Evidence-State Rewards for Long-Context Reasoning
Pith reviewed 2026-07-03 13:21 UTC · model grok-4.3
The pith
Maven rewards add, link and drop actions by their effect on an editable evidence memory rather than final answers alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
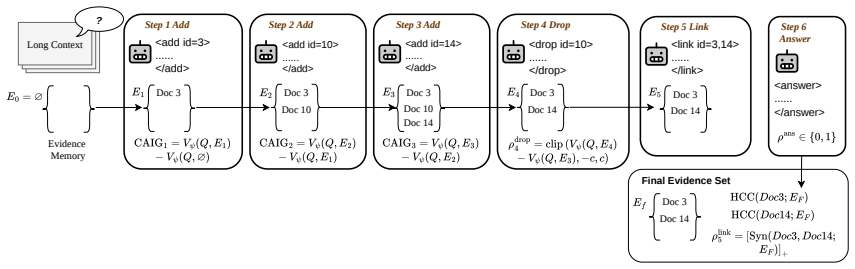
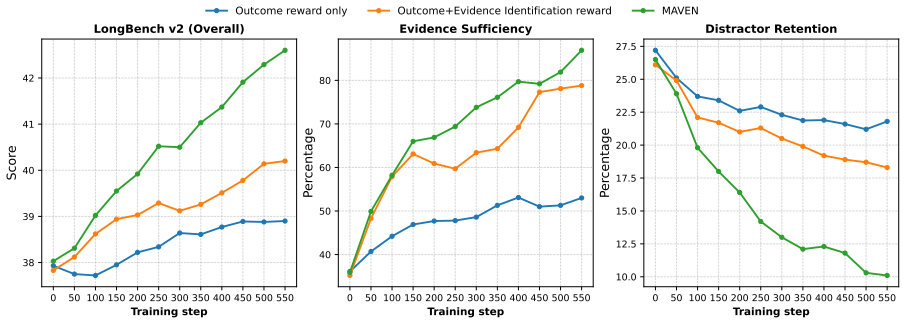
Maven defines an answer-conditioned evidence-state value and rewards action-level state transitions: add actions by marginal gain and hindsight contribution, link actions by evidence synergy, and drop actions by improved answer support after removing misleading evidence. These rewards are assigned to the corresponding action spans in GRPO, producing more sufficient evidence sets and lower distractor retention across benchmarks.
What carries the argument
Answer-conditioned evidence-state value that scores transitions inside an editable memory for add, link, and drop actions.
If this is right
- Models produce more sufficient evidence sets than outcome-only or static-evidence baselines.
- Fewer distractors are retained in the final evidence used for answers.
- Performance improves on LongBench v2, LongReason, and RULER for both Llama and Qwen backbones.
- Long-context RL gains come from optimizing stateful navigation rather than one-shot extraction.
Where Pith is reading between the lines
- Editable memory with state rewards may help agent systems that must gather and revise information over many steps.
- The same transition scoring could be tested on retrieval-augmented generation tasks where evidence quality directly affects output accuracy.
- If the reward definitions prove robust across new evidence distributions, they could reduce reliance on extensive hyperparameter search for long-context RL.
Load-bearing premise
The specific definitions of marginal gain, hindsight contribution, evidence synergy, and improved answer support accurately measure useful evidence navigation without introducing benchmark-specific biases.
What would settle it
Replacing the state-transition rewards with random values and observing unchanged performance on LongBench v2, LongReason, and RULER would show the definitions are not responsible for the gains.
