How Much Due Diligence Before You Bid? Learning in Intractable Takeover Auctions
Pith reviewed 2026-06-30 07:00 UTC · model grok-4.3
The pith
In takeover auctions the optimal amount of due diligence is modest and finite, falling with its cost and with competition from the other bidder.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
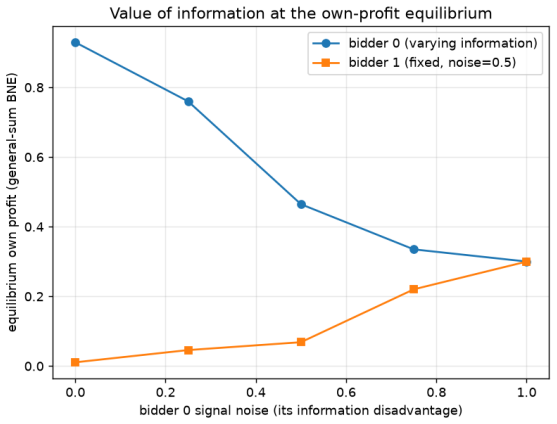
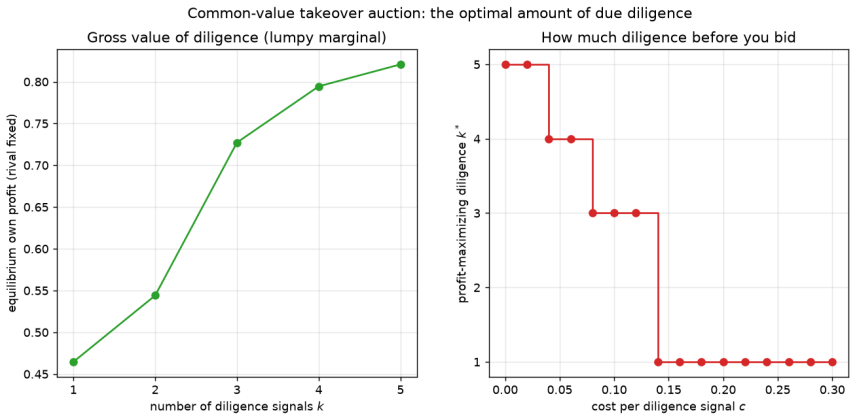
In a self-play model of takeover auctions whose complexity is governed by the number of private information pieces each bidder holds, the equilibrium level of due diligence is modest and finite. This level declines as the cost of diligence rises and declines further when both bidders acquire information, since competition reduces the marginal value of a superior estimate.
What carries the argument
A self-play bidding game parameterized by the number of private information pieces each bidder holds.
If this is right
- As the cost of diligence increases, bidders purchase fewer signals in equilibrium.
- When both bidders acquire information, each purchases less than it would against an uninformed rival.
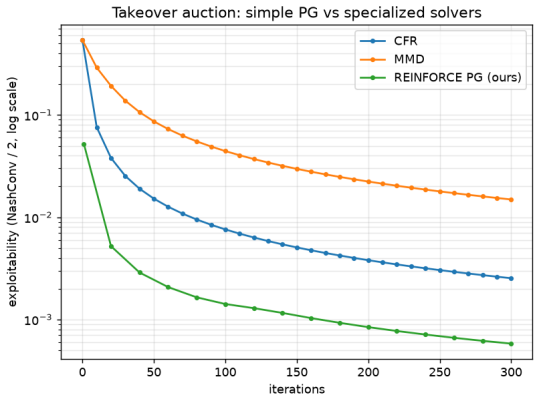
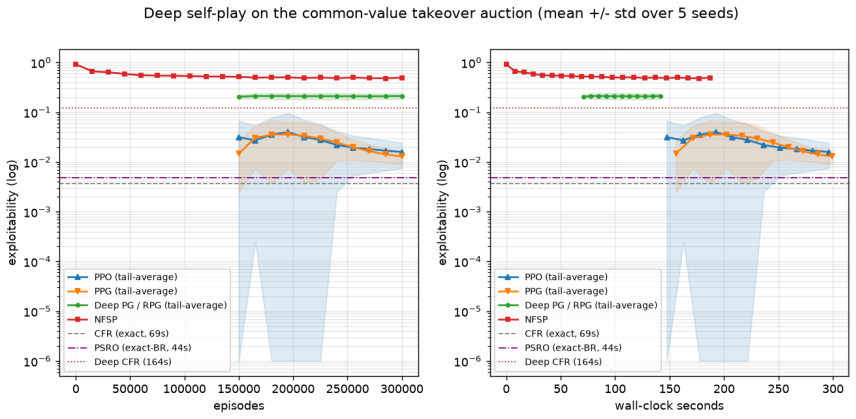
- Simple self-play methods produce strong bidding strategies once the game grows too large for exact solution.
