QnRL: Quantum-Native Reinforcement Learning
Pith reviewed 2026-06-27 19:30 UTC · model grok-4.3
The pith
QnRL distills conditional action policy distributions from moments of quantum generative models entirely inside Hilbert space via the QuAK algorithm.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
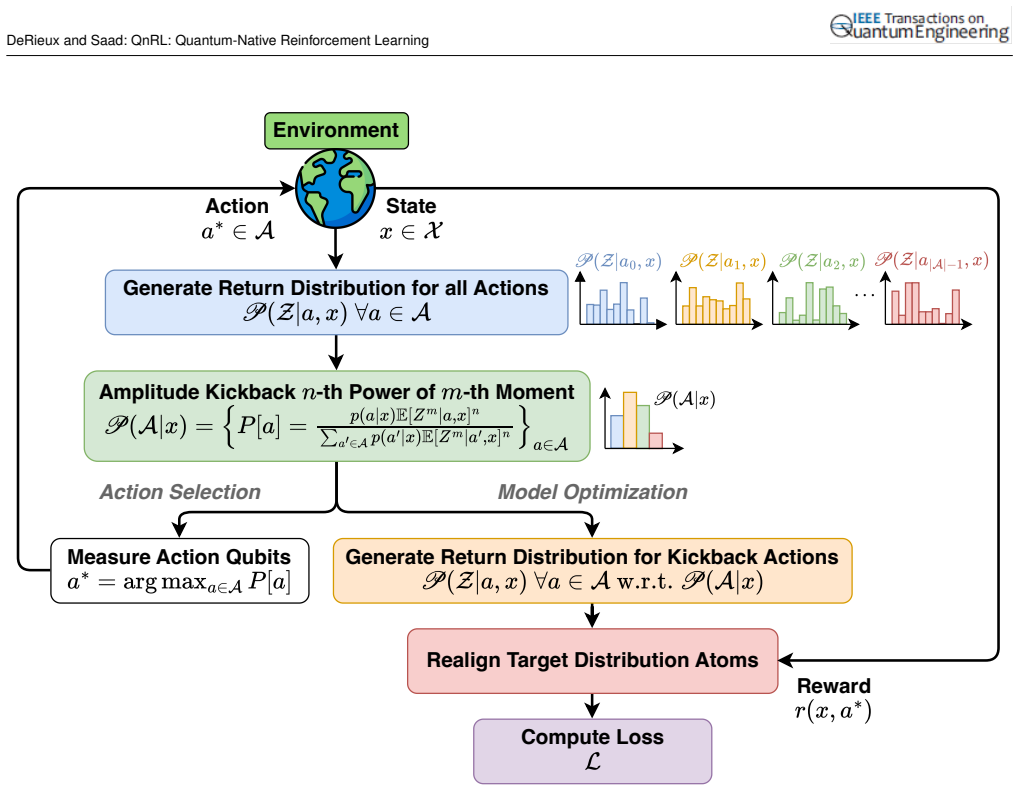
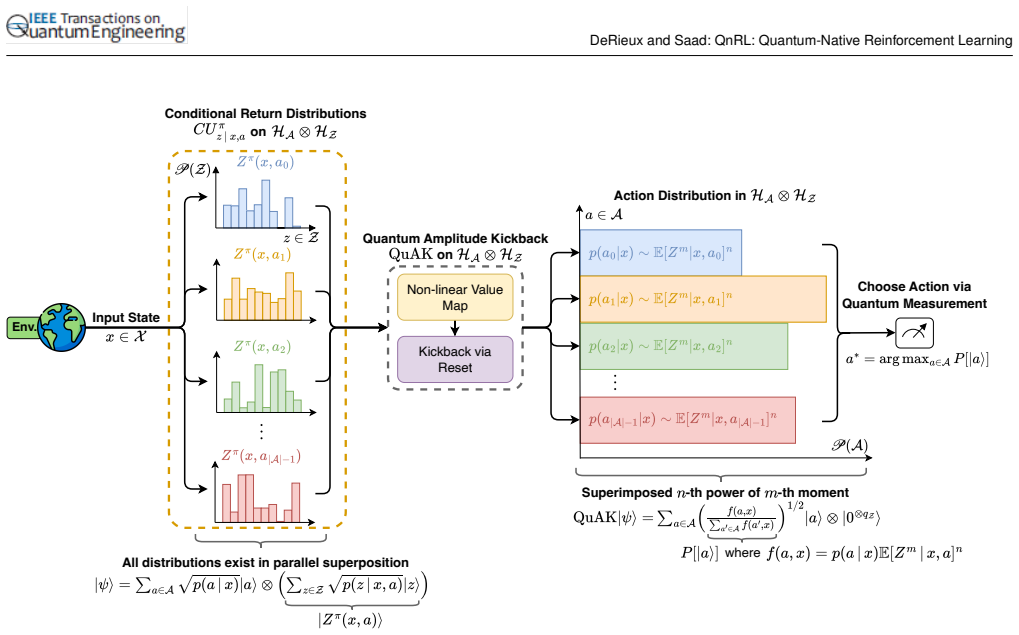
A conditional action policy distribution is distilled from the moments of a quantum generative model entirely within Hilbert space via QuAK and optimized via QnRL. This distributional RL framework directly models environment behavior via the natural properties of quantum systems, providing extra dimensions for expressing unknown correlations that are unavailable to purely classical and classically-sampled quantum models.
What carries the argument
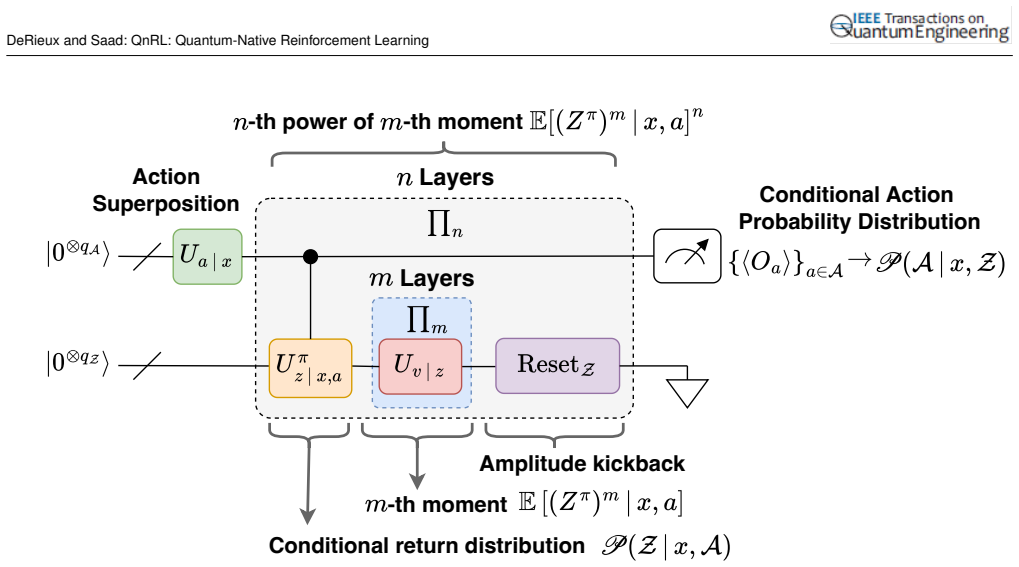
The quantum amplitude kickback (QuAK) algorithm that enables comparing the n-th power of the m-th moment of multiple superimposed quantum distributions.
