Towards Automating Scientific Review with Google's Paper Assistant Tool
Pith reviewed 2026-06-29 04:12 UTC · model grok-4.3
The pith
PAT uses inference scaling in an agentic framework to detect 34% more mathematical errors than zero-shot model calls on the SPOT benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PAT is an agentic AI framework that ingests full scientific manuscripts and produces comprehensive evaluations by applying inference scaling techniques, which allow it to identify deeper issues than single model calls; this yields a 34% improvement over zero-shot recall on mathematical errors in the SPOT benchmark, and conference pilots at STOC and ICML demonstrate its ability to surface critical errors and suggest substantive improvements while leaving final control with human referees.
What carries the argument
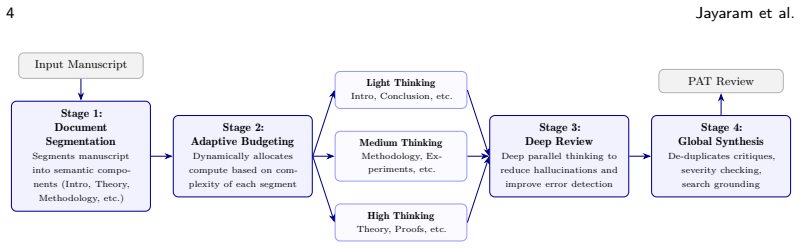
The agentic AI framework PAT that ingests full manuscripts and applies inference scaling techniques to perform multi-step checks on theory, experiments, and potential flaws.
Load-bearing premise
The SPOT benchmark and the STOC and ICML pilots supply representative, unbiased measures of PAT's real-world performance on scientific review tasks.
What would settle it
A larger controlled trial in which PAT reviews papers containing deliberately planted, undisclosed errors and misses a substantial fraction that human reviewers later identify.
Figures
read the original abstract
Artificial intelligence is driving a revolution in scientific discovery, accelerating everything from hypothesis generation to mathematical theorem proving. However, this rapid acceleration is creating a systemic challenge: traditional human peer review cannot scale to match the influx of AI-assisted science. Ultimately, to resolve this tension, we must also deploy AI to accelerate the verification and review process itself. To frame the discussion around this transition, we propose a taxonomy consisting of four progressive levels of AI-human collaboration in scientific evaluation, and discuss various trade-offs involved with each. As a step toward this future, we introduce the Paper Assistant Tool (PAT), an agentic AI framework built for deep scientific review and verification. PAT ingests full scientific manuscripts and produces a comprehensive evaluation, checking theoretical results, validating experiments, suggesting improvements, and identifying potential flaws. By utilizing inference scaling techniques, PAT is able to identify deeper issues than a single model call alone, achieving a 34% improvement over zero-shot recall on mathematical errors in the SPOT benchmark. Pilot deployments of PAT as a pre-submission tool for authors at two major Computer Science conferences -- STOC and ICML -- demonstrate its ability to identify critical errors and suggest substantive improvements to research papers. By catching errors early, PAT eases the cognitive burden placed on referees, while preserving their control over the outcomes of the review process.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a four-level taxonomy for progressive AI-human collaboration in scientific evaluation and introduces the Paper Assistant Tool (PAT), an agentic AI framework that ingests full manuscripts to check theoretical results, validate experiments, suggest improvements, and identify flaws. It claims that inference scaling enables PAT to identify deeper issues than single model calls, yielding a 34% improvement over zero-shot recall on mathematical errors in the SPOT benchmark, and reports positive outcomes from pilot deployments as a pre-submission tool at the STOC and ICML conferences.