- The model supplies a reproducible method for quantifying the value of private information in deal-making.
Where Pith is reading between the lines
- If the model is accurate, firms may be spending more on due diligence than is privately optimal in low-competition deals.
- The result suggests that greater mandatory disclosure of target information could reduce private diligence spending.
- Extending the setup to three or more bidders would likely show even lower optimal diligence levels.
- Historical bid data could be used to test whether real bidders stop acquiring information at roughly the model's predicted thresholds.
Load-bearing premise
The simple computer model of the bidding contest controlled by the number of pieces of private information accurately captures the economic incentives and information structure of real takeover auctions.
What would settle it
A comparison of the model's predicted optimal diligence quantities against observed due diligence expenditures in actual completed takeover deals, for varying costs and numbers of bidders.
Figures
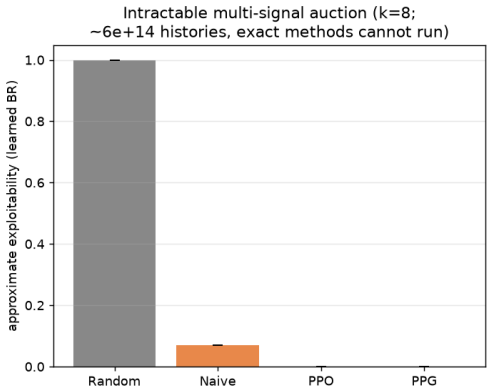
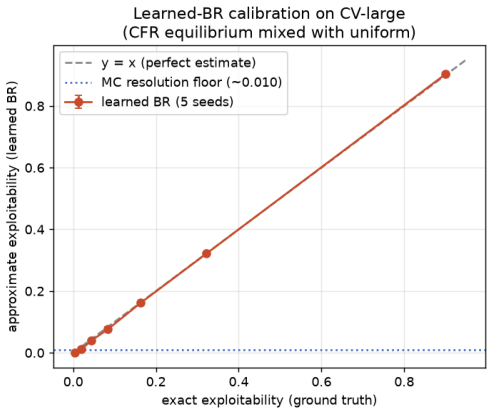
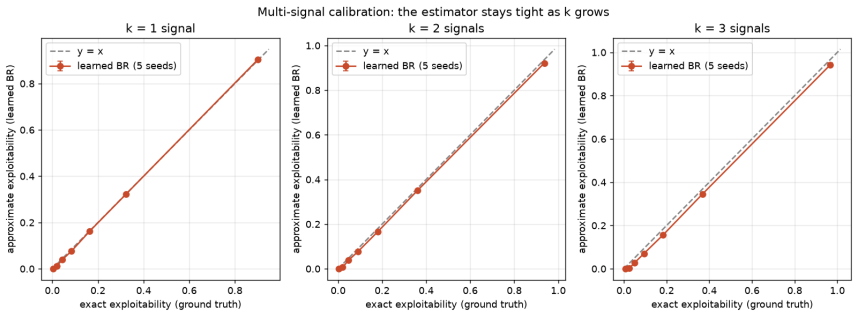
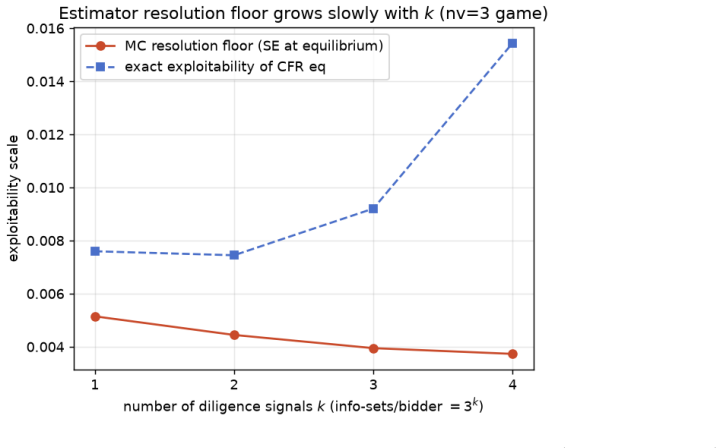
read the original abstract
When two companies bid to buy the same target, no one knows exactly what the target is worth. Each bidder pays for due diligence: costly, imperfect homework that sharpens its own private estimate before it bids. How much of that homework is worth buying? We build a simple computer model of the bidding contest and let it teach itself to bid well by playing against itself, the way a game engine learns chess. The economic question, how much diligence pays for itself, and the computational question, when the contest becomes too complex to solve exactly, are both controlled by a single thing: how many pieces of private information a bidder carries. Our main finding is that the right amount of diligence is modest and finite. It falls as diligence gets more expensive, and it falls further when both sides are doing their homework, because competition erodes the value of knowing more. We also test a recent claim from AI research: that simple, general self-play methods can rival the specialized, expensive algorithms usually built for games like these. Running on an ordinary laptop with no costly frontier AI, we find the simple methods are the best of the self-learning approaches, though purpose-built exact methods still win whenever the game is small enough to solve outright. The simple methods earn their keep only once the game grows too large to solve exactly, which is the regime real deals live in, and there we show they still find strong bidding strategies. The contribution is threefold: a cheap, reproducible way to study deal-making under uncertainty; a concrete, model-based answer to how much due diligence is worth buying; and evidence about when lightweight, general-purpose AI is good enough to replace specialized methods. We release all the games, code, and experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a computational model of takeover auctions where two bidders acquire costly private information (parameterized by the number of independent 'pieces of private information') before bidding on a target of uncertain value. Bidding strategies are learned via self-play reinforcement learning. The central claims are that the optimal diligence level is modest and finite, declines with higher diligence costs, and declines further under bilateral diligence because competition erodes the marginal value of additional information. The paper also reports that simple general-purpose self-play methods perform well relative to specialized algorithms once games become too large for exact solution, and releases all code, games, and experiments for reproducibility.
Significance. If the results hold under the modeling assumptions, the work supplies a reproducible, simulation-based approach to quantifying the value of due diligence in auctions and provides evidence on the regime where lightweight self-play suffices for intractable economic games. The explicit release of code and experiments is a clear strength that supports verification and extension.
major comments (2)
- [Abstract / Model Description] Abstract and model description: the central quantitative claim (optimal diligence is modest/finite and falls with cost or bilateral effort) is controlled entirely by the discrete count of independent private signals. No calibration, mapping to real M&A information structures (correlated signals, multi-dimensional reviews, or diminishing returns), or sensitivity checks to alternative information models are reported; if the marginal value of information differs under those structures, both the 'modest' optimum and the 'erosion by competition' result could shift substantially.
- [Results / Experiments] Results on self-play performance: the claim that simple methods are the best among self-learning approaches and remain strong in the intractable regime rests on simulation outcomes, yet the abstract (and by extension the reported findings) provides no details on the precise training procedure, number of runs, statistical tests, or robustness to hyperparameters; without these, the performance comparison cannot be verified as load-bearing.
minor comments (1)
- [Abstract] The abstract states main findings from simulation without referencing any specific equations, tables, or robustness checks; adding one sentence pointing to the relevant methods subsection would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the modeling assumptions and experimental reporting. We address each major point below and outline planned revisions.
read point-by-point responses
-
Referee: [Abstract / Model Description] Abstract and model description: the central quantitative claim (optimal diligence is modest/finite and falls with cost or bilateral effort) is controlled entirely by the discrete count of independent private signals. No calibration, mapping to real M&A information structures (correlated signals, multi-dimensional reviews, or diminishing returns), or sensitivity checks to alternative information models are reported; if the marginal value of information differs under those structures, both the 'modest' optimum and the 'erosion by competition' result could shift substantially.