If this is right
- Direct modeling of stochastic environment random variables as quantum state distributions instead of expected outcomes.
- Extra dimensions for expressing environment correlations unknown to classical or classically-sampled quantum models.
- Up to 82.9% higher evaluation scores across diverse environments.
- Up to 94.3% fewer parameters on average while more accurately estimating expected return for unseen observations.
- Better adaptation to varying stochastic conditions compared to baselines.
Where Pith is reading between the lines
- The approach opens a route for using quantum superposition to represent full return distributions in other reinforcement learning settings.
- Practical deployment would depend on hardware that preserves coherence long enough for the full QuAK comparison and distillation steps.
- The moment-comparison technique could be adapted to other quantum generative tasks that require comparing properties of multiple overlaid states.
Load-bearing premise
The QuAK procedure can extract and compare moments across superimposed quantum distributions without decoherence or information loss that would invalidate the subsequent policy distillation step.
What would settle it
An experiment in which QuAK applied to superimposed distributions produces moment values that deviate from classically computed moments on the same distributions due to decoherence.
Figures
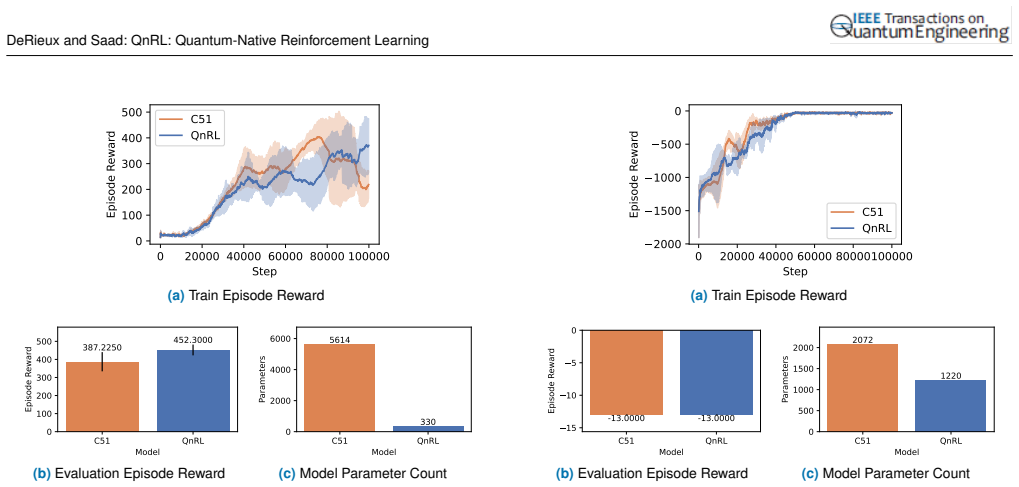
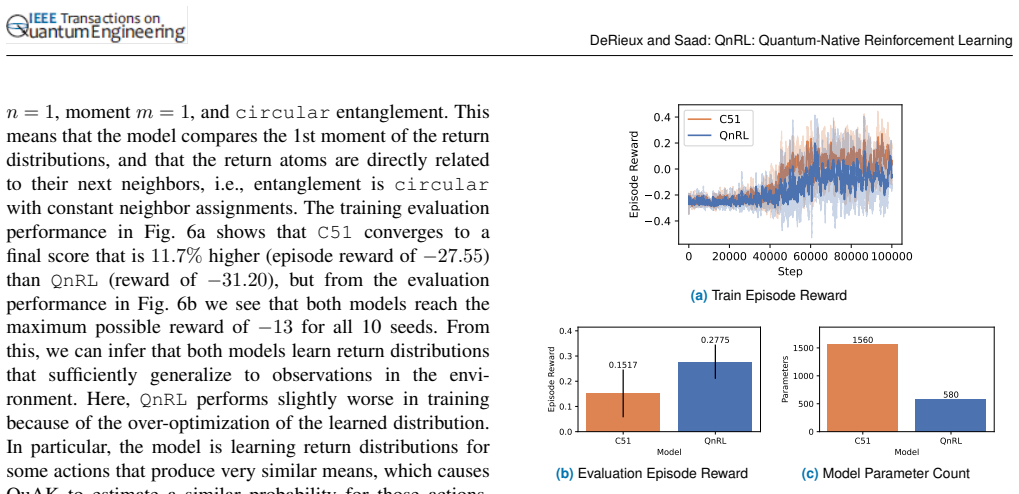
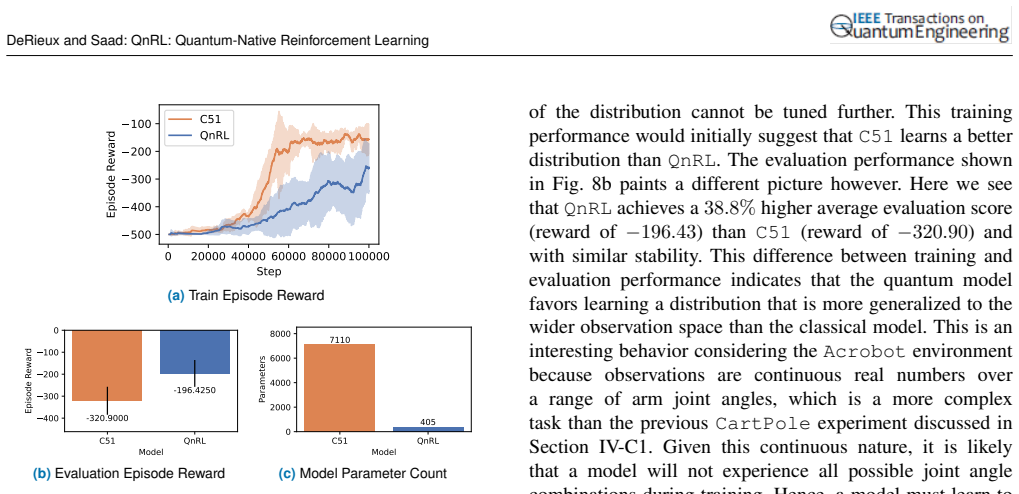
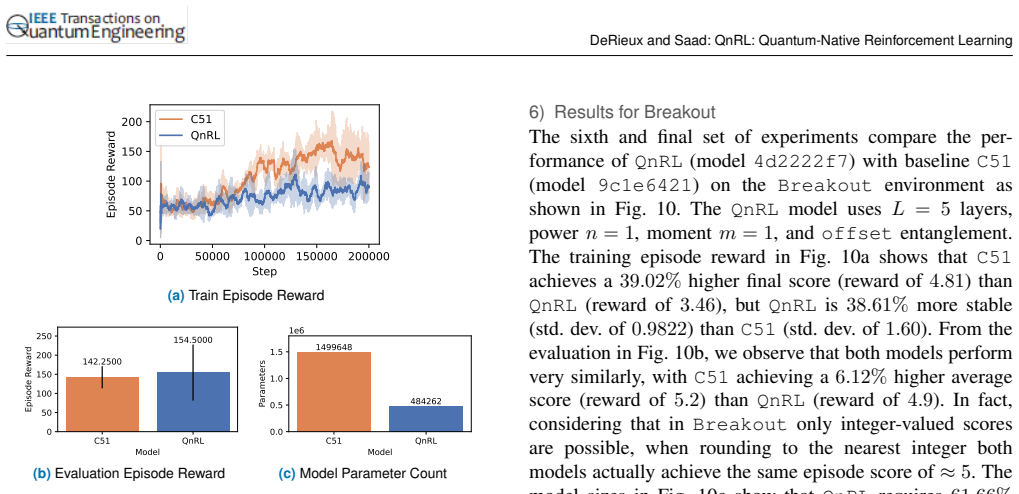
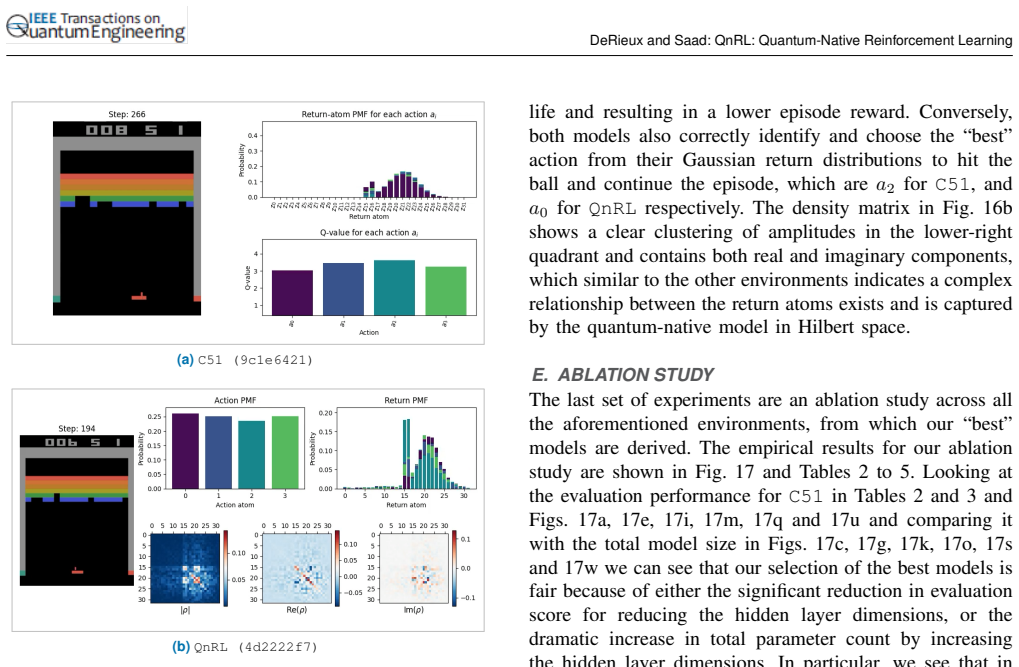
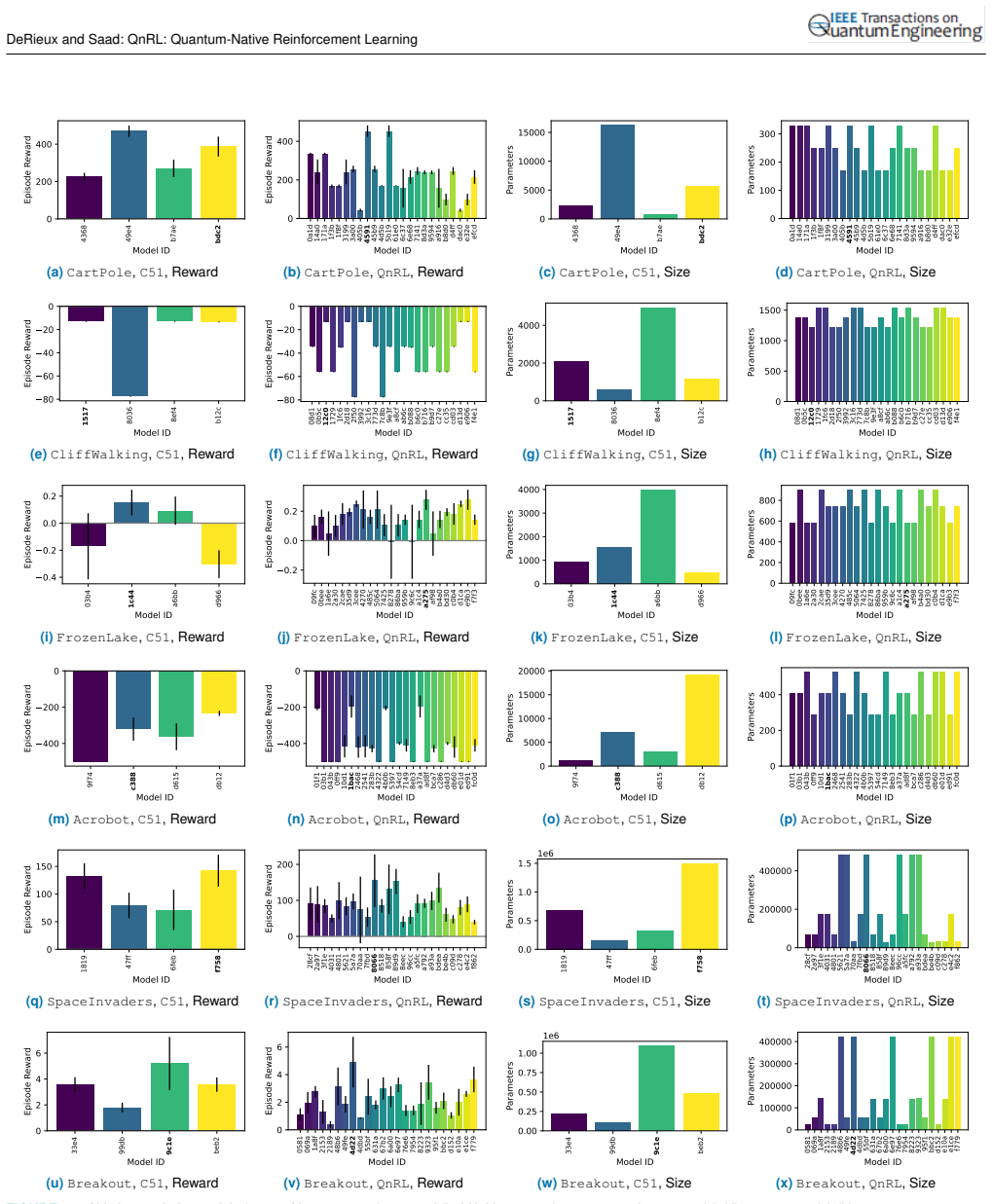
read the original abstract
Quantum reinforcement learning (QRL) is a promising approach to learn effective decision strategies across several applications with stochastic environments. Instead of directly modeling the random variables that govern these environments, existing QRL architectures indirectly approximate environment behavior by estimating expected outcomes, which limits their expressive power and adaptive potential. Overcoming such challenges requires a novel QRL approach that exploits the distributional nature of quantum computers to directly model environment random variables as quantum state distributions. Hence, in this paper, a novel framework dubbed quantum-native reinforcement learning (QnRL) is proposed. QnRL is