allowing models to reason about textual semantics directly from images. To this end, we propose UniCanvas, a first attempt that unifies diffusion models to generate interleaved multimodal contents through text-in-image generation. Diffusion models naturally capture transformations on a shared pixel canvas, which can be viewed as world models of visual change. Instead of producing discrete text tokens, the model learns to represent language as visual patterns inside images, leveraging its inherent multimodal embedding space. This design allows the model to "draw" text naturally within a single pixel canvas during image synthesis, achieving seamless multimodal generation. Experiments demonstrate that UniCanvas improves performance over previous unified models, positioning text-in-image generation with diffusion models as a promising unified multimodal generation paradigm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UniCanvas, a diffusion-based model for unified multimodal generation that embeds language as visual patterns on a shared pixel canvas instead of using discrete text tokens. This design is intended to allow a single diffusion model to generate interleaved text and images by treating text generation as a visual synthesis task. The abstract asserts that experiments show performance improvements over prior unified models and positions the approach as a promising paradigm.
Significance. If the empirical claims are substantiated, the work could meaningfully advance unified vision-language generation by removing the need for separate autoregressive text mechanisms and leveraging diffusion models' existing pixel-canvas operations, potentially simplifying architectures for joint multimodal output.
major comments (1)
- [Abstract] Abstract: the central claim that 'Experiments demonstrate that UniCanvas improves performance over previous unified models' is unsupported by any metrics, baselines, tables, figures, or experimental details in the manuscript, making the primary empirical assertion impossible to evaluate.
minor comments (1)
- [Title] Title contains a clear typo: 'Diffusion-base' should read 'Diffusion-based'.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for highlighting this issue with the abstract. We address the comment point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'Experiments demonstrate that UniCanvas improves performance over previous unified models' is unsupported by any metrics, baselines, tables, figures, or experimental details in the manuscript, making the primary empirical assertion impossible to evaluate.
Authors: We agree that the current version of the manuscript does not contain the metrics, baselines, tables, or figures needed to substantiate the performance claim made in the abstract. In the revised manuscript we will remove the unsupported empirical assertion from the abstract (or qualify it as a direction for future work) until the corresponding experimental results can be included. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces UniCanvas as a conceptual architecture for unified multimodal generation by embedding text as visual patterns on a shared pixel canvas within a diffusion model. No equations, parameter fittings, predictions derived from inputs, or self-citation chains appear in the provided abstract or described structure. The central claim rests on the design choice and subsequent empirical experiments, which are presented as falsifiable performance improvements rather than any self-referential derivation or renaming of known results. The derivation chain is self-contained at the level of a high-level proposal without reductions to fitted inputs or prior author work by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., et al.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
In: Proceedings of the Computer Vision and Pattern Recognition Con- ference
Bar, A., Zhou, G., Tran, D., Darrell, T., LeCun, Y.: Navigation world mod- els. In: Proceedings of the Computer Vision and Pattern Recognition Con- ference. pp. 15791–15801 (2025)
2025
-
[4]
arXiv preprint arXiv:2602.02227 (2026)