Figures

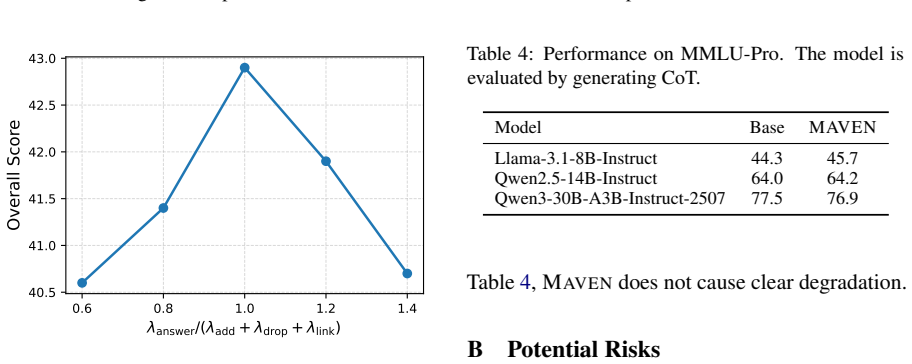
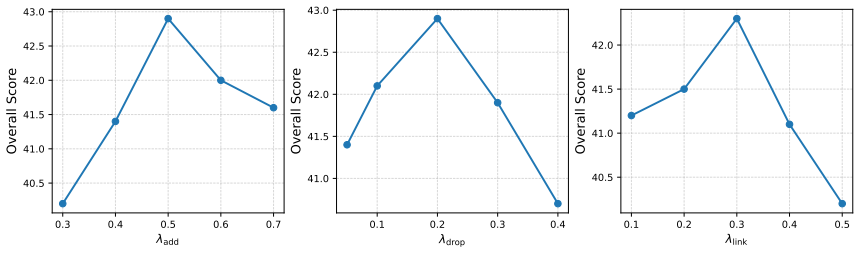
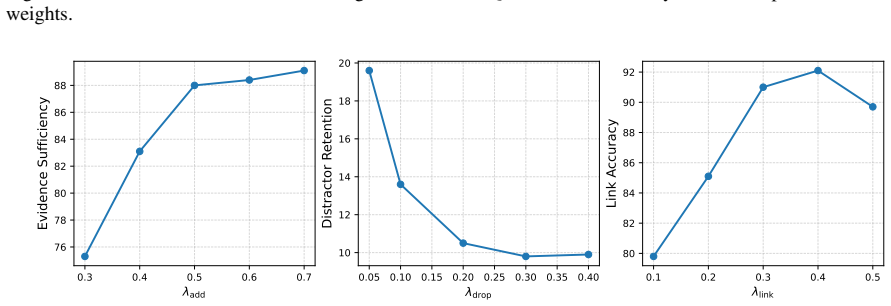
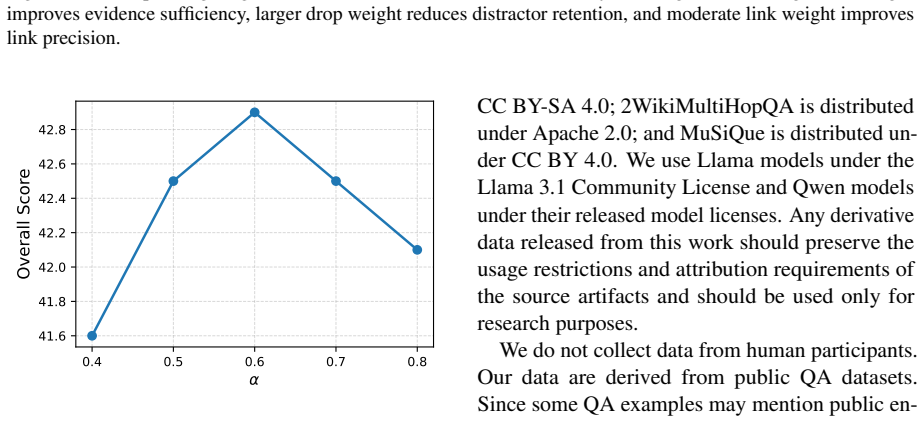
read the original abstract
Long-context reasoning requires models to locate, revise, and synthesize evidence distributed across lengthy inputs. Existing long-context RL methods usually reward final answers or static evidence extraction, offering little feedback on how intermediate actions change the model's evidence state. We propose Maven, a reinforcement learning framework with an editable evidence memory. Maven defines an answer-conditioned evidence-state value and rewards action-level state transitions: add actions are credited by marginal gain and hindsight contribution, link actions by evidence synergy, and drop actions by improved answer support after removing misleading evidence. These rewards are assigned to the corresponding action spans in GRPO. Across Llama and Qwen models on LongBench v2, LongReason, and RULER, Maven outperforms outcome-only RL and evidence-identification baselines, producing more sufficient evidence sets and lower distractor retention. Our results show that long-context RL benefits from optimizing stateful evidence navigation rather than one-shot evidence extraction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Maven, an RL framework for long-context reasoning using an editable evidence memory and an answer-conditioned evidence-state value to assign action-level rewards: marginal gain and hindsight contribution for add actions, evidence synergy for link actions, and improved answer support for drop actions. These are applied via GRPO. On Llama and Qwen models, Maven outperforms outcome-only RL and evidence-identification baselines on LongBench v2, LongReason, and RULER, yielding more sufficient evidence sets and lower distractor retention.
