ArtiTwinSplat: Interactable Digital Twin Reconstruction via Gaussian Splatting from RGB-D videos
Pith reviewed 2026-06-25 23:42 UTC · model grok-4.3
The pith
ArtiTwinSplat builds articulated photo-realistic digital twins directly from RGB-D videos with no CAD models or annotations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
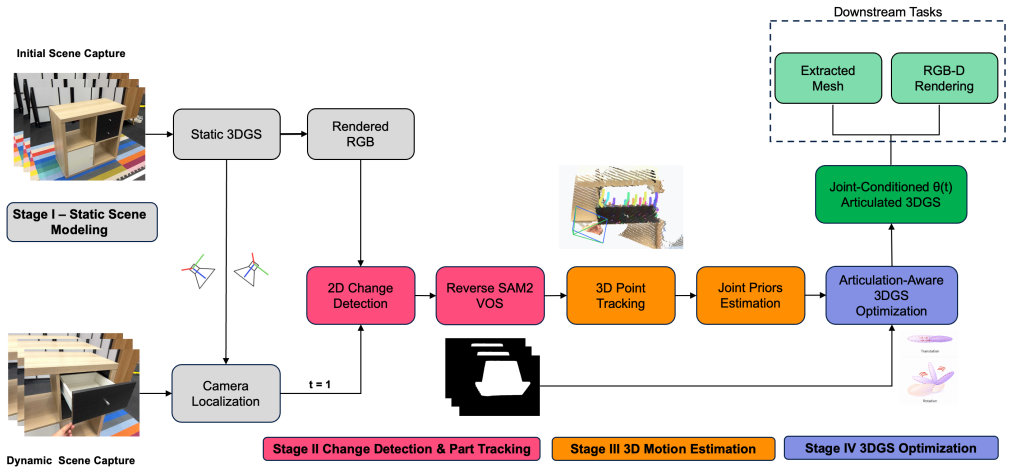
ArtiTwinSplat combines 3D Gaussian Splatting with an unsupervised articulation discovery pipeline to recover part structure and joint kinematics from observed motion alone in RGB-D videos, yielding stable, queryable digital twins that support real-time rendering, viewpoint control, and interactive manipulation without CAD models, simulation assets, or manual annotations.
What carries the argument
3D Gaussian Splatting coupled with an unsupervised articulation discovery pipeline that recovers part structure and joint kinematics from observed motion.
If this is right
- Digital twins become constructible automatically at scale from everyday real-world video observations.
- Twins remain stable and immediately usable by downstream robot planning and learning systems.
- Models support real-time rendering, viewpoint control, and interactive manipulation out of the box.
- The integration barrier drops for articulated object handling in embodied AI and human-robot settings.
Where Pith is reading between the lines
- Robot learning pipelines could incorporate these twins as drop-in environment models to reduce sim-to-real gaps.
- The same video-to-twin process might extend to multi-object scenes if motion separation improves.
- Deployment tests in varied lighting or partial occlusion would show whether the motion-based discovery holds up.
Load-bearing premise
An unsupervised pipeline can reliably recover part structure and joint kinematics from motion in real-world RGB-D videos without extra supervision.
What would settle it
A real-world RGB-D video sequence in which the recovered parts and joints produce a digital twin that fails to match observed object motion during interactive manipulation.
Figures


read the original abstract
Deploying robots in unstructured real-world environments needs accurate, interactive models of the objects. Constructing these models at scale remains a critical bottleneck for robotic system integration. We present ArtiTwinSplat, a framework that automatically constructs articulated, photo-realistic digital twins of objects directly from RGB-D videos, requiring no CAD models, simulation assets, or manual annotations. Our method is built on 3D Gaussian Splatting that preserve geometric fidelity and photometric realism, coupled with an unsupervised articulation discovery pipeline that recovers part structure and joint kinematics from observed motion alone. With tracking and optimization stages our method provides stable, queryable digital twins that support real-time rendering, viewpoint control, and interactive manipulation. Unlike prior methods confined to simulation, ArtiTwinSplat operates directly on real-world observations and produces twins that are immediately usable by downstream robot planning and learning systems. This method offers a practical, scalable pathway toward digital twin construction, lowering the integration barrier for articulated object manipulation in embodied AI and human-robot collaboration contexts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ArtiTwinSplat, a framework that automatically constructs articulated, photo-realistic digital twins of objects directly from RGB-D videos. It combines 3D Gaussian Splatting for geometric and photometric fidelity with an unsupervised articulation discovery pipeline that recovers part structure and joint kinematics from observed motion. The method requires no CAD models, simulation assets, or manual annotations, and after tracking and optimization stages produces stable, queryable twins supporting real-time rendering, viewpoint control, interactive manipulation, and use in downstream robot planning and learning systems.
