Memory as a Wasting Asset: Pricing Flash Endurance for Embodied Agents, and the Limits of Doing So
Pith reviewed 2026-06-27 00:53 UTC · model grok-4.3
The pith
A single endurance shadow price turns robot memory placement into a cost-optimal threshold rule across RAM, flash, and cloud.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
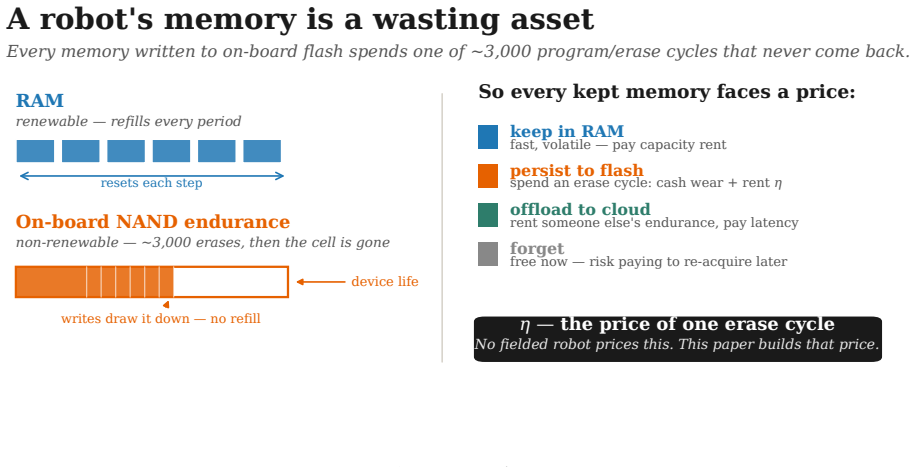
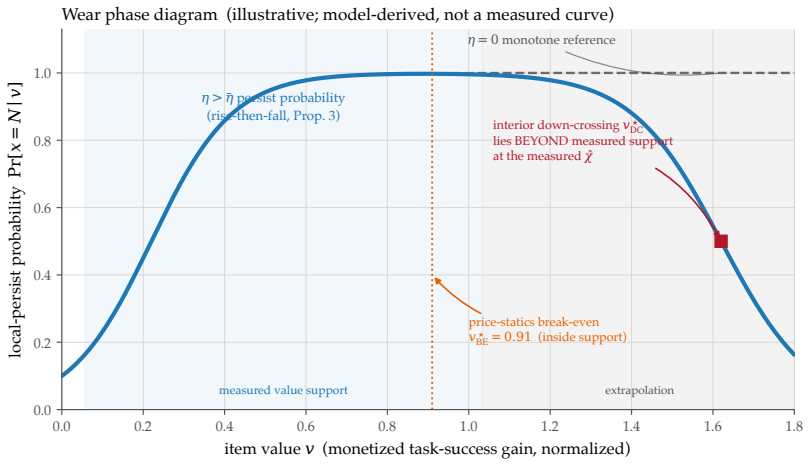
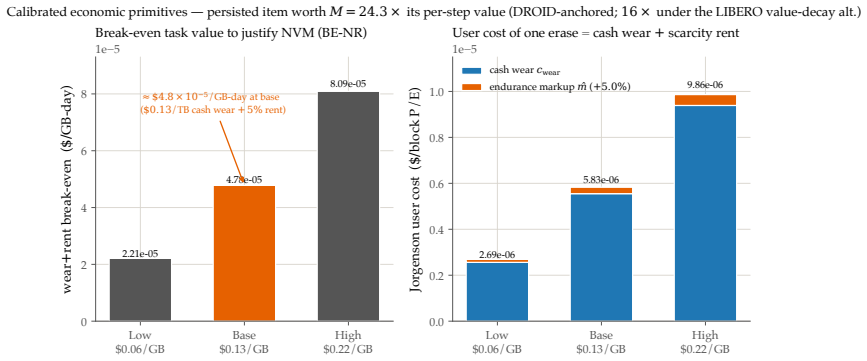
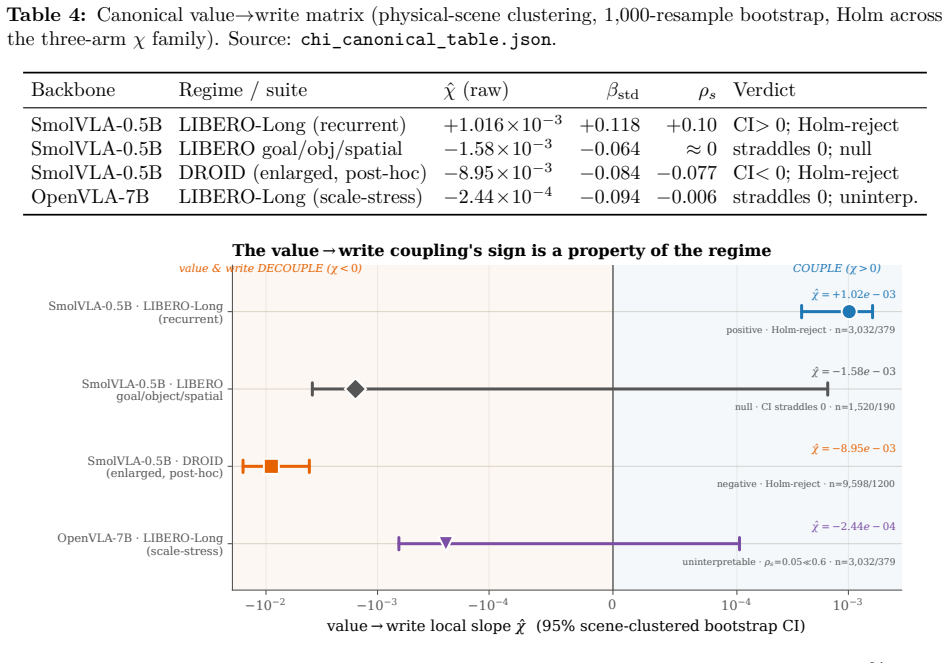
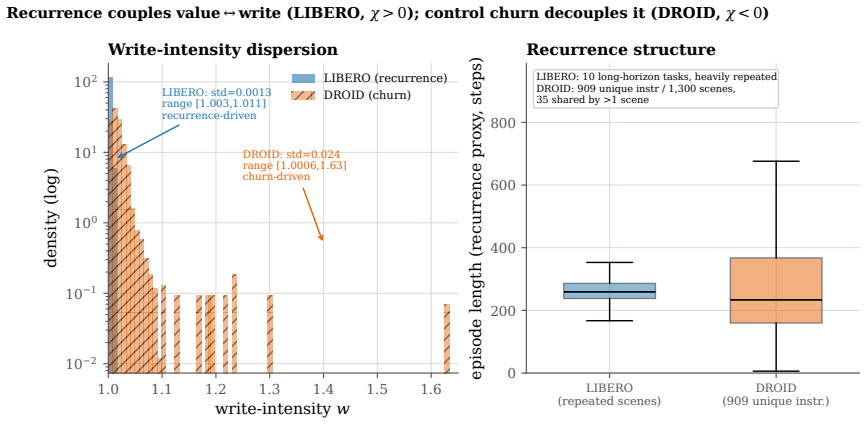
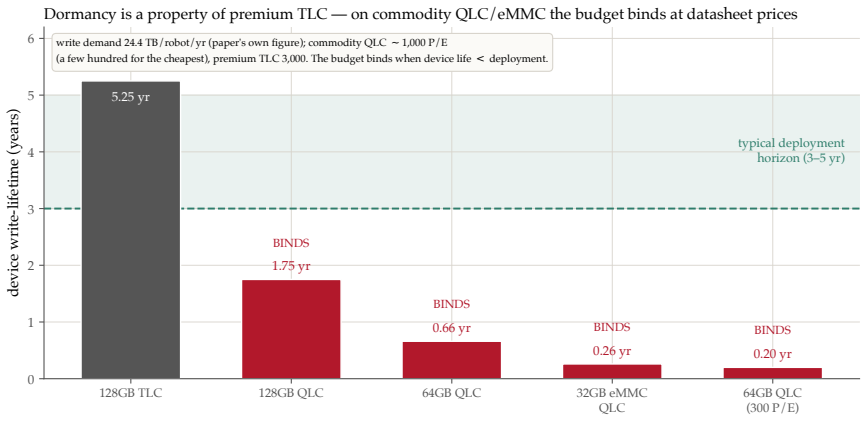
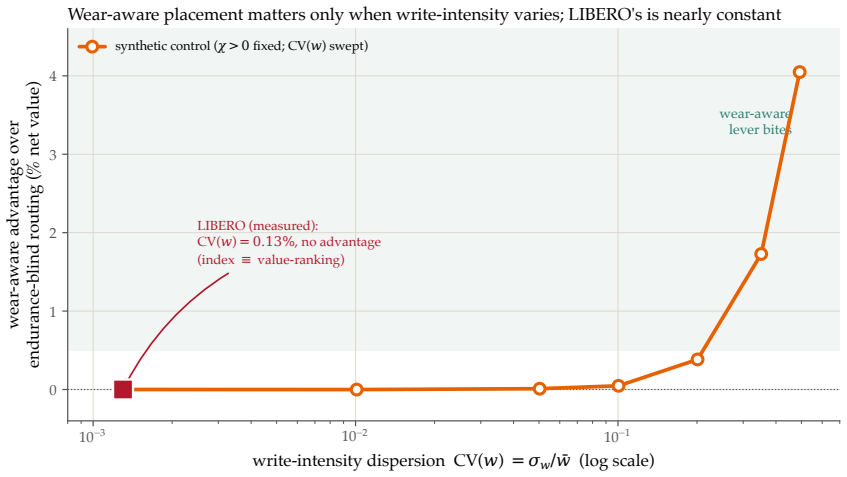
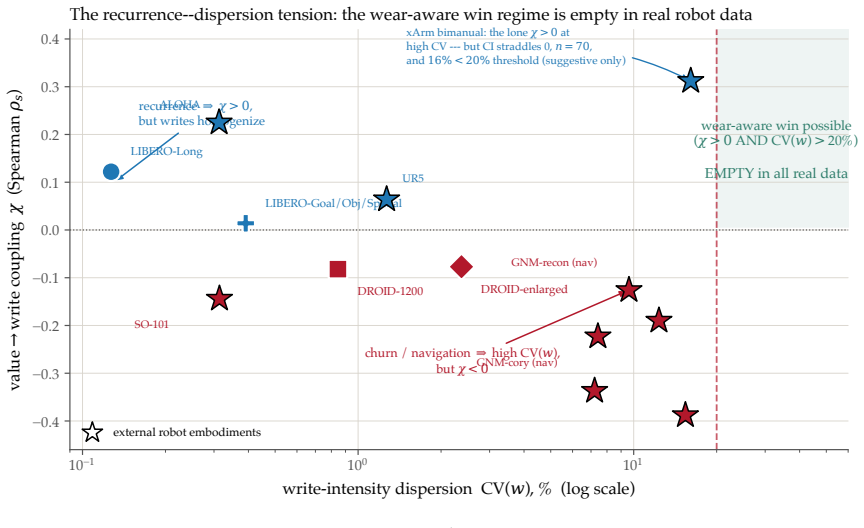
