Token-Sparse Medical Multimodal Reasoning via Dual-Stream Reinforcement Learning
Pith reviewed 2026-07-01 05:34 UTC · model grok-4.3
The pith
Dual-stream reinforcement learning prunes visual tokens in medical VLMs to 77% of original length while exceeding baseline performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
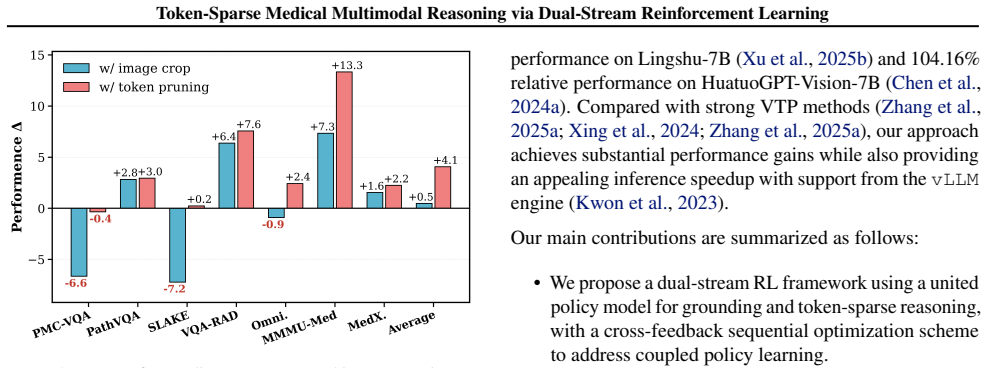
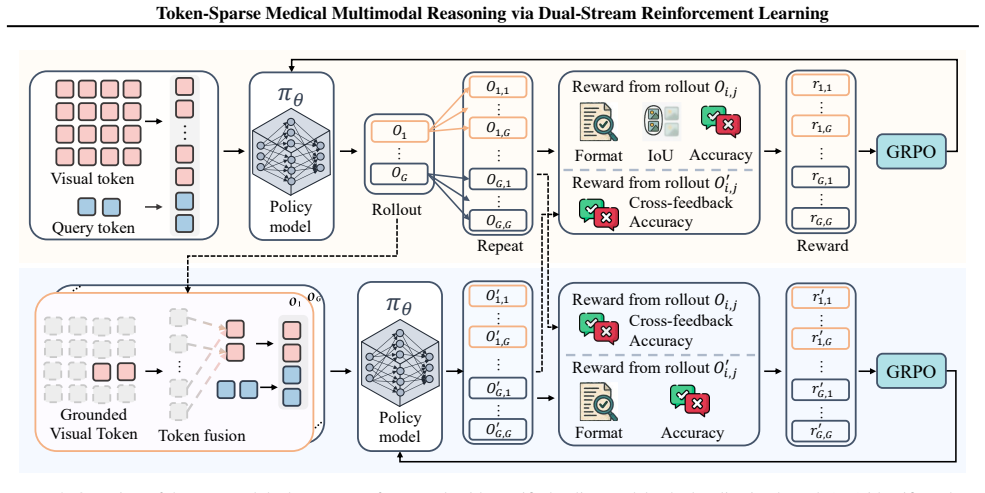
ViToS trains one policy model with two task branches, where one focuses on grounding while the other conducts token-sparse reasoning after visual token pruning. The coupled policy learning problem is solved by introducing cross-feedback sequential optimization, avoiding gradient conflict and facilitating convergence. Evaluated on seven medical benchmarks, the method reduces visual tokens to 77% of the original sequence length while achieving a 108.27% relative performance on Lingshu-7B and 104.16% relative performance on HuatuoGPT-Vision-7B.
What carries the argument
Dual-stream RL framework with cross-feedback sequential optimization on a shared policy model for visual token pruning (VTP) and question answering.
If this is right
- Reduces visual tokens to 77% of original sequence length.
- Achieves superior performance and inference speedup on medical multimodal reasoning.
- Delivers 108.27% relative performance on Lingshu-7B across benchmarks.
- Delivers 104.16% relative performance on HuatuoGPT-Vision-7B.
- Establishes an efficient paradigm for medical multimodal reasoning.
Where Pith is reading between the lines
- This approach could extend to non-medical VLMs where visual evidence is sparse, such as in document understanding or scientific image analysis.
- The token reduction might enable deployment of medical reasoning models on resource-constrained devices.
- Further work could explore combining this with other pruning techniques for even greater efficiency.
Load-bearing premise
A single shared policy model can handle both grounding and token-sparse reasoning through cross-feedback sequential optimization without causing gradient conflicts or losing critical clinical information.