Significance. If the central claims hold with supporting evidence, the work would address a key bottleneck in robotic integration by enabling scalable, annotation-free construction of interactive digital twins from real-world RGB-D data. This could meaningfully advance embodied AI and human-robot collaboration by lowering barriers to articulated object modeling, provided the unsupervised pipeline proves reliable across diverse objects and motions.
major comments (2)
- [Abstract] Abstract: The abstract asserts that the method works and produces usable twins but supplies no quantitative results, comparisons, error metrics, or validation details; central claims rest on unshown evidence.
- [Abstract] Abstract: The unsupervised articulation discovery pipeline is claimed to reliably recover part structure and joint kinematics from observed motion alone in real-world RGB-D videos, but no details on the algorithm, motion observability assumptions, part segmentation stability, or kinematic identifiability are provided to assess this load-bearing assumption.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment on the abstract below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts that the method works and produces usable twins but supplies no quantitative results, comparisons, error metrics, or validation details; central claims rest on unshown evidence.
Authors: We agree that the abstract would benefit from including key quantitative results to support the claims. In the revised version we will add specific metrics from the experiments section, such as rendering PSNR/SSIM, part segmentation accuracy, joint parameter errors, and comparisons to baselines. revision: yes
-
Referee: [Abstract] Abstract: The unsupervised articulation discovery pipeline is claimed to reliably recover part structure and joint kinematics from observed motion alone in real-world RGB-D videos, but no details on the algorithm, motion observability assumptions, part segmentation stability, or kinematic identifiability are provided to assess this load-bearing assumption.
Authors: The abstract is a concise summary; the algorithm, motion observability assumptions, part segmentation stability, and kinematic identifiability analysis are detailed in Sections 3 and 4 of the manuscript. To address the point we will insert a brief high-level statement on the pipeline approach and assumptions into the abstract. revision: partial
Circularity Check
No significant circularity
full rationale
The supplied abstract and high-level description contain no equations, derivations, fitted parameters, or mathematical claims. The framework is presented as a combination of 3D Gaussian Splatting and an unsupervised articulation pipeline without any self-referential predictions, self-definitional steps, or load-bearing self-citations that reduce to inputs by construction. No load-bearing derivation chain exists to analyze, so the paper is self-contained against external benchmarks at the level of detail provided.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption 3D Gaussian Splatting preserves geometric fidelity and photometric realism from RGB-D input
- domain assumption Observed motion in RGB-D video is sufficient for unsupervised recovery of part structure and joint kinematics
Reference graph
Works this paper leans on
-
[1]
G. Yang, C. Wang, N. D. Reddy, and D. Ramanan, “Reconstruct- ing animatable categories from videos,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2023, pp. 16995–17005, doi: 10.1109/CVPR52729.2023.01630
-
[2]
Y . Weng, B. Wen, J. Tremblay, V . Blukis, D. Fox, L. Guibas, and S. Birchfield, “Neural implicit representation for building digital twins of unknown articulated objects,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 3141–3150, doi: 10.1109/CVPR52733.2024.00303
-
[3]
doi: 10.1109/ICRA55743.2025.11128816
R. Luo, H. Geng, C. Deng, P. Li, Z. Wang, B. Jia, L. Guibas, and S. Huang, “PhysPart: Physically plausible part completion for interactable objects,” in Proc. IEEE Int. Conf. Robot. Autom. (ICRA), 2025, pp. 12386–12393, doi: 10.1109/ICRA55743.2025.11127496
-
[4]
SceneVerse: Scaling 3D vision-language learning for grounded scene understanding,
B. Jia, Y . Chen, H. Yu, Y . Wang, X. Niu, T. Liu, Q. Li, and S. Huang, “SceneVerse: Scaling 3D vision-language learning for grounded scene understanding,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2024
2024
-
[5]
An embodied generalist agent in 3D world,
J. Huang, S. Yong, X. Ma, X. Linghu, P. Li, Y . Wang, Q. Li, S.-C. Zhu, B. Jia, and S. Huang, “An embodied generalist agent in 3D world,” in Proc. Int. Conf. Mach. Learn. (ICML), 2024
2024
-
[6]
Multi- modal situated reasoning in 3D scenes,
X. Linghu, J. Huang, X. Niu, X. Ma, B. Jia, and S. Huang, “Multi- modal situated reasoning in 3D scenes,” in Adv. Neural Inf. Process. Syst. (NeurIPS), 2024
2024
-
[7]
