GuideWalk: Learning Unified Autonomous Navigation and Locomotion for Humanoid Robots across Versatile Terrains
Pith reviewed 2026-06-27 12:53 UTC · model grok-4.3
The pith
GuideWalk unifies navigation and locomotion for humanoids by distilling separate teachers into one end-to-end policy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
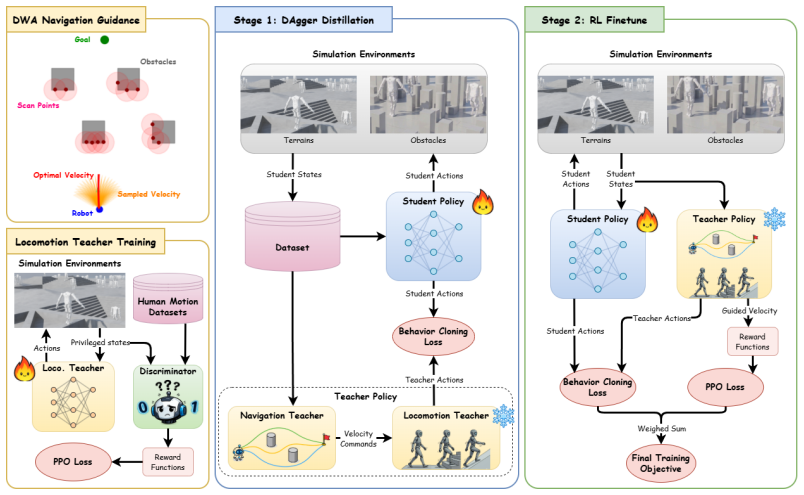
GuideWalk integrates traversability-aware navigation guidance with a terrain-adaptive locomotion teacher through a composite teacher distillation scheme that aggregates goal-directed commands and dynamically consistent actions into one policy; the distilled policy is then refined with reinforcement learning and an auxiliary behavior-cloning objective to produce stable navigation while preserving feasible humanoid locomotion across diverse environments.
What carries the argument
Composite teacher distillation scheme that merges velocity guidance from the navigation teacher with dynamically consistent actions from the locomotion teacher into a single policy.
If this is right
- Obstacle avoidance can be planned independently of terrain adaptation inside the same controller.
- The policy remains effective on a wide range of ground conditions after the refinement stage.
- Exploration during reinforcement learning is guided so that teacher behaviors are retained rather than forgotten.
- End-to-end training removes the coordination overhead between separate navigation and locomotion modules.
Where Pith is reading between the lines
- The same distillation pattern might be applied to other legged platforms that currently use modular controllers.
- Real-robot deployment could reveal whether simulation-trained robustness transfers when sensor noise and actuator limits are present.
- The approach suggests that many multi-objective robot skills can be combined by first training specialist teachers then distilling them rather than designing a single objective from scratch.
- If the method scales, it could reduce the engineering effort required to add new terrain types or navigation tasks.
Load-bearing premise
The two teachers produce compatible signals that can be aggregated without one undermining the other when distilled into the final policy.
What would settle it
A controlled test environment in which the distilled policy either loses balance on terrain transitions or fails to reach navigation goals at a higher rate than the separate teachers used together.