a distributional RL framework that learns conditional distributions naturally in Hilbert space via superimposed and entangled quantum states. Thus, QnRL can directly model the behavior of stochastic learning environments via the natural properties of quantum systems. QnRL accomplishes this via a novel, proposed quantum amplitude kickback (QuAK) algorithm that enables comparing the $n$-th power of the $m$-th moment of multiple superimposed distributions. It is theoretically proven that a conditional action policy distribution is distilled from the moments of a quantum generative model entirely within Hilbert space via QuAK, and optimized via QnRL. This complex distribution composition is also shown to provide extra dimensions for expressing environment correlations that are unknown to purely classical and classically-sampled quantum distributional models. Experimental results across diverse environments show that QnRL achieves up to $82.9\%$ higher evaluation scores, with up to $94.3\%$ fewer parameters on average, more accurately estimates the expected return for unseen observations, and better adapts to varying stochastic conditions compared to the baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes QnRL, a distributional quantum reinforcement learning framework that directly models stochastic environment random variables as superimposed and entangled quantum states in Hilbert space. It introduces the QuAK (quantum amplitude kickback) algorithm to compare the n-th power of the m-th moment across multiple distributions, claims a theoretical proof that a conditional action policy distribution is distilled from the moments of a quantum generative model entirely within Hilbert space via QuAK and then optimized by QnRL, and reports experimental gains of up to 82.9% higher evaluation scores and 94.3% fewer parameters versus baselines across diverse environments.
Significance. If the central theoretical claim holds and the reported gains are reproducible with full protocols, the work would advance distributional RL by exploiting quantum superposition for direct moment-based policy distillation, potentially enabling more expressive modeling of unknown environment correlations with reduced parameter counts. The absence of any machine-checked proofs or reproducible code in the current manuscript limits immediate credit on those dimensions.
major comments (3)
