Understanding Rollout Error in Graph World Models
Pith reviewed 2026-06-29 04:47 UTC · model grok-4.3
The pith
Error-Aware Graph World Models prevent long-horizon rollout divergence while preserving prediction accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
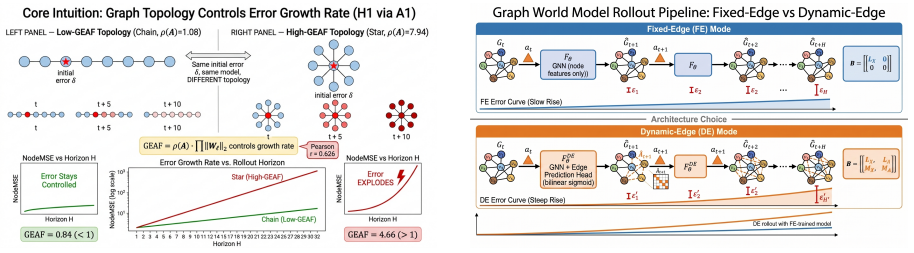
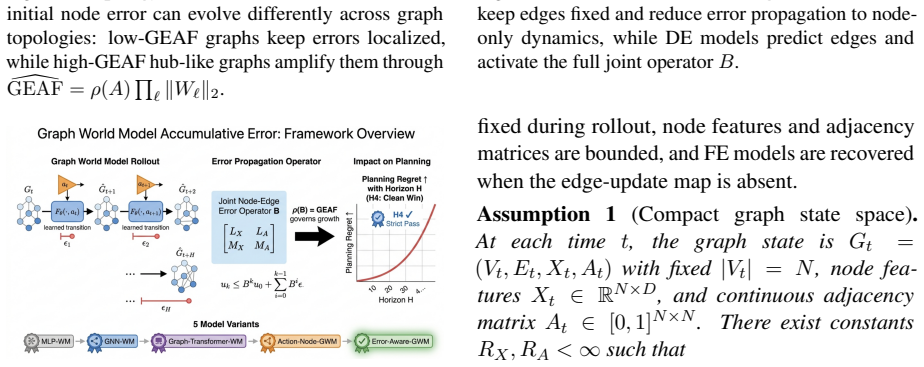
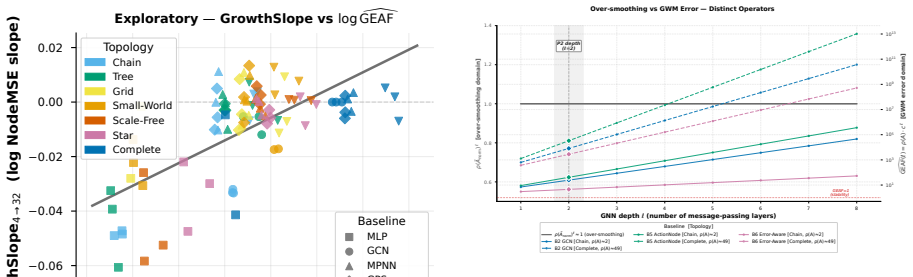
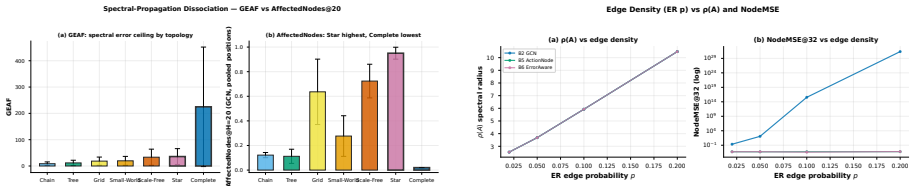
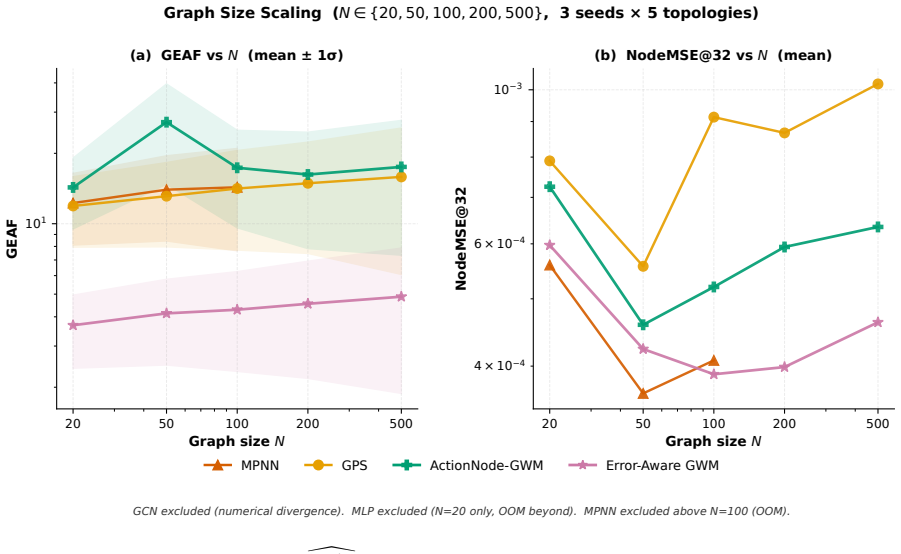
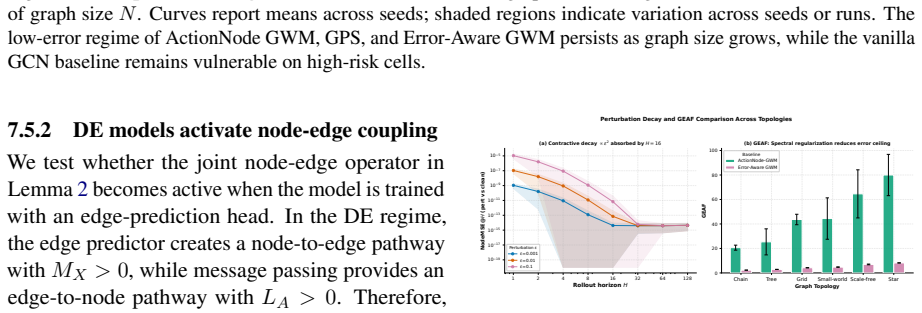