Significance. If the empirical claims hold with proper evidence, the work could meaningfully advance scalable AI assistance for peer review, easing referee burden while preserving human oversight. The taxonomy offers a structured way to discuss automation trade-offs, and the conference pilots provide initial real-world grounding. The absence of methods, data, and analysis in the presented material, however, prevents assessing whether these benefits are realized.
major comments (2)
- [Abstract] Abstract: The central claim of a 34% improvement over zero-shot recall on mathematical errors in the SPOT benchmark is stated without any description of the SPOT benchmark construction, the inference scaling techniques employed, experimental protocol, number of instances, error analysis, or statistical significance. This directly undermines evaluation of the paper's primary technical result.
- [Pilots (conference deployments)] Pilots description: The STOC and ICML conference pilots are presented as demonstrating PAT's ability to identify critical errors and suggest improvements, but no details are given on the number of papers, selection criteria, specific error types found, quantitative metrics, or comparison against human-only review. This leaves the real-world effectiveness claim unsupported.
minor comments (1)
- [Abstract] The four-level taxonomy is introduced but receives no elaboration in the abstract or visible structure; a brief definition of each level would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive report. The comments correctly identify that key methodological and empirical details supporting our central claims are not present in the current manuscript. We address each point below and commit to a major revision that incorporates the requested information.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of a 34% improvement over zero-shot recall on mathematical errors in the SPOT benchmark is stated without any description of the SPOT benchmark construction, the inference scaling techniques employed, experimental protocol, number of instances, error analysis, or statistical significance. This directly undermines evaluation of the paper's primary technical result.
Authors: We agree that the manuscript does not provide the necessary details on the SPOT benchmark or the evaluation protocol. In the revised version we will add a new section (and update the abstract) that fully describes benchmark construction, the inference scaling methods applied, the experimental protocol, number of instances evaluated, error analysis, and statistical significance testing. This will allow proper assessment of the reported 34% improvement. revision: yes
-
Referee: [Pilots (conference deployments)] Pilots description: The STOC and ICML conference pilots are presented as demonstrating PAT's ability to identify critical errors and suggest improvements, but no details are given on the number of papers, selection criteria, specific error types found, quantitative metrics, or comparison against human-only review. This leaves the real-world effectiveness claim unsupported.
Authors: We acknowledge that the pilot descriptions are currently high-level and lack supporting data. In the revision we will expand the relevant section to report the number of papers processed, selection criteria, concrete examples of errors and suggested improvements, any quantitative metrics collected during the pilots, and a discussion of how the tool's outputs relate to human-only review. This will strengthen the evidence for real-world utility. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces an agentic AI framework (PAT) for manuscript review and reports empirical results such as a 34% recall improvement on the SPOT benchmark via inference scaling, plus pilot deployments at STOC and ICML. No equations, derivations, fitted parameters presented as predictions, or load-bearing self-citations appear in the text. All claims rest on described system behavior and external benchmark/pilot outcomes rather than reducing to self-definitional inputs or renamed prior results by the same authors.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alina Beygelzimer, Yann Dauphin, Percy Liang, and Jennifer Wortman Vaughan. 2021. The NeurIPS 2021 Consistency Experiment. NeurIPS Blog. https://blog.neurips.cc/2021/12/08/the-neurips-2021- consistency-experiment/
