Why Muon Outperforms Adam: A Curvature Perspective
Pith reviewed 2026-06-28 07:02 UTC · model grok-4.3
The pith
Muon outperforms Adam by achieving smaller curvature penalty through lower normalized directional sharpness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
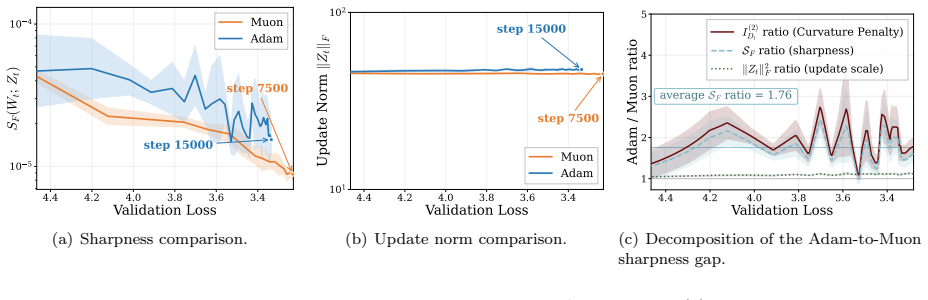
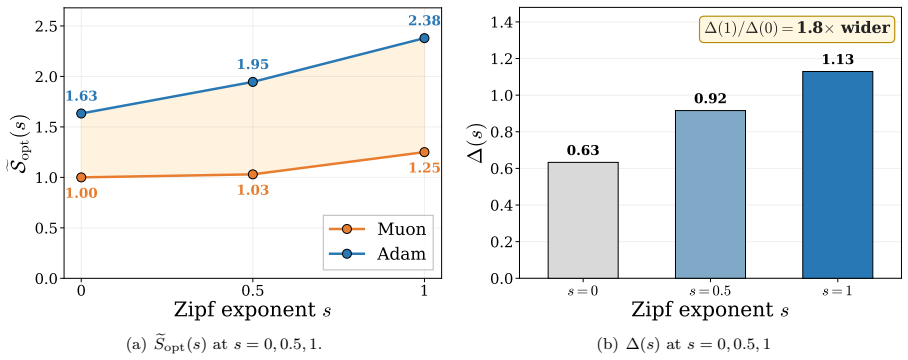
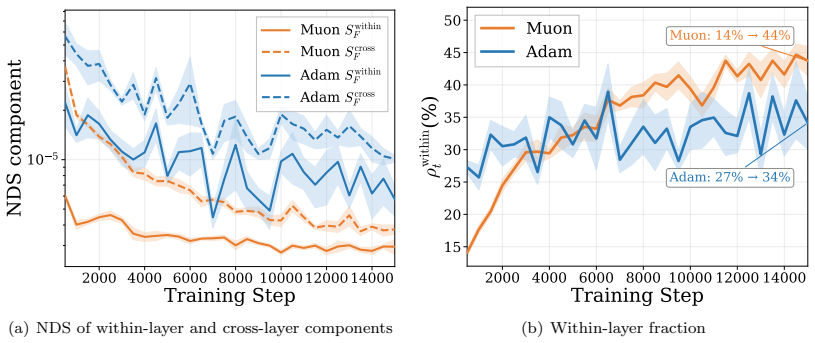
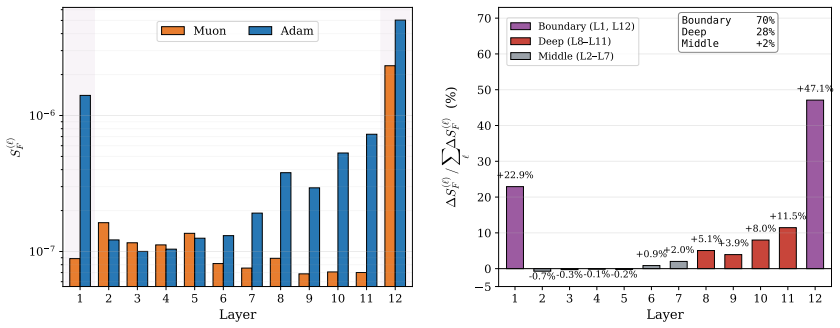
Applying a second-order Taylor expansion, the paper demonstrates that Muon produces a larger one-step loss decrease than Adam at the same validation loss because its curvature penalty is smaller. This advantage traces to lower Normalized Directional Sharpness rather than differences in update norm. In controlled experiments with Zipf-PCFG data, data imbalance widens the gap, and layer decomposition shows the effect concentrates in within-layer curvature during middle and late training. For stylized quadratics with heterogeneous curvature and gradient alignment to high-curvature modes, Muon is proven to achieve smaller average NDS than gradient descent by balancing update energy, resulting in
What carries the argument
Normalized Directional Sharpness (NDS), the curvature term in the second-order loss change normalized by the squared update norm, which Muon reduces by balancing update energy across curvature groups.