Chen, H.H., Yin, X., Shu, W.J., Zhang, H., Zhang, Z., Liao, C., Guo, L., Chen, Q., Chen, Y.C.: Show, don’t tell: Morphing latent reasoning into image generation. arXiv preprint arXiv:2602.02227 (2026)
-
[5]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Chen, J., Xu, Z., Pan, X., Hu, Y., Qin, C., Goldstein, T., Huang, L., Zhou, T., Xie, S., Savarese, S., et al.: Blip3-o: A family of fully open uni- fied multimodal models-architecture, training and dataset. arXiv preprint arXiv:2505.09568 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
PixArt-$\alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
Chen, J., Yu, J., Ge, C., Yao, L., Xie, E., Wu, Y., Wang, Z., Kwok, J., Luo, P., Lu, H., et al.: Pixart: Fast training of diffusion transformer for photore- alistic text-to-image synthesis. arXiv preprint arXiv:2310.00426 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
arXiv preprint arXiv:2407.06135 (2024)
Chern, E., Su, J., Ma, Y., Liu, P.: Anole: An open, autoregressive, na- tive large multimodal models for interleaved image-text generation. arXiv preprint arXiv:2407.06135 (2024)
-
[8]
Emerging Properties in Unified Multimodal Pretraining
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., et al.: Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Advances in neural information processing systems34, 8780–8794 (2021)
Dhariwal, P., Nichol, A.: Diffusion models beat gans on image synthesis. Advances in neural information processing systems34, 8780–8794 (2021)
2021
-
[10]
arXiv preprint arXiv:2309.11499 (2023)
Dong, R., Han, C., Peng, Y., Qi, Z., Ge, Z., Yang, J., Zhao, L., Sun, J., Zhou, H., Wei, H., et al.: Dreamllm: Synergistic multimodal comprehension and creation. arXiv preprint arXiv:2309.11499 (2023)
-
[11]
GoT-R1: Unleashing Reasoning Capability of MLLM for Visual Generation with Reinforcement Learning
Duan, C., Fang, R., Wang, Y., Wang, K., Huang, L., Zeng, X., Li, H., Liu, X.: Got-r1: Unleashing reasoning capability of mllm for visual generation with reinforcement learning. arXiv preprint arXiv:2505.17022 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
In: Forty-first international confer- ence on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transform- ers for high-resolution image synthesis. In: Forty-first international confer- ence on machine learning (2024)
2024
-
[13]
Gao, P., Zhuo, L., Liu, D., Du, R., Luo, X., Qiu, L., Zhang, Y., Lin, C., Huang, R., Geng, S., et al.: Lumina-t2x: Transforming text into any modal- ity, resolution, and duration via flow-based large diffusion transformers. arXiv preprint arXiv:2405.05945 (2024) UniCanvas: Diffusion-base Unified Model for Text-in-Image Joint Generation 25
-
[14]
arXiv preprint arXiv:2503.18938 (2025)
Gao, S., Zhou, S., Du, Y., Zhang, J., Gan, C.: Adaworld: Learning adaptable world models with latent actions. arXiv preprint arXiv:2503.18938 (2025)
-
[15]
Gu, J., Hao, Y., Wang, H.W., Li, L., Shieh, M.Q., Choi, Y., Krishna, R., Cheng, Y.: Thinkmorph: Emergent properties in multimodal interleaved chain-of-thought reasoning. arXiv preprint arXiv:2510.27492 (2025)
-
[16]
arXiv preprint arXiv:2511.16671 (2025)
Guo, Z., Zhang, R., Li, H., Zhang, M., Chen, X., Wang, S., Feng, Y., Pei, P., Heng, P.A.: Thinking-while-generating: Interleaving textual reasoning throughout visual generation. arXiv preprint arXiv:2511.16671 (2025)
-
[17]
arXiv preprint arXiv:2501.13926 (2025)
Guo, Z., Zhang, R., Tong, C., Zhao, Z., Huang, R., Zhang, H., Zhang, M., Liu, J., Zhang, S., Gao, P., et al.: Can we generate images with cot? let’s verify and reinforce image generation step by step. arXiv preprint arXiv:2501.13926 (2025)
-
[18]
Ha, D., Schmidhuber, J.: World models. arXiv preprint arXiv:1803.10122 2(3), 440 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
Dream to Control: Learning Behaviors by Latent Imagination
Hafner, D., Lillicrap, T., Ba, J., Norouzi, M.: Dream to control: Learning behaviors by latent imagination. arXiv preprint arXiv:1912.01603 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[20]
arXiv preprint arXiv:2601.03193 (2026)
Han, R., Fang, Z., Sun, X., Ma, Y., Wang, Z., Zeng, Y., Chen, Z., Chen, L., Huang, W., Xu, W.J., et al.: Unicorn: Towards self-improving uni- fied multimodal models through self-generated supervision. arXiv preprint arXiv:2601.03193 (2026)