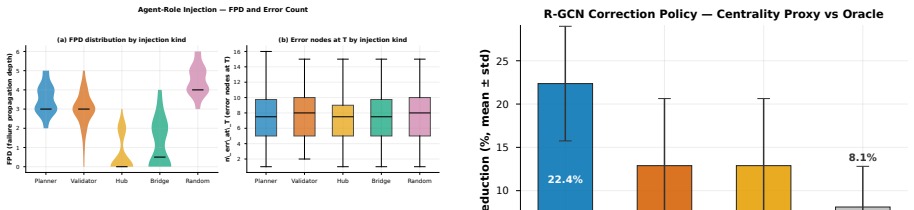
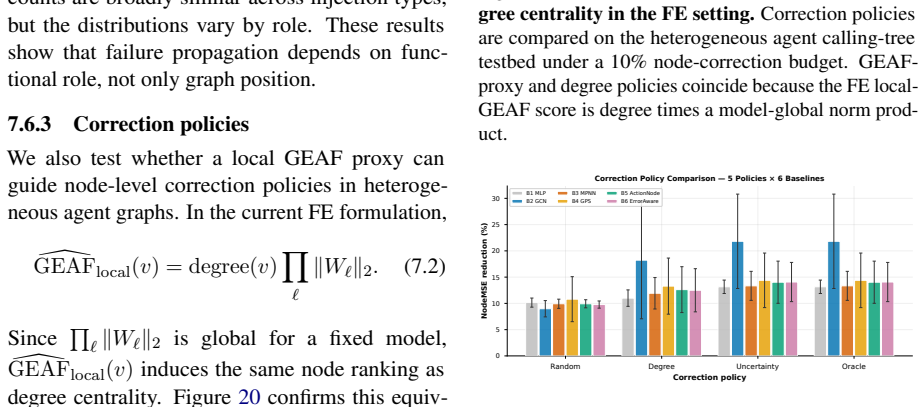
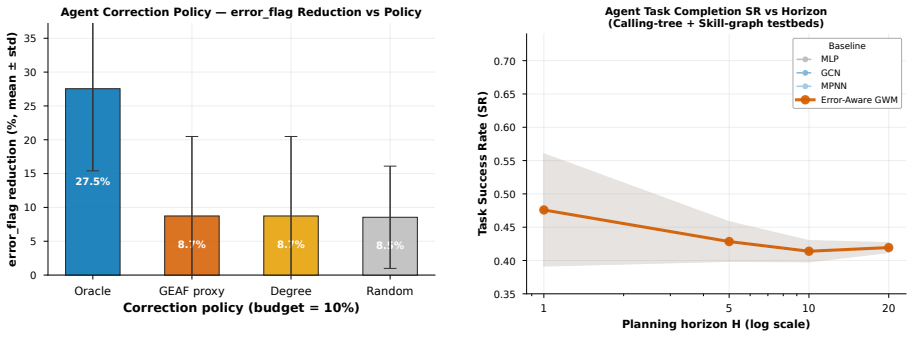
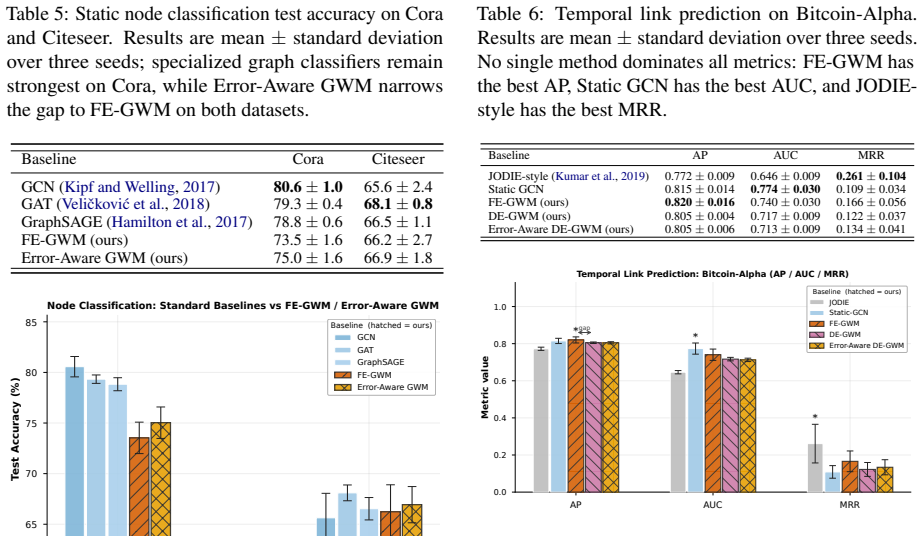
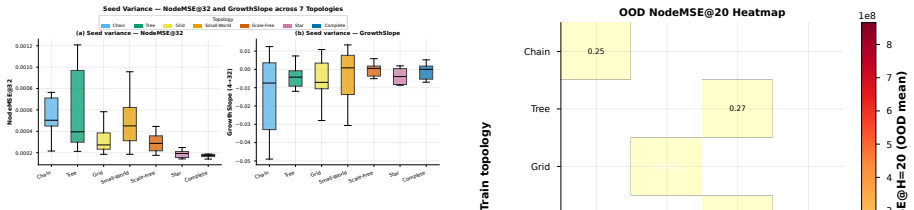
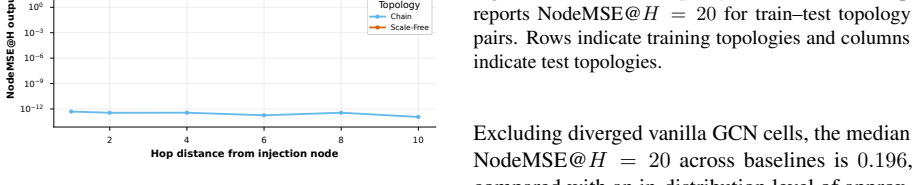
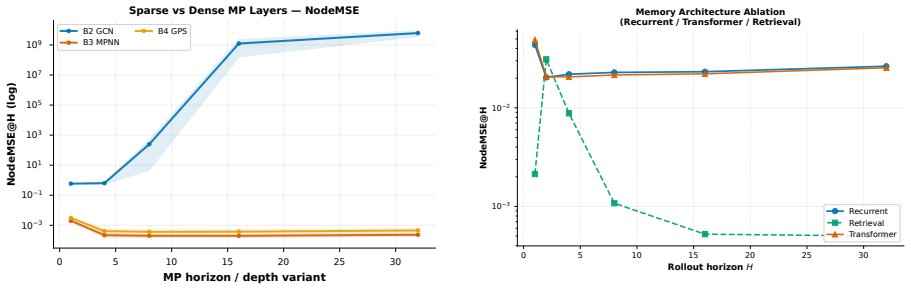
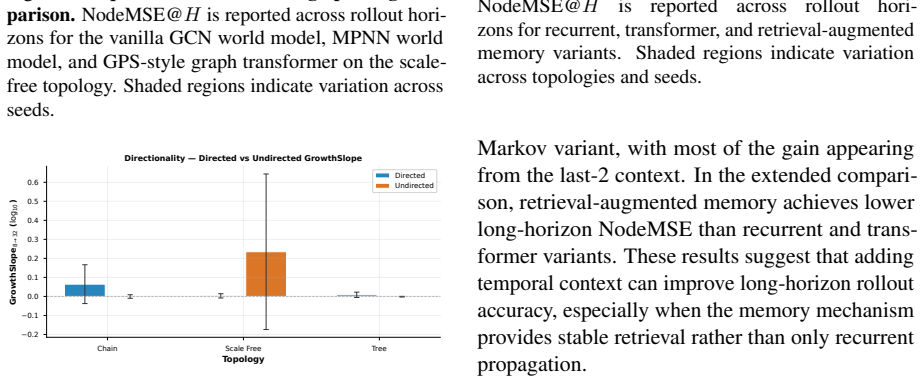
The authors formulate a unified fixed-edge and dynamic-edge GWM framework with action nodes for node-, edge-, and graph-level decisions, develop graph-valued rollout bounds that separate topology-induced amplification from model-induced amplification, introduce a joint node-edge operator for dynamic-edge rollouts, and propose Error-Aware GWM combining spectral regularization, rollout consistency, and critical-node weighting; across synthetic topologies and heterogeneous agent-graph testbeds this approach prevents long-horizon divergence while preserving prediction accuracy, with rollout error and planning regret growing with horizon and dynamic-edge training required when structure evolves.
