EffiNav: Fusing Depth and Vision-Language for Efficient Object Goal Navigation
Pith reviewed 2026-06-26 21:01 UTC · model grok-4.3
The pith
Fusing depth maps with vision-language outputs lets navigation agents choose next steps that cut revisits and redundant motion in unknown spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EffiNav fuses depth and vision-language signals to produce exploration decisions that avoid excessive revisits or redundant back-and-forth motion, delivering success rates and success-weighted path lengths that match or surpass recent baselines on HM3D and OVON while validating on physical robots and extending to memory-augmented object goal navigation on GOAT-BENCH.
What carries the argument
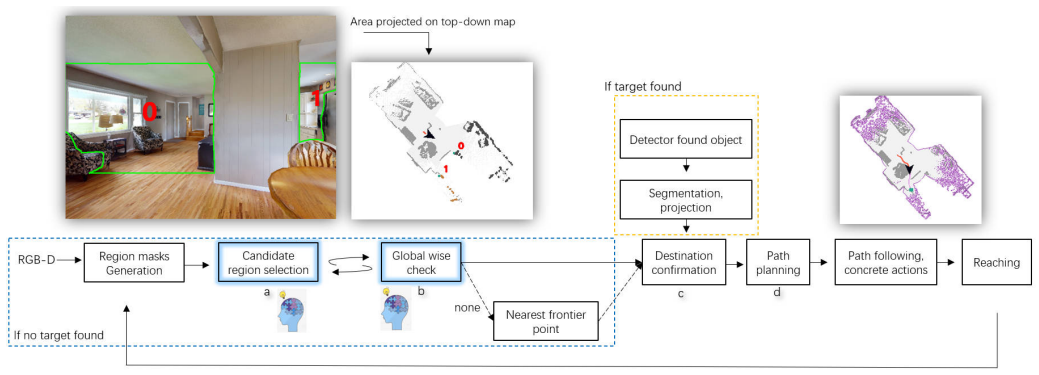
Fusion of depth maps and vision-language model outputs to select the next exploration location in unknown environments.
If this is right
- Agents reach targets with higher path efficiency as measured by SPL.
- The same fusion works across two distinct simulation benchmarks without retraining.
- Real-robot deployment requires only minimal changes from the simulated version.
- The framework extends to memory-augmented object goal navigation with little modification.
Where Pith is reading between the lines
- The fusion approach may generalize to environments containing dynamic obstacles if depth updates remain reliable.
- Combining the method with additional sensors such as wheel odometry could further lower path length in cluttered spaces.
- Failure analysis on large episode sets could identify specific scene types where language cues add the most value over depth alone.
Load-bearing premise
That depth and vision-language signals together yield exploration choices that reliably reduce revisits and redundant motion compared with prior methods.
What would settle it
A set of new simulation episodes where EffiNav produces trajectories whose revisit rate or back-and-forth count matches or exceeds the worst-performing baselines.
Figures








read the original abstract
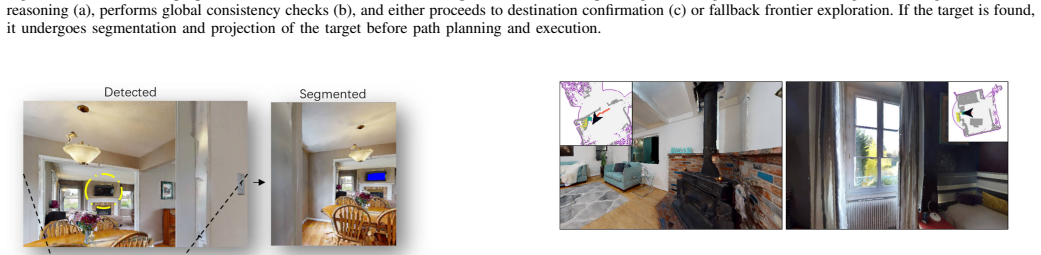
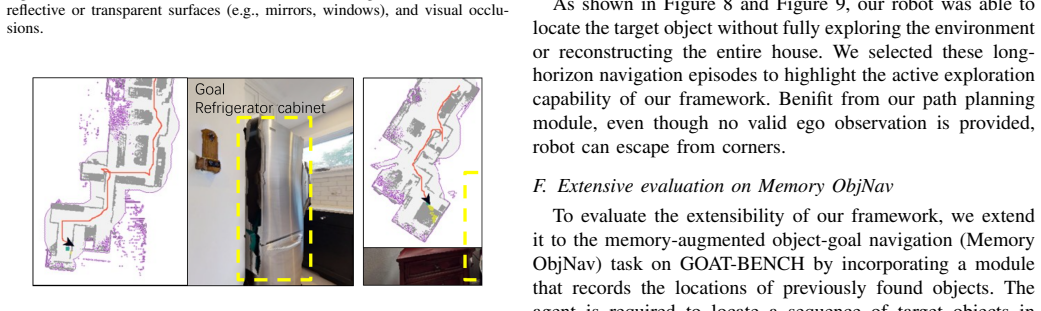
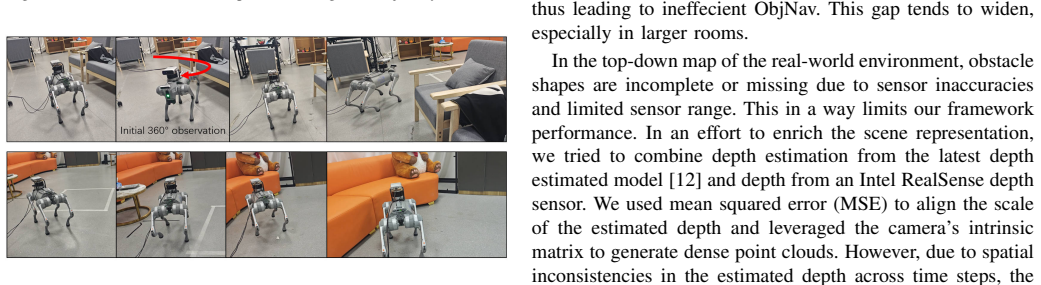
To locate a target object while exploring the unknown environment is a fundamental capability for autonomous agents, with applications ranging from search-and-rescue to field robots. A simplified version of such task is Object Goal Navigation (ObjNav). In ObjNav, successful arrival at the target object provides a basic measure of performance; however, the efficiency of the navigation trajectory is equally important, as it indicates how intelligently the agent explores and how much time remains for subsequent tasks. In unknown environments, the key to efficient