MakeupMirror: Improving Facial Attribute Preservation in Diffusion Models for Makeup Transfer
Pith reviewed 2026-06-26 17:58 UTC · model grok-4.3
The pith
MakeupMirror improves facial identity and skin tone preservation in diffusion models for makeup transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
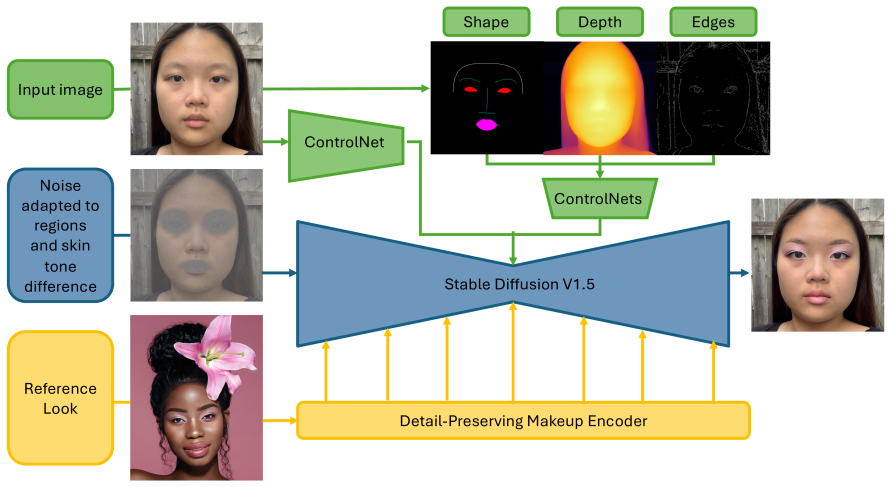
MakeupMirror integrates facial geometry conditioning with ControlNets, region-specific makeup transfer control, skin tone-based makeup transfer modulation, and a Levenberg-Marquardt Langevin sampler to maintain facial fidelity and prevent skin tone alteration while transferring makeup in diffusion models.
What carries the argument
The four-way conditioning stack of ControlNet facial geometry, region-specific makeup controls, skin tone modulation, and optimized Langevin sampling that together steer the diffusion process toward identity-preserving outputs.
Load-bearing premise
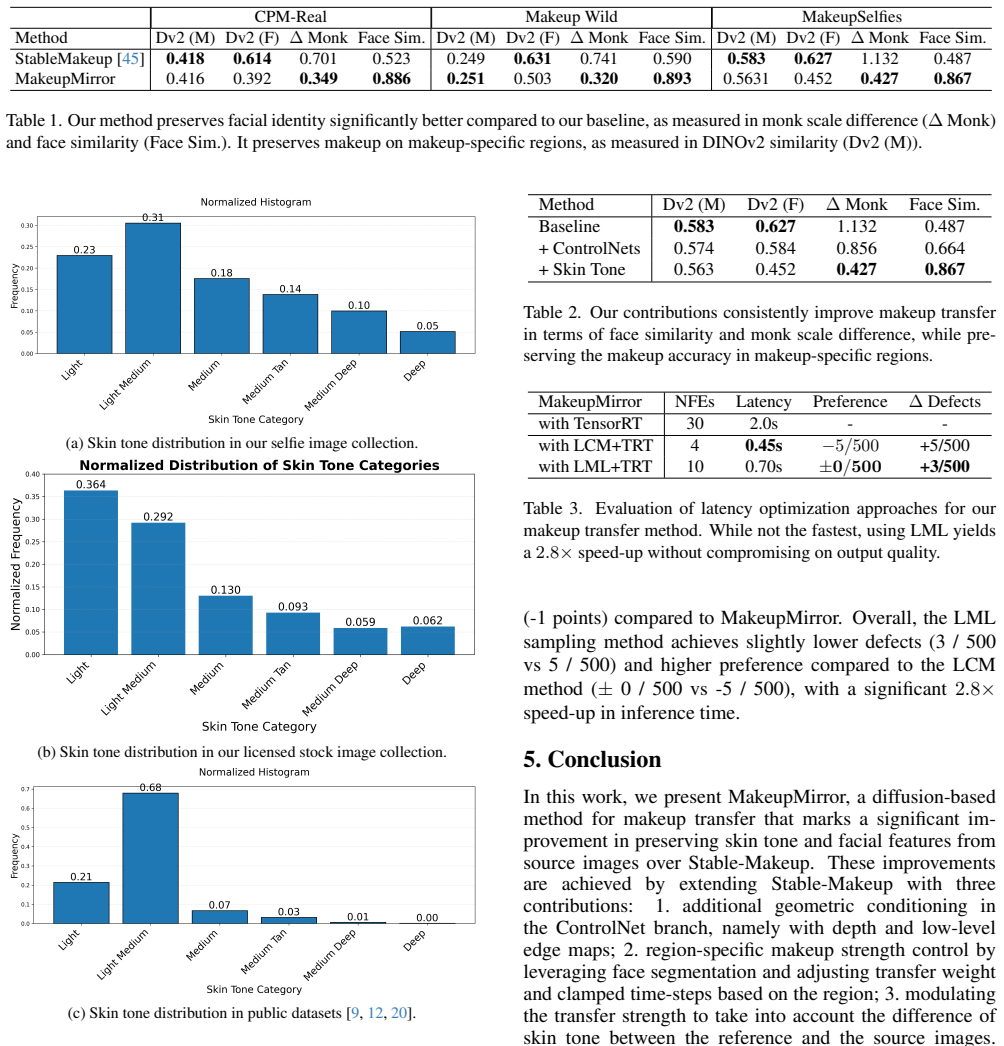
The evaluation metrics and newly collected MakeupSelfies dataset provide an unbiased and representative measure of facial attribute preservation that generalizes beyond the tested scenarios.
What would settle it
A follow-up test on a held-out set of faces with different demographics or lighting that shows no measurable gain in facial recognition similarity or skin tone difference relative to Stable-Makeup.
Figures



read the original abstract
Makeup transfer models enable fun augmented reality (AR) experiences as well as virtual try-on (VTO) for online makeup shopping. While recent state-of-the-art diffusion based solutions such as Stable-Makeup dramatically improve the accuracy and realism of makeup transfer, they still face limitations in identity and skin color preservation, making production-level VTO for makeup shopping unrealistic. In this work, we propose MakeupMirror, a diffusion-based approach to makeup transfer that makes significant progress towards preserving facial features and skin tone. We introduce several technical innovations over Stable-Makeup: (1) integration of facial geometry conditioning with ControlNets to maintain facial fidelity; (2) region-specific makeup transfer control to enable precise makeup application across facial regions such as skin, eyes and lips; (3) skin tone-based makeup transfer modulation that prevent skin tone alteration in cross-subject transfer scenarios; and (4) integration