-
[21]
In: Advances in Neural Information Processing Systems (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: Advances in Neural Information Processing Systems (2020)
2020
-
[22]
Classifier-Free Diffusion Guidance
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
IEEE Robotics and Automation Letters5(2), 3019–3026 (2020)
James, S., Ma, Z., Arrojo, D.R., Davison, A.J.: Rlbench: The robot learn- ing benchmark & learning environment. IEEE Robotics and Automation Letters5(2), 3019–3026 (2020)
2020
-
[24]
Jiang, D., Guo, Z., Zhang, R., Zong, Z., Li, H., Zhuo, L., Yan, S., Heng, P.A., Li, H.: T2i-r1: Reinforcing image generation with collaborative semantic- level and token-level cot. arXiv preprint arXiv:2505.00703 (2025)
-
[25]
arXiv preprint arXiv:2512.05112 (2025)
Jiang, D., Zhang, R., Li, H., Zong, Z., Guo, Z., He, J., Guo, C., Ye, J., Fang, R., Li, W., et al.: Draco: Draft as cot for text-to-image preview and rare concept generation. arXiv preprint arXiv:2512.05112 (2025)
-
[26]
arXiv preprint arXiv:2505.17534 (2025)
Jiang, J., Si, C., Luo, J., Zhang, H., Ma, C.: Co-reinforcement learn- ing for unified multimodal understanding and generation. arXiv preprint arXiv:2505.17534 (2025)
-
[27]
Advances in neural information process- ing systems35, 26565–26577 (2022)
Karras, T., Aittala, M., Aila, T., Laine, S.: Elucidating the design space of diffusion-based generative models. Advances in neural information process- ing systems35, 26565–26577 (2022)
2022
-
[28]
Advances in neural information processing systems34, 21696–21707 (2021)
Kingma, D., Salimans, T., Poole, B., Ho, J.: Variational diffusion models. Advances in neural information processing systems34, 21696–21707 (2021)
2021
-
[29]
Imagine while Reasoning in Space: Multimodal Visualization-of-Thought
Li, C., Wu, W., Zhang, H., Xia, Y., Mao, S., Dong, L., Vulić, I., Wei, F.: Imagine while reasoning in space: Multimodal visualization-of-thought. arXiv preprint arXiv:2501.07542 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Causal World Modeling for Robot Control
Li, L., Zhang, Q., Luo, Y., Yang, S., Wang, R., Han, F., Yu, M., Gao, Z., Xue, N., Zhu, X., Shen, Y., Xu, Y.: Causal world modeling for robot control. arXiv preprint arXiv:2601.21998 (2026) 26 Z. Yang et al
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Genie Envisioner: A Unified World Foundation Platform for Robotic Manipulation
Liao, Y., Zhou, P., Huang, S., Yang, D., Chen, S., Jiang, Y., Hu, Y., Cai, J., Liu, S., Luo, J., et al.: Genie envisioner: A unified world foundation platform for robotic manipulation. arXiv preprint arXiv:2508.05635 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
In: NeurIPS (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: NeurIPS (2023)
2023
-
[33]
arXiv preprint arXiv:2502.20321 (2025)
Ma, C., Jiang, Y., Wu, J., Yang, J., Yu, X., Yuan, Z., Peng, B., Qi, X.: Unitok: A unified tokenizer for visual generation and understanding. arXiv preprint arXiv:2502.20321 (2025)
-
[34]
arXiv preprint arXiv:2411.07975 (2024)
Ma, Y., Liu, X., Chen, X., Liu, W., Wu, C., Wu, Z., Pan, Z., Xie, Z., Zhang, H., Zhao, L., et al.: Janusflow: Harmonizing autoregression and rectified flow for unified multimodal understanding and generation. arXiv preprint arXiv:2411.07975 (2024)
-
[35]
In: International conference on machine learning
Nichol, A.Q., Dhariwal, P.: Improved denoising diffusion probabilistic mod- els. In: International conference on machine learning. pp. 8162–8171. PMLR (2021)
2021
-
[36]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
arXiv preprint arXiv:2510.07313 (2025)
Qian, Z., Chi, X., Li, Y., Wang, S., Qin, Z., Ju, X., Han, S., Zhang, S.: Wristworld: Generating wrist-views via 4d world models for robotic manip- ulation. arXiv preprint arXiv:2510.07313 (2025)
-
[38]
arXiv preprint arXiv:2508.05606 (2025)
Qin, L., Gong, J., Sun, Y., Li, T., Yang, M., Yang, X., Qu, C., Tan, Z., Li, H.: Uni-cot: Towards unified chain-of-thought reasoning across text and vision. arXiv preprint arXiv:2508.05606 (2025)
-
[39]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchi- cal text-conditional image generation with clip latents. arXiv preprint arXiv:2204.061251(2), 3 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[40]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High- resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[41]