If this is right
- Muon achieves larger one-step loss decrease than Adam at matched validation loss.
- Data imbalance amplifies Muon's NDS advantage over Adam.
- Muon's NDS reduction in middle and late stages is driven by smaller within-layer curvature.
- In quadratic settings with strong curvature heterogeneity, balancing update energy yields lower local loss after equal steps.
Where Pith is reading between the lines
- The balancing mechanism may extend to other first-order methods that adjust updates according to curvature variation.
- The result implies that ignoring curvature heterogeneity could limit performance in data regimes with strong imbalance.
- Architecture modifications that reduce within-layer curvature differences could interact with or amplify such optimizer effects.
Load-bearing premise
The second-order Taylor approximation accurately captures the one-step loss decrease in the high-dimensional non-convex landscape of large language model training.
What would settle it
If measurements during actual LLM training show that Muon does not produce a larger one-step loss reduction than Adam when validation losses are matched, or that its NDS is not lower, the curvature explanation would not hold.
Figures
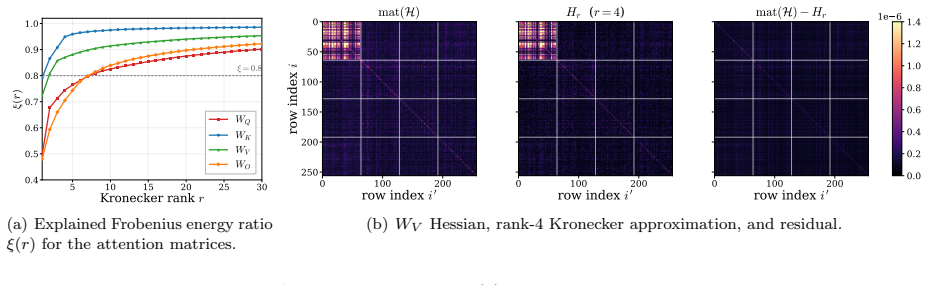
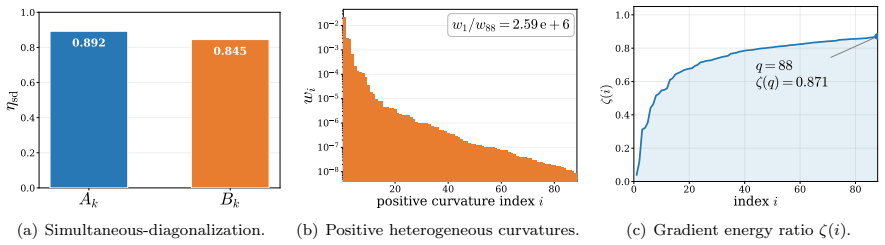
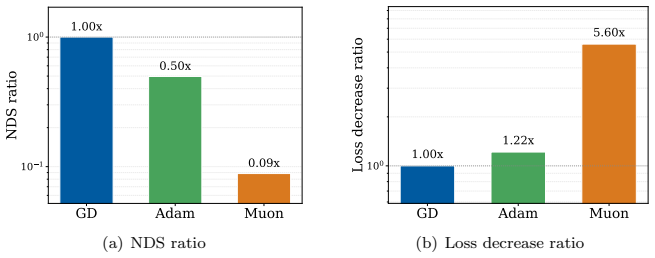
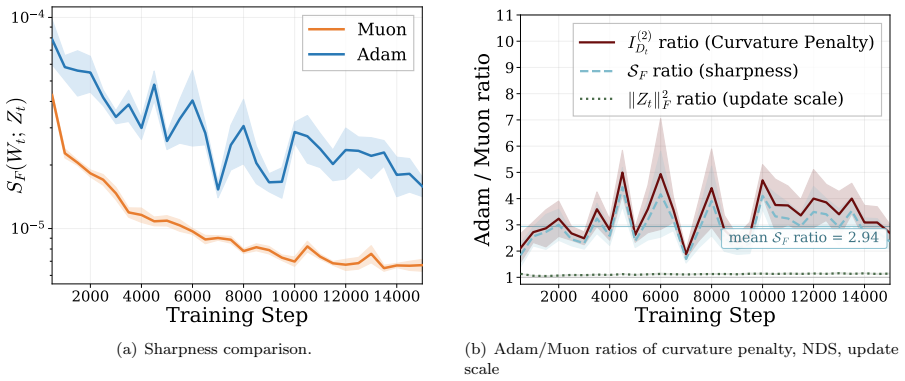

read the original abstract
Muon improves training efficiency over Adam in large language-model training by about two times, but the local geometric source of this advantage remains unclear. Our work takes a first step toward demystifying Muon's superiority over Adam from a curvature perspective. First, we apply a second-order Taylor approximation to the training landscape and show that Muon achieves a larger one-step loss decrease than Adam at matched validation loss. The two optimizers have comparable first-order