2021
-
[2]
Joydeep Biswas, Sheila Schoepp, Gautham Vasan, Anthony Opipari, Arthur Zhang, Zichao Hu, Sebas- tian Joseph, Matthew Lease, Junyi Jessy Li, Peter Stone, Kiri L Wagstaff, Matthew E Taylor, and 10 Jayaram et al. Odest Chadwicke Jenkins. 2026. AI-Assisted Peer Review at Scale: The AAAI-26 AI Review Pilot. arXiv preprint arXiv:2604.13940(2026)
Pith/arXiv arXiv 2026
-
[3]
David P. Blecher. 2024. A missing theorem on dual spaces.arXiv preprint arXiv:2405.01133(2024)
arXiv 2024
-
[4]
Vincent Cohen-Addad and David Woodruff. 2025. Gemini provides automated feedback for theoretical computer scientists at STOC 2026. Google Research Blog. https://research.google/blog/gemini- provides-automated-feedback-for-theoretical-computer-scientists-at-stoc-2026/ Accessed: May 2026
2025
-
[5]
Corinna Cortes and Neil D Lawrence. 2021. Inconsistency in conference peer review: Revisiting the 2014 neurips experiment.arXiv preprint arXiv:2109.09774(2021)
arXiv 2021
-
[6]
Deep Think Team. 2025. Try deep think in the gemini app. https://blog.google/products/gemini/gemini- 2-5-deep-think/
2025
-
[7]
Tony Feng, Trieu H Trinh, Garrett Bingham, Dawsen Hwang, Yuri Chervonyi, Junehyuk Jung, Joonkyung Lee, Carlo Pagano, Sang-hyun Kim, Federico Pasqualotto, et al. 2026. Towards autonomous mathematics research.arXiv preprint arXiv:2602.10177(2026)
arXiv 2026
-
[8]
Google Cloud. 2026. Gemini 3.1 Pro on Vertex AI. https://cloud.google.com/vertex-ai
2026
-
[9]
@icmlconf. 2026. Post on X. X (formerly Twitter). https://x.com/icmlconf/status/ 2016954655599735289?lang=en Accessed May 21, 2026
2026
-
[10]
Rajesh Jayaram, Vincent Cohen-Addad, Alekh Agarwal, Miroslav Dudik, Sharon Li, and Martin Jaggi. 2026. ICML Experimental Program using Google’s Paper Assistant Tool (PAT). ICML Blog. https://blog.icml.cc/2026/01/14/icml-experimental-program-using-googles-paper-assistant-tool-pat/
2026
-
[11]
Dmitry Kobak, Rita González-Márquez, Emőke-Ágnes Horvát, and Jan Lause. 2025. Delving into LLM-assisted writing in biomedical publications through excess vocabulary.Science Advances11, 27 (Jul 2025), eadt3813. doi:10.1126/sciadv.adt3813
-
[12]
Pangram Labs. 2025. Pangram Predicts 21% of ICLR Reviews are AI-Generated. Pangram Labs Blog. https://www.pangram.com/blog/pangram-predicts-21-of-iclr-reviews-are-ai-generated Accessed: May 2026
2025
-
[13]
Weixin Liang, Yaohui Zhang, Zhengxuan Wu, Haley Lepp, Wenlong Ji, Xuandong Zhao, Hancheng Cao, Sheng Liu, Siyu He, Zhi Huang, Diyi Yang, Christopher Potts, Christopher D. Manning, and James Y. Zou. 2024. Mapping the Increasing Use of LLMs in Scientific Papers.arXiv preprint arXiv:2404.01268 (2024). https://arxiv.org/abs/2404.01268
arXiv 2024
-
[14]
2025.Reflections on the 2025 Review Process from the Program Committee Chairs
NeurIPS Program Committee Chairs. 2025.Reflections on the 2025 Review Process from the Program Committee Chairs. NeurIPS Blog. https://blog.neurips.cc/2025/09/30/reflections-on-the-2025-review- process-from-the-program-committee-chairs/
2025
-
[15]
Guijin Son, Jiwoo Hong, Honglu Fan, Heejeong Nam, Hyunwoo Ko, Seungwon Lim, Jinyeop Song, Jinha Choi, Gonçalo Paulo, Youngjae Yu, et al. 2025. When ai co-scientists fail: Spot-a benchmark for automated verification of scientific research.arXiv preprint arXiv:2505.11855(2025)
arXiv 2025
-
[16]
Jing Yang, Qiyao Wei, and Jiaxin Pei. 2025. Paper Copilot: Tracking the Evolution of Peer Review in AI Conferences. Website and conference statistics available at https://papercopilot.com.arXiv preprint arXiv:2510.13201(2025). https://arxiv.org/abs/2510.13201 URL Accessed May 21, 2026
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.