What carries the argument
Graph-valued rollout bounds that separate topology-induced amplification from model-induced amplification, together with the joint node-edge operator for dynamic-edge cases.
If this is right
- Rollout error and planning regret increase with horizon length in both fixed and dynamic graph settings.
- Dynamic-edge training is required whenever the underlying graph structure evolves during rollout.
- Error-Aware GWM maintains short-term prediction accuracy while avoiding divergence at long horizons.
- Graph world models are most useful for dynamic graph rollout and agent planning tasks.
- Specialized graph models remain competitive on static or sparse prediction tasks.
Where Pith is reading between the lines
- The error-separation bounds could be used to design hybrid models that explicitly correct for known topological amplification effects.
- The same analysis framework might apply to planning in other structured domains such as molecular interaction graphs or transportation networks.
- Scalability tests on larger real-world dynamic graphs would reveal whether the joint node-edge operator remains tractable.
- Combining Error-Aware GWM with model-based reinforcement learning planners could improve sample efficiency in graph-structured environments.
Load-bearing premise
The graph-valued rollout bounds can cleanly separate topology-induced amplification from model-induced amplification for both fixed-edge and dynamic-edge cases.
What would settle it
A controlled experiment on a new dynamic graph environment in which the measured long-horizon divergence rates violate the predicted bounds or in which Error-Aware GWM shows no reduction in divergence relative to a standard GWM baseline.
Figures
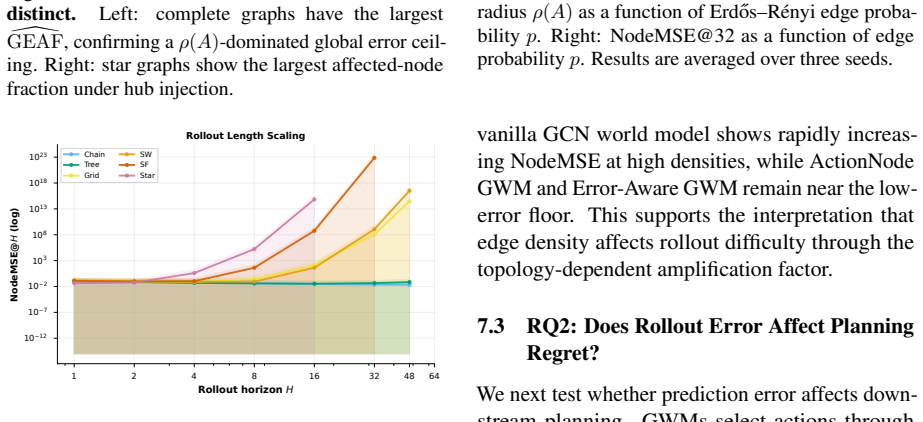
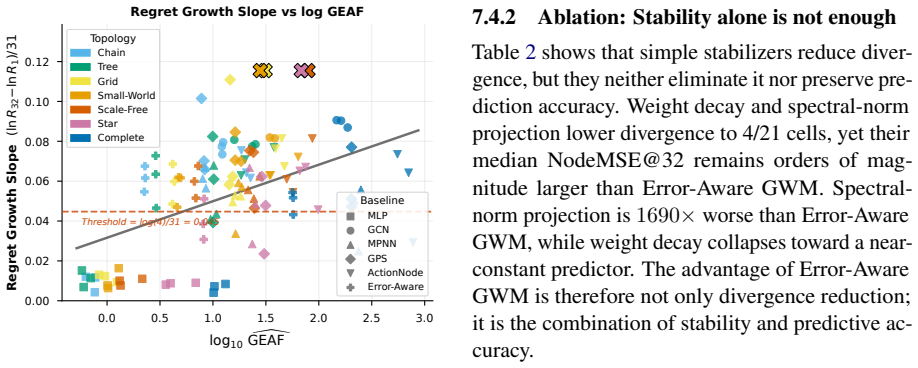
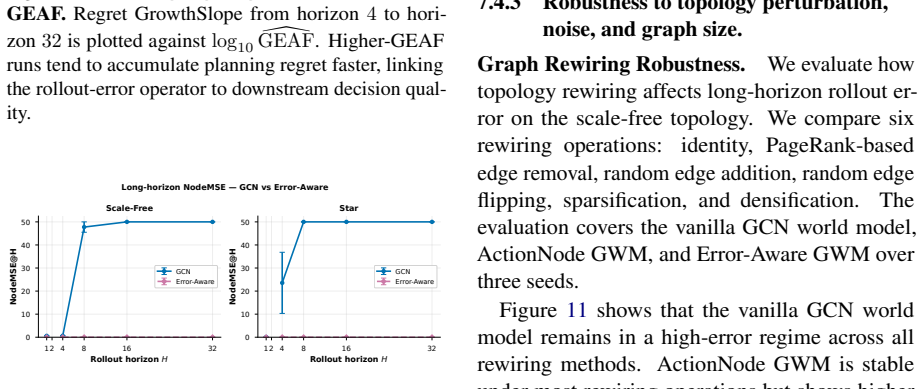
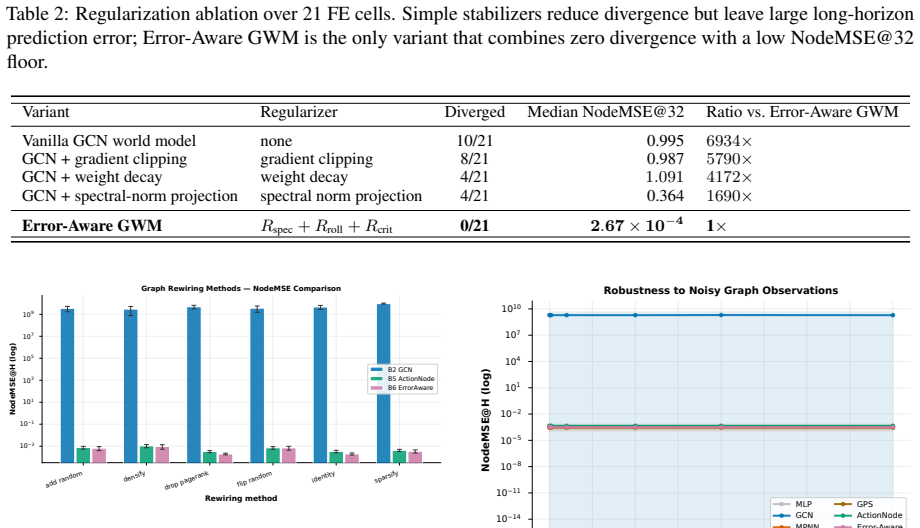


read the original abstract
World models are often used for planning by rolling learned dynamics forward. Many planning environments, however, are not vectors or images; they are graphs of agents, tools, skills, routes, and dependencies. In these settings, a local prediction error may stay local or spread through the graph, and the failure mode changes again when edges are predicted rather than fixed. This paper studies long-horizon rollout error in Graph World Models (GWMs). We formulate a unified fixed-edge and dynamic-edge GWM framework with action nodes for node-, edge-, and graph-level decisions. We develop graph-valued rollout bounds that separate