Figures


read the original abstract
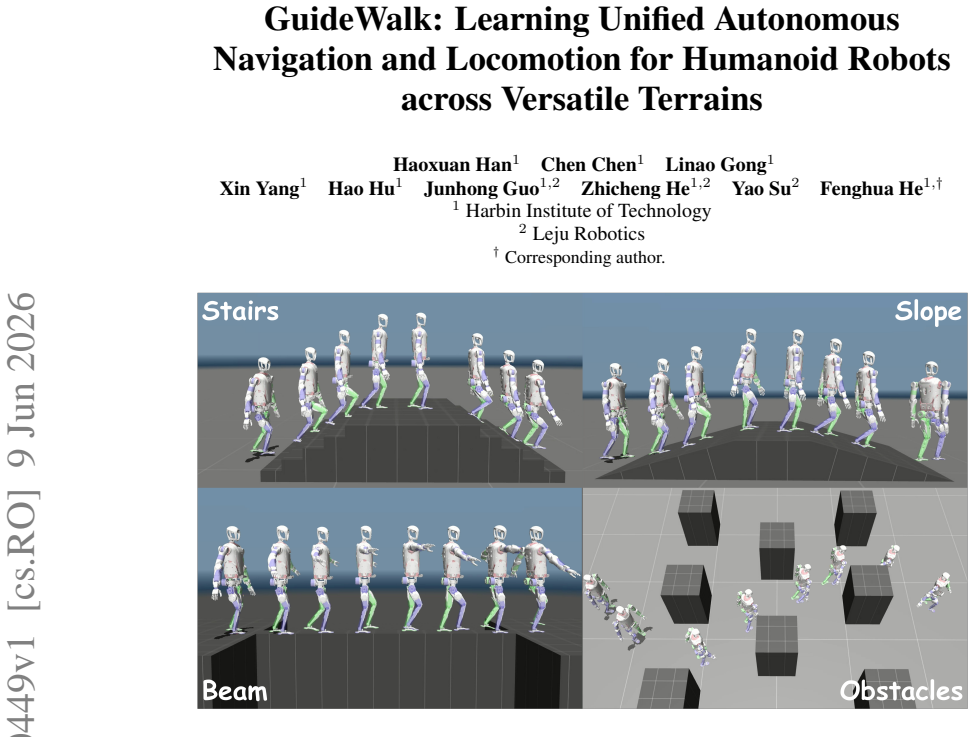
Humanoid robots have achieved strong locomotion capabilities, but reliable navigation on versatile terrains remains challenging because obstacle avoidance must be coordinated with dynamically feasible motion. In this work, we present GuideWalk, a unified end-to-end framework that integrates traversability-aware navigation guidance with terrain-adaptive locomotion teacher for humanoid navigation. Specifically, we introduce a navigation module that provides explicit velocity guidance, decoupling obstacle avoidance from terrain conditions to enable robust planning across diverse environments. We propose a composite teacher distillation scheme, where goal-directed commands and dynamically consistent actions are aggregated and distilled into a single policy. To further improve robustness, the distilled policy is refined with reinforcement learning and an auxiliary behavior cloning objective, which promotes exploration while preserving desirable teacher behaviors. Experiments demonstrate that GuideWalk achieves stable and effective navigation while maintaining stable humanoid locomotion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GuideWalk, a unified end-to-end framework for humanoid robot navigation and locomotion across versatile terrains. It combines a traversability-aware navigation module that supplies explicit velocity guidance with a terrain-adaptive locomotion teacher through a composite teacher distillation scheme; the resulting policy is further refined via reinforcement learning augmented by an auxiliary behavior cloning objective. The central claim is that this produces stable navigation while preserving stable locomotion, as shown by experiments.
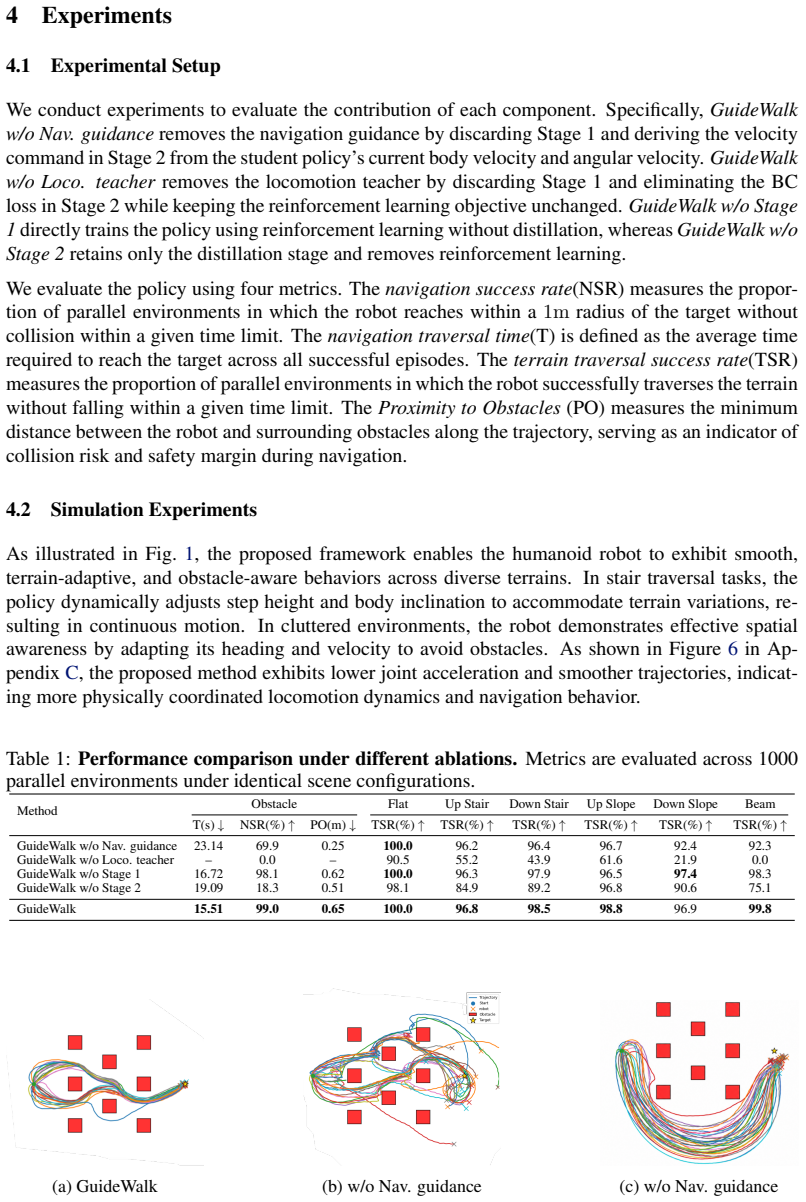
Significance. If the empirical results support the claims, the work would contribute a practical method for coordinating obstacle avoidance with dynamically feasible motion in a single policy, which could simplify deployment of humanoids on diverse terrains. The distillation-plus-RL pipeline is a standard technique, but its application to unify navigation commands with locomotion actions is potentially useful; however, the absence of any quantitative metrics prevents gauging the actual advance.