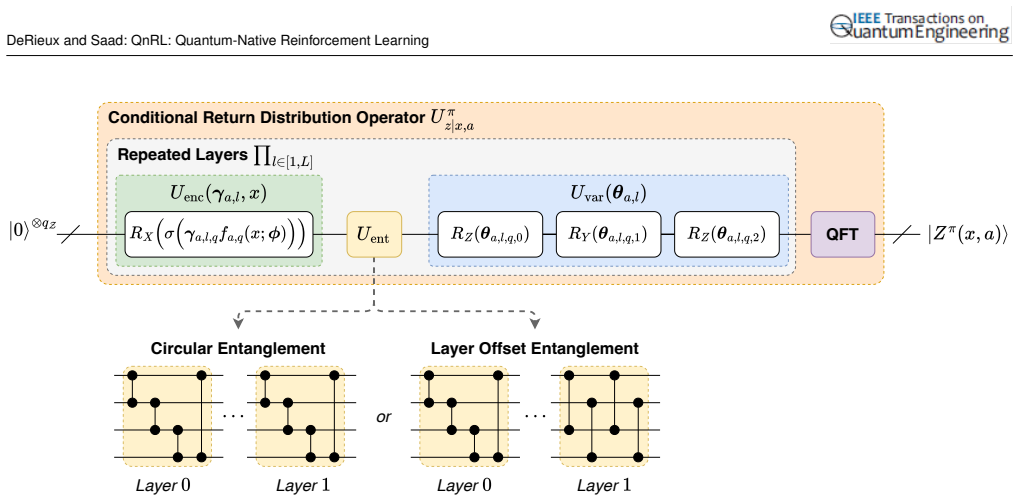
- [Abstract and §3] Abstract and §3 (QuAK description): the claim that QuAK enables comparison of the n-th power of the m-th moment of multiple superimposed distributions 'entirely within Hilbert space' without decoherence or information loss is load-bearing for the distillation proof, yet no explicit unitary operator, circuit identity, or commutation relation is supplied showing how the kickback isolates higher-order moments while preserving the required phase/amplitude information for subsequent policy extraction.
- [Abstract and §4] Abstract and §4 (theoretical proof): the statement 'it is theoretically proven that a conditional action policy distribution is distilled... via QuAK' is asserted without derivation steps, intermediate lemmas, or verification that the extraction commutes with the entanglement structure of the quantum generative model; this directly undermines the 'entirely within Hilbert space' guarantee.
- [Experimental results section] Experimental results section: the reported 82.9% higher scores and 94.3% parameter reduction lack any description of the quantum generative model implementation, classical/quantum baselines, number of runs, statistical tests, or environment details, rendering the quantitative claims unverifiable against the stated advantages.
minor comments (2)
- [Abstract] Abstract: the phrase 'more accurately estimates the expected return for unseen observations' is stated without defining the estimation metric or how it differs from standard value-function baselines.
- Notation: 'QuAK' is introduced without an initial expansion or reference to its full algorithmic pseudocode on first use.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and commit to a major revision that supplies the requested technical details, derivations, and experimental protocols.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (QuAK description): the claim that QuAK enables comparison of the n-th power of the m-th moment of multiple superimposed distributions 'entirely within Hilbert space' without decoherence or information loss is load-bearing for the distillation proof, yet no explicit unitary operator, circuit identity, or commutation relation is supplied showing how the kickback isolates higher-order moments while preserving the required phase/amplitude information for subsequent policy extraction.