Advances in neural information processing systems35, 36479– 36494 (2022)
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text-to-image diffusion models with deep language under- standing. Advances in neural information processing systems35, 36479– 36494 (2022)
2022
-
[42]
Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model
Shi, Q., Bai, J., Zhao, Z., Chai, W., Yu, K., Wu, J., Song, S., Tong, Y., Li, X., Li, X., et al.: Muddit: Liberating generation beyond text-to-image with a unified discrete diffusion model. arXiv:2505.23606 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
In: Proceedings of the 32nd International Conference on Machine Learning
Sohl-Dickstein,J.,Weiss,E.A.,Maheswaranathan,N.,Ganguli,S.:Deepun- supervised learning using nonequilibrium thermodynamics. In: Proceedings of the 32nd International Conference on Machine Learning. pp. 2256–2265 (2015)
2015
-
[44]
Advances in neural information processing systems34, 1415–1428 (2021) UniCanvas: Diffusion-base Unified Model for Text-in-Image Joint Generation 27
Song, Y., Durkan, C., Murray, I., Ermon, S.: Maximum likelihood training of score-based diffusion models. Advances in neural information processing systems34, 1415–1428 (2021) UniCanvas: Diffusion-base Unified Model for Text-in-Image Joint Generation 27
2021
-
[45]
Score-Based Generative Modeling through Stochastic Differential Equations
Song,Y.,Sohl-Dickstein,J.,Kingma,D.P.,Kumar,A.,Ermon,S.,Poole,B.: Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[46]
Generation Enhances Understanding in Unified Multimodal Models via Multi-Representation Generation
Su, Z., Wei, H., Cen, K., Wang, Y., Chen, G., Yuan, C., Chu, X.: Gen- eration enhances understanding in unified multimodal models via multi- representation generation. arXiv preprint arXiv:2601.21406 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Team, C.: Chameleon: Mixed-modal early-fusion foundation models, 2024. URL https://arxiv. org/abs/2405.098189(8) (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Next-Latent Prediction Transformers Learn Compact World Models
Teoh, J., Tomar, M., Ahn, K., Hu, E.S., Sharma, P., Islam, R., Lamb, A., Langford, J.: Next-latent prediction transformers learn compact world models. arXiv preprint arXiv:2511.05963 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
arXiv preprint arXiv:2401.10208 (2024)
Tian, C., Zhu, X., Xiong, Y., Wang, W., Chen, Z., Wang, W., Chen, Y., Lu, L., Lu, T., Zhou, J., et al.: Mm-interleaved: Interleaved image-text generative modeling via multi-modal feature synchronizer. arXiv preprint arXiv:2401.10208 (2024)
-
[50]
MetaMorph: Multimodal Understanding and Generation via Instruction Tuning
Tong, S., Fan, D., Zhu, J., Xiong, Y., Chen, X., Sinha, K., Rabbat, M., LeCun, Y., Xie, S., Liu, Z.: Metamorph: Multimodal understanding and generation via instruction tuning. arXiv preprint arXiv:2412.14164 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
arXiv preprint arXiv:2602.01382 (2026)
Wang,F.Y.,Zhang,H.,Gharbi,M.,Li,H.,Park,T.:Promptrl:Promptmat- ters in rl for flow-based image generation. arXiv preprint arXiv:2602.01382 (2026)
-
[52]
Wang, J., Lai, Y., Li, A., Zhang, S., Sun, J., Kang, N., Wu, C., Li, Z., Luo, P.: Fudoki: Discrete flow-based unified understanding and generation via kinetic-optimal velocities. arXiv:2505.20147 (2025)
-
[53]
arXiv preprint arXiv:2411.07199 (2024)
Wei, C., Xiong, Z., Ren, W., Du, X., Zhang, G., Chen, W.: Omniedit: Build- ing image editing generalist models through specialist supervision. arXiv preprint arXiv:2411.07199 (2024)
-
[54]
arXiv preprint arXiv:2601.19834 (2026)
Wu, J., Zhang, X., Yuan, H., Zhang, X., Huang, T., He, C., Deng, C., Zhang, R., Wu, Y., Long, M.: Visual generation unlocks human-like rea- soning through multimodal world models. arXiv preprint arXiv:2601.19834 (2026)
-
[55]
arXiv preprint arXiv:2407.01863 (2024)
Wu, Q., Zhao, H., Saxon, M., Bui, T., Wang, W.Y., Zhang, Y., Chang, S.: Vsp: Assessing the dual challenges of perception and reasoning in spatial planning tasks for vlms. arXiv preprint arXiv:2407.01863 (2024)