of a Levenberg-Marquardt Langevin sampler to speed up inference while maintaining generation quality. Our experiments on CPM-Real, Makeup Wild, and (herein newly collected, more diverse) MakeupSelfies datasets show that MakeupMirror improves relative facial recognition similarity by +60%, reduces relative skin tone difference by -50% over Stable-Makeup, with a latency of 0.7s, while achieving expert acceptance rate of 94% across core facial identity preservation criteria.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MakeupMirror, a diffusion-based makeup transfer model that builds on Stable-Makeup with four technical additions: facial geometry conditioning via ControlNets, region-specific makeup transfer control, skin-tone-based modulation to avoid cross-subject color shifts, and a Levenberg-Marquardt Langevin sampler for faster inference. On CPM-Real, Makeup Wild, and a newly collected MakeupSelfies dataset, the method is reported to deliver +60% relative facial-recognition similarity, -50% relative skin-tone difference, 0.7 s latency, and 94% expert acceptance on identity-preservation criteria.
Significance. If the reported gains are reproducible under controlled conditions, the work would constitute a practical step toward production-grade virtual try-on by directly targeting the identity and skin-tone failure modes that currently limit diffusion-based AR makeup applications.
major comments (1)
- The abstract (and therefore the central empirical claim) presents performance deltas without any description of experimental protocols, statistical tests, number of runs, or controls for confounding factors such as dataset composition or prompt engineering; this absence prevents assessment of whether the +60% / -50% figures are load-bearing or artifactual.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in how the central empirical claims are presented. We address the comment below and commit to revisions that improve clarity without changing the reported results.
read point-by-point responses
-
Referee: The abstract (and therefore the central empirical claim) presents performance deltas without any description of experimental protocols, statistical tests, number of runs, or controls for confounding factors such as dataset composition or prompt engineering; this absence prevents assessment of whether the +60% / -50% figures are load-bearing or artifactual.
