Behavior Cloning is Not All You Need: The Optimality of On-Policy Distillation for Noisy Expert Feedback
Pith reviewed 2026-07-01 06:19 UTC · model grok-4.3
The pith
Offline imitation learning from noisy experts requires exponential sample complexity in the horizon to match a clean expert.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Offline learning from noisy trajectories is fundamentally hard: to compete with the clean expert, the sample complexity must grow exponentially, in contradistinction to the clean expert setting where no explicit horizon dependence exists. In contrast, online interaction with the noisy expert via a novel variant of OPD enables polynomial dependence on the horizon in general. Under a natural condition on the expert noise distribution, which is necessary for any horizon-free sample complexity, one can obtain such a guarantee, although the algorithm sacrifices statistical efficiency in its dependence on the size of the policy class.
What carries the argument
The noisy expert model (learner observes noisy policy but targets clean-expert reward) together with the novel online variant of on-policy distillation that queries the noisy expert directly.
If this is right
- Offline methods incur exponential horizon dependence when the expert is noisy.
- The proposed online OPD variant achieves only polynomial horizon dependence in general.
- Under the natural noise condition, horizon-free sample complexity is achievable, albeit with worse dependence on policy class size.
- The derived loss function supplies an alternative training objective for language models.
- The separation extends to the setting of unknown corruption when the clean expert is deterministic.
Where Pith is reading between the lines
- The noise condition may be testable on real teacher data used for chain-of-thought training.
- Other online interaction schemes could inherit similar polynomial guarantees.
- The framework suggests preferring online distillation over pure offline fine-tuning whenever expert noise is present and horizon length is large.
Load-bearing premise
A natural condition on the expert noise distribution is necessary for any horizon-free sample complexity.
What would settle it
An explicit noise distribution violating the stated natural condition for which some online algorithm still achieves horizon-free sample complexity, or an offline algorithm achieving only polynomial horizon dependence under the same noise model.