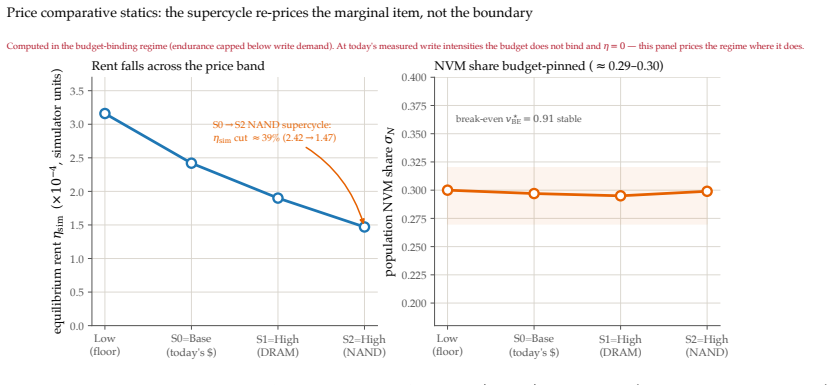
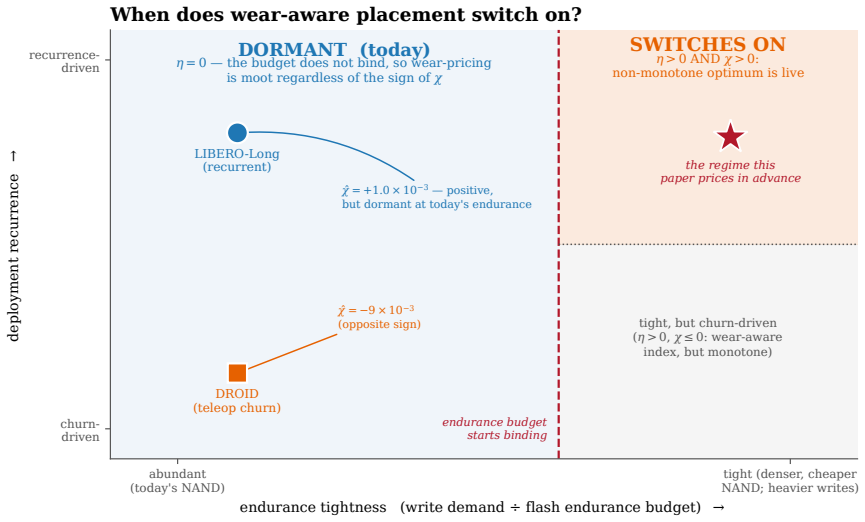
The central claim is that pricing flash endurance with a single shadow price η makes the cost-minimizing placement of memories across a RAM/on-board NVM/cloud hierarchy a threshold rule on a wear-augmented per-byte index. This index remains cost-optimal for any sign of the value-write association χ. Only when χ is positive does the optimum become non-monotone, moving the robot's most valuable memories off its flash. The endurance budget is dormant on premium TLC flash but binding on commodity QLC/eMMC. Where it binds, price-based routing ties learned wear-aware controllers on task value because realized value is tier-invariant.
What carries the argument
the endurance shadow price η that converts memory placement into a threshold on a wear-augmented per-byte index
If this is right
- The placement rule works regardless of whether valuable data is written more frequently.
- When the association is positive, the most valuable memories are evicted from flash.
- The budget only constrains decisions on lower-endurance commodity flash.
- Price-based routing performs as well as learned wear-aware methods on task value.
- The non-monotone optimum remains untested in data.
Where Pith is reading between the lines
- If the tier-invariance of value holds, then task performance depends only on access speed, not on where data lives.
- This suggests that for cheaper robots, endurance pricing could extend device life without hurting capabilities.
- Testing the non-monotone case would require logs from long-horizon recurrent tasks with varying memory values.
Load-bearing premise
Value realized by a memory stays the same whether it sits in RAM, on flash, or in the cloud, so only the rental cost and endurance matter for decisions.
What would settle it
Observing whether the non-monotone placement optimum actually appears in robot logs from recurrent manipulation tasks, or measuring if a wear-aware controller ever beats the price rule on realized task value.