Authors: We agree that the abstract, as currently written, does not describe the experimental protocols, statistical tests, number of runs, or explicit controls for confounding factors. The manuscript body (Section 4) details the three datasets, metrics, and comparison to Stable-Makeup, but the abstract itself provides no such context. We will revise the abstract to include a concise statement of the evaluation protocol (datasets, fixed reference/prompt setup, and identity/skin-tone metrics) and will add a pointer to the Experiments section. We will also ensure the Experiments section explicitly states the number of runs, any statistical testing performed, and controls applied for dataset composition and prompt engineering. These changes will be made in the next revision. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and available context present empirical comparisons of MakeupMirror against Stable-Makeup on CPM-Real, Makeup Wild, and MakeupSelfies datasets, reporting quantitative improvements in facial recognition similarity, skin tone difference, latency, and expert acceptance. No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing steps are described. The central claims rest on experimental results rather than any self-referential construction or ansatz smuggled via citation, making the work self-contained against external benchmarks with no reduction of outputs to inputs by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
A. Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, and Dominik Lorenz. Sta- ble video diffusion: Scaling latent video diffusion models to large datasets.ArXiv, abs/2311.15127, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
A computational approach to edge detection
John Canny. A computational approach to edge detection. IEEE Transactions on Pattern Analysis and Machine Intelli- gence, PAMI-8(6):679–698, 1986. 2, 3, 4
1986
-
[3]
Diffusion models beat gans on image synthesis.Advances in Neural Informa- tion Processing Systems, 34, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in Neural Informa- tion Processing Systems, 34, 2021. 2
2021
-
[4]
Efros, and Aleksander Holynski
Dave Epstein, Allan Jabri, Ben Poole, Alexei A. Efros, and Aleksander Holynski. Diffusion self-guidance for control- lable image generation. InProceedings of the 37th Inter- national Conference on Neural Information Processing Sys- tems, Red Hook, NY , USA, 2023. Curran Associates Inc. 2
2023
-
[5]
Ladn: Local adversarial disentangling net- work for facial makeup and de-makeup
Qiao Gu, Guanzhi Wang, Mang Tik Chiu, Yu-Wing Tai, and Chi-Keung Tang. Ladn: Local adversarial disentangling net- work for facial makeup and de-makeup. InProceedings of the IEEE/CVF International conference on computer vision, pages 10481–10490, 2019. 2
2019
-
[6]
Digital face makeup by exam- ple.2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 73–79, 2009
Dong Guo and Terence Sim. Digital face makeup by exam- ple.2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 73–79, 2009. 1, 2
2009
-
[7]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021. 2, 4
2021
-
[8]
Denoising diffu- sion probabilistic models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020. 2
2020
-
[9]
Psgan: Pose and expression ro- bust spatial-aware gan for customizable makeup transfer
Wentao Jiang, Si Liu, Chen Gao, Jie Cao, Ran He, Jiashi Feng, and Shuicheng Yan. Psgan: Pose and expression ro- bust spatial-aware gan for customizable makeup transfer. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 5194–5202, 2020. 1, 2, 5, 7
2020
-
[10]
Physically-based simulation of cosmetics via intrinsic image decomposition with facial priors.IEEE Trans
Chen Li, Kun Zhou, Hsiang-Tao Wu, and Stephen Lin. Physically-based simulation of cosmetics via intrinsic image decomposition with facial priors.IEEE Trans. Pattern Anal. Mach. Intell., 41(6):1455–1469, 2019. 1, 2
2019
-
[11]
Layerdiffusion: Layered controlled image editing with dif- fusion models
Pengzhi Li, Qinxuan Huang, Yikang Ding, and Zhiheng Li. Layerdiffusion: Layered controlled image editing with dif- fusion models. InSIGGRAPH Asia 2023 Technical Commu- nications, New York, NY , USA, 2023. Association for Com- puting Machinery. 2
2023
-
[12]
Beautygan: Instance-level facial makeup transfer with deep generative adversarial network
Tingting Li, Ruihe Qian, Chao Dong, Si Liu, Qiong Yan, Wenwu Zhu, and Liang Lin. Beautygan: Instance-level facial makeup transfer with deep generative adversarial network. InProceedings of the 26th ACM International Conference on Multimedia, page 645–653, New York, NY , USA, 2018. Association for Computing Machinery. 2, 5, 7
2018
-
[13]
wow! you are so beautiful today!