Figures
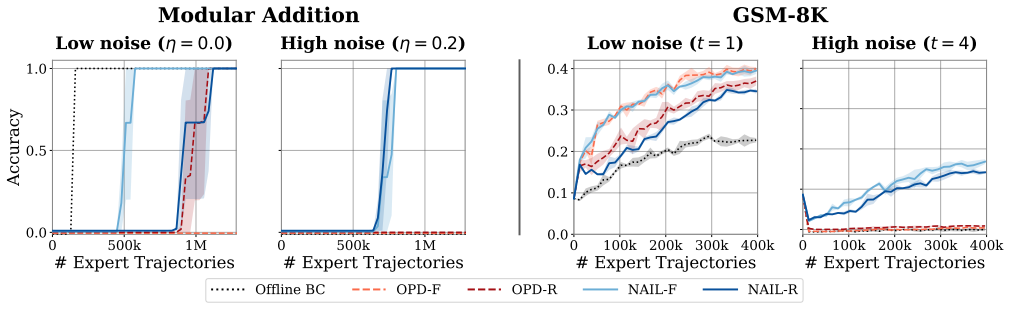
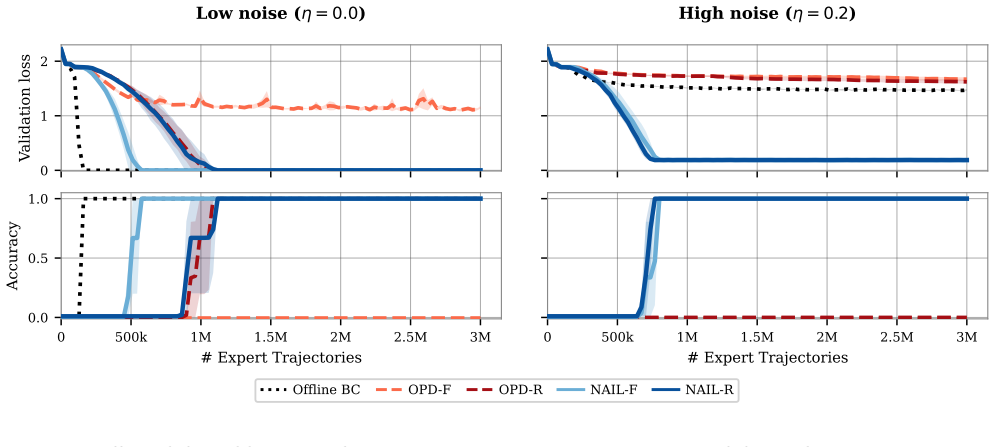
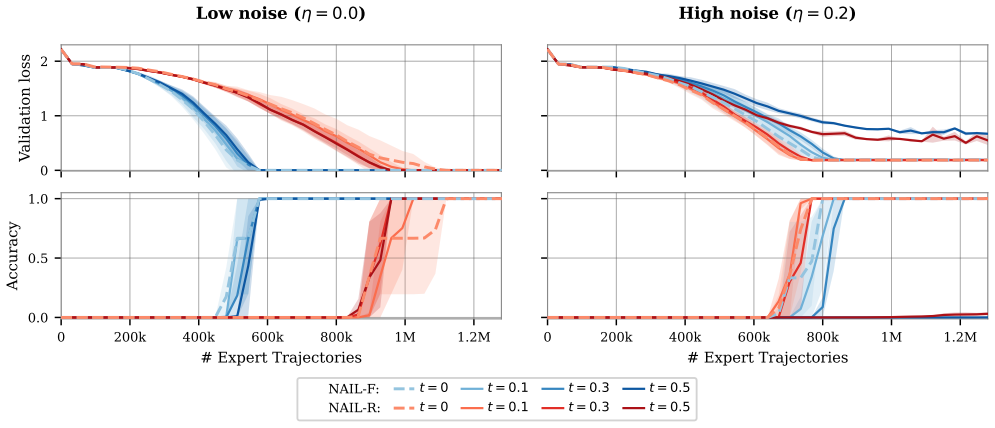
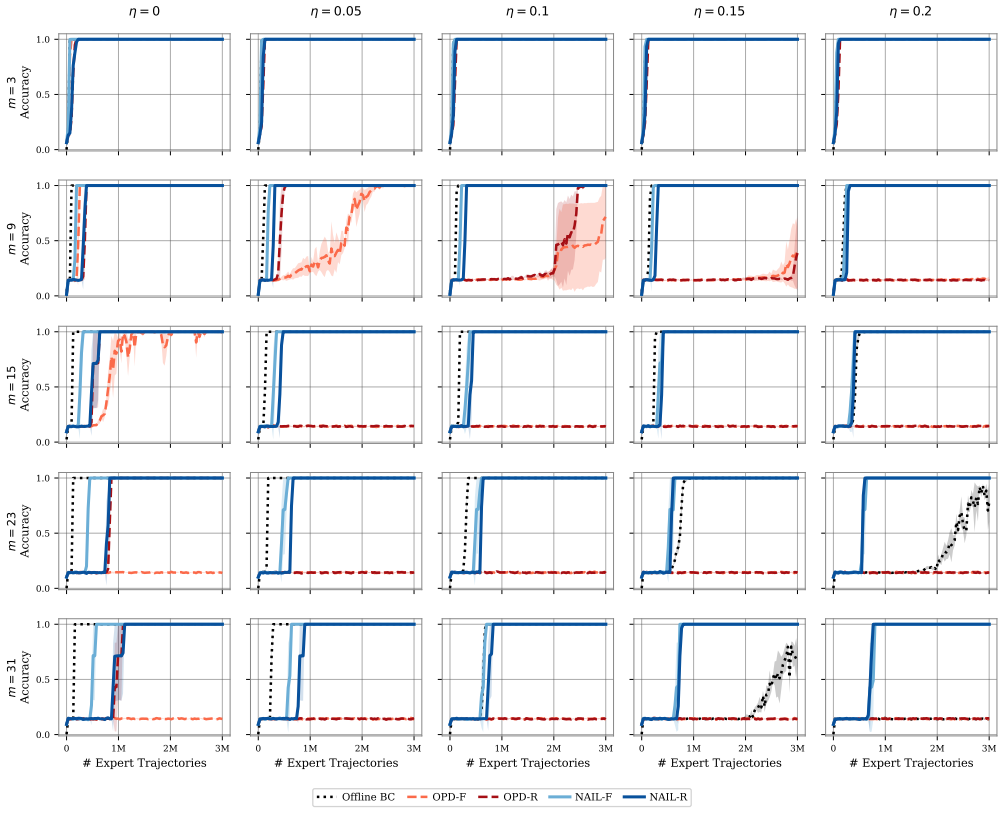
read the original abstract
Imitation Learning is a natural framework for learning in sequential decision-making systems and has emerged as the dominant paradigm through which we understand language model training. A central puzzle is that, while in theory offline IL can be horizon-free and optimal, in practice online methods such as on-policy distillation often outperform offline methods such as supervised fine-tuning. We propose a noisy expert model to explain this gap, in which the learner only has access to a noisy version of the expert's policy, but wishes to compete against the reward achieved by a clean expert, motivated by the fact that in many applications, e.g. training language models to perform long chains of thought, the expert is often imperfect. In this setting, we show a sharp separation between offline and online IL. Offline learning from noisy trajectories is fundamentally hard: to compete with the clean expert, the sample complexity must grow exponentially, in contradistinction to the clean expert setting where no explicit horizon dependence exists. In contrast, we prove that online interaction with the noisy expert via a novel variant of OPD enables polynomial dependence on the horizon in general. We further show that, under a natural condition on the expert noise distribution, which we show to be necessary for any horizon-free sample complexity, one can obtain such a guarantee, although our proposed algorithm sacrifices statistical efficiency in its dependence on the size of the policy class. Our analysis leads to an alternative loss function that is commonly considered empirically for LM training. We further provide algorithms and lower bounds, and extend our results to the more realistic setting of unknown corruption when the clean expert is deterministic, thereby providing a theoretical foundation for why OPD can outperform SFT when training language models from imperfect teachers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a noisy expert model for imitation learning, motivated by imperfect experts in applications