Muon as a Residual Connection
Pith reviewed 2026-07-02 15:37 UTC · model grok-4.3
The pith
Muon optimizer implicitly adds a residual connection by orthogonalizing its updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
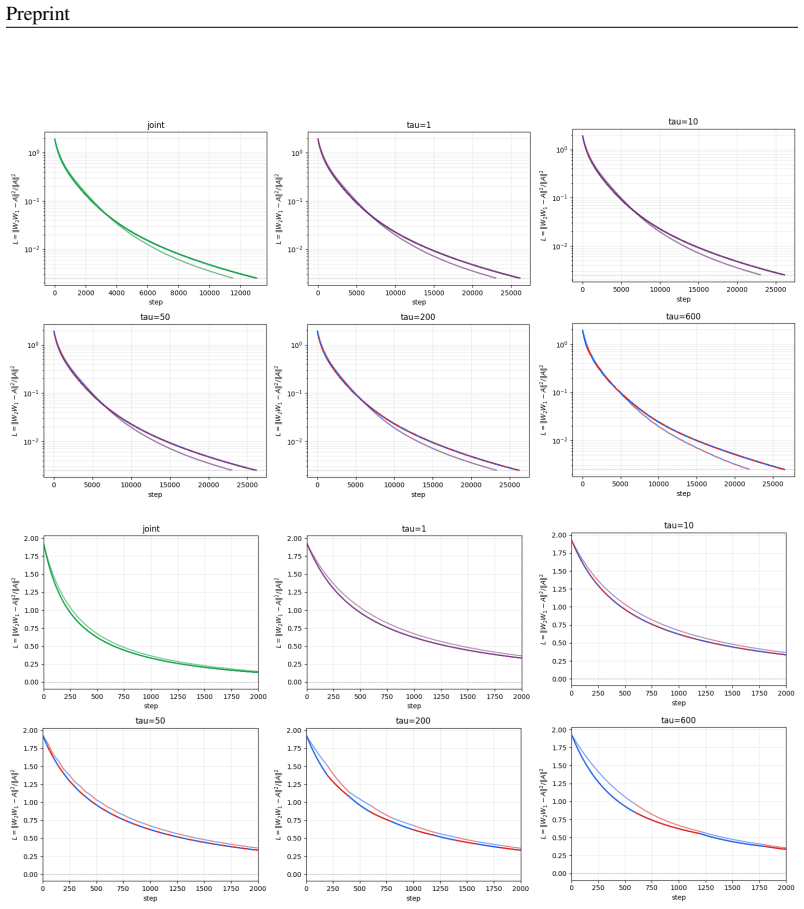
Muon can be understood as an implicit residual connection during training. Specifically, orthogonalizing the update can sacrifice some immediate gradient fidelity while improving representation preservation for downstream layers. In controlled linear optimization settings, Muon learns representations that are slower to fit a local target but easier for downstream layers to exploit.
What carries the argument
Orthogonalization of the update vector, which reduces alignment with the instantaneous gradient in exchange for better preservation of the input representation passed to subsequent layers.
If this is right
- Muon produces representations that downstream layers can exploit more readily than those from standard gradient steps.
- The method deliberately accepts slower local target fitting in return for improved compatibility across the full depth.
- Optimizer design can be guided by explicitly trading local descent speed against representation stability for later layers.
- The residual-like effect appears in linear settings and is proposed as the source of Muon's empirical behavior in deep networks.
Where Pith is reading between the lines
- The same orthogonalization idea could be inserted into other first-order methods to test whether they gain similar depth-wise benefits.
- If the mechanism holds, networks with very long chains of layers should show the largest relative gains from Muon-style updates.
- A direct test would replace Muon's update rule with plain gradient descent inside an otherwise identical architecture and check whether downstream-layer performance drops.
- This framing points toward optimizers that optimize an objective spanning multiple layers rather than a single-step loss.
Load-bearing premise
The trade-off measured in simple linear models is what produces Muon's observed gains when the same rule is used inside large nonlinear networks.
What would settle it
Training a deep network with a version of Muon that skips the orthogonalization step and measuring whether its final accuracy or convergence speed becomes indistinguishable from Adam or SGD would test the claim.
Figures
read the original abstract
Muon has recently emerged as one of the most effective optimizers for training large neural networks, yet its empirical success has been explained from several different perspectives. In this paper, we propose a simple mechanistic interpretation: Muon can be understood as an implicit residual connection during training. Specifically, orthogonalizing the update can sacrifice some immediate gradient fidelity while improving representation preservation for downstream layers. We study this trade-off in controlled linear optimization settings, where Muon can learn representations that are slower to fit a local target but easier for downstream layers to exploit. Our results suggest a conceptual explanation for Muon and a design perspective for optimizers that balance local descent with downstream usability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Muon can be interpreted as an implicit residual connection during training: orthogonalizing the update sacrifices some immediate gradient fidelity but improves representation preservation for downstream layers. This trade-off is examined in controlled linear optimization settings, where Muon learns representations that fit a local target more slowly but are easier for downstream layers to exploit, offering a conceptual explanation for Muon's empirical success in large neural networks and a design perspective for optimizers.