gains, but Muon consistently incurs a smaller second-order curvature penalty. Second, we decompose this curvature penalty into the squared update norm and Normalized Directional Sharpness (NDS). We find that Muon and Adam have comparable update norms, so Muon's smaller curvature penalty is driven by lower NDS, not update scale. Third, we study how training data and model structure shape Muon's NDS advantage. Using Zipf-Probabilistic Context-Free Grammar (PCFG) data with controlled imbalance, we show that data imbalance amplifies Muon's NDS advantage over Adam. A within-/cross-layer decomposition further shows that, in the middle and late stages of training, Muon's lower NDS is mainly sustained by smaller within-layer curvature. Beyond empirical evidence, we analyze stylized quadratic problems with heterogeneous curvature and gradient alignment toward high-curvature modes. We prove that Muon attains a smaller average NDS than GD by balancing update energy across curvature groups; when curvature heterogeneity is sufficiently strong, this also yields lower local quadratic loss after the same number of steps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims Muon outperforms Adam in LLM training by achieving a larger one-step loss decrease under a second-order Taylor approximation of the loss landscape, driven by a smaller curvature penalty from lower Normalized Directional Sharpness (NDS) rather than comparable update norms. Empirical decompositions on real training runs and Zipf-PCFG data with controlled imbalance show data imbalance amplifies the NDS advantage, with within-layer curvature sustaining it in middle/late stages. A proof on stylized quadratic problems with heterogeneous curvature and gradient alignment proves Muon attains smaller average NDS than GD by balancing update energy across curvature groups, yielding lower local quadratic loss when heterogeneity is strong.