major comments (1)
- [Abstract] Abstract: The abstract states that experiments demonstrate stable navigation and locomotion, but provides no quantitative results, baselines, ablation studies, or error metrics; without these, it is impossible to assess whether the central claim is supported by data.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the constructive comment on the abstract. We address the point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states that experiments demonstrate stable navigation and locomotion, but provides no quantitative results, baselines, ablation studies, or error metrics; without these, it is impossible to assess whether the central claim is supported by data.
Authors: We agree that the abstract would be strengthened by including quantitative highlights. The full manuscript contains experimental results with metrics (success rates, traversal efficiency, stability measures) and baseline comparisons in the evaluation section. In the revision we will update the abstract to concisely report the key quantitative outcomes that support the central claims. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper presents an empirical ML framework using a navigation module for velocity guidance, composite teacher distillation to aggregate commands and actions into a single policy, followed by RL refinement with an auxiliary behavior cloning objective. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or described method. Claims of stable navigation and locomotion rest on experimental demonstration across terrains rather than any self-referential mathematical reduction or ansatz imported via prior author work. The derivation chain is self-contained as a standard distillation-plus-RL pipeline without internal circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhang, B
T. Zhang, B. Zheng, R. Nai, Y . Hu, Y .-J. Wang, G. Chen, F. Lin, J. Li, C. Hong, K. Sreenath, and Y . Gao. Hub: Learning extreme humanoid balance. In J. Lim, S. Song, and H.-W. Park, editors,Proceedings of The 9th Conference on Robot Learning, volume 305 ofProceedings of Machine Learning Research, pages 686–704. PMLR, 27–30 Sep 2025. URLhttps:// proceedi...
