Learning Structural Latent Points for Efficient Visual Representations in Robotic Manipulation
Pith reviewed 2026-05-21 03:42 UTC · model grok-4.3
The pith
Structural latent points from a regularized point-cloud autoencoder capture rough shape and semantic cues for robotic manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
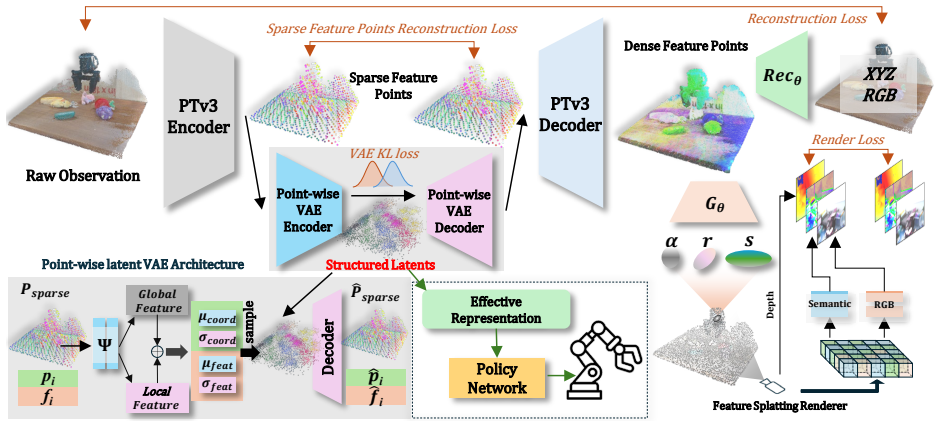
By inserting a point-wise latent variational autoencoder into the latent space of a point-cloud autoencoder and jointly regularizing point-wise features and coordinates toward a Gaussian prior, the resulting compact latent preserves coarse structural tendencies, which do not encode precise geometry but capture richer rough shape and semantic information, effectively combining the expressiveness of implicit representations with the structural priors of explicit ones.
What carries the argument
Structural latent points generated by a point-wise latent variational autoencoder inserted into a point-cloud autoencoder, with joint regularization of features and coordinates to a Gaussian prior.
If this is right
- Higher task success and sample efficiency on RLBench and ManiSkill2 benchmarks.
- Better robustness to viewpoint and scene variations on real-robot platforms.
- Each element of the framework, including the latent regularization and efficient rendering, proves essential to the gains.
- The lightweight rendering pipeline frees capacity for the front-end latent module.
Where Pith is reading between the lines
- Robots might handle lower-resolution 3D inputs effectively by relying on these coarse structural signals rather than detailed geometry.
- Similar point-wise regularization could extend to other sensor modalities for embodied tasks beyond manipulation.
- The latents may transfer to new environments or tasks where precise geometry is unavailable or costly to obtain.
Load-bearing premise
Regularizing point-wise features and coordinates toward a Gaussian prior inside the latent space of a point-cloud autoencoder will reliably produce structural cues that improve downstream robotic manipulation without requiring precise geometry.
What would settle it
An ablation that removes the Gaussian prior regularization and finds no improvement or a drop in manipulation task success rates relative to a plain point-cloud autoencoder baseline.