Luoqi Liu, Junliang Xing, Si Liu, Hui Xu, Xi Zhou, and Shuicheng Yan. “wow! you are so beautiful today!”.ACM Trans. Multimedia Comput. Commun. Appl., 11(1s), 2014. 1, 2
2014
-
[14]
Makeupdiffuse: a double image-controlled diffusion model for exquisite makeup transfer.The Visual Computer, pages 1–17, 2024
Xiongbo Lu, Feng Liu, Yi Rong, Yaxiong Chen, and Shengwu Xiong. Makeupdiffuse: a double image-controlled diffusion model for exquisite makeup transfer.The Visual Computer, pages 1–17, 2024. 2, 3
2024
-
[15]
Mediapipe: A framework for perceiving and processing reality
Camillo Lugaresi, Jiuqiang Tang, Hadon Nash, Chris Mc- Clanahan, Esha Uboweja, Michael Hays, Fan Zhang, Chuo- Ling Chang, Ming Yong, Juhyun Lee, Wan-Teh Chang, Wei Hua, Manfred Georg, and Matthias Grundmann. Mediapipe: A framework for perceiving and processing reality. InThird Workshop on Computer Vision for AR/VR at IEEE Computer Vision and Pattern Recog...
2019
-
[16]
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpaint- ing using denoising diffusion probabilistic models.arXiv preprint arXiv:2201.09865, 2022. 2
-
[17]
Latent Consistency Models: Synthesizing High- Resolution Images with Few-Step Inference, 2023
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent Consistency Models: Synthesizing High- Resolution Images with Few-Step Inference, 2023. 6
2023
-
[18]
The monk skin tone scale
Ellis Monk. The monk skin tone scale. 2023. 4
2023
-
[19]
Chong Mou, Xintao Wang, Liangbin Xie, Jian Zhang, Zhon- gang Qi, Ying Shan, and Xiaohu Feng. T2i-adapter: Learn- ing adapters to dig out more controllable ability for text-to- image diffusion models.arXiv preprint arXiv:2302.08453,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Lipstick ain’t enough: Beyond color matching for in-the-wild makeup transfer
Thao Nguyen, Anh Tran, and Minh Hoai. Lipstick ain’t enough: Beyond color matching for in-the-wild makeup transfer. InProceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), 2021. 2, 5, 7
2021
-
[21]
Maxime Oquab, Timoth ´ee Darcet, Theo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Rus- sell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang- Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nico- las Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patri...
2023
-
[22]
Qihe Pan, Yiming Wu, Xing Zhao, Liang Xie, Guodao Sun, and Ronghua Liang. Supervised makeup transfer with a cu- rated dataset: Decoupling identity and makeup features for enhanced transformation.arXiv preprint arXiv:2602.00729,
-
[23]
Geon Yeong Park, Inhwa Han, Serin Yang, Yeobin Hong, Seongmin Jeong, Heechan Jeon, Myeongjin Goh, Sung Won Yi, Jin Nam, and Jong Chul Ye. Dreammakeup: Face makeup customization using latent diffusion models.arXiv preprint arXiv:2510.10918, 2025. 2
-
[24]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. InThe Twelfth Interna- tional Conference on Learning Representations, 2023. 2
2023
-
[25]
Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever
Alec Radford, Jong Wook Kim, Chris Hallacy, A. Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from nat- ural language supervision. InICML, 2021. 4
2021
-
[26]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with clip latents.arXiv preprint arXiv:2204.06125, 1 (2):3, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2
2022
-
[28]
Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022. 2
2022
-
[29]
Boosted LightFace: A Hybrid DNN and GBM Model for Boosted Facial Recog- nition.Gazi University Journal of Science, 2026
Sefik Ilkin Serengil and Alper Ozpinar. Boosted LightFace: A Hybrid DNN and GBM Model for Boosted Facial Recog- nition.Gazi University Journal of Science, 2026. 5
2026
-
[30]
Shmt: Self- supervised hierarchical makeup transfer via latent diffusion models.Advances in neural information processing systems,
Zhaoyang Sun, Shengwu Xiong, Yaxiong Chen, Fei Du, Weihua Chen, Fang Wang, and Yi Rong. Shmt: Self- supervised hierarchical makeup transfer via latent diffusion models.Advances in neural information processing systems,
-
[31]