2025
-
[2]
Z. Wu, X. Huang, L. Yang, Y . Zhang, K. Sreenath, X. Chen, P. Abbeel, R. Duan, A. Kanazawa, C. Sferrazza, et al. Perceptive humanoid parkour: Chaining dynamic human skills via motion matching.arXiv preprint arXiv:2602.15827, 2026
Pith/arXiv arXiv 2026
-
[3]
Y . Wang, S. Zhu, P. Zhi, Y . Li, J. Li, Y .-L. Li, Y . Xiao, X. Wang, B. Jia, and S. Huang. Om- nixtreme: Breaking the generality barrier in high-dynamic humanoid control.arXiv preprint arXiv:2602.23843, 2026
arXiv 2026
-
[4]
Agarwal, A
A. Agarwal, A. Kumar, J. Malik, and D. Pathak. Legged locomotion in challenging terrains using egocentric vision. In K. Liu, D. Kulic, and J. Ichnowski, editors,Proceedings of The 6th Conference on Robot Learning, volume 205 ofProceedings of Machine Learning Research, pages 403–415. PMLR, 14–18 Dec 2023. URLhttps://proceedings.mlr.press/v205/ agarwal23a.html
2023
-
[5]
Zhuang, S
Z. Zhuang, S. Yao, and H. Zhao. Humanoid parkour learning. In P. Agrawal, O. Kroemer, and W. Burgard, editors,Proceedings of The 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learning Research, pages 1975–1991. PMLR, 06–09 Nov 2025. URLhttps://proceedings.mlr.press/v270/zhuang25a.html
1975
-
[6]
S. Zhu, Z. Zhuang, M. Zhao, K.-Y . Lee, and H. Zhao. Hiking in the wild: A scalable perceptive parkour framework for humanoids, 2026. URLhttps://arxiv.org/abs/2601.07718
arXiv 2026
-
[7]
J. Long, J. Ren, M. Shi, Z. Wang, T. Huang, P. Luo, and J. Pang. Learning humanoid locomo- tion with perceptive internal model. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 9997–10003, 2025. doi:10.1109/ICRA55743.2025.11128333
-
[8]
H. Wang, Z. Wang, J. Ren, Q. Ben, T. Huang, W. Zhang, and J. Pang. BeamDojo: Learning Agile Humanoid Locomotion on Sparse Footholds. InProceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025. doi:10.15607/RSS.2025.XXI.068
-
[9]
J. He, C. Zhang, F. Jenelten, R. Grandia, M. B ¨acher, and M. Hutter. Attention-based map encoding for learning generalized legged locomotion.Science Robotics, 10(105):eadv3604,
-
[10]
URLhttps://www.science.org/doi/abs/10
doi:10.1126/scirobotics.adv3604. URLhttps://www.science.org/doi/abs/10. 1126/scirobotics.adv3604
-
[11]
Zhang, V
C. Zhang, V . Klemm, F. Yang, and M. Hutter. Ame-2: Agile and generalized legged locomo- tion via attention-based neural map encoding, 2026. URLhttps://arxiv.org/abs/2601. 08485
2026
-
[12]
T. Miki, L. Wellhausen, R. Grandia, F. Jenelten, T. Homberger, and M. Hutter. Elevation map- ping for locomotion and navigation using gpu. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2273–2280. IEEE, 2022
2022
-
[13]
I. Radosavovic, T. Xiao, B. Zhang, T. Darrell, J. Malik, and K. Sreenath. Real-world hu- manoid locomotion with reinforcement learning.Science Robotics, 9(89):eadi9579, 2024. doi:10.1126/scirobotics.adi9579. URLhttps://www.science.org/doi/abs/10.1126/ scirobotics.adi9579
-
[14]
Zhang, G
Q. Zhang, G. Han, J. Sun, W. Zhao, C. Sun, J. Cao, J. Wang, Y . Guo, and R. Xu. Distillation- ppo: A novel two-stage reinforcement learning framework for humanoid robot perceptive lo- comotion. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2916–2922. IEEE, 2025. 9
2025
-
[15]
O. A. Donca, C. Beokhaimook, and A. Hereid. Real-time navigation for bipedal robots in dynamic environments.arXiv preprint arXiv:2210.03280, 2022
arXiv 2022
-
[16]
T. He, C. Zhang, W. Xiao, G. He, C. Liu, and G. Shi. Agile but safe: Learning collision-free high-speed legged locomotion. InRobotics: Science and Systems (RSS), 2024
2024
-
[17]
J. Lee, M. Bjelonic, A. Reske, L. Wellhausen, T. Miki, and M. Hutter. Learning robust au- tonomous navigation and locomotion for wheeled-legged robots.Science Robotics, 9(89): eadi9641, 2024
