PEAR: Permutation-Equivariant Adaptive Routing Multi-Agent Debate
Pith reviewed 2026-06-29 16:49 UTC · model grok-4.3
The pith
PEAR dynamically reassigns roles in multi-agent LLM debates to remove fixed positional biases and raise accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PEAR is an inference-time protocol that dynamically reconfigures communication roles and sparse topologies across consecutive debate rounds by strategically switching agent-to-role assignments based on evolving agent states, and it is characterized as an equivariant sparse router that preserves accuracy under agent relabeling while reducing routing complexity and improving generalization.
What carries the argument
The permutation-equivariant adaptive router, which dynamically switches agent-to-role assignments to prevent any agent from permanently occupying a privileged position.
If this is right
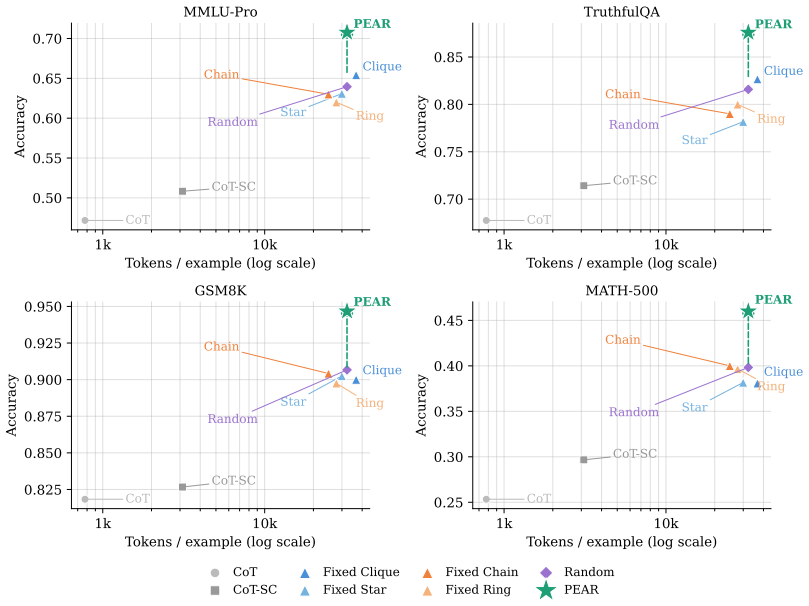
- PEAR improves average accuracy over the strongest debate baselines across four reasoning benchmarks.
- The gains hold across six diverse LLM backbones.
- The method reduces sensitivity to role assignments.
- The equivariant property ensures accuracy is preserved under agent relabeling.
Where Pith is reading between the lines
- The adaptive routing could apply to other multi-agent LLM interactions such as collaborative planning or voting.
- Enforcing permutation symmetry may stabilize performance in broader dynamic communication networks.
- Further tests with agents of highly unequal capabilities would show whether the state-based switching still distributes influence evenly.
Load-bearing premise
Strategically switching agent-to-role assignments based on evolving agent states will prevent any agent from permanently occupying a privileged network position and will distribute influence more evenly.
What would settle it
An experiment on the four reasoning benchmarks where disabling the role switching in PEAR produces no accuracy gain and no reduction in sensitivity to initial assignments would falsify the central claim.
Figures
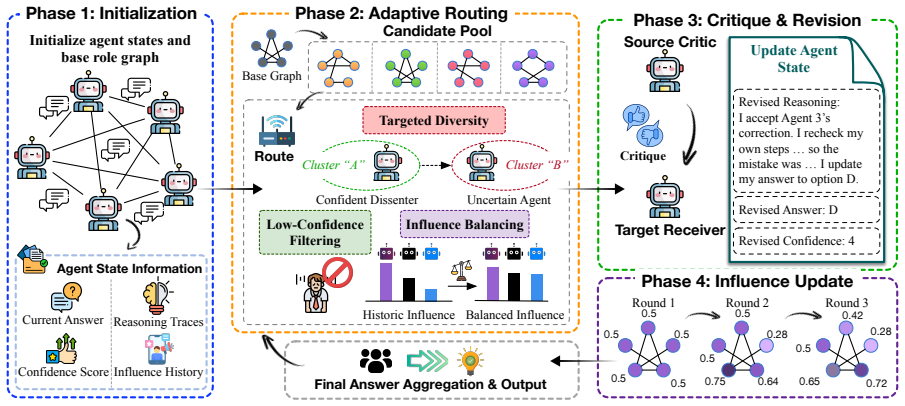
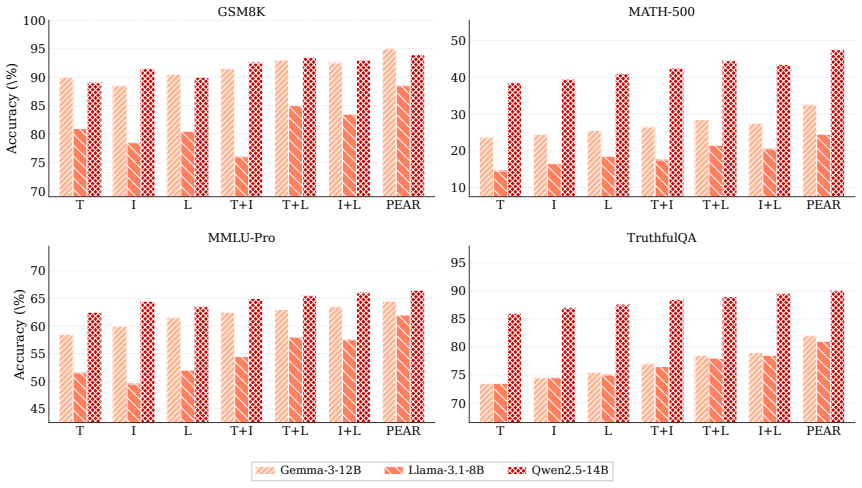
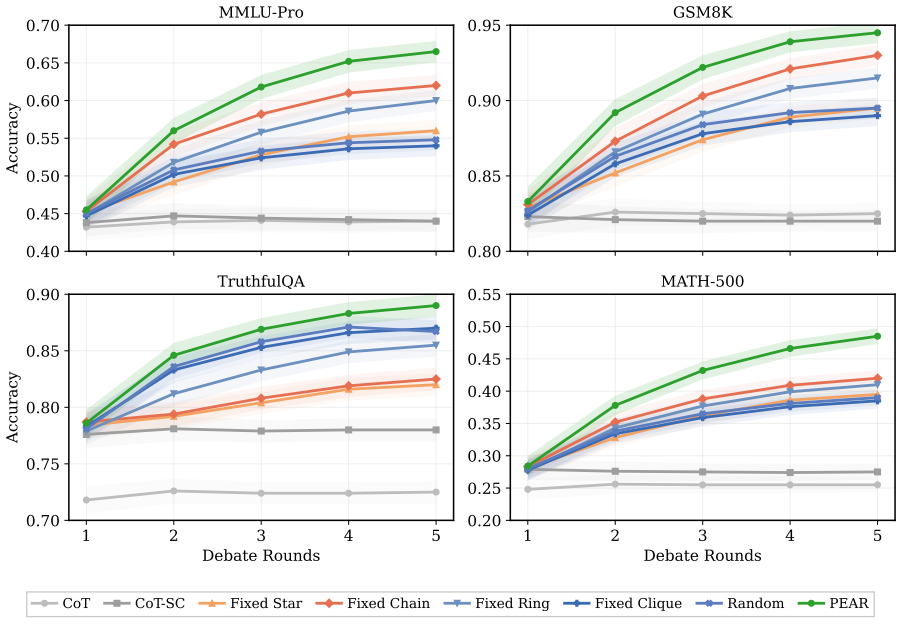
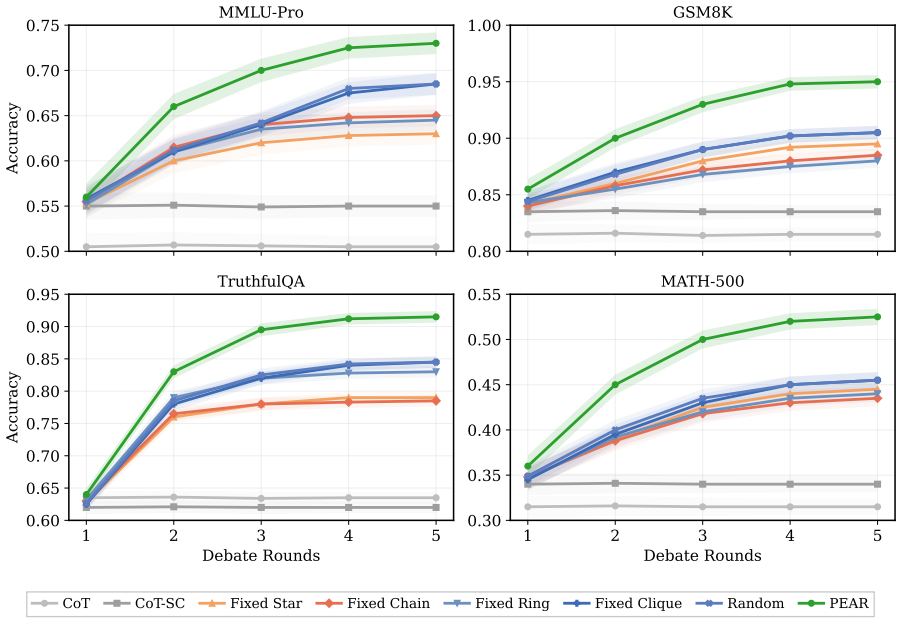
read the original abstract
