Lost in the Flow with Code Talkers: Unveiling the Instruction-Tuning Tax of Large Language Models in Code Tasks
Pith reviewed 2026-06-27 17:59 UTC · model grok-4.3
The pith
Instruction tuning improves LLMs' command following in code but weakens infilling of unfinished programs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
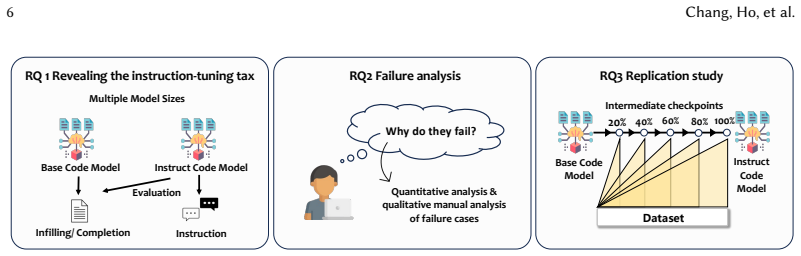
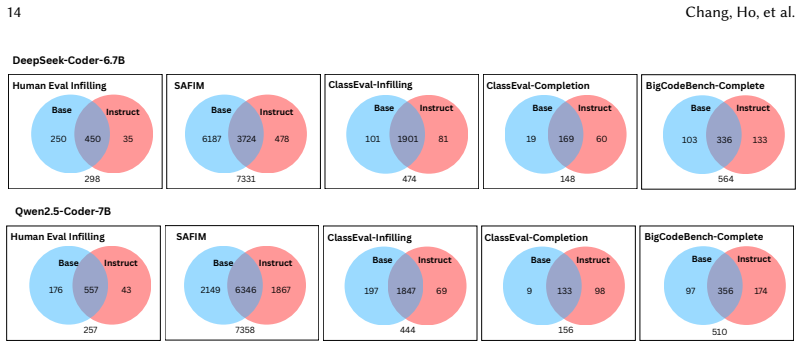
Instruction tuning is not a free lunch: although instruction-tuned models are more capable of following instructions and leveraging structured guidance, these gains often come at the cost of weaker infilling performance. The study is the first to document this trade-off across programming modes through quantitative metrics, behavioral analysis, and intermediate model evaluations.
What carries the argument
The Instruction-Tuning Tax, the measured drop in infilling accuracy after instruction tuning of CodeLLMs.
If this is right
- Instruction-tuned models perform better on tasks that require understanding and executing natural-language instructions.
- The same models show reduced accuracy when completing or infilling gaps in partial code.
- The performance drop emerges progressively during the instruction-tuning process.
- Behavioral metrics reveal lower fidelity in generated code for infilling tasks after tuning.
- Manual review identifies distinct error patterns that differ between the two modes.
Where Pith is reading between the lines
- AI coding tool builders could maintain separate untuned models for Flow-mode assistance alongside tuned ones for Command-mode use.
- New tuning objectives might be designed to retain infilling strength while adding instruction capability.
- The Flow-Command distinction could be tested in other AI assistance domains such as writing or design tools.
- Productivity measurements with actual developers would show whether benchmark differences affect real output.
Load-bearing premise
The chosen benchmarks and metrics for infilling versus instruction tasks accurately reflect the real-world distinction between Flow and Command cognitive modes.
What would settle it
If instruction-tuned models show no decline or an increase in infilling scores on the same code completion benchmarks used in the study, the existence of the tax would be disproved.