Figures



read the original abstract
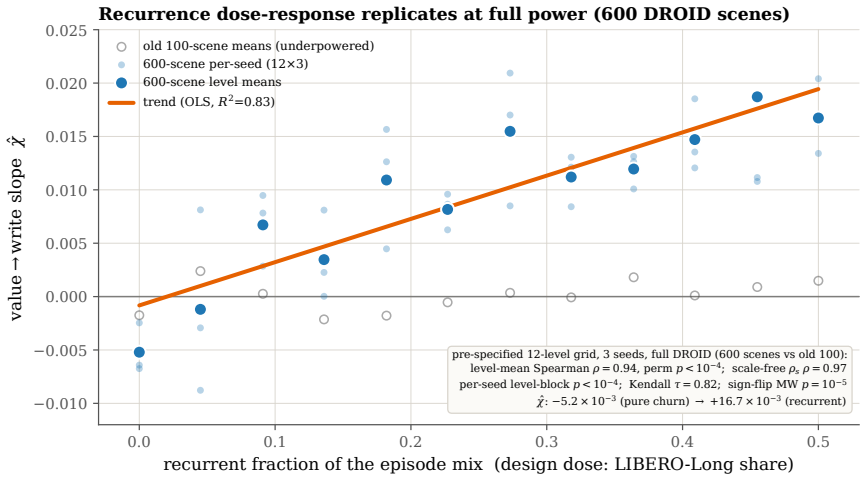
A robot's flash endurance is a non-renewable stock: every persisted write spends one of a few thousand program/erase cycles and never refills, yet no fielded robot memory system prices which memories are worth an erase cycle. We treat embodied memory as depreciating capital and price that stock with a single endurance shadow price $\eta$, which makes cost-minimizing placement across a RAM / on-board NVM / cloud hierarchy a threshold in a wear-augmented per-byte index. The index is cost-optimal whatever the sign of the value-write association $\chi$; only when $\chi > 0$ does the optimum turn non-monotone, sending a robot's most valuable memories off its flash. The pivot is thus empirical, and we measure $\chi$ on real robot logs at a pre-specified gate: its sign is a property of the deployment regime -- positive on recurrent long-horizon manipulation ($\hat{\chi} \approx +1.0 \times 10^{-3}$, replicated at full power), null on a shorter-horizon suite, and negative on non-recurrent teleoperation. Two boundaries scope the result. The endurance budget is dormant on premium 3,000-P/E TLC at datasheet prices and binding on the commodity QLC/eMMC ($\sim$1,000 P/E) that cheaper edge robots run. And where it binds, a learned wear-aware controller only ties price-based routing on task value, because realized value is tier-invariant across RAM, NVM, and cloud: the rent governs device lifetime and cost, not task performance. Whether wear-aware placement improves task value remains open -- $\chi$ is measured against a value proxy, and the non-monotone optimum, while proven, is not yet observed in data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that flash endurance can be priced via a shadow price η to derive a wear-augmented per-byte index for cost-minimizing placement of memories across RAM/NVM/cloud in embodied agents. The index is asserted to be optimal for any sign of the value-write association χ; non-monotonicity (and thus eviction of high-value memories) arises only when χ > 0. Empirically, χ is measured from external robot logs at a pre-specified gate, yielding positive values for recurrent long-horizon manipulation, null or negative otherwise. Endurance is dormant at premium 3000 P/E TLC datasheet prices but binding at commodity ~1000 P/E QLC/eMMC levels; a learned wear-aware controller only ties price-based routing because realized value is tier-invariant, so rent (not task performance) governs lifetime.