Kling Team. Kling-omni: A generalist generative frame- work for multimodal video synthesis.arXiv preprint arXiv:2512.16776, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2406.09203, 2024
Wan Team. Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2406.09203, 2024. 2
-
[33]
Wai-Shun Tong, Chi-Keung Tang, M. S. Brown, and Ying- Qing Xu. Example-based cosmetic transfer.15th Pa- cific Conference on Computer Graphics and Applications (PG’07), pages 211–218, 2007. 1, 2
2007
-
[34]
Linoy Tsaban and Apolin ´ario Passos. Ledits: Real image editing with ddpm inversion and semantic guidance.arXiv preprint arXiv:2307.00522, 2023. 2
-
[35]
Diffusion model alignment using direct preference optimization
Bram Wallace et al. Diffusion model alignment using direct preference optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 2
2024
-
[36]
Unleashing high- quality image generation in diffusion sampling using second- order levenberg-marquardt-langevin
Fangyikang Wang, Hubery Yin, Lei Qian, Yinan Li, Shaobin Zhuang, Huminhao Zhu, Yilin Zhang, Yanlong Tang, Chao Zhang, Hanbin Zhao, et al. Unleashing high- quality image generation in diffusion sampling using second- order levenberg-marquardt-langevin. InProceedings of the IEEE/CVF International Conference on Computer Vision,
-
[37]
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
Yichi Wu, Hongming Zhang, Xiaohui Li, Nian Wen, Yingxue Gao, Yelong Shen, and Nan Duan. A unified frame- work for incorporating human feedback into text-to-image generation.arXiv preprint arXiv:2305.06500, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Ramgan: Region attentive morph- ing gan for region-level makeup transfer
Jianfeng Xiang, Junliang Chen, Wenshuang Liu, Xianxu Hou, and Linlin Shen. Ramgan: Region attentive morph- ing gan for region-level makeup transfer. InComputer Vi- sion – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXII, page 719–735, Berlin, Heidelberg, 2022. Springer-Verlag. 2
2022
-
[39]
Edit every- thing: A text-guided generative system for images editing
Defeng Xie, Ruichen Wang, Jian Ma, Chen Chen, Haonan Lu, Dong Yang, Fobo Shi, and Xiaodong Lin. Edit every- thing: A text-guided generative system for images editing. arXiv preprint arXiv:2304.14006, 2023. 2
-
[40]
An automatic framework for example-based virtual makeup
Lin Xu, Yangzhou Du, and Yimin Zhang. An automatic framework for example-based virtual makeup. InProceed- ings of the 20th IEEE International Conference on Image Processing, pages 3206–3210, 2013. 1, 2
2013
-
[41]
Elegant: Exquisite and locally editable gan for makeup trans- fer
Chenyu Yang, Wanrong He, Yingqing Xu, and Yang Gao. Elegant: Exquisite and locally editable gan for makeup trans- fer. InEuropean conference on computer vision, pages 737–
-
[42]
Springer, 2022. 1, 2
2022
-
[43]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10371–10381, 2024. 2, 3, 4
2024
-
[44]
Haonan Yu, Xiangyu Chen, Kunhao Chen, Weiwei Shi, Xi- aodong Xie, Yong Zhang, Tao Qin, and Tie-Yan Liu. Lora: Low-rank adaptation for fast text-to-image diffusion fine- tuning.arXiv preprint arXiv:2307.02904, 2023. 2
-
[45]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 2, 3, 4
2023
-
[46]
Stablemakeup: When real-world makeup transfer meets dif- fusion model
Yuxuan Zhang, Yirui Yuan, Yiren Song, and Jiaming Liu. Stablemakeup: When real-world makeup transfer meets dif- fusion model. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Confer- ence Conference Papers, New York, NY , USA, 2025. Asso- ciation for Computing Machinery. 1, 2, 3, 5, 7
2025
-
[47]
Sine: Single image editing with text- to-image diffusion models
Zhixing Zhang, Ligong Han, Arnab Ghosh, Dimitris N Metaxas, and Jian Ren. Sine: Single image editing with text- to-image diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6027–6037, 2023. 2
2023
-
[48]
Jian Zhu, Shanyuan Liu, Liuzhuozheng Li, Yue Gong, He Wang, Bo Cheng, Yuhang Ma, Liebucha Wu, Xiaoyu Wu, Dawei Leng, et al. Flux-makeup: High-fidelity, identity- consistent, and robust makeup transfer via diffusion trans- former.arXiv preprint arXiv:2508.05069, 2025. 2, 3
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.