Significance. If the proposed mechanism generalizes, the work supplies a mechanistic account of an effective optimizer and a concrete design principle (balancing local descent against downstream usability) that could guide future optimizer development. The controlled linear studies constitute a clear, falsifiable starting point for the interpretation.
major comments (1)
- [Abstract] Abstract: the central claim that the observed linear trade-off explains Muon's success in large neural networks rests on an untested extrapolation; the manuscript reports no experiments, ablations, or analysis in non-convex, multi-layer, non-linear regimes, leaving the load-bearing step from linear optimization to deep-network dynamics unsupported.
Simulated Author's Rebuttal
We thank the referee for the constructive comment. We agree that the manuscript's scope is limited to linear settings and will revise the abstract to clarify that our results provide a conceptual hypothesis rather than a validated explanation for non-linear deep networks.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the observed linear trade-off explains Muon's success in large neural networks rests on an untested extrapolation; the manuscript reports no experiments, ablations, or analysis in non-convex, multi-layer, non-linear regimes, leaving the load-bearing step from linear optimization to deep-network dynamics unsupported.
Authors: We agree that the extrapolation from linear to deep non-linear networks is untested in the manuscript. The paper explicitly studies the trade-off only in controlled linear optimization settings and positions the work as offering a conceptual explanation and design perspective, not as a direct mechanistic account of large-network training. To address this, we will revise the abstract (and any similar phrasing in the introduction) to emphasize the linear scope and to frame the connection to Muon's empirical success as a hypothesis motivated by the linear results rather than a demonstrated explanation. revision: yes
Circularity Check
No significant circularity; interpretation derived from linear studies without reduction to inputs
full rationale
The paper advances a mechanistic interpretation of Muon as an implicit residual connection, supported by trade-off observations in controlled linear optimization settings. No equations, fitted parameters, or self-citations are shown that would make any claim equivalent to its inputs by construction. The central claim is presented as arising from the described empirical studies rather than a self-definitional loop, fitted prediction, or imported uniqueness theorem. The derivation chain remains self-contained as an interpretive proposal without load-bearing reductions to prior fits or definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Old Optimizer, New Norm: An Anthology
Jeremy Bernstein and Laker Newhouse. Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Identity mappings in deep residual networks
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. InEuropean Conference on Computer Vision, pp. 630–645, 2016a. Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recog- nition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778...
-
[3]
Dong-Hyun Lee, Saizheng Zhang, Asja Fischer, and Yoshua Bengio. Difference target propagation. arXiv preprint arXiv:1412.7525,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Interpreting the residual stream of ResNet18.arXiv preprint arXiv:2407.05340,
Andr´e Longon. Interpreting the residual stream of ResNet18.arXiv preprint arXiv:2407.05340,
-
[5]
Muon Dynamics as a Spectral Wasserstein Flow
Gabriel Peyr´e. Muon dynamics as a spectral wasserstein flow.arXiv preprint arXiv:2604.04891,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Lions and muons: Optimization via stochastic frank–wolfe
Maria-Eleni Sfyraki and Jun-Kun Wang. Lions and muons: Optimization via stochastic frank–wolfe. arXiv preprint arXiv:2506.04192,
-
[7]
Muon is Not That Special: Random or Inverted Spectra Work Just as Well
Zakhar Shumaylov, Nathael Da Costa, Peter Zaika, B´alint Mucs´anyi, Alex Massucco, Yoav Gelberg, Carola-Bibiane Sch¨onlieb, Yarin Gal, and Philipp Hennig. Muon is not that special: Random or inverted spectra work just as well.arXiv preprint arXiv:2605.11181,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Bhavya Vasudeva, Puneesh Deora, Yize Zhao, Vatsal Sharan, and Christos Thrampoulidis. How Muon’s spectral design benefits generalization: A study on imbalanced data.arXiv preprint arXiv:2510.22980,
- [9]
-
[10]
Why Muon Outperforms Adam: A Curvature Perspective
Shuche Wang, Fengzhuo Zhang, Jiaxiang Li, Dirk Bergemann, and Zhuoran Yang. Why Muon outperforms Adam: A curvature perspective.arXiv preprint arXiv:2606.04662,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
A.1 STEEPESTDESCENT UNDER THESPECTRALNORM Bernstein & Newhouse (2024) interpret Muon as steepest descent under the matrix spectral norm
A DETAILEDEXISTINGINTERPRETATIONS OFMUON For completeness, we provide a more detailed summary of the existing interpretations of Muon discussed in the main text. A.1 STEEPESTDESCENT UNDER THESPECTRALNORM Bernstein & Newhouse (2024) interpret Muon as steepest descent under the matrix spectral norm. LetG=∇f(W)and define Orth(G) =U V ⊤, G=UΣV ⊤. The steepest...