Significance. If the Taylor approximation reliably captures one-step dynamics, the work supplies a geometric account of optimizer differences via NDS and curvature heterogeneity, with credit due to the exact self-contained quadratic proof and the controlled empirical decomposition separating NDS from update norm. The introduction of NDS and the data-imbalance experiments provide mechanistic insight beyond standard optimizer comparisons.
major comments (1)
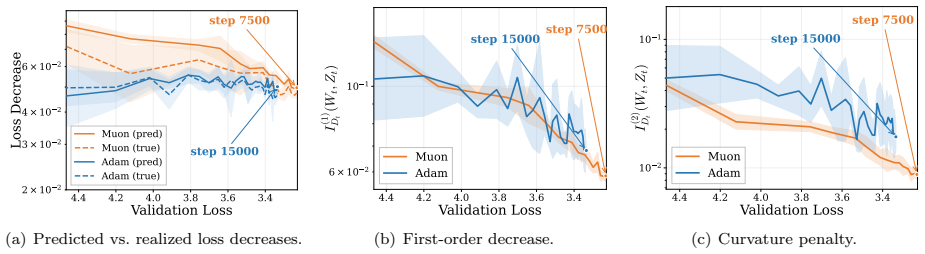
- [Abstract (first analysis step)] Abstract (first analysis step): The central claim that Muon achieves larger one-step loss decrease than Adam (at matched validation loss) because of smaller curvature penalty rests on the second-order Taylor expansion accurately predicting the actual loss change. In high-dimensional non-convex LLM landscapes, higher-order terms, movement across curvature regions, or step-size effects may dominate; no verification comparing the quadratic prediction to observed loss decrease is provided, so the subsequent NDS decomposition does not yet reliably explain performance gaps.
minor comments (2)
- The manuscript would benefit from an explicit early definition and formula for Normalized Directional Sharpness (NDS) before its use in the decomposition.
- Figure captions for the within-/cross-layer NDS plots should state the exact training stages (e.g., step ranges) and number of runs averaged.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the reliability of the second-order Taylor approximation. We address the major comment below.
read point-by-point responses
-
Referee: The central claim that Muon achieves larger one-step loss decrease than Adam (at matched validation loss) because of smaller curvature penalty rests on the second-order Taylor expansion accurately predicting the actual loss change. In high-dimensional non-convex LLM landscapes, higher-order terms, movement across curvature regions, or step-size effects may dominate; no verification comparing the quadratic prediction to observed loss decrease is provided, so the subsequent NDS decomposition does not yet reliably explain performance gaps.
Authors: We agree that an explicit verification comparing the quadratic prediction to the observed one-step loss decrease would strengthen the central claim. While the NDS decomposition itself is performed using gradients and curvature estimates from actual training runs (rather than purely from the approximation), we did not include a direct side-by-side comparison of predicted versus realized loss change. In the revised manuscript we will add this verification: on the LLM training trajectories we will compute the actual loss after a single optimizer step on held-out batches and report its correlation with the second-order Taylor prediction, along with the relative contribution of higher-order terms. This addition will clarify the regime in which the approximation remains informative and thereby support the subsequent geometric interpretation via NDS. revision: yes
Circularity Check
No significant circularity; derivation self-contained against external assumptions
full rationale
The paper's central chain begins with a second-order Taylor expansion applied to the loss (abstract, first analysis step), decomposes the curvature penalty into update norm and NDS (defined quantities), and then proves a comparison result for stylized quadratic problems with heterogeneous curvature. The quadratic proof is an exact derivation within its stated model and does not reduce to a fitted parameter or self-citation; NDS is computed from the Taylor term rather than reverse-engineered from performance gaps. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the provided derivation steps. The Taylor approximation's applicability to real LLM landscapes is a separate correctness question, not a circularity issue.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Second-order Taylor approximation suffices to compare one-step loss decreases between optimizers.