Authors: We agree that Section 3 currently presents QuAK at a high level without the explicit unitary, circuit identity, or commutation relations needed to substantiate the no-decoherence claim. In the revised manuscript we will insert a dedicated subsection deriving the unitary operator for the amplitude kickback step, the corresponding circuit identity, and the commutation relations that isolate the n-th power of the m-th moment while preserving phase and amplitude information. revision: yes
-
Referee: [Abstract and §4] Abstract and §4 (theoretical proof): the statement 'it is theoretically proven that a conditional action policy distribution is distilled... via QuAK' is asserted without derivation steps, intermediate lemmas, or verification that the extraction commutes with the entanglement structure of the quantum generative model; this directly undermines the 'entirely within Hilbert space' guarantee.
Authors: The current manuscript states that a proof exists but does not supply the derivation steps, lemmas, or commutation verification. We will expand Section 4 with the complete proof, including all intermediate lemmas and an explicit check that the policy-distillation map commutes with the entanglement structure of the generative model. revision: yes
-
Referee: [Experimental results section] Experimental results section: the reported 82.9% higher scores and 94.3% parameter reduction lack any description of the quantum generative model implementation, classical/quantum baselines, number of runs, statistical tests, or environment details, rendering the quantitative claims unverifiable against the stated advantages.
Authors: We acknowledge that the experimental section omits implementation specifics, baseline definitions, run counts, statistical tests, and environment details. The revised version will add a complete experimental protocol subsection that specifies the quantum generative model circuit, all classical and quantum baselines, the number of independent runs, the statistical tests employed, and full environment descriptions. revision: yes
Circularity Check
No significant circularity; derivation self-contained against external benchmarks.
full rationale
The abstract claims a theoretical proof that a conditional action policy distribution is distilled from moments of a quantum generative model via the proposed QuAK algorithm entirely within Hilbert space. No equations, circuit identities, or derivations are exhibited that reduce this result to its inputs by construction. No self-citations, fitted parameters renamed as predictions, ansatzes smuggled via prior work, or uniqueness theorems imported from the same authors appear in the provided text. The central claim is presented as a novel contribution with experimental validation, and the derivation chain does not collapse to self-definition or statistical forcing within the inspected material.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard axioms of quantum mechanics (Hilbert space, superposition, entanglement, measurement)