like language model training on long reasoning chains. In this model, the learner accesses only noisy versions of the expert policy but seeks to match the reward of the clean expert. It establishes a sharp separation: offline imitation learning from noisy trajectories requires exponential sample complexity in the horizon to compete with the clean expert (contrasting with horizon-free results for clean experts), while a novel variant of on-policy distillation (OPD) achieves polynomial horizon dependence in general. Under a natural condition on the expert noise distribution—which the paper proves is necessary for any horizon-free sample complexity—the online method yields improved guarantees (though with worse dependence on policy class size). The analysis derives an alternative loss function relevant to LM training and extends the results to unknown corruption when the clean expert is deterministic, providing algorithms and lower bounds throughout.
Significance. If the derivations hold, this work supplies a theoretical explanation for why online methods such as on-policy distillation empirically outperform offline supervised fine-tuning when experts are noisy or imperfect. The offline-online separation, the necessity result for the noise condition, and the suggested alternative loss function constitute substantive contributions to imitation learning theory. The extension to unknown corruption strengthens applicability. The manuscript ships explicit algorithms, lower bounds, and a falsifiable modeling assumption, which are strengths.
minor comments (3)
- [Abstract / §1] The abstract and introduction would benefit from a brief explicit statement of the precise assumptions on the MDP (e.g., finite horizon, deterministic vs. stochastic transitions) that underpin both the exponential lower bound and the polynomial upper bound.
- [§3 / §4] Notation for the noisy expert distribution and the clean expert policy should be unified across the lower-bound construction and the online algorithm analysis to avoid any potential reader confusion.
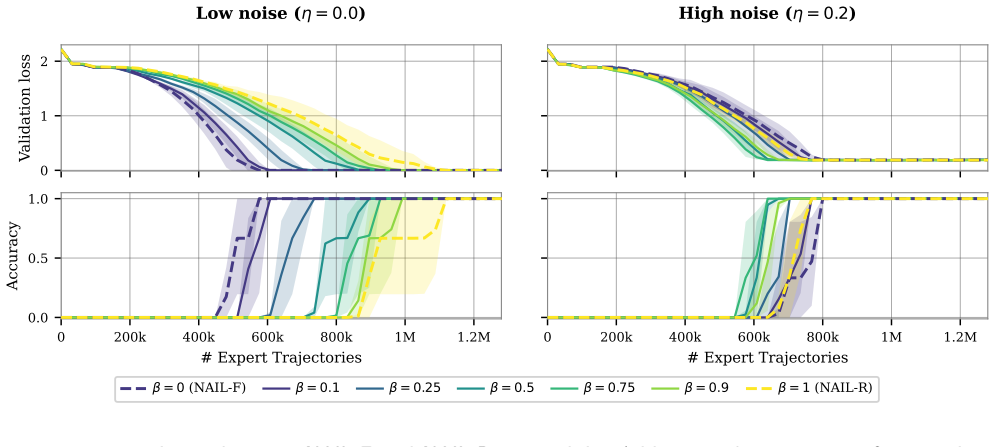
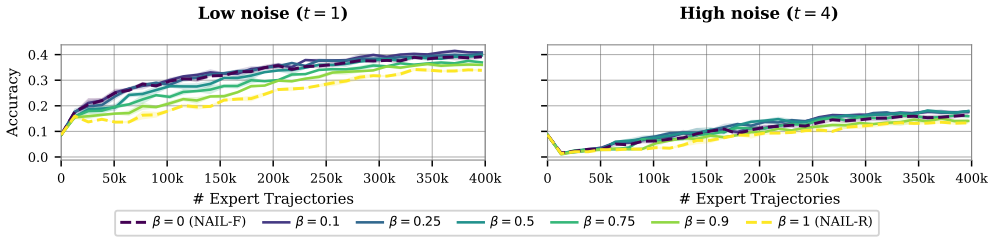
- [Figures] Figure captions for any sample-complexity plots should explicitly state whether the plotted curves correspond to the general polynomial bound or the horizon-free regime under the noise condition.