invented entities (1)
-
Normalized Directional Sharpness (NDS)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Muon as a Residual Connection
Muon is interpreted as an implicit residual connection that sacrifices local gradient fidelity to improve downstream layer usability in neural network training.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2410.06205 , year=
Round and Round We Go! What makes Rotary Positional Encodings useful? , author=. arXiv preprint arXiv:2410.06205 , year=
-
[10]
2024 , url =
Keller Jordan and Jeremy Bernstein and Brendan Rappazzo and @fernbear.bsky.social and Boza Vlado and You Jiacheng and Franz Cesista and Braden Koszarsky and @Grad62304977 , title =. 2024 , url =
2024
-
[11]
Advances in Neural Information Processing Systems , volume=
The fineweb datasets: Decanting the web for the finest text data at scale , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
, author=
Neural networks and physical systems with emergent collective computational abilities. , author=. Proceedings of the national academy of sciences , volume=
-
[13]
IEEE transactions on computers , volume=
Correlation matrix memories , author=. IEEE transactions on computers , volume=. 2009 , publisher=
2009
-
[14]
International Conference on Machine Learning , pages=
Resurrecting recurrent neural networks for long sequences , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[15]
European Conference on Computer Vision , pages=
Motion mamba: Efficient and long sequence motion generation , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[16]
Nature , volume=
Non-holographic associative memory , author=. Nature , volume=. 1969 , publisher=
1969
-
[17]
URL https://kellerjordan
Muon: An optimizer for hidden layers in neural networks, 2024 , author=. URL https://kellerjordan. github. io/posts/muon , volume=
2024
-
[21]
High-dimensional Learning Dynamics 2025 , year=
On Generalization of Spectral Gradient Descent: A Case Study on Imbalanced Data , author=. High-dimensional Learning Dynamics 2025 , year=
2025
-
[23]
arXiv e-prints , pages=
A note on the convergence of muon and further , author=. arXiv e-prints , pages=
-
[27]
On the Convergence Analysis of Muon
On the convergence analysis of muon , author=. arXiv preprint arXiv:2505.23737 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[33]
Advances in neural information processing systems , volume=
Symbolic discovery of optimization algorithms , author=. Advances in neural information processing systems , volume=
-
[34]
Advances in Neural Information Processing Systems , volume=
Convergence of adam under relaxed assumptions , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
Advances in neural information processing systems , volume=
Adam can converge without any modification on update rules , author=. Advances in neural information processing systems , volume=
-
[36]
Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition , pages=
A sufficient condition for convergences of adam and rmsprop , author=. Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition , pages=
-
[39]
Advances in neural information processing systems , volume=
Why transformers need adam: A hessian perspective , author=. Advances in neural information processing systems , volume=
-
[40]
, author=
Adaptive subgradient methods for online learning and stochastic optimization. , author=. Journal of machine learning research , volume=
-
[42]
Zero-Shot Relation Extraction via Reading Comprehension
Zero-shot relation extraction via reading comprehension , author=. arXiv preprint arXiv:1706.04115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Mathematics , volume=
Survey of optimization algorithms in modern neural networks , author=. Mathematics , volume=. 2023 , publisher=
2023
-
[44]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[45]
Advances in Neural Information Processing Systems , volume=
High-dimensional asymptotics of feature learning: How one gradient step improves the representation , author=. Advances in Neural Information Processing Systems , volume=
-
[46]
arXiv preprint arXiv:2305.18270 , year=
How two-layer neural networks learn, one (giant) step at a time , author=. arXiv preprint arXiv:2305.18270 , year=
-
[47]
arXiv preprint arXiv:2410.02355 , year=
Alphaedit: Null-space constrained knowledge editing for language models , author=. arXiv preprint arXiv:2410.02355 , year=
-
[48]
Advances in Neural Information Processing Systems , volume=