invented entities (2)
-
QuAK (quantum amplitude kickback) algorithm
no independent evidence
-
quantum generative model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
R. S. Sutton and A. G. Barto,Reinforcement Learning: An Introduction. Cambridge, MA, USA: A Bradford Book, 2018
2018
-
[2]
J.-H. Chen, Y .-C. Huang, Y .-C. Tsai, and S. Y .-C. Chen,Quantum-Enhanced Forecasting for Deep Reinforcement Learning in Algorithmic Trading, arXiv:2509.09176 [cs], Sep. 2025. DOI: 10.48550/arXiv.2509.09176
-
[3]
Y .-K. Liu, Y .-H. Pan, P.-F. Lu, Y .-C. Tsai, and S. Y .-C. Chen,Quantum- Enhanced Reinforcement Learning with LSTM Forecasting Signals for Opti- mizing Fintech Trading Decisions, arXiv:2507.12835 [cs.CE], Jul. 2025. DOI: 10.48550/arXiv.2507.12835
-
[4]
Quantum Reinforcement Learning: The Maze problem,
N. D. Pozza, L. Buffoni, S. Martina, and F. Caruso, “Quantum Reinforcement Learning: The Maze problem,”Quantum Machine Intelligence, vol. 4, no. 1, p. 11, Jun. 2022, arXiv:2108.04490 [quant-ph]. DOI: 10.1007/s42484- 022- 00068-y
-
[5]
S. Y .-C. Chen,Efficient quantum recurrent reinforcement learning via quantum reservoir computing, arXiv:2309.07339 [quant-ph], Sep. 2023
arXiv 2023
- [6]
-
[7]
S. Park, G. S. Kim, Z. Han, and J. Kim, “Quantum Multi-Agent Reinforcement Learning is All You Need: Coordinated Global Access in Integrated TN/NTN Cube-Satellite Networks,”IEEE Communications Magazine, vol. 62, no. 10, pp. 86–92, Oct. 2024, Conference Name: IEEE Communications Magazine. DOI: 10.1109/MCOM.010.2400001
-
[8]
Quantum Reinforcement Learning for Coordinated Satellite Systems,
G. S. Kim, S. Yen-Chi Chen, S. Park, and J. Kim, “Quantum Reinforcement Learning for Coordinated Satellite Systems,” inICASSP 2025 - 2025 IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India: IEEE, Apr. 2025, pp. 1–5. DOI: 10.1109/ICASSP49660. 2025.10889145
-
[9]
J. J. Park, H.-H. Tseng, S. Yoo, S. Y .-C. Chen, and J. Cha,It’s-A-Me, Quantum Mario: Scalable Quantum Reinforcement Learning with Multi-Chip Ensembles, arXiv:2509.00713 [quant-ph], Aug. 2025. DOI: 10.48550/arXiv. 2509.00713
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[10]
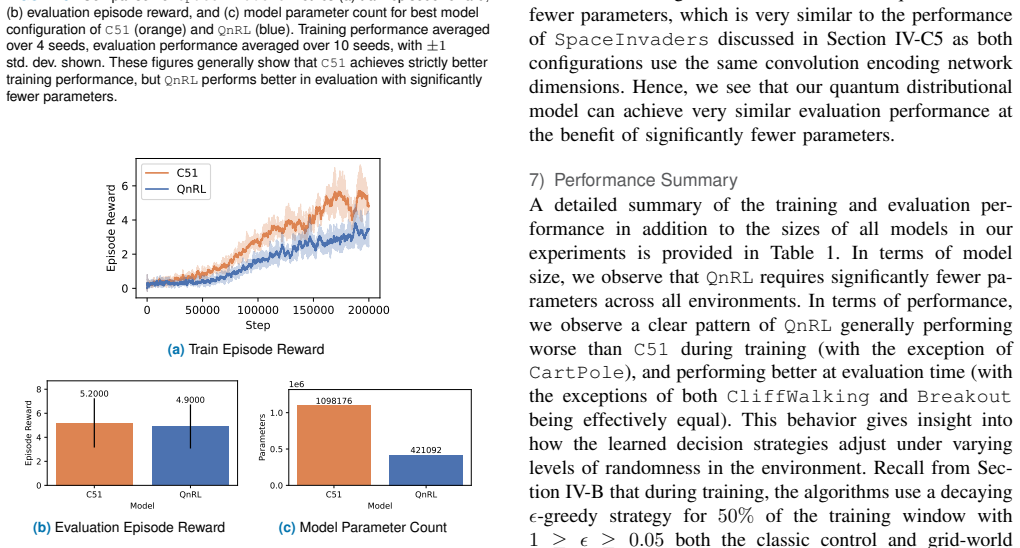
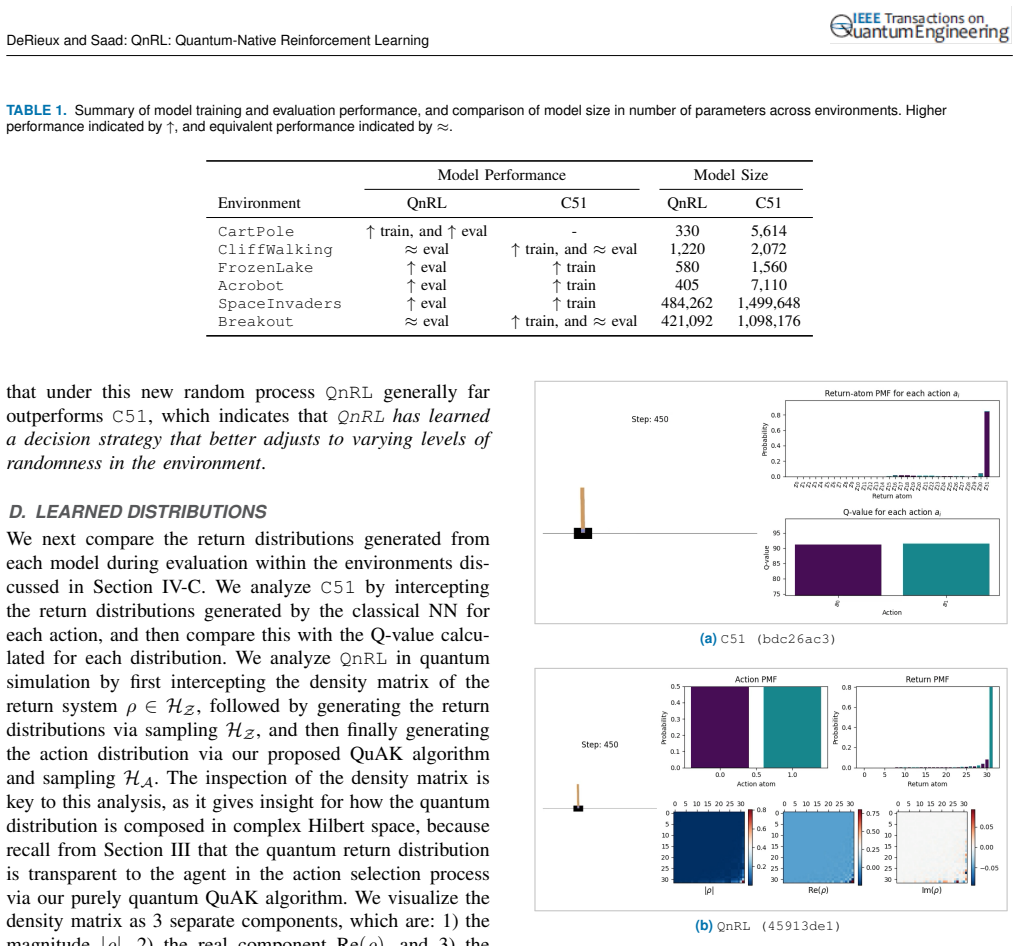
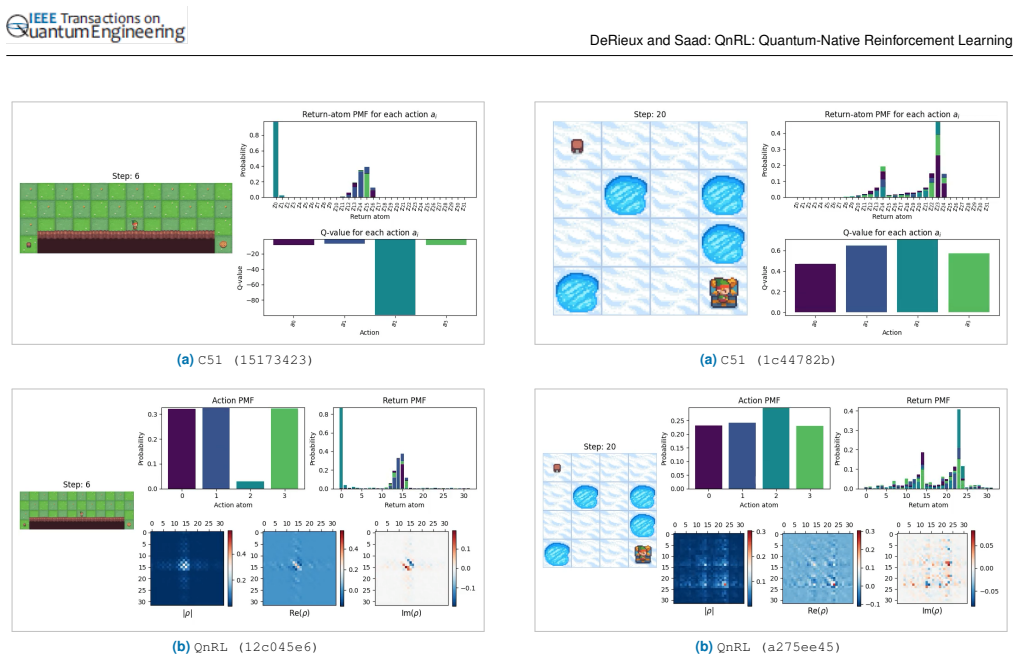
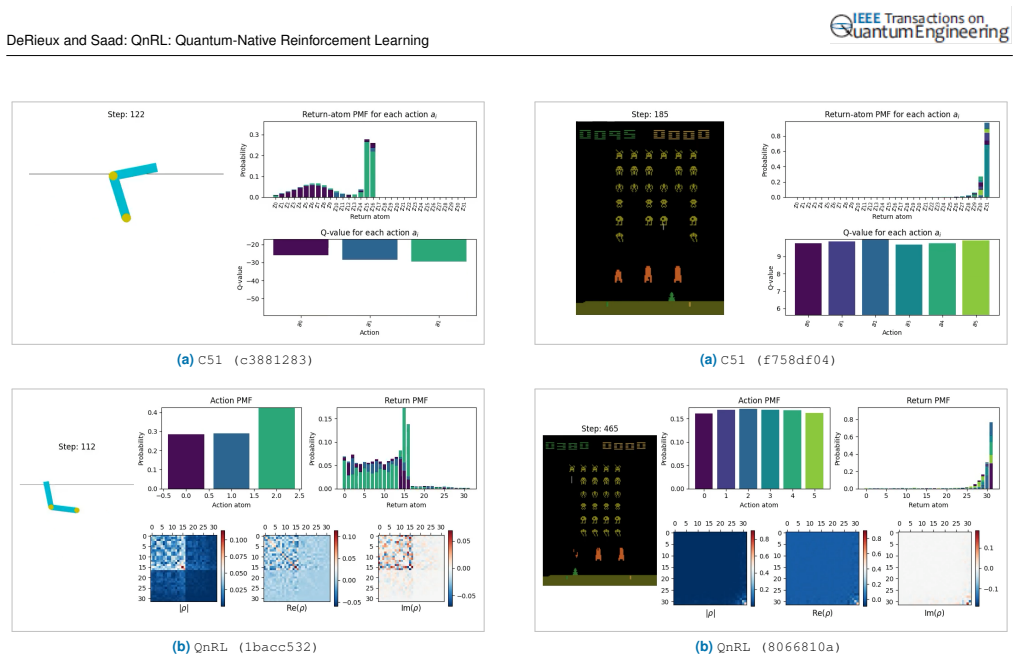
N. Cai, M. Zhao, Y . Ke, and X. Liu, “Quantum-enhanced hybrid deep reinforcement learning for real-time volleyball tactical decision making,” en, 34 VOLUME 4, 2016 DeRieux and Saad: QnRL: Quantum-Native Reinforcement Learning TABLE E.1.Description of hyperparameters forC51andQnRLused on the classic control and grid-world environments. Model Parameter Desc...