Authors: Our model parameterizes due diligence via the discrete count of independent private signals to enable controlled variation of information levels while remaining computationally feasible for self-play learning. This isolates the effects of cost and bilateral competition on optimal diligence. We acknowledge that alternative structures (e.g., correlated signals or diminishing returns) could alter quantitative results, and no calibration to empirical M&A data is provided. The released code and games are intended to support such extensions by others. In revision we will add an explicit limitations paragraph discussing this modeling choice and its scope. revision: partial
-
Referee: [Results / Experiments] Results on self-play performance: the claim that simple methods are the best among self-learning approaches and remain strong in the intractable regime rests on simulation outcomes, yet the abstract (and by extension the reported findings) provides no details on the precise training procedure, number of runs, statistical tests, or robustness to hyperparameters; without these, the performance comparison cannot be verified as load-bearing.
Authors: The full manuscript describes the self-play methods employed, and the complete training code, game instances, and experiment logs are released publicly to enable verification and reproduction. To strengthen the paper, we will insert a concise methods subsection (or appendix) summarizing the training procedure, number of runs, hyperparameter ranges, and any robustness checks performed. revision: yes
Circularity Check
No circularity: simulation outcomes from explicit model parameterization
full rationale
The paper defines a computational model in which diligence is controlled by the discrete count of private information pieces, then reports outcomes from self-play simulations under varying costs and bilateral effort. These results are direct consequences of running the specified model rather than algebraic reductions, fitted parameters renamed as predictions, or load-bearing self-citations. No quoted step exhibits a definitional loop or imported uniqueness theorem; the derivation chain remains self-contained within the stated simulation framework.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of pieces of private information