Heavy-tailed class imbalance and why adam outperforms gradient descent on language models , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
Transformer Feed-Forward Layers Are Key-Value Memories , year =
Transformer feed-forward layers are key-value memories , author=. arXiv preprint arXiv:2012.14913 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[50]
Mass-Editing Memory in a Transformer
Mass-editing memory in a transformer , author=. arXiv preprint arXiv:2210.07229 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Advances in neural information processing systems , volume=
What can transformers learn in-context? a case study of simple function classes , author=. Advances in neural information processing systems , volume=
-
[52]
arXiv preprint arXiv:2104.08696 , year=
Knowledge neurons in pretrained transformers , author=. arXiv preprint arXiv:2104.08696 , year=
-
[53]
Advances in neural information processing systems , volume=
Locating and editing factual associations in gpt , author=. Advances in neural information processing systems , volume=
-
[54]
Organization of memory , volume=
Episodic and semantic memory , author=. Organization of memory , volume=. 1972 , publisher=
1972
-
[55]
arXiv preprint arXiv:2412.06538 , year=
Understanding factual recall in transformers via associative memories , author=. arXiv preprint arXiv:2412.06538 , year=
-
[56]
arXiv preprint arXiv:2310.17813 , year=
A spectral condition for feature learning , author=. arXiv preprint arXiv:2310.17813 , year=
-
[58]
arXiv preprint arXiv:2410.11474 , year=
How transformers implement induction heads: Approximation and optimization analysis , author=. arXiv preprint arXiv:2410.11474 , year=
-
[59]
Advances in Neural Information Processing Systems , volume=
Birth of a transformer: A memory viewpoint , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
Advances in Neural Information Processing Systems , volume=
The evolution of statistical induction heads: In-context learning markov chains , author=. Advances in Neural Information Processing Systems , volume=
-
[61]
arXiv preprint arXiv:2409.10559 , year=
Unveiling induction heads: Provable training dynamics and feature learning in transformers , author=. arXiv preprint arXiv:2409.10559 , year=
-
[62]
arXiv preprint arXiv:2402.14735 , year=
How transformers learn causal structure with gradient descent , author=. arXiv preprint arXiv:2402.14735 , year=
-
[63]
International Conference on Learning Representations , year=
On the Convergence of A Class of Adam-Type Algorithms for Non-Convex Optimization , author=. International Conference on Learning Representations , year=
-
[64]
Gemma 3 technical report , author=. arXiv preprint arXiv:2503.19786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
arXiv preprint arXiv:2404.05405 , year=
Physics of language models: Part 3.3, knowledge capacity scaling laws , author=. arXiv preprint arXiv:2404.05405 , year=
-
[66]
Proceedings of the National Academy of Sciences , volume=
Singular value decomposition for genome-wide expression data processing and modeling , author=. Proceedings of the National Academy of Sciences , volume=. 2000 , publisher=
2000
-
[67]
2007 15th European signal processing conference , pages=
The effective rank: A measure of effective dimensionality , author=. 2007 15th European signal processing conference , pages=. 2007 , organization=
2007
-
[68]
Kimi K2: Open Agentic Intelligence
Kimi k2: Open agentic intelligence , author=. arXiv preprint arXiv:2507.20534 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
arXiv preprint arXiv:2407.07972 , year=
Deconstructing what makes a good optimizer for language models , author=. arXiv preprint arXiv:2407.07972 , year=
-
[72]
arXiv preprint arXiv:2408.09632 , year=
Modegpt: Modular decomposition for large language model compression , author=. arXiv preprint arXiv:2408.09632 , year=
-
[77]
IEE proceedings F (radar and signal processing) , volume=
Blind beamforming for non-Gaussian signals , author=. IEE proceedings F (radar and signal processing) , volume=. 1993 , organization=
1993
-
[78]
SIAM journal on matrix analysis and applications , volume=
Jacobi angles for simultaneous diagonalization , author=. SIAM journal on matrix analysis and applications , volume=. 1996 , publisher=
1996
-
[79]
International Conference on Machine Learning , pages=
Sharp minima can generalize for deep nets , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[83]
International conference on machine learning , pages=
Optimizing neural networks with kronecker-factored approximate curvature , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[84]