2024
-
[18]
M. Seo, R. Gupta, Y . Zhu, A. Skoutnev, L. Sentis, and Y . Zhu. Learning to walk by steer- ing: Perceptive quadrupedal locomotion in dynamic environments. In2023 IEEE Inter- national Conference on Robotics and Automation (ICRA), pages 5099–5105, 2023. doi: 10.1109/ICRA48891.2023.10161302
-
[19]
J. Ren, T. Huang, H. Wang, Z. Wang, Q. Ben, J. Long, Y . Yang, J. Pang, and P. Luo. Vb-com: Learning vision-blind composite humanoid locomotion against deficient perception.arXiv preprint arXiv:2502.14814, 2025
arXiv 2025
-
[20]
Huang, H
F. Huang, H. Mou, and Q. Li. Tnavrl: Cross-modal transformer for humanoid visual naviga- tion.IEEE Robotics and Automation Letters, 2026
2026
-
[21]
Q. Ben, B. Xu, K. Li, F. Jia, W. Zhang, J. Wang, J. Wang, D. Lin, and J. Pang. Gallant: V oxel grid-based humanoid locomotion and local-navigation across 3d constrained terrains.arXiv preprint arXiv:2511.14625, 2025
arXiv 2025
- [22]
-
[23]
Ho and S
J. Ho and S. Ermon. Generative adversarial imitation learning.Advances in neural information processing systems, 29, 2016
2016
-
[24]
Hester, M
T. Hester, M. Vecerik, O. Pietquin, M. Lanctot, T. Schaul, B. Piot, D. Horgan, J. Quan, A. Sendonaris, I. Osband, et al. Deep q-learning from demonstrations. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[25]
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y . Tassa, D. Silver, and D. Wierstra. Continuous control with deep reinforcement learning. In Y . Bengio and Y . LeCun, editors,4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, 2016. URLhttp://arxiv.org/abs/1...
2016
-
[26]
W. Sun, J. A. Bagnell, and B. Boots. Truncated horizon policy search: Combining reinforce- ment learning & imitation learning. In6th International Conference on Learning Represen- tations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Pro- ceedings. OpenReview.net, 2018. URLhttps://openreview.net/forum?id=ryUlhzWCZ
2018
-
[27]
G. Liu, L. Zhao, P. Zhang, J. Bian, T. Qin, N. Yu, and T.-Y . Liu. Demonstration actor critic.Neurocomputing, 434:194–202, 2021. ISSN 0925-2312. doi:https://doi.org/10.1016/j. neucom.2020.12.116. URLhttps://www.sciencedirect.com/science/article/pii/ S0925231220320282
work page doi:10.1016/j 2021
-
[28]
D. Fox, W. Burgard, and S. Thrun. The dynamic window approach to collision avoidance. IEEE Robotics & Automation Magazine, 4(1):23–33, 1997. doi:10.1109/100.580977
-
[29]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured predic- tion to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Pro- ceedings, 2011. 10
2011
-
[30]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[31]
X. B. Peng, Z. Ma, P. Abbeel, S. Levine, and A. Kanazawa. Amp: Adversarial motion priors for stylized physics-based character control.ACM Trans. Graph., 40(4), July 2021. doi:10. 1145/3450626.3459670. URLhttp://doi.acm.org/10.1145/3450626.3459670
-
[32]
P. E. Hart, N. J. Nilsson, and B. Raphael. A formal basis for the heuristic determination of minimum cost paths.IEEE transactions on Systems Science and Cybernetics, 4(2):100–107, 1968
1968
-
[33]
S. Karaman, M. R. Walter, A. Perez, E. Frazzoli, and S. Teller. Anytime motion planning using the rrt*. In2011 IEEE International Conference on Robotics and Automation, pages 1478–1483, 2011. doi:10.1109/ICRA.2011.5980479
-
[34]
W. Sun, Y . Su, L. Huang, A. Zhang, D. Wei, M. San, D. Tian, E. Cao, F. Yan, E. Xie, and Z. Xie. Now you see that: Learning end-to-end humanoid locomotion from raw pixels, 2026. URLhttps://arxiv.org/abs/2602.06382. 11 A Details of Policy Training We train our policy in the Isaac Sim simulation platform, which enables large-scale parallelized rollouts and ...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.