What would settle it
Testing the shared policy model on the medical benchmarks and observing either performance below 100% relative or failure to converge due to gradient conflicts would falsify the central claim.
Figures

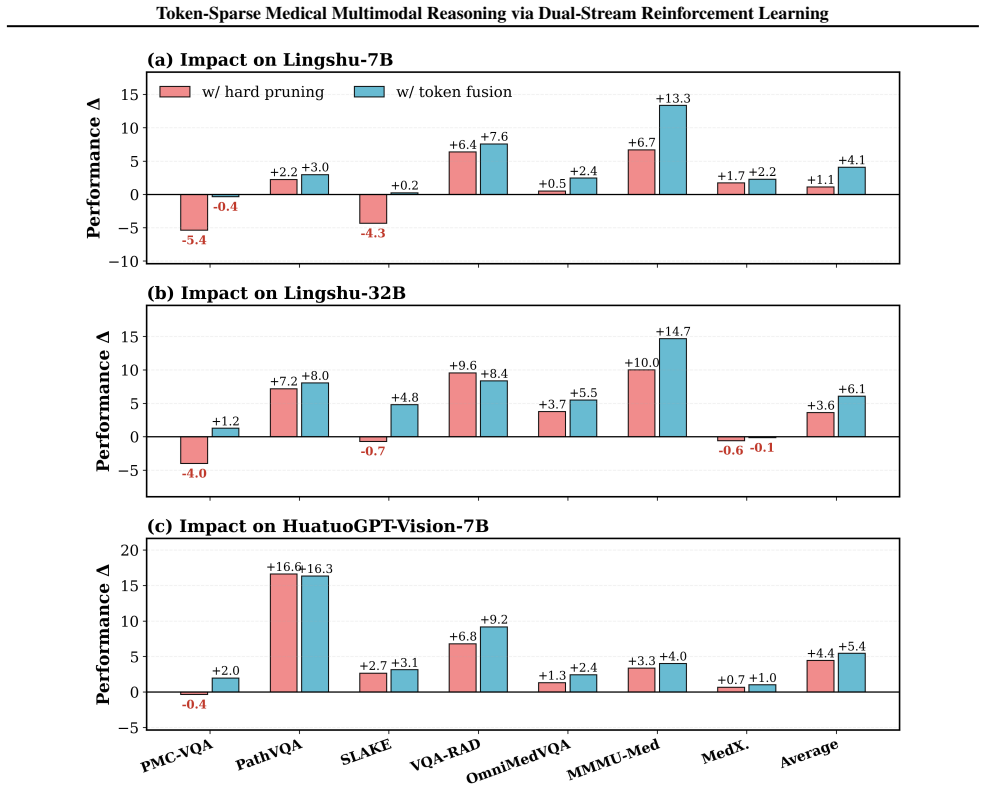
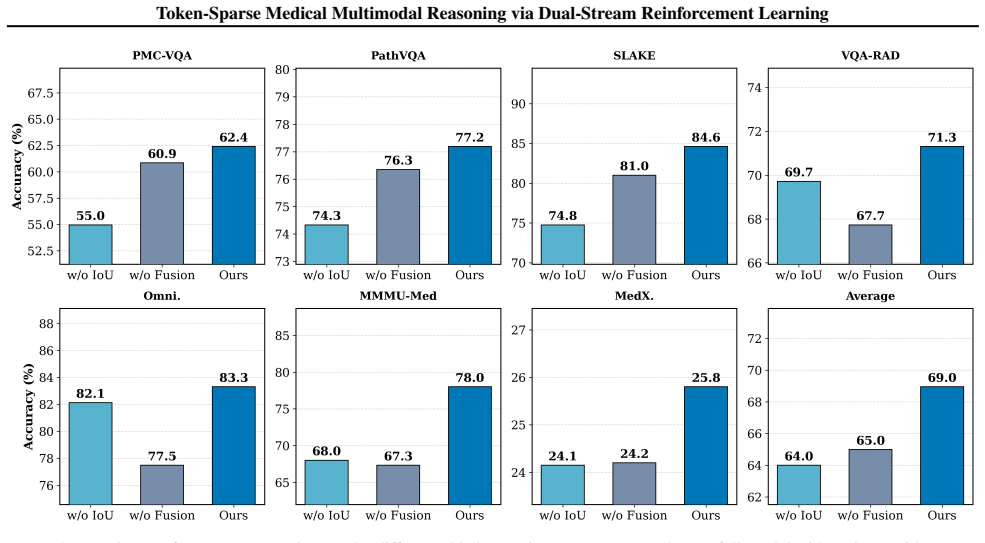






read the original abstract
Vision-language models (VLMs) combining reinforcement learning (RL) ignite remarkable progress in multimodal reasoning, yet still struggle with medical images, which typically exhibit extremely sparse visual evidence to inform clinical decision-making. We recognize that pruning visual tokens outside the grounding region greatly enhances medical reasoning. However, a united RL framework for active visual token pruning (VTP) and medical multimodal reasoning remains unestablished. Here, we propose a dual-stream RL framework, ViToS, to fulfill token pruning and question answering. ViToS trains one policy model with two task branches, where one focuses on grounding while the other conducts token-sparse reasoning after VTP. Furthermore, we solve the coupled policy learning problem by introducing the cross-feedback sequential optimization, avoiding gradient conflict and facilitating convergence of the shared policy model. Evaluated on seven medical benchmarks, our method reduces visual tokens to 77% of the original sequence length while achieving a 108.27% relative performance on Lingshu-7B and 104.16% relative performance on HuatuoGPT-Vision-7B. Overall, ViToS delivers superior performance and inference speedup, establishing an efficient paradigm for medical multimodal reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ViToS, a dual-stream RL framework for medical multimodal reasoning in VLMs. It trains a single shared policy model with separate branches for visual grounding and token-sparse reasoning after active visual token pruning (VTP), using cross-feedback sequential optimization to manage the coupled tasks. On seven medical benchmarks the method is reported to reduce visual tokens to 77% of the original length while delivering relative performance of 108.27% on Lingshu-7B and 104.16% on HuatuoGPT-Vision-7B, together with inference speedup.
Significance. If the empirical claims are supported by complete, reproducible experimental evidence, the work would demonstrate a practical route to efficient medical VLM reasoning by discarding tokens outside clinically relevant regions, potentially improving both accuracy and speed in evidence-sparse domains.
major comments (2)
- [Abstract] Abstract: the central performance claims rest on relative percentages (108.27% and 104.16%) and a 77% token-reduction figure, yet no absolute baseline scores, standard deviations, error bars, or statistical tests are supplied. Without these quantities the data cannot be assessed for support of the superiority claim.
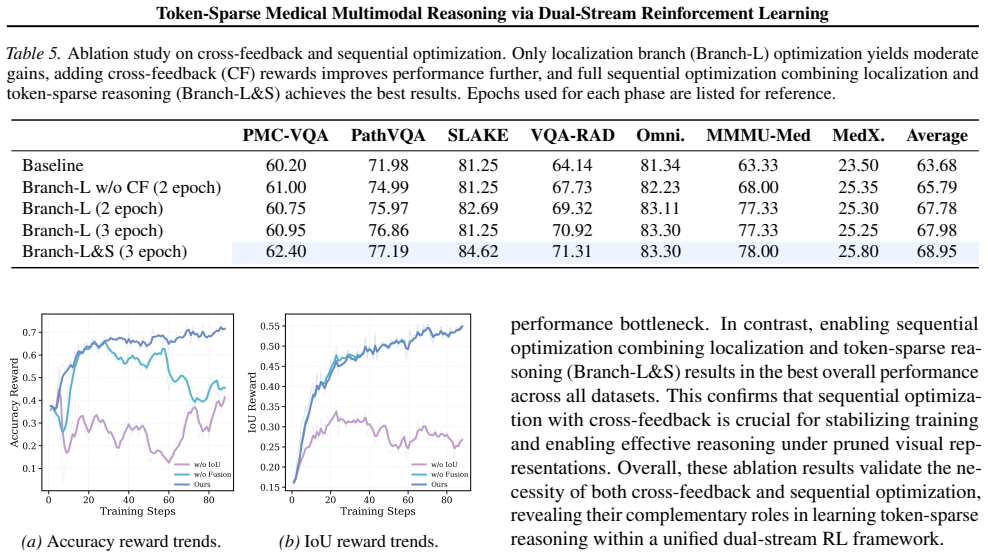
- [Method] Method section (cross-feedback sequential optimization): the shared-policy construction is presented as solving gradient conflict between grounding and reasoning branches, but no analysis, loss curves, or ablation isolating the cross-feedback mechanism is referenced to confirm absence of conflict or preservation of clinically critical information.
minor comments (1)
- Clarify the precise definition and computation of 'relative performance' (e.g., relative to which base model and on which metric) so that the reported percentages can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims rest on relative percentages (108.27% and 104.16%) and a 77% token-reduction figure, yet no absolute baseline scores, standard deviations, error bars, or statistical tests are supplied. Without these quantities the data cannot be assessed for support of the superiority claim.