Multi-agent debate improves the reliability of large language models (LLMs) through iterative peer critiques. However, fixed topologies often introduce persistent positional biases, amplify unreliable agents, and cause high sensitivity to role assignments. We introduce \textit{Permutation-Equivariant Adaptive Routing Multi-Agent Debate (PEAR)}, an inference-time protocol that dynamically reconfigures communication roles and sparse topologies across consecutive debate rounds. By strategically switching agent-to-role assignments based on evolving agent states, PEAR prevents any agent from permanently occupying a privileged network position or distributes influence more evenly across the debate. We theoretically characterize PEAR as an equivariant sparse router: it preserves accuracy under agent relabeling while reducing routing complexity and improving generalization. Comprehensive empirical evaluations across four reasoning benchmarks and six diverse LLM backbones demonstrate PEAR significantly improves average accuracy over the strongest debate baselines. The code is at https://github.com/EVIEHub/PEAR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PEAR, an inference-time multi-agent debate protocol for LLMs that dynamically reconfigures roles and sparse communication topologies across rounds by switching agent-to-role assignments based on evolving agent states. It claims to theoretically characterize PEAR as a permutation-equivariant sparse router that preserves accuracy under agent relabeling while reducing complexity and improving generalization, and reports significant average accuracy gains over strongest debate baselines across four reasoning benchmarks and six LLM backbones, with code released at https://github.com/EVIEHub/PEAR.
Significance. If the equivariance property and empirical gains hold under scrutiny, the work offers a structured way to address positional bias in multi-agent LLM debate systems. The released code supports reproducibility, which strengthens the contribution for the field.
major comments (2)
- [Abstract, §3] Abstract and §3 (Theoretical Characterization): the claim that PEAR 'preserves accuracy under agent relabeling' as an equivariant sparse router is load-bearing for the central contribution, yet the description of routing decisions based on 'evolving agent states' leaves open whether those states are invariant to permutation (e.g., via per-agent history or embeddings keyed to original labels). Without an explicit definition of the router function f and a proof that f(π(G), π(s)) = π(f(G, s)) for permutation π, the reduction in positional bias rests on an unverified assumption rather than a demonstrated property.