Figures



read the original abstract
Current 3D-aware pretraining methods for embodied perception and manipulation are largely built on differentiable rendering frameworks, producing either fully implicit neural fields or fully explicit geometric primitives. Implicit representations, while expressive, lack explicit structural cues, whereas explicit ones preserve geometry but suffer from resolution limits and weak generalization. To address these limitations, we propose a novel pretraining framework that learns a hybrid representation-structural latent points. Specifically, we insert a point-wise latent variational autoencoder into the latent space of a point-cloud autoencoder, jointly regularizing point-wise features and coordinates toward a Gaussian prior. The resulting compact latent preserves coarse structural tendencies, which do not encode precise geometry but capture richer rough shape and semantic information, effectively combining the expressiveness of implicit representations with the structural priors of explicit ones. In addition, informed by shared design choices in prior work, we develop a streamlined, efficient 3DGS-based rendering pipeline that is deliberately kept lightweight, improving efficiency while leaving greater representational capacity to the front-end latent module. Extensive evaluations on RLBench, ManiSkill2, and a real-robot platform demonstrate consistent gains in task success, sample efficiency, and robustness to viewpoint and scene variations over strong baselines. Ablation studies further confirm that each component of our framework is critical to overall performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hybrid pretraining framework for robotic manipulation that learns 'structural latent points' by inserting a point-wise latent variational autoencoder into the latent space of a point-cloud autoencoder. Point-wise features and coordinates are jointly regularized toward a Gaussian prior, producing a compact latent that is claimed to preserve coarse structural tendencies and richer rough shape/semantic information while combining expressiveness of implicit representations with structural priors of explicit ones. A lightweight 3DGS-based rendering pipeline is introduced to improve efficiency. Extensive experiments on RLBench, ManiSkill2, and a real-robot platform report consistent gains in task success, sample efficiency, and robustness to viewpoint/scene variations, with ablations confirming the importance of each component.
Significance. If the central empirical claims hold after addressing the evidence gap, the work would offer a practical middle ground between fully implicit neural fields and explicit geometric primitives for embodied perception, potentially enabling more efficient and robust visual representations for manipulation without heavy rendering costs. The reported downstream gains on standard benchmarks and the inclusion of ablation studies are strengths that support the framework's utility if the structural/semantic interpretation of the regularization can be more directly substantiated.
major comments (2)
- [Method description and Evaluation section] The core claim that Gaussian regularization of point-wise features and coordinates yields 'coarse structural tendencies' and 'richer rough shape and semantic information' (rather than generic compression) is load-bearing for the hybrid-representation argument, yet the manuscript provides no isolating quantitative test such as part segmentation, semantic retrieval, or 3D correspondence metrics. Downstream RLBench/ManiSkill2 gains and ablations are reported but do not separate this effect from the lightweight 3DGS renderer or standard VAE regularization.
- [Ablation studies] Ablation studies confirm component importance but lack a control that removes only the coordinate regularization (while retaining feature regularization) to test whether the claimed structural cues are specifically responsible for the observed robustness gains.
minor comments (2)
- [Method] Clarify the precise insertion point and dimensionality of the point-wise latent VAE within the point-cloud autoencoder architecture, including any equations defining the joint regularization loss.
- [Experiments] Add error bars or standard deviations to the reported task success rates and sample-efficiency curves to allow assessment of statistical significance of the gains.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each of the major comments in detail below and have made revisions to strengthen the presentation of our results and the supporting evidence for our claims.
read point-by-point responses
-
Referee: [Method description and Evaluation section] The core claim that Gaussian regularization of point-wise features and coordinates yields 'coarse structural tendencies' and 'richer rough shape and semantic information' (rather than generic compression) is load-bearing for the hybrid-representation argument, yet the manuscript provides no isolating quantitative test such as part segmentation, semantic retrieval, or 3D correspondence metrics. Downstream RLBench/ManiSkill2 gains and ablations are reported but do not separate this effect from the lightweight 3DGS renderer or standard VAE regularization.
Authors: We acknowledge that the manuscript would benefit from more direct quantitative evidence to substantiate the interpretation of the learned latent points as capturing coarse structural tendencies and semantic information beyond generic compression. While the downstream performance improvements and existing ablations provide supporting evidence for the overall framework, they do not fully isolate the contribution of the joint regularization. In the revised version, we will incorporate additional experiments, including part segmentation or semantic retrieval tasks on appropriate 3D datasets, to better separate the effects of the structural regularization from the rendering pipeline and standard VAE components. revision: yes
-
Referee: [Ablation studies] Ablation studies confirm component importance but lack a control that removes only the coordinate regularization (while retaining feature regularization) to test whether the claimed structural cues are specifically responsible for the observed robustness gains.