topology-induced amplification from model-induced amplification, and we introduce a joint node-edge operator for dynamic-edge rollouts. Guided by the analysis, we propose Error-Aware GWM, which combines spectral regularization, rollout consistency, and critical-node weighting. Across synthetic topologies and heterogeneous agent-graph testbeds, rollout error and planning regret grow with horizon, dynamic-edge training is needed when structure evolves, and Error-Aware GWM prevents long-horizon divergence while preserving prediction accuracy. Real-world graph benchmarks clarify the scope of GWMs: they are most useful for dynamic graph rollout and agent planning, while specialized graph models remain strong on static or sparse prediction tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to study long-horizon rollout error in Graph World Models (GWMs) by formulating a unified framework for fixed-edge and dynamic-edge cases with action nodes. It develops graph-valued rollout bounds separating topology-induced from model-induced amplification, introduces a joint node-edge operator for dynamic-edge rollouts, and proposes Error-Aware GWM using spectral regularization, rollout consistency, and critical-node weighting. Experiments across synthetic topologies and heterogeneous agent-graph testbeds indicate that rollout error grows with horizon, dynamic-edge training is necessary for evolving structures, and Error-Aware GWM prevents divergence while maintaining prediction accuracy. Real-world benchmarks suggest GWMs are useful for dynamic graph rollout and agent planning.
Significance. Should the derived bounds rigorously separate the two sources of amplification and the experimental results demonstrate clear improvements with statistical significance, this work would offer valuable theoretical and practical guidance for designing robust world models in graph-structured environments, particularly for long-horizon planning where error propagation is a key concern. The unified treatment of fixed and dynamic edges addresses an important extension beyond standard vector or image-based world models.
major comments (2)
- Abstract: The central claim that the graph-valued rollout bounds separate topology-induced amplification from model-induced amplification, including for the joint node-edge operator in dynamic-edge cases, lacks any derivation steps, explicit assumptions, or proof sketches. This makes it impossible to assess whether the separation remains valid when edge predictions depend on prior node states, as the operator may couple the sources.