Significance. If the action-level rewards derived from the evidence-state value genuinely reflect useful navigation rather than estimator artifacts, the work would advance long-context RL by replacing sparse outcome rewards with denser state-transition signals. The empirical gains on three benchmarks would then indicate a practical benefit for evidence synthesis tasks.
major comments (3)
- [Abstract] Abstract: the claim of outperformance on LongBench v2, LongReason, and RULER is stated without any quantitative results, error bars, ablation tables, or statistical tests, preventing evaluation of effect sizes or post-hoc selection.
- [Method] Method (reward definitions): the four action rewards (marginal gain, hindsight contribution, evidence synergy, improved answer support) are defined via an answer-conditioned evidence-state value whose functional form, normalization, and dependence on the final-answer model are not specified; this is load-bearing because the central claim requires these quantities to measure useful evidence navigation rather than benchmark artifacts.
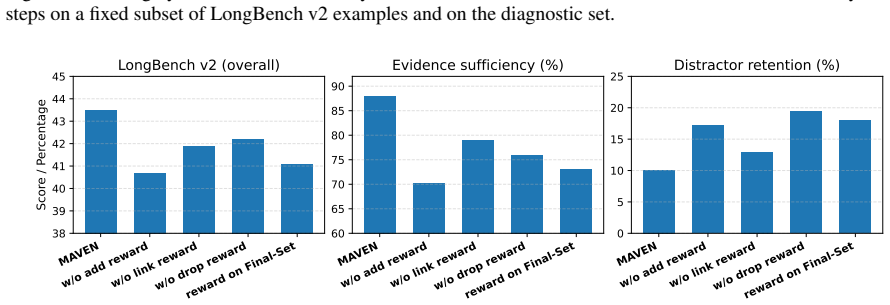
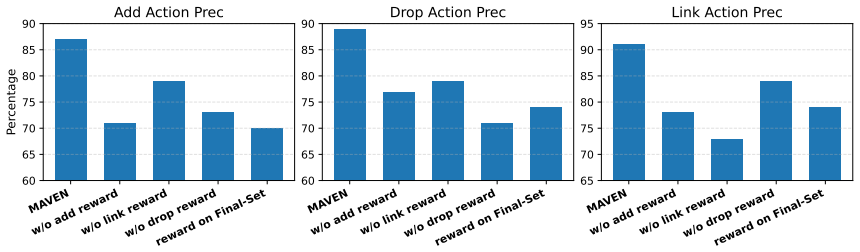
- [Experiments] Experiments: no ablations isolating individual reward terms or testing sensitivity of results to the value estimator are reported, so the mapping from the proposed rewards to measured sufficiency and distractor retention cannot be verified.
minor comments (2)
- [Notation] The term 'evidence-state value' is introduced without explicit comparison to standard RL value functions or discussion of potential circularity with the final-answer model.
- [Experiments] Ensure all benchmark results include the exact model sizes, context lengths, and hyperparameter settings used for both Maven and baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will incorporate revisions to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of outperformance on LongBench v2, LongReason, and RULER is stated without any quantitative results, error bars, ablation tables, or statistical tests, preventing evaluation of effect sizes or post-hoc selection.
Authors: We agree that the abstract would benefit from including key quantitative results. In the revised manuscript we will add specific performance deltas (with reference to error bars and significance from the main tables) to allow readers to assess effect sizes directly from the abstract. revision: yes
-
Referee: [Method] Method (reward definitions): the four action rewards (marginal gain, hindsight contribution, evidence synergy, improved answer support) are defined via an answer-conditioned evidence-state value whose functional form, normalization, and dependence on the final-answer model are not specified; this is load-bearing because the central claim requires these quantities to measure useful evidence navigation rather than benchmark artifacts.
Authors: We will expand Section 3 to provide the explicit functional form of the evidence-state value, its normalization relative to a baseline, and the precise manner in which it is estimated from the final-answer model. This will make the reward definitions fully transparent. revision: yes
-
Referee: [Experiments] Experiments: no ablations isolating individual reward terms or testing sensitivity of results to the value estimator are reported, so the mapping from the proposed rewards to measured sufficiency and distractor retention cannot be verified.