Authors: We agree that an ablation isolating the coordinate regularization would provide clearer insight into whether the structural cues from coordinate regularization are key to the robustness gains. We will add this specific control experiment to the ablation studies in the revised manuscript, comparing performance with and without coordinate regularization while keeping feature regularization intact. revision: yes
Circularity Check
No circularity: hybrid latent construction is method description, not self-referential derivation
full rationale
The paper describes a concrete architectural choice—inserting a point-wise latent VAE inside a point-cloud autoencoder and applying Gaussian regularization to both features and coordinates—then states the resulting latent 'preserves coarse structural tendencies' and 'capture[s] richer rough shape and semantic information.' This is presented as an empirical outcome of the design rather than a mathematical derivation that reduces to its own inputs by construction. No equations, fitted-parameter predictions, or self-citation chains appear in the supplied text; downstream gains on RLBench/ManiSkill2 and ablations are reported as external validation. The central claim therefore remains self-contained against benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nerf: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoor- thi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,”Communications of the ACM, vol. 65, no. 1, pp. 99–106, 2021
work page 2021
-
[2]
3d gaussian splatting for real-time radiance field rendering
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, G. Drettakiset al., “3d gaussian splatting for real-time radiance field rendering.”ACM Trans. Graph., vol. 42, no. 4, pp. 139–1, 2023
work page 2023
-
[3]
H. Bharadhwaj, J. Vakil, M. Sharma, A. Gupta, S. Tulsiani, and V . Kumar, “Roboagent: Generalization and efficiency in robot ma- nipulation via semantic augmentations and action chunking,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 4788–4795
work page 2024
-
[4]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsuet al., “Rt-1: Robotics transformer for real-world control at scale,”arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Bc-z: Zero-shot task generalization with robotic imitation learning,
E. Jang, A. Irpan, M. Khansari, D. Kappler, F. Ebert, C. Lynch, S. Levine, and C. Finn, “Bc-z: Zero-shot task generalization with robotic imitation learning,” inConference on Robot Learning. PMLR, 2022, pp. 991–1002
work page 2022
-
[6]
Robot learning with sensorimotor pre-training,
I. Radosavovic, B. Shi, L. Fu, K. Goldberg, T. Darrell, and J. Malik, “Robot learning with sensorimotor pre-training,” inConference on Robot Learning. PMLR, 2023, pp. 683–693
work page 2023
-
[7]
Image augmentation is all you need: Regularizing deep reinforcement learning from pixels,
D. Yarats, I. Kostrikov, and R. Fergus, “Image augmentation is all you need: Regularizing deep reinforcement learning from pixels,” in International conference on learning representations, 2021
work page 2021
-
[8]
Reinforcement learning with augmented data,
M. Laskin, K. Lee, A. Stooke, L. Pinto, P. Abbeel, and A. Srinivas, “Reinforcement learning with augmented data,”Advances in neural information processing systems, vol. 33, pp. 19 884–19 895, 2020
work page 2020
-
[9]
Scaling Robot Learning with Semantically Imagined Experience
T. Yu, T. Xiao, A. Stone, J. Tompson, A. Brohan, S. Wang, J. Singh, C. Tan, J. Peralta, B. Ichteret al., “Scaling robot learning with semantically imagined experience,”arXiv preprint arXiv:2302.11550, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Masked autoencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked autoencoders are scalable vision learners,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 16 000–16 009
work page 2022
-
[11]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
work page 2021
-