axioms (1)
- domain assumption Self-play reinforcement learning produces strong bidding strategies in this auction game.
Reference graph
Works this paper leans on
-
[1]
Deep Counterfactual Regret Minimization
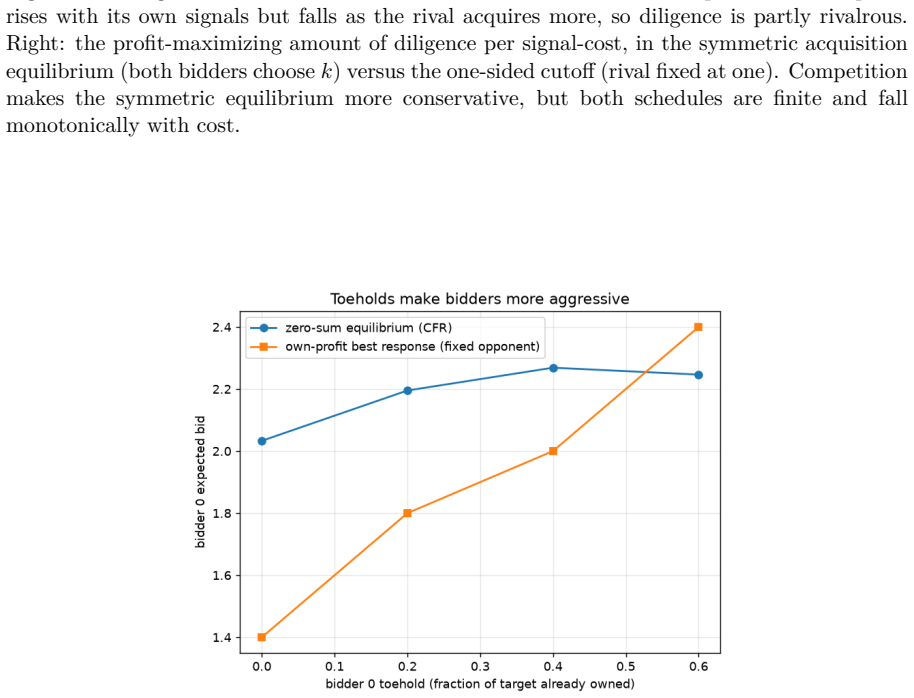
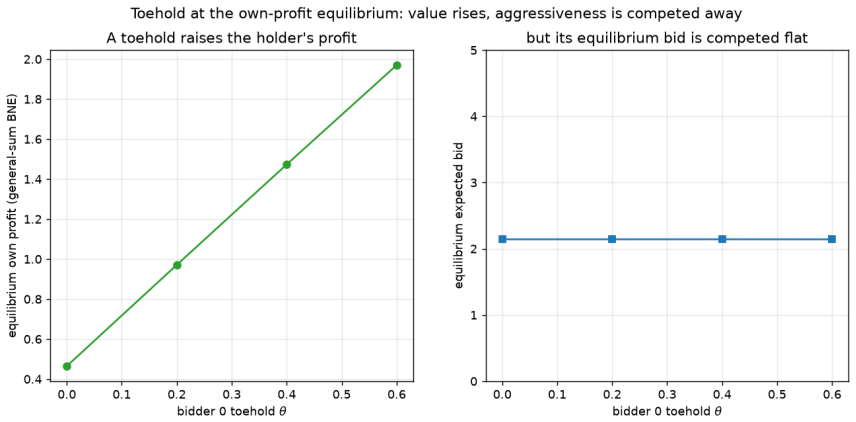
arXiv:1811.00164. Noam Brown, Anton Bakhtin, Adam Lerer, and Qucheng Gong. Combining deep reinforcement 15 Figure7: Valueofinformationatthegenuineown-profitBayes-Nashequilibrium(solvedexactly, §4), not the zero-sum rendering. As bidder 0’s signal noise rises (bidder 1 fixed at noise0.5), bidder 0’s equilibrium own profit falls and the better-informed riva...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Jeremy Bulow, Ming Huang, and Paul Klemperer
arXiv:2007.13544. Jeremy Bulow, Ming Huang, and Paul Klemperer. Toeholds and takeovers.Journal of Political Economy, 107(3):427–454,
-
[3]
Multi-issue bargaining with deep reinforcement learning.arXiv preprint arXiv:2002.07788,
Ho-Chun Herbert Chang. Multi-issue bargaining with deep reinforcement learning.arXiv preprint arXiv:2002.07788,
-
[4]
Olivier Compte and Philippe Jehiel
arXiv:2009.04416. Olivier Compte and Philippe Jehiel. Auctions and information acquisition: Sealed Bid or Dynamic Formats?RAND Journal of Economics, 38(2):355–372,
- [5]
-
[6]
Bayesian
John C. Harsanyi. Games with incomplete information played by “Bayesian” players, I–III. Management Science, 14:159–182, 320–334, 486–502, 1967–1968. Johannes Heinrich and David Silver. Deep reinforcement learning from self-play in imperfect-information games. InNIPS 2016 Deep Reinforcement Learning Workshop,
1967
-
[7]
Deep Reinforcement Learning from Self-Play in Imperfect-Information Games
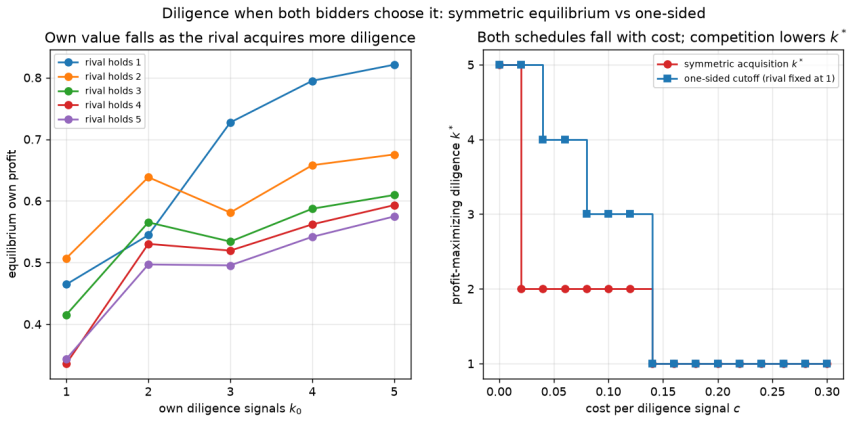
arXiv:1603.01121. 16 Figure 8: How much due diligence, in the base game (five values, six bids, noise0.5). Left: bidder 0’s equilibrium own profit as it acquires more independent diligence signalsk(rival fixed at one signal), rising with a lumpy marginal. Right: with a per-signal diligence costc, the profit- maximizing amount of diligencek⋆ = arg max k[va...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Marc Lanctot, Kevin Waugh, Martin Zinkevich, and Michael Bowling