-
[11]
W. J. Yun, J. P. Kim, S. Jung, J.-H. Kim, and J. Kim, “Quantum Multi- Agent Actor-Critic Neural Networks for Internet-Connected Multi-Robot Coordination in Smart Factory Management,” Jan. 2023, arXiv: 2301.04012. DOI: 10.48550/arXiv.2301.04012
-
[12]
A Distributional Perspective on Reinforcement Learning
M. G. Bellemare, W. Dabney, and R. Munos, “A distributional perspective on reinforcement learning,” inProceedings of the 34th international conference on machine learning, D. Precup and Y . W. Teh, Eds., ser. Proceedings of machine learning research, vol. 70, PMLR, Aug. 2017, pp. 449–458. DOI: 10.48550/arXiv.1707.06887
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1707.06887 2017
-
[13]
M. G. Bellemare, W. Dabney, and M. Rowland,Distributional reinforcement learning. MIT Press, 2023. DOI: 10.7551/mitpress/14207.001.0001
-
[14]
Distributional Reinforcement Learning with Quantum Neural Networks,
W. Hu and J. Hu, “Distributional Reinforcement Learning with Quantum Neural Networks,”Intelligent Control and Automation, vol. 10, no. 02, pp. 63–78, 2019. DOI: 10.4236/ica.2019.102004
-
[15]
E. A. Cherrat et al., “Quantum Deep Hedging,” en,Quantum, vol. 7, p. 1191, Nov. 2023. DOI: 10.22331/q-2023-11-29-1191
-
[16]
C. Zoufal, A. Lucchi, and S. Woerner, “Quantum Generative Adversarial Networks for Learning and Loading Random Distributions,”npj Quantum Information, vol. 5, no. 1, p. 103, Nov. 2019, arXiv:1904.00043 [quant-ph]. DOI: 10.1038/s41534-019-0223-2
-
[17]
Y . Du, M.-H. Hsieh, T. Liu, and D. Tao, “The Expressive Power of Parameter- ized Quantum Circuits,”Physical Review Research, vol. 2, no. 3, p. 033 125, Jul. 2020, arXiv:1810.11922 [quant-ph]. DOI: 10.1103/PhysRevResearch.2. 033125
-
[18]
On the Quantum versus Classical Learnability of Discrete Distributions,
R. Sweke, J.-P. Seifert, D. Hangleiter, and J. Eisert, “On the Quantum versus Classical Learnability of Discrete Distributions,”Quantum, vol. 5, p. 417, Mar. 2021, arXiv:2007.14451 [quant-ph]. DOI: 10.22331/q-2021-03-23-417
-
[19]
Generative quantum learning of joint probability distribution functions,
E. Y . Zhu et al., “Generative quantum learning of joint probability distribution functions,” en,Physical Review Research, vol. 4, no. 4, p. 043 092, Nov. 2022. DOI: 10.1103/PhysRevResearch.4.043092 TABLE E.2.Description of hyperparameters forC51andQnRLused on the Atari environments. Model Parameter Description C51 Total Train Steps200,000 |x|Input observ...
-
[20]
A. Rao, D. Madan, A. Ray, D. Vinayagamurthy, and M. S. Santhanam, Learning hard distributions with quantum-enhanced Variational Autoencoders, arXiv:2305.01592 [quant-ph], May 2023. DOI: 10.48550/arXiv.2305.01592
-
[21]
A. Barthe, M. Grossi, S. Vallecorsa, J. Tura, and V . Dunjko, “Parameterized quantum circuits as universal generative models for continuous multivariate distributions,” en,npj Quantum Information, vol. 11, no. 1, p. 121, Jul. 2025. DOI: 10.1038/s41534-025-01064-3
-
[22]
Differentiable Learning of Quantum Circuit Born Machine
J.-G. Liu and L. Wang, “Differentiable Learning of Quantum Circuit Born Machine,”Physical Review A, vol. 98, no. 6, p. 062 324, Dec. 2018, arXiv:1804.04168 [quant-ph]. DOI: 10.1103/PhysRevA.98.062324
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1103/physreva.98.062324 2018
-
[23]
Quantum state preparation of normal distributions using matrix product states,
J. Iaconis, S. Johri, and E. Y . Zhu, “Quantum state preparation of normal distributions using matrix product states,” en,npj Quantum Information, vol. 10, no. 1, p. 15, Jan. 2024. DOI: 10.1038/s41534-024-00805-0
-
[24]
Y . Sano and I. Hamamura, “Quantum State Preparation for Probability Distri- butions with Reflection Symmetry Using Matrix Product States,”Physical Review Applied, vol. 24, no. 3, p. 034 062, Sep. 2025, arXiv:2403.16729 [quant-ph]. DOI: 10.1103/yqj3-hyxv
-
[25]
P.-L. Dallaire-Demers and N. Killoran, “Quantum generative adversarial networks,” en,Physical Review A, vol. 98, no. 1, p. 012 324, Jul. 2018. DOI: 10.1103/PhysRevA.98.012324
-
[26]
Quantum Generative Adversarial Learning,
S. Lloyd and C. Weedbrook, “Quantum Generative Adversarial Learning,” en,Physical Review Letters, vol. 121, no. 4, p. 040 502, Jul. 2018. DOI: 10.1103/PhysRevLett.121.040502
-
[27]
Information Perspective to Probabilistic Modeling: Boltzmann Machines versus Born Machines,
S. Cheng, J. Chen, and L. Wang, “Information Perspective to Probabilistic Modeling: Boltzmann Machines versus Born Machines,” en,Entropy, vol. 20, no. 8, p. 583, Aug. 2018. DOI: 10.3390/e20080583 VOLUME 4, 2016 35 DeRieux and Saad: QnRL: Quantum-Native Reinforcement Learning
-
[28]
A generative modeling approach for benchmarking and training shallow quantum circuits,
M. Benedetti, D. Garcia-Pintos, O. Perdomo, V . Leyton-Ortega, Y . Nam, and A. Perdomo-Ortiz, “A generative modeling approach for benchmarking and training shallow quantum circuits,” en,npj Quantum Information, vol. 5, no. 1, p. 45, May 2019. DOI: 10.1038/s41534-019-0157-8
-
[29]
H. Wiltzer et al.,A Distributional Analogue to the Successor Representation, arXiv:2402.08530 [cs], May 2024. DOI: 10.48550/arXiv.2402.08530
-
[30]
R. E. Bellman,Dynamic programming. Princeton, NJ: Princeton University Press, 1957
1957