- Abstract: No quantitative experimental results, error bars, specific metrics (e.g., rollout error values, planning regret), or comparisons to baselines are provided, undermining the ability to verify claims about Error-Aware GWM preventing long-horizon divergence while preserving accuracy across testbeds.
minor comments (1)
- The abstract mentions 'real-world graph benchmarks' but does not specify which ones or how they clarify the scope of GWMs relative to specialized graph models.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. Both comments correctly identify that the abstract is too concise to fully convey the derivations or quantitative results. We will revise the abstract to incorporate a brief outline of the key assumptions, separation result, and sample metrics while remaining within length limits. The full manuscript already contains the supporting material in Sections 3 and 5; the revisions will make this more immediately accessible from the abstract. We respond to each major comment below.
read point-by-point responses
-
Referee: Abstract: The central claim that the graph-valued rollout bounds separate topology-induced amplification from model-induced amplification, including for the joint node-edge operator in dynamic-edge cases, lacks any derivation steps, explicit assumptions, or proof sketches. This makes it impossible to assess whether the separation remains valid when edge predictions depend on prior node states, as the operator may couple the sources.
Authors: We agree that the abstract omits derivation steps and proof sketches. The manuscript derives the bounds in Section 3 by decomposing the rollout operator into a topology-dependent amplification term (controlled by the spectral radius of the graph operator) and an additive model-error term (bounded by the predictor's Lipschitz constant). For the dynamic-edge case the joint node-edge operator is defined so that edge predictions are applied after the current node state, allowing the two error sources to be bounded separately; the proof sketch appears in Appendix A under the stated assumptions of bounded node features and Lipschitz-continuous predictors. We will revise the abstract to state the main assumptions and the separation result explicitly, thereby addressing the concern about potential coupling. revision: yes
-
Referee: Abstract: No quantitative experimental results, error bars, specific metrics (e.g., rollout error values, planning regret), or comparisons to baselines are provided, undermining the ability to verify claims about Error-Aware GWM preventing long-horizon divergence while preserving accuracy across testbeds.
Authors: We agree that the abstract presents only qualitative summaries of the experimental findings. The full manuscript reports quantitative results in Section 5, including rollout error curves with error bars across horizons, planning regret values, and statistical comparisons (paired t-tests) against standard GNN and RNN baselines on both synthetic and real-world testbeds. To allow immediate verification of the claims about divergence prevention and accuracy preservation, we will revise the abstract to include one or two representative quantitative highlights drawn from those tables and figures. revision: yes
Circularity Check
No circularity: derivation chain self-contained with no reductions to fitted inputs or self-citations shown
full rationale
The abstract formulates a unified GWM framework, develops graph-valued rollout bounds separating topology-induced from model-induced amplification, introduces a joint node-edge operator, and proposes Error-Aware GWM combining spectral regularization, rollout consistency, and critical-node weighting. No equations, self-citations, or fitted parameters are quoted that reduce any prediction or bound to its own inputs by construction. The reader's assessment notes absence of indication that bounds or method reduce to fitted quantities. Without load-bearing steps that collapse to self-definition or fitted renaming, the analysis remains independent of its outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Machine Learning (ICML) , year =
Lipschitz Continuity in Model-based Reinforcement Learning , author =. International Conference on Machine Learning (ICML) , year =
-
[2]
Science , volume=
Emergence of Scaling in Random Networks , author=. Science , volume=. 1999 , publisher=
1999
-
[3]
Nature , volume=
Collective Dynamics of `Small-World' Networks , author=. Nature , volume=. 1998 , publisher=
1998
-
[4]
Advances in Neural Information Processing Systems (NeurIPS) , year =
When to Trust Your Model: Model-Based Policy Optimization , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[5]
2024 , eprint=
A Note on Loss Functions and Error Compounding in Model-based Reinforcement Learning , author=. 2024 , eprint=
2024
-
[6]
International Conference on Machine Learning (ICML) , year =
Model-Based Reinforcement Learning with Value-Targeted Regression , author =. International Conference on Machine Learning (ICML) , year =
-
[7]
2019 , eprint=
Learning to Combat Compounding-Error in Model-Based Reinforcement Learning , author=. 2019 , eprint=
2019
-
[8]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Recurrent World Models Facilitate Policy Evolution , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[9]
World Models , author=. arXiv preprint arXiv:1803.10122 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Proceedings of the 36th International Conference on Machine Learning , pages=
Learning Latent Dynamics for Planning from Pixels , author=. Proceedings of the 36th International Conference on Machine Learning , pages=
-
[11]
International Conference on Learning Representations , year=