navigation lies in deciding where to explore next. While many prior works aim to address this core challenge and achieved promising performance in certain settings, recent training-based models and non-training frameworks still suffer from generalization and efficiency issues respectively, which in the worst cases can lead to excessive exploration of already-visited areas or redundant back-and-forth motion. We evaluate EffiNav on two widely used simulation benchmarks Habitat Matterport 3D (HM3D) and Open-Vocabulary Object goal Navigation (OVON), and further validate its effectiveness on physical robots in real-world settings. We conduct failure analysis on massive simulation episodes. With minimal modification, we also extend EffiNav to a memory-augmented ObjNav task on the GOAT-BENCH dataset, demonstrating its adaptability beyond standard ObjNav settings. Across two standard metrics--Success Rate (SR) and Success weighted by Path Length (SPL), EffiNav matches or outperforms recent baselines, reflecting its efficiency, robustness, and practical applicability. Recognizing the different emphases of the two datasets, the performances reveals this framework is more balanced and generalizable for efficient ObjNav.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EffiNav, a framework fusing depth information with vision-language models to enable more efficient exploration decisions in Object Goal Navigation (ObjNav) tasks within unknown environments. It evaluates the approach on HM3D and OVON simulation benchmarks, extends it with minimal modification to a memory-augmented setting on GOAT-BENCH, and includes real-robot validation, while providing failure analysis across simulation episodes. The central claim is that EffiNav matches or outperforms recent baselines on Success Rate (SR) and Success weighted by Path Length (SPL), indicating improved efficiency, robustness, and generalizability.
Significance. If the reported performance on SR and SPL holds, the work provides a practical fusion-based approach that balances success and trajectory efficiency in ObjNav, with demonstrated adaptability to related tasks and real-world settings. This could support deployment in applications such as search-and-rescue where avoiding redundant motion is critical.
minor comments (3)
- [Abstract] Abstract: The final sentence contains a subject-verb agreement error ('the performances reveals' should be 'the performance reveals').
- [Abstract] Abstract and §4: While the text states that EffiNav 'matches or outperforms' baselines on SR and SPL, the abstract itself provides no numerical values, error bars, or dataset-specific breakdowns; ensure the results section supplies these with clear table references for verifiability.