Figures

read the original abstract
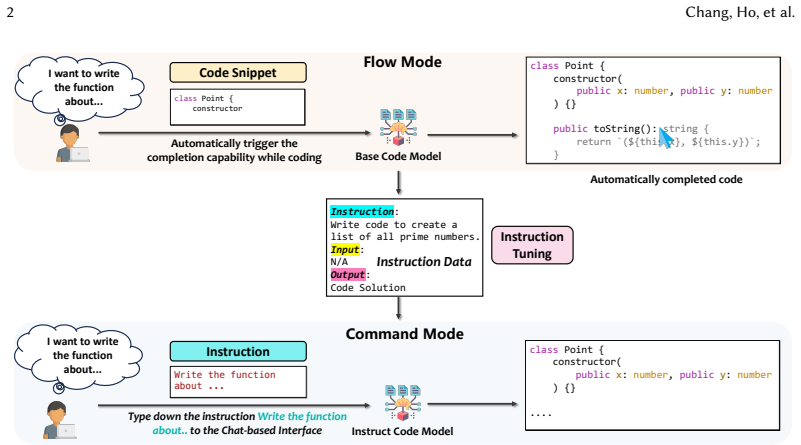
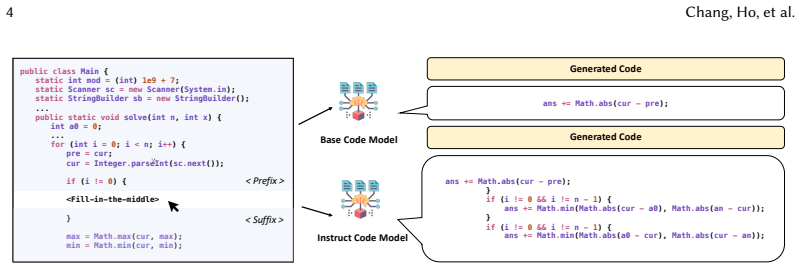
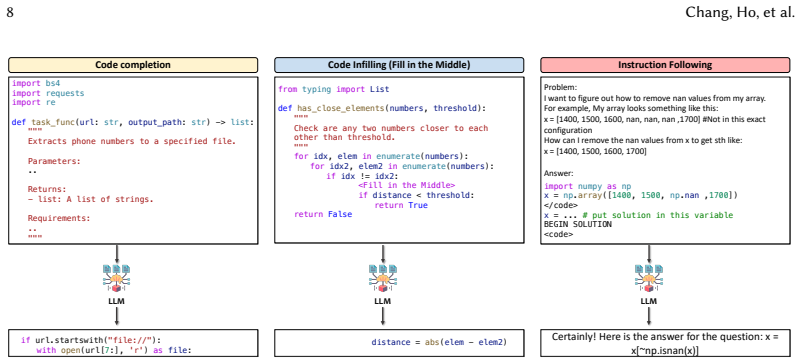
AI coding assistants have significantly improved developer productivity by automatically suggesting code that aligns with user intent, and many of these tools are now integrated directly into Integrated Development Environments (IDEs). Developers interact with code in two distinct cognitive modes: Flow and Command. While developers require tools that directly complete or infill code in unfinished programs during Flow mode, they also need tools that can comprehend intentions expressed as natural-language instructions and convert them into executable code in Command mode. Although instruction-tuned Large Language Models (LLMs) dominate many application scenarios due to their abilities to infer and fulfill developers' intents, it remains unclear whether the same paradigm is equally suitable for different code-related tasks. Therefore, it is necessary to understand how instruction tuning affects the feasibility of CodeLLMs as coding assistants. To fill this gap, we conduct the first empirical study that uncovers a key trade-off caused by instruction tuning across programming modes, which we term the Instruction-Tuning Tax. Our results show that instruction tuning is not a free lunch: although instruction-tuned models are more capable of following instructions and leveraging structured guidance, these gains often come at the cost of weaker infilling performance. We further extend our study through both qualitative and quantitative analyses, including manual failure categorization, behavioral metrics that capture generation fidelity, and intermediate-checkpoint evaluation throughout the tuning process. Summarizing our results into seven findings and four implications, our study offers a new perspective on the development of AI-powered coding tools and highlights the need to carefully balance instruction-following ability with effective code generation assistance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study on the effects of instruction tuning on CodeLLMs for code-related tasks. It claims that instruction tuning improves performance on instruction-following and structured-guidance tasks but degrades infilling performance, a trade-off termed the 'Instruction-Tuning Tax'. The study supports this via quantitative metrics, qualitative failure categorization, behavioral metrics on generation fidelity, and intermediate-checkpoint analysis during tuning, culminating in seven findings and four implications for AI coding assistants.
Significance. If the reported trade-off is robust to benchmark choice and the task proxies validly distinguish developer cognitive modes, the work would provide a useful empirical perspective on training CodeLLMs, encouraging more balanced optimization rather than instruction-following alone.
major comments (2)
- [Abstract and study design] Abstract and study design: the interpretation of benchmark results as an 'Instruction-Tuning Tax' on real developer cognition in Flow vs. Command modes requires that instruction-following tasks proxy Command mode and infilling tasks proxy Flow mode. No developer study, usage-log correlation, or other validation of this mapping is supplied, rendering the cognitive-mode framing load-bearing yet unsupported.