-
[31]
Human-level control through deep reinforcement learning,
V . Mnih et al., “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529–533, Feb. 2015. DOI: 10 . 1038 / nature14236
2015
-
[32]
Quantum agents in the Gym: A variational quantum algorithm for deep Q-learning,
A. Skolik, S. Jerbi, and V . Dunjko, “Quantum agents in the Gym: A variational quantum algorithm for deep Q-learning,” Mar. 2021, arXiv: 2103.15084. DOI: 10.22331/q-2022-05-24-720
-
[33]
C. Van Loan,Computational Frameworks for the Fast Fourier Transform, en. Society for Industrial and Applied Mathematics, Jan. 1992. DOI: 10.1137/1. 9781611970999
work page doi:10.1137/1 1992
-
[34]
D. Coppersmith,An approximate Fourier transform useful in quantum fac- toring, arXiv:quant-ph/0201067, Jan. 2002. DOI: 10 . 48550 / arXiv . quant - ph/0201067
Pith/arXiv arXiv 2002
-
[35]
M. A. Nielsen and I. L. Chuang,Quantum Computation and Quantum Information: 10th Anniversary Edition, 1st ed. Cambridge University Press, Jun. 2012. DOI: 10.1017/CBO9780511976667
-
[36]
K. Kraus, A. Böhm, J. D. Dollard, and W. H. Wootters, Eds.,States, Effects, and Operations Fundamental Notions of Quantum Theory(Lecture Notes in Physics), en. Berlin, Heidelberg: Springer Berlin Heidelberg, 1983, vol. 190. DOI: 10.1007/3-540-12732-1
-
[37]
T. Heinosaari, M. A. Jivulescu, D. Reeb, and M. M. Wolf, “Extending quantum operations,”Journal of Mathematical Physics, vol. 53, no. 10, p. 102 208, Oct. 2012, arXiv:1205.0641 [math-ph]. DOI: 10.1063/1.4755845
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1063/1.4755845 2012
-
[38]
C. J. Wood, J. D. Biamonte, and D. G. Cory,Tensor networks and graphical calculus for open quantum systems, arXiv:1111.6950 [quant-ph], May 2015. DOI: 10.48550/arXiv.1111.6950
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1111.6950 2015
-
[39]
Introduction to mid-circuit measurements,
D. Wierichs, “Introduction to mid-circuit measurements,” en,PennyLane Demos, May 2024
2024
-
[40]
Quantum state preparation and nonunitary evolution with diagonal operators,
A. W. Schlimgen, K. Head-Marsden, L. M. Sager-Smith, P. Narang, and D. A. Mazziotti, “Quantum state preparation and nonunitary evolution with diagonal operators,” en,Physical Review A, vol. 106, no. 2, p. 022 414, Aug. 2022. DOI: 10.1103/PhysRevA.106.022414
-
[41]
Parametrized quantum policies for reinforcement learning,
S. Jerbi, C. Gyurik, S. C. Marshall, H. J. Briegel, and V . Dunjko, “Parametrized quantum policies for reinforcement learning,” Mar. 2021, arXiv: 2103.05577. DOI: 10.48550/arXiv.2103.05577
-
[42]
Neuronlike adaptive elements that can solve difficult learning control problems,
A. G. Barto, R. S. Sutton, and C. W. Anderson, “Neuronlike adaptive elements that can solve difficult learning control problems,”IEEE Transactions on Systems, Man, and Cybernetics, vol. SMC-13, no. 5, pp. 834–846, Sep. 1983, Conference Name: IEEE Transactions on Systems, Man, and Cybernetics. DOI: 10.1109/TSMC.1983.6313077
-
[43]
G. Brockman et al.,OpenAI Gym, arXiv:1606.01540 [cs], Jun. 2016. DOI: 10.48550/arXiv.1606.01540
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1606.01540 2016
-
[44]
The Arcade Learning Environment: An Evaluation Platform for General Agents,
M. G. Bellemare, Y . Naddaf, J. Veness, and M. Bowling, “The Arcade Learning Environment: An Evaluation Platform for General Agents,”Journal of Artificial Intelligence Research, vol. 47, pp. 253–279, Jun. 2013, Belle- mare2013ArcadeLearningEnvironment. DOI: 10.1613/jair.3912
-
[45]
M. C. Machado, M. G. Bellemare, E. Talvitie, J. Veness, M. Hausknecht, and M. Bowling, “Revisiting the Arcade Learning Environment: Eval- uation Protocols and Open Problems for General Agents,”Journal of Artificial Intelligence Research, vol. 61, pp. 523–562, Mar. 2018, Machado2018RevisitingArcadeLearning. DOI: 10.1613/jair.5699
-
[46]
Cleanrl: High-quality single-file implementations of deep reinforcement learning algorithms,
S. Huang et al., “Cleanrl: High-quality single-file implementations of deep reinforcement learning algorithms,”Journal of Machine Learning Research, vol. 23, no. 274, pp. 1–18, 2022
2022
-
[47]
Heek et al.,Flax: A neural network library and ecosystem for JAX, 2024
J. Heek et al.,Flax: A neural network library and ecosystem for JAX, 2024
2024
-
[48]
DeepMind et al.,The DeepMind JAX Ecosystem, 2020
2020
-
[49]
V . Bergholm et al.,PennyLane: Automatic differentiation of hybrid quantum- classical computations, arXiv:1811.04968 [quant-ph], Jul. 2022. DOI: 10 . 48550/arXiv.1811.04968
Pith/arXiv arXiv 2022
-
[50]
Adam: A Method for Stochastic Optimization,
D. P. Kingma and J. Ba, “Adam: A Method for Stochastic Optimization,”Iclr, pp. 1–15, Dec. 2014, arXiv: 1412.6980
Pith/arXiv arXiv 2014
-
[51]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter,Decoupled Weight Decay Regularization, arXiv:1711.05101 [cs], Jan. 2019. DOI: 10.48550/arXiv.1711.05101 ALEXANDER DERIEUX(Graduate Student Member, IEEE) received the B.S. degree in Electrical Engineering with honors and the B.S. degree in Computer Science with honors from Virginia Tech in 2016, and the M.S. degree in Electrical...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1711.05101 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.