Significance. If the central derivation and empirical sign-of-χ result hold, the work supplies a first-principles cost-minimization framework for non-renewable memory stock in robots, with clear hardware-scope boundaries and an explicit statement that the non-monotone optimum remains unobserved. Credit is due for deriving the placement rule from external logs rather than internal fitting (avoiding tautology) and for the transparent acknowledgment that wear-aware gains on task value are untested.
major comments (2)
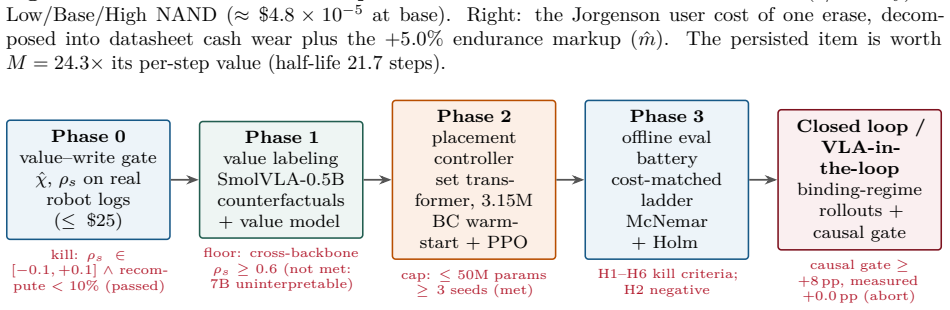
- [Empirical measurement of χ (abstract and results section)] The empirical pivot on χ (measured at a pre-specified gate on robot logs) is load-bearing for the claim that its sign is a property of the deployment regime and for the conclusion that endurance binds only on low-P/E media. The manuscript must supply the exact gate definition, error bars on the reported χ̂ ≈ +1.0 imes 10^{-3}, exclusion rules, and replication protocol (including the 'full power' replication) to allow assessment of robustness; these details are not visible even in the abstract.
- [Derivation of non-monotonicity and discussion of unobserved optimum] The non-monotone optimum is derived for χ > 0 but explicitly stated to be unobserved in data. Because this is the distinctive practical implication (most valuable memories sent off flash), the manuscript should either provide a concrete test or bound the conditions under which the non-monotonicity would appear, rather than leaving it as an open empirical gap.
minor comments (1)
- Notation for the endurance shadow price η and the association χ is introduced without an early consolidated table of symbols; a short notation table would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below. We will expand the empirical details on χ measurement in the revised manuscript. For the non-monotonic optimum, we will add explicit bounds on the conditions for its appearance while acknowledging that a direct empirical test lies outside the current datasets.
read point-by-point responses
-
Referee: [Empirical measurement of χ (abstract and results section)] The empirical pivot on χ (measured at a pre-specified gate on robot logs) is load-bearing for the claim that its sign is a property of the deployment regime and for the conclusion that endurance binds only on low-P/E media. The manuscript must supply the exact gate definition, error bars on the reported χ̂ ≈ +1.0 times 10^{-3}, exclusion rules, and replication protocol (including the 'full power' replication) to allow assessment of robustness; these details are not visible even in the abstract.
Authors: We agree that these methodological details are necessary to evaluate robustness. In the revised manuscript we will add, in the results section (with a cross-reference from the abstract), the precise definition of the pre-specified gate used on the robot logs, the formula and numerical error bars for χ̂, the exclusion criteria applied to log entries, and the complete replication protocol including the full-power replication. These additions will be presented without altering the reported sign or magnitude of χ. revision: yes
-
Referee: [Derivation of non-monotonicity and discussion of unobserved optimum] The non-monotone optimum is derived for χ > 0 but explicitly stated to be unobserved in data. Because this is the distinctive practical implication (most valuable memories sent off flash), the manuscript should either provide a concrete test or bound the conditions under which the non-monotonicity would appear, rather than leaving it as an open empirical gap.