Advances in neural information processing systems , volume=
Fast approximate natural gradient descent in a kronecker factored eigenbasis , author=. Advances in neural information processing systems , volume=
-
[85]
arXiv preprint arXiv:2406.17748 , year=
A New Perspective on Shampoo's Preconditioner , author=. arXiv preprint arXiv:2406.17748 , year=
-
[86]
International Conference on Machine Learning , pages=
Shampoo: Preconditioned stochastic tensor optimization , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[99]
International conference on machine learning , pages=
Adafactor: Adaptive learning rates with sublinear memory cost , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[101]
Advances in neural information processing systems , volume=
Adabelief optimizer: Adapting stepsizes by the belief in observed gradients , author=. Advances in neural information processing systems , volume=
-
[102]
Large Batch Optimization for Deep Learning: Training BERT in 76 minutes
Large batch optimization for deep learning: Training bert in 76 minutes , author=. arXiv preprint arXiv:1904.00962 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[103]
arXiv preprint arXiv:2305.14342 , year=
Sophia: A scalable stochastic second-order optimizer for language model pre-training , author=. arXiv preprint arXiv:2305.14342 , year=
-
[104]
Advances in neural information processing systems , volume=
Visualizing the loss landscape of neural nets , author=. Advances in neural information processing systems , volume=
-
[107]
International conference on machine learning , pages=
Asam: Adaptive sharpness-aware minimization for scale-invariant learning of deep neural networks , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[109]
Advances in Neural Information Processing Systems , volume=
Sharpness minimization algorithms do not only minimize sharpness to achieve better generalization , author=. Advances in Neural Information Processing Systems , volume=
-
[111]
Linear algebra for large scale and real-time applications , pages=
Approximation with Kronecker products , author=. Linear algebra for large scale and real-time applications , pages=. 1993 , publisher=
1993
-
[115]
Advances in Neural Information Processing Systems , volume=
Sharpness-aware training for free , author=. Advances in Neural Information Processing Systems , volume=
- [121]
- [122]
-
[123]
Andriushchenko, M. , Croce, F. , M \"u ller, M. , Hein, M. and Flammarion, N. (2023). A modern look at the relationship between sharpness and generalization. arXiv preprint arXiv:2302.07011
-
[124]
arXiv preprint arXiv:2002.09018 , year=
Anil, R. , Gupta, V. , Koren, T. , Regan, K. and Singer, Y. (2020). Scalable second order optimization for deep learning. arXiv preprint arXiv:2002.09018
-
[125]
Bernstein, J. and Newhouse, L. (2024 a ). Modular duality in deep learning. arXiv preprint arXiv:2410.21265
-
[126]
Old Optimizer, New Norm: An Anthology
Bernstein, J. and Newhouse, L. (2024 b ). Old optimizer, new norm: An anthology. arXiv preprint arXiv:2409.20325
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[127]
Boissin, T. , Massena, T. , Mamalet, F. and Serrurier, M. (2025). Turbo-muon: Accelerating orthogonality-based optimization with pre-conditioning. arXiv preprint arXiv:2512.04632
-
[128]
and Souloumiac, A
Cardoso, J.-F. and Souloumiac, A. (1993). Blind beamforming for non-gaussian signals. In IEE proceedings F (radar and signal processing), vol. 140. IET
1993
-
[129]
and Souloumiac, A
Cardoso, J.-F. and Souloumiac, A. (1996). Jacobi angles for simultaneous diagonalization. SIAM journal on matrix analysis and applications, 17 161--164
1996
- [130]
-
[131]
, Liu, S
Chen, X. , Liu, S. , Sun, R. and Hong, M. (2019). On the convergence of a class of adam-type algorithms for non-convex optimization. In International Conference on Learning Representations. ://openreview.net/forum?id=H1x-x309tm
2019
- [132]
- [133]
-
[134]
D \'e fossez, A. , Bottou, L. , Bach, F. and Usunier, N. (2020). A simple convergence proof of adam and adagrad. arXiv preprint arXiv:2003.02395
-
[135]
, Pascanu, R
Dinh, L. , Pascanu, R. , Bengio, S. and Bengio, Y. (2017). Sharp minima can generalize for deep nets. In International Conference on Machine Learning. PMLR
2017
-
[136]
Dong, Z. , Zhang, Y. , Yao, J. and Sun, R. (2025). Towards quantifying the hessian structure of neural networks. arXiv preprint arXiv:2505.02809
- [137]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.