Dream to Control: Learning Behaviors by Latent Imagination , author=. International Conference on Learning Representations , year=
-
[12]
International Conference on Learning Representations , year=
Mastering Atari with Discrete World Models , author=. International Conference on Learning Representations , year=
-
[13]
International Conference on Learning Representations , year =
Semi-Supervised Classification with Graph Convolutional Networks , author =. International Conference on Learning Representations , year =
-
[14]
Proceedings of the 34th International Conference on Machine Learning , pages =
Neural Message Passing for Quantum Chemistry , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , series =
2017
-
[15]
Advances in Neural Information Processing Systems , volume =
Recipe for a General, Powerful, Scalable Graph Transformer , author =. Advances in Neural Information Processing Systems , volume =
-
[16]
International Conference on Machine Learning , year =
Graph World Model , author =. International Conference on Machine Learning , year =
-
[17]
International Conference on Learning Representations , year=
Transformers are Sample-Efficient World Models , author=. International Conference on Learning Representations , year=
-
[18]
Proceedings of the 6th Conference on Robot Learning , pages=
DayDreamer: World Models for Physical Robot Learning , author=. Proceedings of the 6th Conference on Robot Learning , pages=
-
[19]
Hansen, Nicklas and Su, Hao and Wang, Xiaolong , booktitle=
-
[20]
Learning Latent Dynamics for Planning from Pixels
Learning Latent Dynamics for Planning from Pixels , author =. arXiv preprint arXiv:1811.04551 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
International Conference on Learning Representations (ICLR) , year =
Dream to Control: Learning Behaviors by Latent Imagination , author =. International Conference on Learning Representations (ICLR) , year =
-
[22]
Mastering Diverse Domains through World Models
Mastering Diverse Domains through World Models , author =. arXiv preprint arXiv:2301.04104 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Nature , year =
Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model , author =. Nature , year =
-
[24]
International Conference on Machine Learning (ICML) , year =
Graph World Model , author =. International Conference on Machine Learning (ICML) , year =
-
[25]
Graph World Models: Concepts, Taxonomy, and Future Directions
Graph World Models: Concepts, Taxonomy, and Future Directions , author =. arXiv preprint arXiv:2604.27895 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
International Conference on Machine Learning (ICML) , year =
World Model as a Graph: Learning Latent Landmarks for Planning , author =. International Conference on Machine Learning (ICML) , year =
-
[27]
International Conference on Learning Representations (ICLR) , year =
Value Memory Graph: A Graph-Structured World Model for Offline Reinforcement Learning , author =. International Conference on Learning Representations (ICLR) , year =
-
[28]
2025 , eprint=
SPARTAN: A Sparse Transformer World Model Attending to What Matters , author=. 2025 , eprint=
2025
-
[29]
2025 , eprint=
Dyn-O: Building Structured World Models with Object-Centric Representations , author=. 2025 , eprint=
2025
-
[30]
2025 , eprint=
BAgger: Backwards Aggregation for Mitigating Drift in Autoregressive Video Diffusion Models , author=. 2025 , eprint=
2025
-
[31]
International Joint Conference on Artificial Intelligence (IJCAI) , year =
AriGraph: Learning Knowledge Graph World Models with Episodic Memory for LLM Agents , author =. International Joint Conference on Artificial Intelligence (IJCAI) , year =
-
[32]
International Conference on Learning Representations (ICLR) , year =
Contrastive Learning of Structured World Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[33]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Learning Knowledge Graph-based World Models of Textual Environments , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[34]
International Conference on Learning Representations (ICLR) , year =
Graph Neural Networks Exponentially Lose Expressive Power For Node Classification , author =. International Conference on Learning Representations (ICLR) , year =
-
[35]
2023 , eprint=
A Survey on Oversmoothing in Graph Neural Networks , author=. 2023 , eprint=
2023
-
[36]
Relational inductive biases, deep learning, and graph networks
Relational Inductive Biases, Deep Learning, and Graph Networks , author =. arXiv preprint arXiv:1806.01261 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
VRAG: Learning World Models for Interactive Video Generation
Learning World Models for Interactive Video Generation , author=. arXiv preprint arXiv:2505.21996 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Hierarchical Planning with Latent World Models
Hierarchical Planning with Latent World Models , author=. arXiv preprint arXiv:2604.03208 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Reinforcement Learning Journal , volume=
Long-Horizon Planning with Predictable Skills , author=. Reinforcement Learning Journal , volume=
-
[40]
arXiv preprint arXiv:2511.23465 , year=
SmallWorlds: Assessing Dynamics Understanding of World Models in Isolated Environments , author=. arXiv preprint arXiv:2511.23465 , year=
-
[41]
2026 , eprint=
GraSP: Graph-Structured Skill Compositions for LLM Agents , author=. 2026 , eprint=
2026
-
[42]
arXiv preprint arXiv:2507.08800 , year=
NeuralOS: Towards Simulating Operating Systems via Neural Generative Models , author=. arXiv preprint arXiv:2507.08800 , year=
-
[43]
Prismatic World Model: Learning Compositional Dynamics for Planning in Hybrid Systems
Prismatic World Model: Learning Compositional Dynamics for Planning in Hybrid Systems , author=. arXiv preprint arXiv:2512.08411 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Long-Horizon Model-Based Offline Reinforcement Learning Without Explicit Conservatism