Authors: We acknowledge that isolating each reward term and testing sensitivity to the value estimator would strengthen the empirical claims. We will add these ablations and sensitivity analyses in the revised version. revision: yes
Circularity Check
No circularity: reward definitions and performance claims are independent of self-referential inputs
full rationale
The paper presents an empirical RL method where rewards are explicitly constructed from an answer-conditioned evidence-state value function, with performance evaluated on external benchmarks (LongBench v2, LongReason, RULER) against separate baselines. No equations or claims reduce a prediction to a fitted parameter by construction, nor does any load-bearing step rely on self-citation chains or imported uniqueness theorems. The derivation chain remains self-contained because the value estimates and action rewards are defined as design choices whose validity is tested via end-to-end comparisons rather than assumed or renamed from prior results within the paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Long-context reasoning can be modeled as state transitions on an editable evidence memory whose value is conditioned on the eventual answer.
invented entities (1)
-
Answer-conditioned evidence-state value
no independent evidence
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Kimi K2: Open Agentic Intelligence
Kimi k2: Open agentic intelligence , author=. arXiv preprint arXiv:2507.20534 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Transactions of the association for computational linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the association for computational linguistics , volume=
-
[5]
arXiv preprint arXiv:2510.19363 , year=
Loongrl: Reinforcement learning for advanced reasoning over long contexts , author=. arXiv preprint arXiv:2510.19363 , year=
-
[6]
Guanzheng Chen and Michael Qizhe Shieh and Lidong Bing , booktitle=. Long. 2026 , url=
2026
-
[7]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Kimi Linear: An Expressive, Efficient Attention Architecture
Kimi linear: An expressive, efficient attention architecture , author=. arXiv preprint arXiv:2510.26692 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2505.17667 , year=
Qwenlong-l1: Towards long-context large reasoning models with reinforcement learning , author=. arXiv preprint arXiv:2505.17667 , year=
-
[10]
Evidence-Augmented Policy Optimization with Reward Co-Evolution for Long-Context Reasoning
Evidence-Augmented Policy Optimization with Reward Co-Evolution for Long-Context Reasoning , author=. arXiv preprint arXiv:2601.10306 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
arXiv preprint arXiv:2602.05758 , year=
LongR: Unleashing Long-Context Reasoning via Reinforcement Learning with Dense Utility Rewards , author=. arXiv preprint arXiv:2602.05758 , year=
-
[12]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
HotpotQA: A dataset for diverse, explainable multi-hop question answering , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[13]
Transactions of the Association for Computational Linguistics , volume=
MuSiQue: Multihop Questions via Single-hop Question Composition , author=. Transactions of the Association for Computational Linguistics , volume=. 2022 , publisher=
2022
-
[14]
Proceedings of the 28th International Conference on Computational Linguistics , pages=
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps , author=. Proceedings of the 28th International Conference on Computational Linguistics , pages=
-
[15]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[17]
arXiv preprint arXiv:2501.15089 , year=
Longreason: A synthetic long-context reasoning benchmark via context expansion , author=. arXiv preprint arXiv:2501.15089 , year=
-
[18]
RULER: What's the Real Context Size of Your Long-Context Language Models?
RULER: What's the real context size of your long-context language models? , author=. arXiv preprint arXiv:2404.06654 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
International Conference on Learning Representations , volume=
Yarn: Efficient context window extension of large language models , author=. International Conference on Learning Representations , volume=
-
[20]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Neurocomputing , volume=
Roformer: Enhanced transformer with rotary position embedding , author=. Neurocomputing , volume=. 2024 , publisher=
2024
-
[22]
Extending Context Window of Large Language Models via Positional Interpolation
Extending context window of large language models via positional interpolation , author=. arXiv preprint arXiv:2306.15595 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens
Longrope: Extending llm context window beyond 2 million tokens , author=. arXiv preprint arXiv:2402.13753 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[25]
InFindings of the Association for Computational Linguistics: ACL 2024, pages 14982– 14995
Longrag: Enhancing retrieval-augmented generation with long-context llms , author=. arXiv preprint arXiv:2406.15319 , year=
-
[26]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Longrag: A dual-perspective retrieval-augmented generation paradigm for long-context question answering , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[27]
Advances in Neural Information Processing Systems , volume=
Chain of agents: Large language models collaborating on long-context tasks , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Longalign: A recipe for long context alignment of large language models , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[29]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Longreward: Improving long-context large language models with ai feedback , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[30]
arXiv preprint arXiv:2504.16828 , year=
Process reward models that think , author=. arXiv preprint arXiv:2504.16828 , year=
-
[31]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
The lessons of developing process reward models in mathematical reasoning , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[32]
International Conference on Learning Representations , volume=
Let's verify step by step , author=. International Conference on Learning Representations , volume=
-
[33]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[35]
ArXiv , year=
Qwen2.5 Technical Report , author=. ArXiv , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.