- [Experimental details (throughout)] Experimental details (throughout): the central trade-off claim cannot be verified without access to dataset definitions, statistical tests, baseline selection criteria, and failure-mode operationalizations. Post-hoc choices in these areas could materially affect whether the observed performance gap constitutes a genuine tax rather than an artifact of the evaluation protocol.
minor comments (1)
- [Title] The title uses evocative phrasing ('Lost in the Flow with Code Talkers') that may obscure the technical focus; a clearer subtitle would aid discoverability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and presentation of our empirical findings on the Instruction-Tuning Tax. We address each major comment below and commit to revisions that strengthen transparency and moderate interpretive claims while preserving the core empirical contributions.
read point-by-point responses
-
Referee: [Abstract and study design] Abstract and study design: the interpretation of benchmark results as an 'Instruction-Tuning Tax' on real developer cognition in Flow vs. Command modes requires that instruction-following tasks proxy Command mode and infilling tasks proxy Flow mode. No developer study, usage-log correlation, or other validation of this mapping is supplied, rendering the cognitive-mode framing load-bearing yet unsupported.
Authors: We acknowledge that the Flow/Command framing is conceptual and that the manuscript does not include a developer study or usage-log validation to confirm the task-to-cognition mapping. The distinction draws from prior IDE and developer-behavior literature, but we agree it is not empirically validated here. In revision we will (1) reframe the tasks explicitly as proxies for different interaction styles rather than direct measures of cognitive modes, (2) add a limitations subsection that states the absence of such validation, and (3) remove or qualify phrases that imply direct correspondence to 'real developer cognition.' These changes will be reflected in the abstract, introduction, and discussion. revision: yes
-
Referee: [Experimental details (throughout)] Experimental details (throughout): the central trade-off claim cannot be verified without access to dataset definitions, statistical tests, baseline selection criteria, and failure-mode operationalizations. Post-hoc choices in these areas could materially affect whether the observed performance gap constitutes a genuine tax rather than an artifact of the evaluation protocol.
Authors: We agree that full reproducibility requires explicit documentation of these elements. The original manuscript summarizes the benchmarks and metrics but does not provide exhaustive definitions or code. In the revised version we will expand the Experimental Setup and Evaluation sections to include: precise dataset construction details and splits, the exact statistical tests and significance thresholds used, the rationale and selection criteria for all baselines, and the operational definitions and annotation guidelines for the qualitative failure categories. We will also make the evaluation code, processed datasets, and analysis scripts publicly available upon acceptance. revision: yes
Circularity Check
Empirical measurement study with no derivation chain or self-referential reduction
full rationale
The paper is an empirical study that measures performance trade-offs on instruction-following and infilling benchmarks after instruction tuning, then names the observed difference the 'Instruction-Tuning Tax.' No equations, fitted parameters, or derivations are present that reduce any claim to its own inputs by construction. The central observation is a direct comparison of model outputs on fixed benchmarks; the cognitive-mode interpretation is an interpretive framing rather than a load-bearing mathematical step. No self-citation chains or ansatzes are invoked to force the result. The work is therefore self-contained as a measurement within its chosen evaluation protocols.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Selected code benchmarks and human failure categories faithfully represent real developer Flow and Command cognitive modes.
Reference graph
Works this paper leans on
-
[1]
[n. d.]. Aider - AI Pair Programming in Your Terminal — aider.chat. https://aider.chat/. [Accessed 06-09-2025]
2025
-
[2]
[n. d.]. Cursor - The AI Code Editor — cursor.com. https://cursor.com/. [Accessed 06-09-2025]
2025
-
[3]
[n. d.]. OpenCode | The open source AI coding agent — opencode.ai. https://opencode.ai/. [Accessed 14-05-2026]
2026
-
[4]
2023. The Programmer’s Assistant: Conversational Interaction with a Large Language Model for Software Development. InProceedings of the 28th International Conference on Intelligent User Interfaces(Sydney, NSW, Australia)(IUI ’23). Association for Computing Machinery, New York, NY, USA, 491–514. doi:10.1145/3581641.3584037
-
[5]
Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie J
Jacob Austin, Augustus Odena, Maxwell I. Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie J. Cai, Michael Terry, Quoc V. Le, and Charles Sutton. 2021. Program Synthesis with Large Language Models. CoRRabs/2108.07732 (2021). arXiv:2108.07732 https://arxiv.org/abs/2108.07732
Pith/arXiv arXiv 2021
-
[6]
and Polikarpova, Nadia , title =
Shraddha Barke, Michael B. James, and Nadia Polikarpova. 2023. Grounded Copilot: How Programmers Interact with Code-Generating Models.Proc. ACM Program. Lang.7, OOPSLA1, Article 78 (April 2023), 27 pages. doi:10.1145/3586030
-
[7]
Mohammad Bavarian, Heewoo Jun, Nikolas Tezak, John Schulman, Christine McLeavey, Jerry Tworek, and Mark Chen. 2022. Efficient Training of Language Models to Fill in the Middle. arXiv:2207.14255 [cs.CL] https://arxiv.org/ abs/2207.14255
Pith/arXiv arXiv 2022
-
[8]
BigCode. 2025. Big Code Models Leaderboard. https://huggingface.co/spaces/bigcode/bigcode-models-leaderboard https://huggingface.co/spaces/bigcode/bigcode-models-leaderboard
2025
-
[10]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
Pith/arXiv arXiv 2020
-
[13]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
Pith/arXiv arXiv 2021
-
[14]
Guanting Dong, Hongyi Yuan, Keming Lu, Chengpeng Li, Mingfeng Xue, Dayiheng Liu, Wei Wang, Zheng Yuan, Chang Zhou, and Jingren Zhou. 2024. How Abilities in Large Language Models are Affected by Supervised Fine-tuning Data Composition. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei...