[12]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Curl: Contrastive unsupervised representations for reinforcement learning,
M. Laskin, A. Srinivas, and P. Abbeel, “Curl: Contrastive unsupervised representations for reinforcement learning,” inInternational confer- ence on machine learning. PMLR, 2020, pp. 5639–5650
work page 2020
-
[14]
Ponder: Point cloud pre-training via neural rendering,
D. Huang, S. Peng, T. He, H. Yang, X. Zhou, and W. Ouyang, “Ponder: Point cloud pre-training via neural rendering,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 16 089–16 098
work page 2023
-
[15]
Lift3d: Zero-shot lifting of any 2d vision model to 3d,
P. Wang, Z. Fan, Z. Wang, H. Su, R. Ramamoorthiet al., “Lift3d: Zero-shot lifting of any 2d vision model to 3d,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 21 367–21 377
work page 2024
-
[16]
3D Diffuser Actor: Policy Diffusion with 3D Scene Representations
T.-W. Ke, N. Gkanatsios, and K. Fragkiadaki, “3d diffuser ac- tor: Policy diffusion with 3d scene representations,”arXiv preprint arXiv:2402.10885, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
RVT-2: learning precise manipulation from few demonstrations,
A. Goyal, V . Blukis, J. Xu, Y . Guo, Y .-W. Chao, and D. Fox, “Rvt- 2: Learning precise manipulation from few demonstrations,”arXiv preprint arXiv:2406.08545, 2024
-
[18]
Pre-training auto-regressive robotic models with 4d representations,
D. Niu, Y . Sharma, H. Xue, G. Biamby, J. Zhang, Z. Ji, T. Darrell, and R. Herzig, “Pre-training auto-regressive robotic models with 4d representations,”arXiv preprint arXiv:2502.13142, 2025
-
[19]
Act3d: Infinite resolution action detection transformer for robotic manipulation
T. Gervet, Z. Xian, N. Gkanatsios, and K. Fragkiadaki, “Act3d: 3d feature field transformers for multi-task robotic manipulation,”arXiv preprint arXiv:2306.17817, 2023
-
[20]
Spa: 3d spatial-awareness enables effective embodied representation,
H. Zhu, H. Yang, Y . Wang, J. Yang, L. Wang, and T. He, “Spa: 3d spatial-awareness enables effective embodied representation,”arXiv preprint arXiv:2410.08208, 2024
-
[21]
Y . Jia, J. Liu, S. Chen, C. Gu, Z. Wang, L. Luo, L. Lee, P. Wang, Z. Wang, R. Zhanget al., “Lift3d foundation policy: Lifting 2d large- scale pretrained models for robust 3d robotic manipulation,”arXiv preprint arXiv:2411.18623, 2024
-
[22]
isdf: Real-time neural signed distance fields for robot perception,
J. Ortiz, A. Clegg, J. Dong, E. Sucar, D. Novotny, M. Zollhoefer, and M. Mukadam, “isdf: Real-time neural signed distance fields for robot perception,”arXiv preprint arXiv:2204.02296, 2022
-
[23]
Go-surf: Neural feature grid optimization for fast, high-fidelity rgb-d surface reconstruction,
J. Wang, T. Bleja, and L. Agapito, “Go-surf: Neural feature grid optimization for fast, high-fidelity rgb-d surface reconstruction,” in 2022 International Conference on 3D Vision (3DV). IEEE, 2022, pp. 433–442
work page 2022
-
[24]
J. Wang, Z. Zhang, and R. Xu, “Learning robust generalizable radiance field with visibility and feature augmented point representation,”arXiv preprint arXiv:2401.14354, 2024
-
[25]
Evggs: A collaborative learning framework for event-based generalizable gaussian splatting,
J. Wang, J. He, Z. Zhang, M. Sun, J. Sun, and R. Xu, “Evggs: A collaborative learning framework for event-based generalizable gaussian splatting,”arXiv preprint arXiv:2405.14959, 2024
-
[26]
Feature splatting: Language-driven physics-based scene synthesis and editing,
R.-Z. Qiu, G. Yang, W. Zeng, and X. Wang, “Feature splatting: Language-driven physics-based scene synthesis and editing,”arXiv preprint arXiv:2404.01223, 2024
-
[27]
Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields,
S. Zhou, H. Chang, S. Jiang, Z. Fan, Z. Zhu, D. Xu, P. Chari, S. You, Z. Wang, and A. Kadambi, “Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 21 676–21 685
work page 2024
-
[28]
Langsplat: 3d language gaussian splatting,
M. Qin, W. Li, J. Zhou, H. Wang, and H. Pfister, “Langsplat: 3d language gaussian splatting,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 20 051–20 060