Simulated Author's Rebuttal
We thank the referee for their positive review, accurate summary of our contributions on the noisy expert model, the offline-online separation, and the necessity result for the noise condition, as well as the recommendation for minor revision. The referee's assessment aligns well with the manuscript's goals of providing theoretical foundations for why on-policy distillation can outperform offline methods under imperfect experts.
Circularity Check
No significant circularity identified
full rationale
The paper proposes a noisy expert model and derives theoretical sample complexity bounds, separations between offline and online imitation learning, and a necessity result for a noise condition directly from the model assumptions and standard analysis techniques. No steps reduce by construction to fitted parameters, self-definitions, or load-bearing self-citations; the derivations remain self-contained against the stated model without renaming known results or smuggling ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption natural condition on the expert noise distribution is necessary for any horizon-free sample complexity
invented entities (1)
-
noisy expert model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InThe twelfth international conference on learning representations, 2024
2024
-
[3]
Cot information: Improved sample complexity under chain-of-thought supervision
Awni Altabaa, Omar Montasser, and John Lafferty. Cot information: Improved sample complexity under chain-of-thought supervision. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[4]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
A careful examination of large behavior models for multitask dexterous manipulation.Science Robotics, 11(113):eaea6201, 2026
Jose Barreiros, Andrew Beaulieu, Aditya Bhat, Rick Cory, Eric Cousineau, Hongkai Dai, Ching-Hsin Fang, Kunimatsu Hashimoto, Muhammad Zubair Irshad, Masha Itkina, et al. A careful examination of large behavior models for multitask dexterous manipulation.Science Robotics, 11(113):eaea6201, 2026
2026
-
[6]
Provable guaran- tees for generative behavior cloning: Bridging low-level stability and high-level behavior.Advances in Neural Information Processing Systems, 36:48534–48547, 2023
Adam Block, Ali Jadbabaie, Daniel Pfrommer, Max Simchowitz, and Russ Tedrake. Provable guaran- tees for generative behavior cloning: Bridging low-level stability and high-level behavior.Advances in Neural Information Processing Systems, 36:48534–48547, 2023
2023
-
[7]
Butter- fly effects of sgd noise: Error amplification in behavior cloning and autoregression
Adam Block, Dylan J Foster, Akshay Krishnamurthy, Max Simchowitz, and Cyril Zhang. Butter- fly effects of sgd noise: Error amplification in behavior cloning and autoregression. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[8]
Cambridge university press, 2006
Nicolo Cesa-Bianchi and Gábor Lugosi.Prediction, learning, and games. Cambridge university press, 2006. 15
2006
-
[9]
Learning to generate better than your llm
Jonathan Chang, Kianté Brantley, Rajkumar Ramamurthy, Dipendra Misra, and Wen Sun. Learning to generate better than your llm. InNeurIPS 2023 Workshop on Instruction Tuning and Instruction Following, 2023
2023
-
[10]
Ash, Akshay Krishnamurthy, and Dylan J Foster
Fan Chen, Audrey Huang, Noah Golowich, Sadhika Malladi, Adam Block, Jordan T. Ash, Akshay Krishnamurthy, and Dylan J Foster. The coverage principle: How pre-training enables post-training. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[11]
Deep imitation learning for autonomous driving in genericurbanscenarioswithenhancedsafety
Jianyu Chen, Bodi Yuan, and Masayoshi Tomizuka. Deep imitation learning for autonomous driving in genericurbanscenarioswithenhancedsafety. In2019 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 2884–2890. IEEE, 2019
2019
-
[12]
Self-play fine-tuning converts weak language models to strong language models
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models. InInternational Conference on Machine Learning, pages 6621–6642. PMLR, 2024
2024
-
[13]
Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[14]
Training Verifiers to Solve Math Word Problems