Long-Horizon Model-Based Offline Reinforcement Learning Without Conservatism , author=. arXiv preprint arXiv:2512.04341 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
ACM SIGKDD Conference on Knowledge Discovery and Data Mining , year =
ROLAND: Graph Learning Framework for Dynamic Graphs , author =. ACM SIGKDD Conference on Knowledge Discovery and Data Mining , year =
-
[46]
International Conference on Machine Learning (ICML) , year =
GraphRNN: Generating Realistic Graphs with Deep Auto-regressive Models , author =. International Conference on Machine Learning (ICML) , year =
-
[47]
International Conference on Learning Representations (ICLR) , year =
DiGress: Discrete Denoising Diffusion for Graph Generation , author =. International Conference on Learning Representations (ICLR) , year =
-
[48]
From Spark to Fire: Modeling and Mitigating Error Cascades in LLM-Based Multi-Agent Collaboration
From Spark to Fire: Modeling and Mitigating Error Cascades in LLM-Based Multi-Agent Collaboration , author =. arXiv preprint arXiv:2603.04474 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
2026 , eprint=
Evaluating Tool-Using Language Agents: Judge Reliability, Propagation Cascades, and Runtime Mitigation in AgentProp-Bench , author=. 2026 , eprint=
2026
-
[50]
2024 , eprint=
The Effectiveness of Curvature-Based Rewiring and the Role of Hyperparameters in GNNs Revisited , author=. 2024 , eprint=
2024
-
[51]
2025 , eprint=
PIORF: Physics-Informed Ollivier-Ricci Flow for Long-Range Interactions in Mesh Graph Neural Networks , author=. 2025 , eprint=
2025
-
[52]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[53]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Recipe for a General, Powerful, Scalable Graph Transformer , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[54]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Do Transformers Really Perform Bad for Graph Representation? , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[55]
arXiv preprint arXiv:2512.23760 , year =
Audited Skill-Graph Self-Improvement for Agentic LLMs via Verifiable Rewards, Experience Synthesis, and Continual Memory , author =. arXiv preprint arXiv:2512.23760 , year =
-
[56]
2026 , eprint=
CASCADE: Cumulative Agentic Skill Creation through Autonomous Development and Evolution , author=. 2026 , eprint=
2026
-
[57]
2026 , eprint=
Reinforcement Learning for Self-Improving Agent with Skill Library , author=. 2026 , eprint=
2026
-
[58]
International Conference on Learning Representations (ICLR) , year =
Semi-Supervised Classification with Graph Convolutional Networks , author =. International Conference on Learning Representations (ICLR) , year =
-
[59]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Inductive Representation Learning on Large Graphs , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[60]
International Conference on Learning Representations (ICLR) , year =
Graph Attention Networks , author =. International Conference on Learning Representations (ICLR) , year =
-
[61]
International Conference on Machine Learning (ICML) , year =
Neural Message Passing for Quantum Chemistry , author =. International Conference on Machine Learning (ICML) , year =
-
[62]
International Conference on Machine Learning (ICML) , year =
Approximately Optimal Approximate Reinforcement Learning , author =. International Conference on Machine Learning (ICML) , year =
-
[63]
Proceedings of the 41st International Conference on Machine Learning , year=
Genie: Generative Interactive Environments , author=. Proceedings of the 41st International Conference on Machine Learning , year=
-
[64]
Wu, Jialong and Hu, Shaofeng and Guo, Ningya and Guo, Lanqing and Du, Jian and Yan, Junwei and Hao, Jianye and Huang, Minlie , journal=
-
[65]
The Twelfth International Conference on Learning Representations , year=
One for All: Towards Training One Graph Model for All Classification Tasks , author=. The Twelfth International Conference on Learning Representations , year=
-
[66]
2024 , publisher=
Chen, Runjin and Zhao, Tong and Jaiswal, Ajay and Shah, Neil and Wang, Zhangyang , booktitle=. 2024 , publisher=
2024
-
[67]
International Conference on Learning Representations , year=
Graph Attention Networks , author=. International Conference on Learning Representations , year=
-
[68]
Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=
Predicting Dynamic Embedding Trajectory in Temporal Interaction Networks , author=. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=
-
[69]
Proceedings of the 33rd International Conference on Machine Learning , year=
Revisiting Semi-Supervised Learning with Graph Embeddings , author=. Proceedings of the 33rd International Conference on Machine Learning , year=
-
[70]
Advances in Neural Information Processing Systems , volume=
Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models , author=. Advances in Neural Information Processing Systems , volume=
-
[71]
Advances in Neural Information Processing Systems , volume=
Interaction Networks for Learning about Objects, Relations and Physics , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
Proceedings of the 35th International Conference on Machine Learning , pages=
Graph Networks as Learnable Physics Engines for Inference and Control , author=. Proceedings of the 35th International Conference on Machine Learning , pages=. 2018 , series=
2018
-
[73]
and Bronstein, Michael and Webb, Stefan and Rossi, Emanuele , booktitle=
Chamberlain, Ben and Rowbottom, James and Gorinova, Maria I. and Bronstein, Michael and Webb, Stefan and Rossi, Emanuele , booktitle=. 2021 , series=
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.