Authors: We agree that absolute scores and statistical details would aid assessment. In the revised manuscript we will expand the abstract to report the absolute baseline and ViToS scores on all seven benchmarks together with standard deviations from repeated runs. revision: yes
-
Referee: [Method] Method section (cross-feedback sequential optimization): the shared-policy construction is presented as solving gradient conflict between grounding and reasoning branches, but no analysis, loss curves, or ablation isolating the cross-feedback mechanism is referenced to confirm absence of conflict or preservation of clinically critical information.
Authors: We acknowledge that explicit validation of the cross-feedback mechanism is currently absent. We will add an ablation comparing training with and without cross-feedback, together with loss curves and grounding-accuracy metrics, to demonstrate convergence behavior and retention of clinically relevant tokens. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical method (dual-stream RL with cross-feedback optimization for visual token pruning and reasoning) whose central claims are performance numbers obtained from evaluation on seven external medical benchmarks. No derivation, equation, or uniqueness theorem is shown that reduces by construction to fitted inputs, self-definitions, or a self-citation chain; the token-reduction and relative-performance figures are reported outcomes rather than predictions forced by the method's own parameters.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pruning visual tokens outside the grounding region greatly enhances medical reasoning
Reference graph
Works this paper leans on
-
[1]
Data-Centric Foundation Models in Computational Healthcare: A Survey
Data-centric foundation models in computational healthcare: A survey , author=. arXiv preprint arXiv:2401.02458 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Advances in Neural Information Processing Systems , volume=
Visual instruction tuning , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Machine Learning for Health , pages=
Med-flamingo: a multimodal medical few-shot learner , author=. Machine Learning for Health , pages=
-
[4]
Advances in Neural Information Processing Systems , volume=
Llava-med: Training a large language-and-vision assistant for biomedicine in one day , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
Huatuogpt-vision, towards injecting medical visual knowledge into multimodal llms at scale , author=. arXiv preprint arXiv:2406.19280 , year=
-
[6]
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning , author=. arXiv preprint arXiv:2506.07044 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
International Joint Conference on Neural Networks , pages=
R-llava: Improving med-vqa understanding through visual region of interest , author=. International Joint Conference on Neural Networks , pages=. 2025 , organization=
2025
-
[8]
arXiv preprint arXiv:2408.02900 , year=
Medtrinity-25m: A large-scale multimodal dataset with multigranular annotations for medicine , author=. arXiv preprint arXiv:2408.02900 , year=
-
[9]
Hulu-med: A transparent generalist model towards holistic medical vision-language understanding , author=. arXiv preprint arXiv:2510.08668 , year=
-
[10]
arXiv preprint arXiv:2505.18503 , year=
Focus on What Matters: Enhancing Medical Vision-Language Models with Automatic Attention Alignment Tuning , author=. arXiv preprint arXiv:2505.18503 , year=
-
[11]
Neural computation , volume=
Adaptive mixtures of local experts , author=. Neural computation , volume=
-
[12]
Nature , volume=
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author=. Nature , volume=
-
[13]
arXiv preprint arXiv:2503.01773 , year=
Why is spatial reasoning hard for vlms? an attention mechanism perspective on focus areas , author=. arXiv preprint arXiv:2503.01773 , year=
-
[14]
arXiv preprint arXiv:2503.13939 , year=
Med-r1: Reinforcement learning for generalizable medical reasoning in vision-language models , author=. arXiv preprint arXiv:2503.13939 , year=
-
[15]
International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=
Medvlm-r1: Incentivizing medical reasoning capability of vision-language models (vlms) via reinforcement learning , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=. 2025 , organization=
2025
-
[16]
arXiv preprint arXiv:2510.10052 , year=
Think Twice to See More: Iterative Visual Reasoning in Medical VLMs , author=. arXiv preprint arXiv:2510.10052 , year=
-
[17]
International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=
Medground-r1: Advancing medical image grounding via spatial-semantic rewarded group relative policy optimization , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=. 2025 , organization=
2025
-
[18]
Llavanext: Improved reasoning, ocr, and world knowledge , author=
-
[19]
Advances in Neural Information Processing Systems , volume=
Dynamicvit: Efficient vision transformers with dynamic token sparsification , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Token Merging: Your ViT But Faster
Token merging: Your vit but faster , author=. arXiv preprint arXiv:2210.09461 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
European Conference on Computer Vision , pages=
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models , author=. European Conference on Computer Vision , pages=
-
[22]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Topv: Compatible token pruning with inference time optimization for fast and low-memory multimodal vision language model , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[23]
arXiv preprint arXiv:2112.07658 , year=