work page 2024
-
[29]
Pfgs: High fidelity point cloud rendering via feature splatting,
J. Wang, Z. Zhang, J. He, and R. Xu, “Pfgs: High fidelity point cloud rendering via feature splatting,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 193–209
work page 2024
-
[30]
Reinforcement learning with generaliz- able gaussian splatting,
J. Wang, Q. Zhang, J. Sun, J. Cao, G. Han, W. Zhao, W. Zhang, Y . Shao, Y . Guo, and R. Xu, “Reinforcement learning with generaliz- able gaussian splatting,” inProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024
work page 2024
-
[31]
B. Zhou, S. Zheng, H. Tu, R. Shao, B. Liu, S. Zhang, L. Nie, and Y . Liu, “Gps-gaussian+: Generalizable pixel-wise 3d gaussian splatting for real-time human-scene rendering from sparse views,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[32]
Am-radio: Agglomerative vision foundation model – reduce all domains into one,
M. Ranzinger, G. Heinrich, J. Kautz, and P. Molchanov, “Am-radio: Agglomerative vision foundation model – reduce all domains into one,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 12 490–12 500
work page 2024
-
[33]
Rlbench: The robot learning benchmark & learning environment,
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison, “Rlbench: The robot learning benchmark & learning environment,”IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 3019–3026, 2020
work page 2020
-
[34]
Maniskill2: A unified benchmark for generalizable manipulation skills,
J. Gu, F. Xiang, X. Li, Z. Ling, X. Liu, T. Mu, Y . Tang, S. Tao, X. Wei, Y . Yaoet al., “Maniskill2: A unified benchmark for generalizable manipulation skills,”arXiv preprint arXiv:2302.04659, 2023
-
[35]
Where are we in the search for an artificial visual cortex for embodied intelligence?
A. Majumdar, K. Yadav, S. Arnaud, J. Ma, C. Chen, S. Silwal, A. Jain, V .-P. Berges, T. Wu, J. Vakilet al., “Where are we in the search for an artificial visual cortex for embodied intelligence?”Advances in Neural Information Processing Systems, vol. 36, pp. 655–677, 2023
work page 2023
-
[36]
Point cloud matters: Rethinking the impact of different observation spaces on robot learning,
H. Zhu, Y . Wang, D. Huang, W. Ye, W. Ouyang, and T. He, “Point cloud matters: Rethinking the impact of different observation spaces on robot learning,”Advances in Neural Information Processing Systems, vol. 37, pp. 77 799–77 830, 2024
work page 2024
-
[37]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,”arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Point transformer v3: Simpler faster stronger,
X. Wu, L. Jiang, P.-S. Wang, Z. Liu, X. Liu, Y . Qiao, W. Ouyang, T. He, and H. Zhao, “Point transformer v3: Simpler faster stronger,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 4840–4851
work page 2024
-
[39]
X. Liu, X. Liu, Y .-S. Liu, and Z. Han, “Spu-net: Self-supervised point cloud upsampling by coarse-to-fine reconstruction with self-projection optimization,”IEEE Transactions on Image Processing, vol. 31, pp. 4213–4226, 2022
work page 2022
-
[40]
Multimae: Multi-modal multi-task masked autoencoders,
R. Bachmann, D. Mizrahi, A. Atanov, and A. Zamir, “Multimae: Multi-modal multi-task masked autoencoders,” inEuropean Confer- ence on Computer Vision. Springer, 2022, pp. 348–367
work page 2022
-
[41]
Ponderv2: Pave the way for 3d foundation model with a universal pre-training paradigm,
H. Zhu, H. Yang, X. Wu, D. Huang, S. Zhang, X. He, H. Zhao, C. Shen, Y . Qiao, T. Heet al., “Ponderv2: Pave the way for 3d foundation model with a universal pre-training paradigm,”arXiv preprint arXiv:2310.08586, 2023
-
[42]
Query-based semantic gaussian field for scene representation in reinforcement learning,
J. Wang, Z. Zhang, Q. Zhang, J. Li, J. Sun, M. Sun, J. He, and R. Xu, “Query-based semantic gaussian field for scene representation in reinforcement learning,”arXiv preprint arXiv:2406.02370, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.