KarlCobbe, VineetKosaraju, MohammadBavarian, MarkChen, HeewooJun, LukaszKaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
Efficient first-order contextual bandits: Prediction, allo- cation, and triangular discrimination.Advances in Neural Information Processing Systems, 34:18907– 18919, 2021
Dylan J Foster and Akshay Krishnamurthy. Efficient first-order contextual bandits: Prediction, allo- cation, and triangular discrimination.Advances in Neural Information Processing Systems, 34:18907– 18919, 2021
2021
-
[16]
The statistical complexity of interactive decision making.arXiv preprint arXiv:2112.13487, 2021
Dylan J Foster, Sham M Kakade, Jian Qian, and Alexander Rakhlin. The statistical complexity of interactive decision making.arXiv preprint arXiv:2112.13487, 2021
-
[17]
Is behavior cloning all you need? understanding horizon in imitation learning.Advances in Neural Information Processing Systems, 37:120602–120666, 2024
Dylan J Foster, Adam Block, and Dipendra Misra. Is behavior cloning all you need? understanding horizon in imitation learning.Advances in Neural Information Processing Systems, 37:120602–120666, 2024
2024
-
[18]
Online estimation via offline estima- tion: An information-theoretic framework.Advances in Neural Information Processing Systems, 37: 42840–42898, 2024
Dylan J Foster, Yanjun Han, Jian Qian, and Alexander Rakhlin. Online estimation via offline estima- tion: An information-theoretic framework.Advances in Neural Information Processing Systems, 37: 42840–42898, 2024
2024
-
[19]
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
Yuqian Fu, Haohuan Huang, Kaiwen Jiang, Jiacai Liu, Zhuo Jiang, Yuanheng Zhu, and Dongbin Zhao. Revisiting on-policy distillation: Empirical failure modes and simple fixes.arXiv preprint arXiv:2603.25562, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Cambridge university press, 2000
Sara A Geer.Empirical Processes in M-estimation, volume 6. Cambridge university press, 2000
2000
-
[21]
Knowledge distillation: A survey
Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. Knowledge distillation: A survey. International journal of computer vision, 129(6):1789–1819, 2021
2021
-
[22]
MiniLLM: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. MiniLLM: Knowledge distillation of large language models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[23]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. DeepSeek-R1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[25]
Generative adversarial imitation learning.Advances in neural information processing systems, 29, 2016
Jonathan Ho and Stefano Ermon. Generative adversarial imitation learning.Advances in neural information processing systems, 29, 2016
2016
-
[26]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Tinybert: Distilling bert for natural language understanding
Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. Tinybert: Distilling bert for natural language understanding. InFindings of the association for com- putational linguistics: EMNLP 2020, pages 4163–4174, 2020
2020
-
[28]
A theory of learning with autoregressive chain of thought
Nirmit Joshi, Gal Vardi, Adam Block, Surbhi Goel, Zhiyuan Li, Theodor Misiakiewicz, and Nathan Srebro. A theory of learning with autoregressive chain of thought. InThe Thirty Eighth Annual Conference on Learning Theory, pages 3161–3212. PMLR, 2025
2025
-
[29]
Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
NanoGPT.https://github.com/karpathy/nanoGPT, 2022
Andrej Karpathy. NanoGPT.https://github.com/karpathy/nanoGPT, 2022
2022
-
[31]
Sequence-level knowledge distillation
Yoon Kim and Alexander M Rush. Sequence-level knowledge distillation. InProceedings of the 2016 conference on empirical methods in natural language processing, pages 1317–1327, 2016
2016
-
[32]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In3rd International Conference on Learning Representations, ICLR 2015, 2015
2015
-
[33]
DISTILLM: towards streamlined distillation for large language models
Jongwoo Ko, Sungnyun Kim, Tianyi Chen, and Se-Young Yun. DISTILLM: towards streamlined distillation for large language models. InProceedings of the 41st International Conference on Machine Learning, pages 24872–24895, 2024
2024
-
[34]