- [§4] §4 (Empirical Evaluation): the statement that PEAR 'significantly improves average accuracy over the strongest debate baselines' is central to the empirical claim, but the manuscript provides no details on baseline implementations, hyperparameter matching, statistical significance tests, or variance across runs; without these, it is impossible to determine whether the reported gains are attributable to the adaptive routing or to uncontrolled differences in prompting or decoding.
minor comments (2)
- [§2] Notation for agent states and routing decisions should be formalized with explicit symbols early in the manuscript to aid readability.
- [Figures] Figure captions should include the exact number of agents, rounds, and LLM backbones used in each panel for immediate interpretability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our theoretical claims and strengthen the empirical evaluation. We address each major comment below and will incorporate revisions in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Theoretical Characterization): the claim that PEAR 'preserves accuracy under agent relabeling' as an equivariant sparse router is load-bearing for the central contribution, yet the description of routing decisions based on 'evolving agent states' leaves open whether those states are invariant to permutation (e.g., via per-agent history or embeddings keyed to original labels). Without an explicit definition of the router function f and a proof that f(π(G), π(s)) = π(f(G, s)) for permutation π, the reduction in positional bias rests on an unverified assumption rather than a demonstrated property.
Authors: We acknowledge that §3 would benefit from greater formality. The current text characterizes PEAR as an equivariant router but does not supply an explicit definition of the router function f nor a complete proof of the stated permutation-equivariance property. In the revised manuscript we will add a precise mathematical definition of f together with the proof that f(π(G), π(s)) = π(f(G, s)) for any permutation π, thereby making the invariance claim fully rigorous. revision: yes
-
Referee: [§4] §4 (Empirical Evaluation): the statement that PEAR 'significantly improves average accuracy over the strongest debate baselines' is central to the empirical claim, but the manuscript provides no details on baseline implementations, hyperparameter matching, statistical significance tests, or variance across runs; without these, it is impossible to determine whether the reported gains are attributable to the adaptive routing or to uncontrolled differences in prompting or decoding.