- The description of real-robot validation would benefit from explicit mention of sensor setup, environment scale, and any domain-shift handling to strengthen the practical-applicability claim.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work on EffiNav and the recommendation for minor revision. The referee's description accurately captures the framework's fusion of depth and vision-language inputs, its performance on HM3D and OVON, the real-robot validation, failure analysis, and the extension to GOAT-BENCH. No specific major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper describes an empirical navigation framework whose performance claims rest on direct comparisons against external baselines on HM3D, OVON, GOAT-BENCH, and real-robot trials. No equations, fitted parameters, or first-principles derivations appear in the provided text; success metrics (SR, SPL) are reported as measured outcomes rather than quantities defined in terms of themselves. No self-citation chains or ansatzes are invoked to close any derivation loop, so the argument chain remains open to external falsification.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Peter Anderson, Angel Chang, Devendra Singh Chaplot, Alexey Dosovitskiy, Saurabh Gupta, Vladlen Koltun, Jana Kosecka, Jitendra Malik, Roozbeh Mottaghi, Mano- lis Savva, and Amir R. Zamir. On evaluation of embodied navigation agents, 2018. URL https://arxiv.org/abs/1807. 06757
2018
-
[2]
Navdp: Learning sim-to-real navigation diffusion policy with privileged information guidance, 2025
Wenzhe Cai, Jiaqi Peng, Yuqiang Yang, Yujian Zhang, Meng Wei, Hanqing Wang, Yilun Chen, Tai Wang, and Jiangmiao Pang. Navdp: Learning sim-to-real navigation diffusion policy with privileged information guidance, 2025
2025
-
[3]
Cognav: Cognitive process modeling for object goal navigation with llms
Yihan Cao, Jiazhao Zhang, Zhinan Yu, Shuzhen Liu, Zheng Qin, Qin Zou, Bo Du, and Kai Xu. Cognav: Cognitive process modeling for object goal navigation with llms. InInternational Conference on Computer Vision (ICCV), 2025
2025
-
[4]
Matterport3D: Learning from RGB-D data in indoor environments.International Conference on 3D Vision (3DV), 2017
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3D: Learning from RGB-D data in indoor environments.International Conference on 3D Vision (3DV), 2017
2017
-
[5]
Navila: Legged robot vision-language- action model for navigation
An-Chieh Cheng, Yandong Ji, Zhaojing Yang, Xueyan Zou, Jan Kautz, Erdem Biyik, Hongxu Yin, Sifei Liu, and Xiaolong Wang. Navila: Legged robot vision-language- action model for navigation. InRSS, 2025
2025
-
[6]
End-to-end navigation with vlms: Trans- forming spatial reasoning into question-answering
Dylan Goetting, Himanshu Gaurav Singh, and Antonio Loquercio. End-to-end navigation with vlms: Trans- forming spatial reasoning into question-answering. In Workshop on Language and Robot Learning: Language as an Interface, 2024
2024
-
[7]
Yiming Ji, Kaijie Yun, Yang Liu, Zhengpu Wang, Boyu Ma, Zongwu Xie, and Hong Liu. Diffusion as reasoning: Enhancing object navigation via diffusion model condi- tioned on llm-based object-room knowledge, 2025. URL https://arxiv.org/abs/2410.21842
-
[8]
Zihe Ji, Huangxuan Lin, and Yue Gao. Dynavlm: Zero- shot vision-language navigation system with dynamic viewpoints and self-refining graph memory, 2025. URL https://arxiv.org/abs/2506.15096
-
[9]
Goat-bench: A benchmark for multi- modal lifelong navigation, 2024
Mukul Khanna*, Ram Ramrakhya*, Gunjan Chhablani, Sriram Yenamandra, Theophile Gervet, Matthew Chang, Zsolt Kira, Devendra Singh Chaplot, Dhruv Batra, and Roozbeh Mottaghi. Goat-bench: A benchmark for multi- modal lifelong navigation, 2024
2024
-
[10]
Beyond the nav-graph: Vision- and-language navigation in continuous environments
Jacob Krantz, Erik Wijmans, Arjun Majumdar, Dhruv Batra, and Stefan Lee. Beyond the nav-graph: Vision- and-language navigation in continuous environments. In Andrea Vedaldi, Horst Bischof, Thomas Brox, and Jan- Michael Frahm, editors,Computer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23- 28, 2020, Proceedings, Part XXVIII, volume ...