-
[15]
Xueying Du, Mingwei Liu, Kaixin Wang, Hanlin Wang, Junwei Liu, Yixuan Chen, Jiayi Feng, Chaofeng Sha, Xin Peng, and Yiling Lou. 2023. ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs on Class-level Code Generation. arXiv:2308.01861 [cs.CL] https://arxiv.org/abs/2308.01861
arXiv 2023
-
[16]
Daniel Fried, Armen Aghajanyan, Jessy Lin, Sida Wang, Eric Wallace, Freda Shi, Ruiqi Zhong, Scott Yih, Luke Zettlemoyer, and Mike Lewis. 2023. InCoder: A Generative Model for Code Infilling and Synthesis. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net. https://openreview.net/pd...
2023
-
[17]
GitHub. 2025. GitHub Copilot: Your AI pair programmer. https://github.com/features/copilot
2025
-
[18]
Linyuan Gong, Sida Wang, Mostafa Elhoushi, and Alvin Cheung. 2024. Evaluation of LLMs on Syntax-Aware Code Fill-in-the-Middle Tasks. InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235), Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett...
2024
-
[19]
Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. 2022. Unixcoder: Unified cross-modal pre-training for code representation.arXiv preprint arXiv:2203.03850(2022)
Pith/arXiv arXiv 2022
-
[20]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y. Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming - The Rise of Code Intelligence.CoRRabs/2401.14196 (2024). arXiv:2401.14196 doi:10.48550/ARXIV.2401.14196
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.14196 2024
-
[21]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, Kai Dang, Yang Fan, Yichang Zhang, An Yang, Rui Men, Fei Huang, Bo Zheng, Yibo Miao, Shanghaoran Quan, Yunlong Feng, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. 2024. Qwen2.5-Coder Technical Report. arXiv:2409.12186 [cs.CL...
Pith/arXiv arXiv 2024
-
[22]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. SWE-bench: Can Language Models Resolve Real-World GitHub Issues?CoRRabs/2310.06770 (2023). arXiv:2310.06770 doi:10.48550/ARXIV.2310.06770
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06770 2023
-
[23]
Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettlemoyer, Wen-Tau Yih, Daniel Fried, Sida Wang, and Tao Yu. 2022. DS-1000: A Natural and Reliable Benchmark for Data Science Code Generation.ArXiv abs/2211.11501 (2022)
arXiv 2022
-
[24]
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. 2023. StarCoder: may the source be with you!CoRRabs/2305.06161 (2023). arXiv:2305.06161 doi:10.48550/ARXIV.2305.06161
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.06161 2023
-
[25]
Yikun Li, Ngoc Tan Bui, Ting Zhang, Martin Weyssow, Chengran Yang, Xin Zhou, Jinfeng Jiang, Junkai Chen, Huihui Huang, Huu Hung Nguyen, Chiok Yew Ho, Jie Tan, Ruiyin Li, Yide Yin, Han Wei Ang, Frank Liauw, Eng Lieh Ouh, Lwin Khin Shar, and David Lo. 2025. Out of Distribution, Out of Luck: How Well Can LLMs Trained on Vulnerability Datasets Detect Top 25 C...
arXiv 2025
-
[26]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2023. Is your code generated by ChatGPT really correct? rigorous evaluation of large language models for code generation. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran Associates Inc., Red Hook, NY, USA, Art...