H. Geng, H. Xu, C. Zhao, C. Xu, L. Yi, S. Huang, and H. Wang, “GAPartNet: Cross-category domain-generalizable object perception and manipulation via generalizable and actionable parts,” arXiv preprint arXiv:2211.05272, 2022
arXiv 2022
-
[8]
ARNOLD: A benchmark for language-grounded task learning with continuous states in realistic 3D scenes,
R. Gong, J. Huang, Y . Zhao, H. Geng, X. Gao, Q. Wu, W. Ai, Z. Zhou, D. Terzopoulos, S.-C. Zhu,et al., “ARNOLD: A benchmark for language-grounded task learning with continuous states in realistic 3D scenes,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2023
2023
-
[9]
Reconciling reality through simulation: A real-to-sim- to-real approach for robust manipulation,
M. Torne, A. Simeonov, Z. Li, A. Chan, T. Chen, A. Gupta, and P. Agrawal, “Reconciling reality through simulation: A real-to-sim- to-real approach for robust manipulation,” arXiv:2403.03949 [cs.RO], 2024
arXiv 2024
-
[10]
Robot see robot do: Imitating articulated object manipu- lation with monocular 4D reconstruction,
J. Kerr, C. M. Kim, M. Wu, B. Yi, Q. Wang, K. Goldberg, and A. Kanazawa, “Robot see robot do: Imitating articulated object manipu- lation with monocular 4D reconstruction,” in Proc. Conf. Robot Learn. (CoRL), 2024
2024
-
[11]
PARIS: Part-level re- construction and motion analysis for articulated objects,
J. Liu, A. Mahdavi-Amiri, and M. Savva, “PARIS: Part-level re- construction and motion analysis for articulated objects,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2023
2023
-
[12]
NeRF: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoor- thi, and R. Ng, “NeRF: Representing scenes as neural radiance fields for view synthesis,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2020
2020
-
[13]
3D Gaussian splatting for real-time radiance field rendering,
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3D Gaussian splatting for real-time radiance field rendering,” ACM Trans. Graph., vol. 42, no. 4, 2023
2023
-
[14]
Real2Code: Reconstruct articulated objects via code generation,
Z. Mandi, Y . Weng, D. Bauer, and S. Song, “Real2Code: Reconstruct articulated objects via code generation,” arXiv:2406.08474, 2024
arXiv 2024
-
[15]
L. Le, J. Xie, W. Liang, H.-J. Wang, Y . Yang, Y . J. Ma, K. Vedder, A. Krishna, D. Jayaraman, and E. Eaton, “Articulate-Anything: Automatic modeling of articulated objects via a vision language foundation model,” arXiv:2410.13882, 2024
arXiv 2024
-
[16]
Building interactable replicas of complex articulated objects via Gaussian splatting,
Y . Liu, B. Jia, R. Lu, J. Ni, S.-C. Zhu, and S. Huang, “Building interactable replicas of complex articulated objects via Gaussian splatting,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2025
2025
-
[17]
SplArt: Articulation esti- mation and part-level reconstruction with 3D Gaussian splatting,
S. Lin, J. Fang, M. Z. Irshad, V . C. Guizilini, R. A. Ambrus, G. Shakhnarovich, and M. R. Walter, “SplArt: Articulation esti- mation and part-level reconstruction with 3D Gaussian splatting,” arXiv:2506.03594, 2025
arXiv 2025
-
[18]
Deformable 3D Gaussians for high-fidelity monocular dynamic scene reconstruc- tion,
Z. Yang, X. Gao, W. Zhou, S. Jiao, Y . Zhang, and X. Jin, “Deformable 3D Gaussians for high-fidelity monocular dynamic scene reconstruc- tion,” arXiv:2309.13101, 2023
arXiv 2023
-
[19]
Shape of motion: 4D reconstruction from a single video,
Q. Wang, V . Ye, H. Gao, W. Zeng, J. Austin, Z. Li, and A. Kanazawa, “Shape of motion: 4D reconstruction from a single video,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2025
2025
-
[20]
SAM 2: Segment anything in images and videos,
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R¨adle, C. Rolland, L. Gustafson, E. Mintun, J. Pan, K. V . Alwala, N. Carion, C.-Y . Wu, R. Girshick, P. Doll´ar, and C. Feichtenhofer, “SAM 2: Segment anything in images and videos,” arXiv:2408.00714, 2024
Pith/arXiv arXiv 2024
-
[21]
From coarse to fine: Robust hierarchical localization at large scale,
P.-E. Sarlin, C. Cadena, R. Siegwart, and M. Dymczyk, “From coarse to fine: Robust hierarchical localization at large scale,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019
2019
-
[22]
3DGS-CD: 3D Gaussian splatting-based change detection for physical object rearrangement,
Z. Lu, J. Ye, and J. Leonard, “3DGS-CD: 3D Gaussian splatting-based change detection for physical object rearrangement,” arXiv:2411.03706 [cs.CV], 2025
arXiv 2025
-
[23]
TAPIP3D: Tracking any point in persistent 3D geometry,
B. Zhang, L. Ke, A. W. Harley, and K. Fragkiadaki, “TAPIP3D: Tracking any point in persistent 3D geometry,” arXiv:2504.14717, 2025
arXiv 2025
-
[24]
Mobility fitting using 4D RANSAC,
H. Li, G. Wan, H. Li, A. Sharf, K. Xu, and B. Chen, “Mobility fitting using 4D RANSAC,” Comput. Graph. Forum, vol. 35, no. 5, pp. 79–88, 2016, doi: 10.1111/cgf.12965
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.