-
[11]
Ground-level viewpoint vision-and-language navigation in continuous environments
Zerui Li, Gengze Zhou, Haodong Hong, Yanyan Shao, Wenqi Lyu, Yanyuan Qiao, and Qi Wu. Ground-level viewpoint vision-and-language navigation in continuous environments. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 5266–5273,
-
[12]
doi: 10.1109/ICRA55743.2025.11127275
-
[13]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
PIVOT: iterative visual prompting elicits action- able knowledge for vlms
Soroush Nasiriany, Fei Xia, Wenhao Yu, Ted Xiao, Jacky Liang, Ishita Dasgupta, Annie Xie, Danny Driess, Ayzaan Wahid, Zhuo Xu, Quan Vuong, Tingnan Zhang, Tsang-Wei Edward Lee, Kuang-Huei Lee, Peng Xu, Sean Kirmani, Yuke Zhu, Andy Zeng, Karol Hausman, Nicolas Heess, Chelsea Finn, Sergey Levine, and Brian Ichter. PIVOT: iterative visual prompting elicits ac...
2024
-
[15]
Habitat 3.0: A co-habitat for humans, avatars and robots, 2023
Xavi Puig, Eric Undersander, Andrew Szot, Mikael Dal- laire Cote, Ruslan Partsey, Jimmy Yang, Ruta Desai, Alexander William Clegg, Michal Hlavac, Tiffany Min, Theo Gervet, Vladim ´ır V ondrus, Vincent-Pierre Berges, John Turner, Oleksandr Maksymets, Zsolt Kira, Mrinal Kalakrishnan, Jitendra Malik, Devendra Singh Chaplot, Unnat Jain, Dhruv Batra, Akshara R...
2023
-
[16]
Open- nav: Exploring zero-shot vision-and-language navigation in continuous environment with open-source llms
Yanyuan Qiao, Wenqi Lyu, Hui Wang, Zixu Wang, Zerui Li, Yuan Zhang, Mingkui Tan, and Qi Wu. Open- nav: Exploring zero-shot vision-and-language navigation in continuous environment with open-source llms. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[17]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. URL https://arxiv.org/abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
Santhosh K. Ramakrishnan, Aaron Gokaslan, Erik Wij- mans, Oleksandr Maksymets, Alex Clegg, John Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X. Chang, Manolis Savva, Yili Zhao, and Dhruv Batra. Habitat-matterport 3d dataset (hm3d): 1000 large- scale 3d environments for embodied ai, 2021. URL https://arxiv.org/abs/2109.08238
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[19]
Pirlnav: Pretraining with imitation and rl finetuning for objectnav
Ram Ramrakhya, Dhruv Batra, Erik Wijmans, and Ab- hishek Das. Pirlnav: Pretraining with imitation and rl finetuning for objectnav. InComputer Vision and Pattern Recognition (CVPR), 2023 IEEE Conference on, 2023
2023
-
[20]
Vint: A foundation model for visual navigation
Dhruv Shah, Ajay Sridhar, Nitish Dashora, Kyle Sta- chowicz, Kevin Black, Noriaki Hirose, and Sergey Levine. Vint: A foundation model for visual navigation. In Jie Tan, Marc Toussaint, and Kourosh Darvish, editors, Proceedings of The 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning Re- search, pages 711–733. PMLR, 06–09 Nov 2...
2023
-
[21]
NoMaD: Goal Masked Diffusion Policies for Navigation and Exploration
Ajay Sridhar, Dhruv Shah, Catherine Glossop, and Sergey Levine. NoMaD: Goal Masked Diffusion Policies for Navigation and Exploration. InInternational Confer- ence on Robotics and Automation(ICRA), 2024. URL https://arxiv.org/abs/2310.xxxx
2024
-
[22]
Boyang Sun, Hanzhi Chen, Stefan Leutenegger, Cesar Cadena, Marc Pollefeys, and Hermann Blum. Frontier- net: Learning visual cues to explore.IEEE Robotics and Automation Letters, 10(7):6576–6583, 2025. doi: 10.1109/LRA.2025.3569122
-
[23]
Qwen2.5-vl, January 2025
Qwen Team. Qwen2.5-vl, January 2025. URL https: //qwenlm.github.io/blog/qwen2.5-vl/
2025
-
[24]
Trackvla: Embodied visual tracking in the wild.arXiv pre-print, 2025
Shaoan Wang, Jiazhao Zhang, Minghan Li, Jiahang Liu, Anqi Li, Kui Wu, Fangwei Zhong, Junzhi Yu, Zhizheng Zhang, and He Wang. Trackvla: Embodied visual tracking in the wild.arXiv pre-print, 2025. URL http://arxiv.org/abs/2505.23189
-
[25]
3d-mem: 3d scene memory for embodied exploration and reasoning