Dart: Noise injection for robust imitation learning
Michael Laskey, Jonathan Lee, Roy Fox, Anca Dragan, and Ken Goldberg. Dart: Noise injection for robust imitation learning. InConference on robot learning, pages 143–156. PMLR, 2017
2017
-
[35]
Datacomp-lm: In search of the next generation of training sets for language models.Advances in Neural Information Processing Systems, 37:14200–14282, 2024
Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, Etash Guha, Sedrick Keh, Kushal Arora, et al. Datacomp-lm: In search of the next generation of training sets for language models.Advances in Neural Information Processing Systems, 37:14200–14282, 2024
2024
-
[36]
Yichen Li and Chicheng Zhang. Agnostic interactive imitation learning: New theory and practical algorithms.arXiv preprint arXiv:2312.16860, 2023
-
[37]
Yichen Li and Chicheng Zhang. Interactive and hybrid imitation learning: Provably beating behavior cloning.arXiv preprint arXiv:2412.07057, 2024
-
[38]
Chain of thought empowers transformers to solve inherentlyserialproblems
Zhiyuan Li, Hong Liu, Denny Zhou, and Tengyu Ma. Chain of thought empowers transformers to solve inherentlyserialproblems. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[39]
Learning quickly when irrelevant attributes abound: A new linear-threshold algo- rithm.Machine learning, 2(4):285–318, 1988
Nick Littlestone. Learning quickly when irrelevant attributes abound: A new linear-threshold algo- rithm.Machine learning, 2(4):285–318, 1988
1988
-
[40]
TinyGSM: achieving 80% on GSM8k with one billion parameters
Bingbin Liu, Sebastien Bubeck, Ronen Eldan, Janardhan Kulkarni, Yuanzhi Li, Anh Nguyen, Rachel Ward, and Yi Zhang. TinyGSM: achieving 80% on GSM8k with one billion parameters. InThe 3rd Workshop on Mathematical Reasoning and AI at NeurIPS’23, 2023. 17
2023
-
[41]
On-policy distillation.Thinking Machines Lab: Connectionism,
Kevin Lu and Thinking Machines Lab. On-policy distillation.Thinking Machines Lab: Connectionism,
-
[42]
https://thinkingmachines.ai/blog/on-policy-distillation
doi: 10.64434/tml.20251026. https://thinkingmachines.ai/blog/on-policy-distillation
-
[43]
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, et al. 2 OLMo 2 furious.arXiv preprint arXiv:2501.00656, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Cambridge university press, 2025
Yury Polyanskiy and Yihong Wu.Information theory: From coding to learning. Cambridge university press, 2025
2025
-
[45]
Alvinn: An autonomous land vehicle in a neural network.Advances in neural information processing systems, 1, 1988
Dean A Pomerleau. Alvinn: An autonomous land vehicle in a neural network.Advances in neural information processing systems, 1, 1988
1988
-
[46]
Computational-statistical tradeoffs at the next-token prediction barrier: Autoregressive and imita- tion learning under misspecification
Dhruv Rohatgi, Adam Block, Audrey Huang, Akshay Krishnamurthy, and Dylan J Foster. Computational-statistical tradeoffs at the next-token prediction barrier: Autoregressive and imita- tion learning under misspecification. InThe Thirty Eighth Annual Conference on Learning Theory, pages 4831–4837. PMLR, 2025
2025
-
[47]
John Wiley & Sons Hoboken, NJ, USA, 2009
Elvezio M Ronchetti and Peter J Huber.Robust statistics. John Wiley & Sons Hoboken, NJ, USA, 2009
2009
-
[48]
Efficient reductions for imitation learning
Stéphane Ross and Drew Bagnell. Efficient reductions for imitation learning. InProceedings of the thir- teenth international conference on artificial intelligence and statistics, pages 661–668. JMLR Workshop and Conference Proceedings, 2010
2010
-
[49]
Reinforcement and Imitation Learning via Interactive No-Regret Learning
Stephane Ross and J Andrew Bagnell. Reinforcement and imitation learning via interactive no-regret learning.arXiv preprint arXiv:1406.5979, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[50]
A reduction of imitation learning and structured prediction to no-regret online learning
Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages627–635.JMLRWorkshopandConferenceProceedings, 2011
2011
-
[51]