2023
-
[27]
Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, et al. 2024. StarCoder 2 and The Stack v2: The Next Generation.CoRR abs/2402.19173 (2024). arXiv:2402.19173 doi:10.48550/ARXIV.2402.19173
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.19173 2024
-
[28]
Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambrosio Blanco, Colin Clement, Dawn Drain, Daxin Jiang, Duyu Tang, et al. 2021. Codexglue: A machine learning benchmark dataset for code understanding and generation.arXiv preprint arXiv:2102.04664(2021)
Pith/arXiv arXiv 2021
-
[29]
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. 2025. An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning. arXiv:2308.08747 [cs.CL] https://arxiv.org/abs/ 2308.08747
Pith/arXiv arXiv 2025
-
[30]
Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. 2023. WizardCoder: Empowering Code Large Language Models with Evol-Instruct.CoRRabs/2306.08568 (2023). arXiv:2306.08568 doi:10.48550/ARXIV.2306.08568
-
[31]
Mary L McHugh. 2012. Interrater reliability: the kappa statistic.Biochemia medica22, 3 (2012), 276–282
2012
-
[32]
Niklas Muennighoff, Qian Liu, Armel Randy Zebaze, Qinkai Zheng, Binyuan Hui, Terry Yue Zhuo, Swayam Singh, Xiangru Tang, Leandro von Werra, and Shayne Longpre. 2024. OctoPack: Instruction Tuning Code Large Language Models. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. https:...
2024
-
[33]
Vijayaraghavan Murali, Chandra Maddila, Imad Ahmad, Michael Bolin, Daniel Cheng, Negar Ghorbani, Renuka Fernandez, Nachiappan Nagappan, and Peter C. Rigby. 2024. AI-Assisted Code Authoring at Scale: Fine-Tuning, Lost in the Flow with Code Talkers 25 Deploying, and Mixed Methods Evaluation.Proc. ACM Softw. Eng.1, FSE, Article 48 (July 2024), 20 pages. doi:...
2024
-
[34]
OpenAI. 2022. ChatGPT. https://openai.com/blog/chatgpt https://openai.com/blog/chatgpt
2022
-
[35]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems35 (2022), 27730–27744
2022
-
[36]
Wainwright, Pamela Mishkin, Chong Zhang, et al
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, et al. 2022. Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, No- vember 28 - ...
2022
-
[37]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford Alpaca: An Instruction-following LLaMA model. https://github.com/tatsu-lab/stanford_ alpaca
2023
-
[38]
O’Reilly Media, Inc
Tom Taulli. 2024.AI-assisted programming: Better planning, coding, testing, and deployment. " O’Reilly Media, Inc. "
2024
-
[39]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Harts...
Pith/arXiv arXiv 2023
-
[40]
Chaozheng Wang, Zezhou Yang, Shuzheng Gao, Cuiyun Gao, Ting Peng, Hailiang Huang, Yuetang Deng, and Michael Lyu. 2025. RAG or Fine-tuning? A Comparative Study on LCMs-based Code Completion in Industry. InProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering. 93–104
2025
-
[41]
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. 2025. Openhands: An open platform for ai software developers as generalist agents. InInternational Conference on Learning Representations, Vol. 2025. 65882–65919
2025
-
[42]
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi
-
[43]
Self-instruct: Aligning language models with self-generated instructions.arXiv preprint arXiv:2212.10560(2022)
Pith/arXiv arXiv 2022
-
[44]
Yue Wang, Hung Le, Akhilesh Gotmare, Nghi D. Q. Bui, Junnan Li, and Steven C. H. Hoi. 2023. CodeT5+: Open Code Large Language Models for Code Understanding and Generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023. Association for Computational Linguistics, 1069–108...
-
[45]
Joty, and Steven C
Yue Wang, Weishi Wang, Shafiq R. Joty, and Steven C. H. Hoi. 2021. CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November,
2021
-
[46]
Association for Computational Linguistics, 8696–8708. doi:10.18653/V1/2021.EMNLP-MAIN.685
-
[47]
Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. 2023. Magicoder: Source Code Is All You Need. CoRRabs/2312.02120 (2023). arXiv:2312.02120 doi:10.48550/ARXIV.2312.02120
-
[48]
Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, et al. 2024. BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions.arXiv preprint arXiv:2406.15877(2024)
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.