Yuncong Yang, Han Yang, Jiachen Zhou, Peihao Chen, Hongxin Zhang, Yilun Du, and Chuang Gan. 3d-mem: 3d scene memory for embodied exploration and reasoning. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 17294–17303, June 2025
2025
-
[26]
Navigation with vlm framework: Go to any language, 2024
Zecheng Yin, Chonghao Cheng, and Lizhen. Navigation with vlm framework: Go to any language, 2024. URL https://arxiv.org/abs/2410.02787
-
[27]
Hypernav: Hybrid perception for object-oriented navigation in unknown en- vironment, 2025
Zecheng Yin, Hao Zhao, and Zhen Li. Hypernav: Hybrid perception for object-oriented navigation in unknown en- vironment, 2025. URL https://arxiv.org/abs/2510.22917
-
[28]
Vlfm: Vision-language frontier maps for zero-shot semantic navigation
Naoki Yokoyama, Sehoon Ha, Dhruv Batra, Jiuguang Wang, and Bernadette Bucher. Vlfm: Vision-language frontier maps for zero-shot semantic navigation. In International Conference on Robotics and Automation (ICRA), 2024
2024
-
[29]
Hm3d-ovon: A dataset and benchmark for open-vocabulary object goal naviga- tion
Naoki Yokoyama, Ram Ramrakhya, Abhishek Das, Dhruv Batra, and Sehoon Ha. Hm3d-ovon: A dataset and benchmark for open-vocabulary object goal naviga- tion. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024
2024
-
[30]
Trajectory diffusion for objectgoal navigation
Xinyao Yu, Sixian Zhang, Xinhang Song, Xiaorong Qin, and Shuqiang Jiang. Trajectory diffusion for objectgoal navigation. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA, 2025. Curran Associates Inc. ISBN 9798331314385
2025
-
[31]
Gamap: zero-shot object goal navigation with multi-scale geometric-affordance guidance
Shuaihang Yuan, Hao Huang, Yu Hao, Congcong Wen, Anthony Tzes, and Yi Fang. Gamap: zero-shot object goal navigation with multi-scale geometric-affordance guidance. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA, 2025. Curran Associates Inc. ISBN 9798331314385
2025
-
[32]
Navidiffusor: Cost-guided diffusion model for visual navigation
Yiming Zeng, Hao Ren, Shuhang Wang, Junlong Huang, and Hui Cheng. Navidiffusor: Cost-guided diffusion model for visual navigation. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[33]
Faster Segment Anything: Towards Lightweight SAM for Mobile Applications
Chaoning Zhang, Dongshen Han, Yu Qiao, Jung Uk Kim, Sung-Ho Bae, Seungkyu Lee, and Choong Seon Hong. Faster segment anything: Towards lightweight sam for mobile applications.arXiv preprint arXiv:2306.14289, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Embodied navigation foundation model
Jiazhao Zhang, Anqi Li, Yunpeng Qi, Minghan Li, Jia- hang Liu, Shaoan Wang, Haoran Liu, Gengze Zhou, Yuze Wu, Xingxing Li, et al. Embodied navigation foundation model.arXiv preprint arXiv:2509.12129, 2025
-
[35]
Uni-navid: A video-based vision- language-action model for unifying embodied navigation tasks.Robotics: Science and Systems, 2025
Jiazhao Zhang, Kunyu Wang, Shaoan Wang, Minghan Li, Haoran Liu, Songlin Wei, Zhongyuan Wang, Zhizheng Zhang, and He Wang. Uni-navid: A video-based vision- language-action model for unifying embodied navigation tasks.Robotics: Science and Systems, 2025
2025
-
[36]
URL https://arxiv.org/abs/2508.04598
Lingfeng Zhang, Xiaoshuai Hao, Yingbo Tang, Haoxiang Fu, Xinyu Zheng, Pengwei Wang, Zhongyuan Wang, Wenbo Ding, and Shanghang Zhang.nava 3: Under- standing any instruction, navigating anywhere, finding anything, 2025. URL https://arxiv.org/abs/2508.04598
-
[37]
yes” or “no
Yufeng Zhong, Chengjian Feng, Feng Yan, Fanfan Liu, Liming Zheng, and Lin Ma. Robotron-nav: A unified framework for embodied navigation integrating percep- tion, planning, and prediction. InInternational Confer- ence on Computer Vision (ICCV), 2025. APPENDIX LetNdenote the total number of evaluation episodes. For each episodei∈ {1, . . . , N}, define: •I ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.