-
[56]
VILA-U: a Unified Foundation Model Integrating Visual Understanding and Generation
Wu, Y., Zhang, Z., Chen, J., Tang, H., Li, D., Fang, Y., Zhu, L., Xie, E., Yin, H., Yi, L., et al.: Vila-u: a unified foundation model integrating visual understanding and generation. arXiv preprint arXiv:2409.04429 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
arXiv preprint arXiv:2505.13031 (2025)
Xiao, Y., Song, L., Chen, Y., Luo, Y., Chen, Y., Gan, Y., Huang, W., Li, X., Qi, X., Shan, Y.: Mindomni: Unleashing reasoning generation in vision language models with rgpo. arXiv preprint arXiv:2505.13031 (2025)
-
[58]
In: The Thirteenth International Conference on Learning Representations (2025)
Xie, J., Mao, W., Bai, Z., Zhang, D.J., Wang, W., Lin, K.Q., Gu, Y., Chen, Z., Yang, Z., Shou, M.Z.: Show-o: One single transformer to unify mul- timodal understanding and generation. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[59]
arXiv preprint arXiv:2505.11409 (2025) 28 Z
Xu, Y., Li, C., Zhou, H., Wan, X., Zhang, C., Korhonen, A., Vulić, I.: Visual planning: Let’s think only with images. arXiv preprint arXiv:2505.11409 (2025) 28 Z. Yang et al
-
[60]
MMaDA: Multimodal Large Diffusion Language Models
Yang, L., Tian, Y., Li, B., Zhang, X., Shen, K., Tong, Y., Wang, M.: Mmada: Multimodal large diffusion language models. arXiv preprint arXiv:2505.15809 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
arXiv preprint arXiv:2507.12508 (2025)
Yang, Y., Liu, J., Zhang, Z., Zhou, S., Tan, R., Yang, J., Du, Y., Gan, C.: Mindjourney: Test-time scaling with world models for spatial reasoning. arXiv preprint arXiv:2507.12508 (2025)
-
[62]
Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens
Yang, Z., Yu, X., Chen, D., Shen, M., Gan, C.: Machine mental imagery: Empower multimodal reasoning with latent visual tokens. arXiv preprint arXiv:2506.17218 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Ye, S., Ge, Y., Zheng, K., Gao, S., Yu, S., Kurian, G., Indupuru, S., Tan, Y.L., Zhu, C., Xiang, J., Malik, A., Lee, K., Liang, W., Ranawaka, N., Gu, J., Xu, Y., Wang, G., Hu, F., Narayan, A., Bjorck, J., Wang, J., Kim, G., Niu, D., Zheng, R., Xie, Y., Wu, J., Wang, Q., Julian, R., Xu, D., Du, Y., Chebotar, Y., Reed, S., Kautz, J., Zhu, Y., Fan, L.J., Jan...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[64]
arXiv preprint arXiv:2511.22625 (2025)
Yin, F., Liu, S., Han, Y., Wang, Z., Xing, P., Wang, R., Cheng, W., Wang, Y., Li, A., Yin, Z., et al.: Reasonedit: Towards reasoning-enhanced image editing models. arXiv preprint arXiv:2511.22625 (2025)
-
[65]
In: Proceedings of the 33rd ACM International Conference on Mul- timedia
Zeng, B., Yang, L., Liu, J., Xu, M., Zhang, Y., Wan, P., Zhang, W., Yan, S.: Editworld: Simulating world dynamics for instruction-following image editing. In: Proceedings of the 33rd ACM International Conference on Mul- timedia. pp. 12674–12681 (2025)
2025
-
[66]
In: CVPR (2018)
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreason- able effectiveness of deep features as a perceptual metric. In: CVPR (2018)
2018
-
[67]
arXiv preprint arXiv:2602.12322 (2026)
Zhang, Z., Yang, S., Hu, Q., Huang, L.J., Hou, J., Sun, Y., Lu, Y., Han, S.: Foreact: Steering your vla with efficient visual foresight planning. arXiv preprint arXiv:2602.12322 (2026)
-
[68]
3D-VLA: A 3D Vision-Language-Action Generative World Model
Zhen, H., Qiu, X., Chen, P., Yang, J., Yan, X., Du, Y., Hong, Y., Gan, C.: 3d-vla: A 3d vision-language-action generative world model. arXiv preprint arXiv:2403.09631 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[69]
arXiv preprint arXiv:2504.20995 (2025)
Zhen, H., Sun, Q., Zhang, H., Li, J., Zhou, S., Du, Y., Gan, C.: Tesser- act: Learning 4d embodied world models. arXiv preprint arXiv:2504.20995 (2025)
-
[70]
In: The Thirteenth Inter- national Conference on Learning Representations (2025)
Zhou, C., Yu, L., Babu, A., Tirumala, K., Yasunaga, M., Shamis, L., Kahn, J., Ma, X., Zettlemoyer, L., Levy, O.: Transfusion: Predict the next token and diffuse images with one multi-modal model. In: The Thirteenth Inter- national Conference on Learning Representations (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.