Andrei A Rusu, Sergio Gomez Colmenarejo, Caglar Gulcehre, Guillaume Desjardins, James Kirk- patrick, Razvan Pascanu, Volodymyr Mnih, Koray Kavukcuoglu, and Raia Hadsell. Policy distillation. arXiv preprint arXiv:1511.06295, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[52]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. DistilBERT, a distilled version of bert: smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[53]
Contextual bandits and imitation learning with preference-based active queries.Advances in Neural Information Processing Systems, 36: 11261–11295, 2023
Ayush Sekhari, Karthik Sridharan, Wen Sun, and Runzhe Wu. Contextual bandits and imitation learning with preference-based active queries.Advances in Neural Information Processing Systems, 36: 11261–11295, 2023
2023
-
[54]
Selective sampling and imitation learning via online regression.Advances in Neural Information Processing Systems, 36:67213–67268, 2023
Ayush Sekhari, Karthik Sridharan, Wen Sun, and Runzhe Wu. Selective sampling and imitation learning via online regression.Advances in Neural Information Processing Systems, 36:67213–67268, 2023
2023
-
[55]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
A Survey of On-Policy Distillation for Large Language Models
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models.arXiv preprint arXiv:2604.00626, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
MIT press Cambridge, 1998
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998. 18
1998
-
[58]
Causal imitation learning under temporally correlated noise
Gokul Swamy, Sanjiban Choudhury, Drew Bagnell, and Steven Wu. Causal imitation learning under temporally correlated noise. InInternational Conference on Machine Learning, pages 20877–20890. PMLR, 2022
2022
-
[59]
Beyond the 80/20 rule: High-entropy minority tokens drive ef- fective reinforcement learning for LLM reasoning
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xiong-Hui Chen, Jianxin Yang, Zhenru Zhang, Yuqiong Liu, An Yang, Andrew Zhao, Yang Yue, Shiji Song, Bowen Yu, Gao Huang, and Junyang Lin. Beyond the 80/20 rule: High-entropy minority tokens drive ef- fective reinforcement learning for LLM reasoning. InThe Thirty-ninth Annual Con...
2026
-
[60]
Minilm: Deep self- attention distillation for task-agnostic compression of pre-trained transformers.Advances in neural information processing systems, 33:5776–5788, 2020
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. Minilm: Deep self- attention distillation for task-agnostic compression of pre-trained transformers.Advances in neural information processing systems, 33:5776–5788, 2020
2020
-
[61]
Maurice Weber, Daniel Y. Fu, Quentin Anthony, Yonatan Oren, Shane Adams, Anton Alexandrov, Xiaozhong Lyu, Huu Nguyen, Xiaozhe Yao, Virginia Adams, Ben Athiwaratkun, Rahul Chalamala, Kezhen Chen, Max Ryabinin, Tri Dao, Percy Liang, Christopher Ré, Irina Rish, and Ce Zhang. RedPajama: an open dataset for training large language models.NeurIPS Datasets and B...
2024
-
[62]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. Self-distilled rlvr.arXiv preprint arXiv:2604.03128, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[64]
Embarrassingly Simple Self-Distillation Improves Code Generation
Ruixiang Zhang, Richard He Bai, Huangjie Zheng, Navdeep Jaitly, Ronan Collobert, and Yizhe Zhang. Embarrassingly simple self-distillation improves code generation.arXiv preprint arXiv:2604.01193, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[65]
Fromε-entropy to kl-entropy: Analysis of minimum information complexity density estimation.The Annals of Statistics, pages 2180–2210, 2006
Tong Zhang. Fromε-entropy to kl-entropy: Analysis of minimum information complexity density estimation.The Annals of Statistics, pages 2180–2210, 2006
2006
-
[66]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[67]
SCOPE: Signal-Calibrated On-Policy Distillation Enhancement with Dual-Path Adaptive Weighting
Binbin Zheng, Xing Ma, Yiheng Liang, Jingqing Ruan, Xiaoliang Fu, Kepeng Lin, Benchang Zhu, Ke Zeng, and Xunliang Cai. SCOPE: Signal-calibrated on-policy distillation enhancement with dual- path adaptive weighting.arXiv preprint arXiv:2604.10688, 2026. Contents 1 Introduction 1 2 Formal Problem Setup and Preliminaries 4 3 Offline Imitation Learning with a...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.