arXiv:2303.09500. Marc Lanctot, Kevin Waugh, Martin Zinkevich, and Michael Bowling. Monte carlo sampling for regret minimization in extensive games. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[9]
A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning
arXiv:1711.00832. Marc Lanctot, Edward Lockhart, Jean-Baptiste Lespiau, et al. Openspiel: A framework for reinforcement learning in games.arXiv preprint arXiv:1908.09453,
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[10]
Stephen McAleer, Gabriele Farina, Marc Lanctot, and Tuomas Sandholm
arXiv:1903.05614. Stephen McAleer, Gabriele Farina, Marc Lanctot, and Tuomas Sandholm. ESCHER: Eschewing importance sampling in games by computing a history value function to estimate regret. In International Conference on Learning Representations (ICLR),
-
[11]
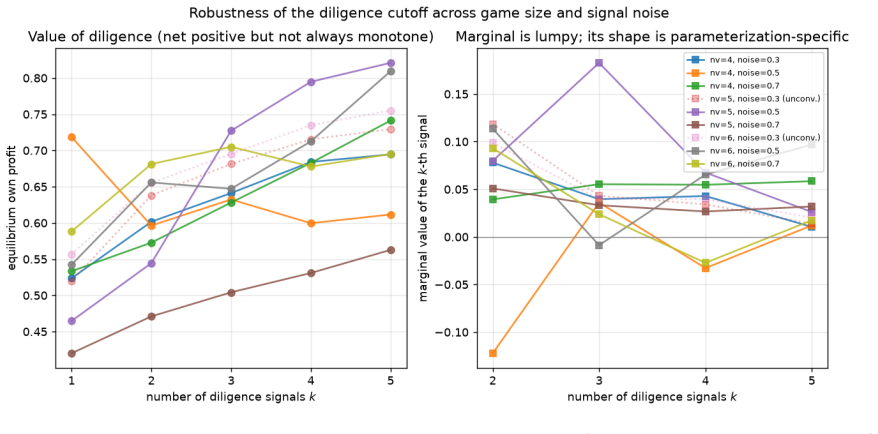
arXiv:2206.04122. 17 Figure 9: Robustness of the diligence cutoff across game sizes (four, five, six common values) and signal qualities (noise0.3,0.5,0.7); dotted lines are parameterizations the fictitious-play solver did not bring to tolerance and are excluded from the counts. Left: the value of diligence is positive on net but not always monotone ink. ...
-
[12]
Reevaluating Policy Gradient Methods for Imperfect-Information Games
arXiv:2502.08938. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Eric Steinberger, Adam Lerer, and Noam Brown
arXiv:2206.05825. Eric Steinberger, Adam Lerer, and Noam Brown. DREAM: Deep regret minimization with advantage baselines and model-free learning.arXiv preprint arXiv:2006.10410,
-
[14]
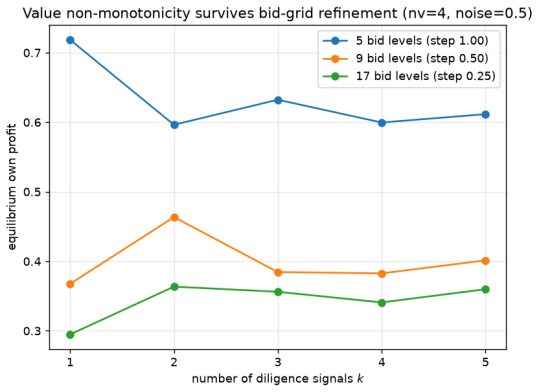
arXiv:2004.09677. 18 Figure 10: The value non-monotonicity is a bid-grid artifact. Re-solving a non-monotone ro- bustness cell (four values, noise0.5) with the bid grid refined from5to9and17levels over the same bid range: the coarse-grid decline fromk= 1tok= 2reverses into an increase once the grid is refined, so “more signals lower profit” does not survi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.