Authors: We agree that the current §4 lacks the necessary experimental details for full reproducibility and attribution. In the revision we will expand the section to document (i) exact baseline implementations and prompting templates, (ii) hyperparameter values and matching procedure, (iii) the statistical tests employed (including p-values), and (iv) mean accuracy together with standard deviation across multiple independent runs with different random seeds. revision: yes
Circularity Check
No circularity in claimed theoretical characterization
full rationale
The paper describes PEAR as a protocol that dynamically reconfigures roles and topologies, then states it is 'theoretically characterize[d] ... as an equivariant sparse router' that 'preserves accuracy under agent relabeling.' No equations, proofs, or derivation steps appear in the provided text. The equivariance claim is asserted rather than derived from prior self-citations or fitted parameters. Empirical evaluations on benchmarks are presented as independent validation. No load-bearing step reduces by construction to its own inputs; the central description remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Reconcile: Round-table conference improves reasoning via consensus among diverse llms , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[2]
Proceedings of the 41st International Conference on Machine Learning , series =
Improving Factuality and Reasoning in Language Models through Multiagent Debate , author =. Proceedings of the 41st International Conference on Machine Learning , series =. 2024 , publisher =
2024
-
[3]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =. 2024 , publisher =
2024
-
[4]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Improving multi-agent debate with sparse communication topology , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[5]
Deep think with confidence , author=. arXiv preprint arXiv:2508.15260 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Confidence improves self-consistency in llms , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[7]
arXiv preprint arXiv:2409.14051 , year=
Groupdebate: Enhancing the efficiency of multi-agent debate using group discussion , author=. arXiv preprint arXiv:2409.14051 , year=
-
[8]
arXiv preprint arXiv:2509.14034 , year=
Enhancing multi-agent debate system performance via confidence expression , author=. arXiv preprint arXiv:2509.14034 , year=
-
[9]
Demystifying Multi-Agent Debate: The Role of Confidence and Diversity
Demystifying Multi-Agent Debate: The Role of Confidence and Diversity , author=. arXiv preprint arXiv:2601.19921 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Key Decision-Makers in Multi-Agent Debates: Who Holds the Power? , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[11]
arXiv preprint arXiv:2603.20215 , year=
Multi-Agent Debate with Memory Masking , author=. arXiv preprint arXiv:2603.20215 , year=
-
[12]
Hear Both Sides: Efficient Multi-Agent Debate via Diversity-Aware Message Retention
Hear Both Sides: Efficient Multi-Agent Debate via Diversity-Aware Message Retention , author=. arXiv preprint arXiv:2603.20640 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Assemble Your Crew: Automatic Multi-agent Communication Topology Design via Autoregressive Graph Generation , author=. arXiv preprint arXiv:2507.18224 , year=
-
[14]
arXiv preprint arXiv:2410.11782 , year=
G-designer: Architecting multi-agent communication topologies via graph neural networks , author=. arXiv preprint arXiv:2410.11782 , year=
-
[15]
Learning multi-agent communication from graph modeling perspective
Learning multi-agent communication from graph modeling perspective , author=. arXiv preprint arXiv:2405.08550 , year=
-
[16]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
T2mac: Targeted and trusted multi-agent communication through selective engagement and evidence-driven integration , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[17]
Semantic Information Extraction and Multi-Agent Communication Optimization Based on Generative Pre-Trained Transformer , year=
Zhou, Li and Deng, Xinfeng and Wang, Zhe and Zhang, Xiaoying and Dong, Yanjie and Hu, Xiping and Ning, Zhaolong and Wei, Jibo , journal=. Semantic Information Extraction and Multi-Agent Communication Optimization Based on Generative Pre-Trained Transformer , year=
-
[18]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Efficient communication via self-supervised information aggregation for online and offline multiagent reinforcement learning , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2024 , publisher=
2024
-
[19]
Beyond Self-Talk: A Communication-Centric Survey of LLM-Based Multi-Agent Systems
Beyond self-talk: A communication-centric survey of llm-based multi-agent systems , author=. arXiv preprint arXiv:2502.14321 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
arXiv preprint arXiv:2506.02951 , year=
Adaptive graph pruning for multi-agent communication , author=. arXiv preprint arXiv:2506.02951 , year=
-
[21]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[24]
2026 , howpublished =
OpenAI , title =. 2026 , howpublished =
2026
-
[25]
2025 , howpublished =
Anthropic , title =. 2025 , howpublished =
2025
-
[26]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[27]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-consistency improves chain of thought reasoning in language models , author=. arXiv preprint arXiv:2203.11171 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Truthfulqa: Measuring how models mimic human falsehoods , author=. Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.