AdaViT: Adaptive tokens for efficient vision transformer , author=. arXiv preprint arXiv:2112.07658 , year=
-
[24]
arXiv preprint arXiv:2505.19536 , year=
FlowCut: Rethinking Redundancy via Information Flow for Efficient Vision-Language Models , author=. arXiv preprint arXiv:2505.19536 , year=
-
[25]
arXiv preprint arXiv:2602.03060 , year=
IVC-Prune: Revealing the Implicit Visual Coordinates in LVLMs for Vision Token Pruning , author=. arXiv preprint arXiv:2602.03060 , year=
-
[26]
arXiv preprint arXiv:2506.21873 , year=
Grounding-Aware Token Pruning: Recovering from Drastic Performance Drops in Visual Grounding Caused by Pruning , author=. arXiv preprint arXiv:2506.21873 , year=
-
[27]
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference
Sparsevlm: Visual token sparsification for efficient vision-language model inference , author=. arXiv preprint arXiv:2410.04417 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Llava-prumerge: Adaptive token reduction for efficient large multimodal models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[29]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Visionzip: Longer is better but not necessary in vision language models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[30]
arXiv preprint arXiv:2505.22654 , year=
VScan: Rethinking Visual Token Reduction for Efficient Large Vision-Language Models , author=. arXiv preprint arXiv:2505.22654 , year=
-
[31]
arXiv preprint arXiv:2507.13348 (2025)
Visionthink: Smart and efficient vision language model via reinforcement learning , author=. arXiv preprint arXiv:2507.13348 , year=
-
[32]
IEEE International Symposium on Biomedical Imaging , pages=
Slake: A semantically-labeled knowledge-enhanced dataset for medical visual question answering , author=. IEEE International Symposium on Biomedical Imaging , pages=. 2021 , organization=
2021
-
[33]
PathVQA: 30000+ Questions for Medical Visual Question Answering
Pathvqa: 30000+ questions for medical visual question answering , author=. arXiv preprint arXiv:2003.10286 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[34]
Scientific Data , volume=
A dataset of clinically generated visual questions and answers about radiology images , author=. Scientific Data , volume=
-
[35]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Omnimedvqa: A new large-scale comprehensive evaluation benchmark for medical lvlm , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[36]
PMC-VQA: Visual Instruction Tuning for Medical Visual Question Answering
Pmc-vqa: Visual instruction tuning for medical visual question answering , author=. arXiv preprint arXiv:2305.10415 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[38]
MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding
Medxpertqa: Benchmarking expert-level medical reasoning and understanding , author=. arXiv preprint arXiv:2501.18362 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction
Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction , author=. arXiv preprint arXiv:2410.17247 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Qwen2.5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models , author=. arXiv preprint arXiv:2504.10479 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Qwen2. 5 technical report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Qwen3-VL Technical Report , author=. arXiv preprint arXiv: 2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
arXiv preprint arXiv:2506.07851 , year=
Learning to Focus: Causal Attention Distillation via Gradient-Guided Token Pruning , author=. arXiv preprint arXiv:2506.07851 , year=
-
[45]
arXiv preprint arXiv:2505.19213 , year=
Improving Medical Reasoning with Curriculum-Aware Reinforcement Learning , author=. arXiv preprint arXiv:2505.19213 , year=
-
[46]
Proceedings of Symposium on Operating Systems Principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of Symposium on Operating Systems Principles , pages=
-
[47]
2024 , journal =
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
2024
-
[48]
Proceedings of the Annual Meeting of the Association for Computational Linguistics , pages=
Llamafactory: Unified efficient fine-tuning of 100+ language models , author=. Proceedings of the Annual Meeting of the Association for Computational Linguistics , pages=
-
[49]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[50]
arXiv preprint arXiv:2505.11404 , year=
Patho-R1: A Multimodal Reinforcement Learning-Based Pathology Expert Reasoner , author=. arXiv preprint arXiv:2505.11404 , year=
-
[51]
Self-Rewarding Vision-Language Model via Reasoning Decomposition
Self-rewarding vision-language model via reasoning decomposition , author=. arXiv preprint arXiv:2508.19652 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
arXiv preprint arXiv:2508.02669 , year=
Medvlthinker: Simple baselines for multimodal medical reasoning , author=. arXiv preprint arXiv:2508.02669 , year=
-
[54]
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Pixel reasoner: Incentivizing pixel-space reasoning with curiosity-driven reinforcement learning , author=. arXiv preprint arXiv:2505.15966 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning , author=. arXiv preprint arXiv:2505.14362 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[57]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[58]
M. J. Kearns , title =
-
[59]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[60]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[61]
Suppressed for Anonymity , author=
-
[62]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[63]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.