2024
-
[12]
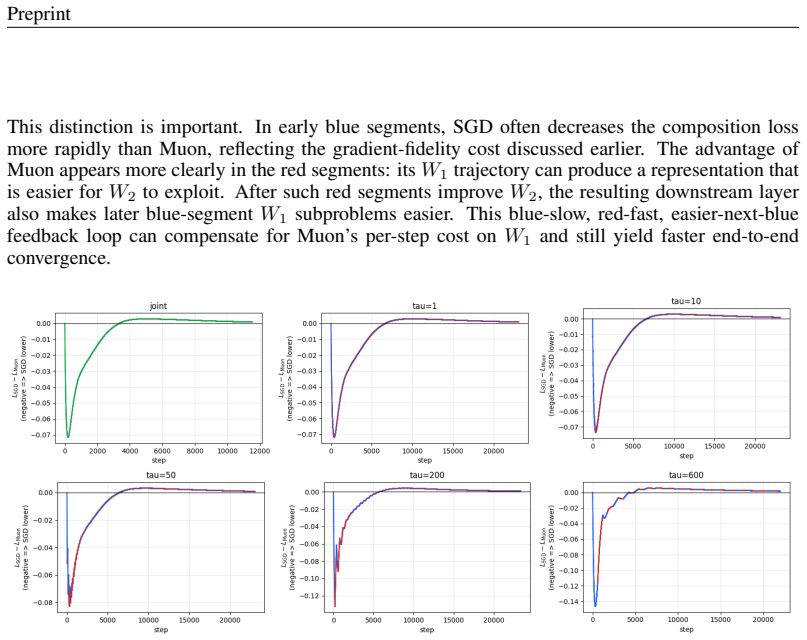
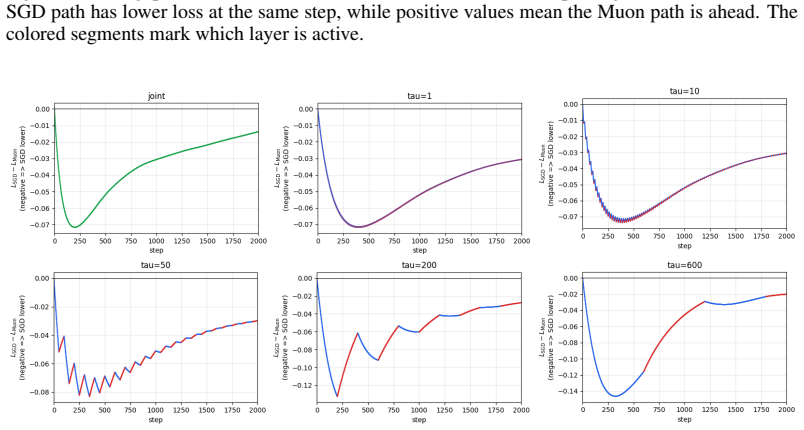
Figure 2 plots this effect directly as the loss gapL SGD −L Muon, with Figure 3 zooming in on the first 2000 steps
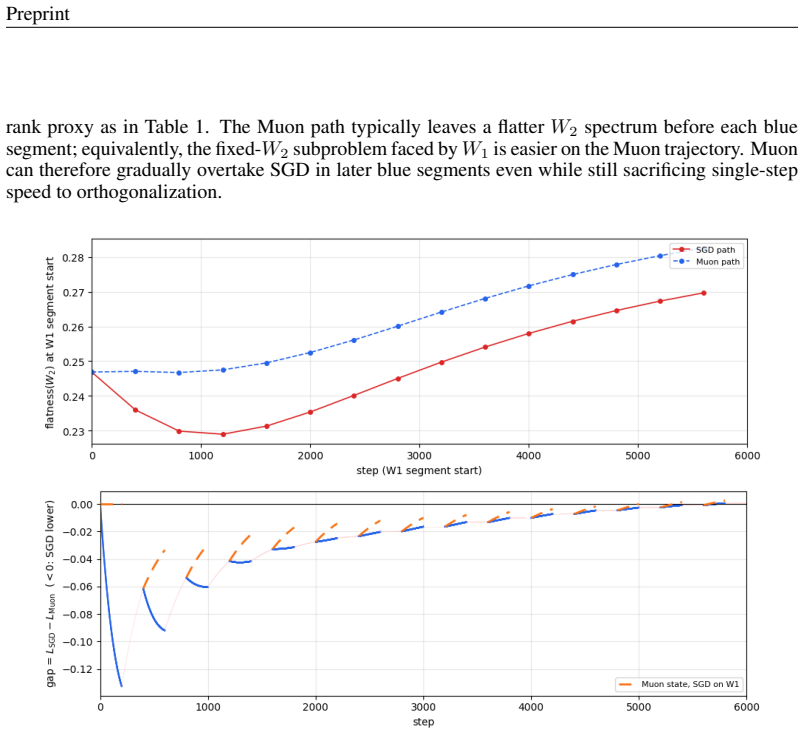
The zoom highlights the initial local- optimization advantage of SGD onW 1 segments before Muon’s representation advantage propa- gates through laterW 2 updates. Figure 2 plots this effect directly as the loss gapL SGD −L Muon, with Figure 3 zooming in on the first 2000 steps. The early negative gaps show SGD’s local advantage on fixed-W 2 blue seg- ments...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.