Authors: The model derivation establishes that non-monotonicity arises exclusively when χ > 0. We accept that the current datasets do not exhibit the non-monotone placement regime itself. In revision we will insert an explicit bounding analysis (new subsection) that states the minimum χ magnitude and endurance-budget tightness required for the non-monotone optimum to appear, derived directly from the closed-form threshold condition. A controlled empirical demonstration of the non-monotone regime would require new robot experiments with higher χ or lower-P/E hardware; we will note this as future work rather than claim it is resolved here. revision: partial
Circularity Check
No significant circularity identified
full rationale
The derivation obtains the wear-augmented per-byte index directly from cost minimization across the RAM/NVM/cloud hierarchy once the endurance shadow price η is introduced; the optimality statement for any sign of χ follows mathematically from that construction and does not reduce to a fitted input or self-definition. χ itself is obtained by external measurement on robot logs at a pre-specified gate, not estimated inside the model or renamed as a prediction. No self-citation chain, uniqueness theorem, or ansatz is invoked as load-bearing support. The tier-invariance assumption and the binding/non-binding endurance boundaries are stated empirical scope conditions rather than internal reductions. The central claim therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- η
- χ
axioms (1)
- domain assumption Realized value of a memory is invariant to the storage tier that holds it.
Reference graph
Works this paper leans on
-
[1]
Daniel Adelman and Adam J. Mersereau. Relaxations of weakly coupled stochastic dynamic programs.Operations Research, 56(3):712–727, 2008. doi: 10.1287/opre.1070.0445
-
[2]
Chapman and Hall/CRC, 1999
Eitan Altman.Constrained Markov Decision Processes. Chapman and Hall/CRC, 1999. URL https://www-sop.inria.fr/members/Eitan.Altman/TEMP/h.pdf. 29 Table 5:Run-ID provenance for the main results. Result Run ID(s) Phase-0 value–write gatephase0-full-20260612(GATE-cov) Canonicalχmatrix / re-analysischi-reanalysis-20260612(D-012);W1+W2 battery Phase-1 labeling ...
1999
-
[3]
ReMEmbR: Building and reasoning over long-horizon spatio-temporal memory for robot navigation, 2024
Abrar Anwar, John Welsh, Joydeep Biswas, Soha Pouya, and Yan Chang. ReMEmbR: Building and reasoning over long-horizon spatio-temporal memory for robot navigation, 2024. URL https://arxiv.org/abs/2409.13682
arXiv 2024
-
[4]
The financial guide to calculating the true TCO of a robotic fleet, 2025
Balyo. The financial guide to calculating the true TCO of a robotic fleet, 2025. URL https://www.balyo.com/blog/the-financial-guide-to-calculating-the-true-tco-o f-a-robotic-fleet
2025
-
[5]
A primal-dual randomized algorithm for weighted paging.Journal of the ACM, 59(4), 2012
Nikhil Bansal, Niv Buchbinder, and Joseph (Seffi) Naor. A primal-dual randomized algorithm for weighted paging.Journal of the ACM, 59(4), 2012. doi: 10.1145/2339123.2339126. Preliminary version FOCS 2007
-
[6]
On the promise and pitfalls of optimizing embodied carbon
Noman Bashir, David Irwin, and Prashant Shenoy. On the promise and pitfalls of optimizing embodied carbon. InProc. 2nd Workshop on Sustainable Computer Systems (HotCarbon),
-
[7]
URLhttps://arxiv.org/abs/2306.15816
doi: 10.1145/3604930.3605710. URLhttps://arxiv.org/abs/2306.15816
-
[8]
Laszlo A. Belady. A study of replacement algorithms for a virtual-storage computer.IBM Systems Journal, 5(2):78–101, 1966. doi: 10.1147/sj.52.0078
-
[9]
AEGIS: A backup reflex for physical AI, 2026
Josef Chen. AEGIS: A backup reflex for physical AI, 2026. URLhttps://arxiv.org/abs/26 06.06660
2026
-
[10]
AURA: Action-gated memory for robot policies at constant VRAM, 2026
Josef Chen. AURA: Action-gated memory for robot policies at constant VRAM, 2026. URL https://arxiv.org/abs/2606.02775
Pith/arXiv arXiv 2026
-
[11]
Memory-bound but not bandwidth-limited: The physical AI inference gap in batch-1 LLM decode, 2026
Josef Chen. Memory-bound but not bandwidth-limited: The physical AI inference gap in batch-1 LLM decode, 2026. URL https://arxiv.org/abs/2605.30571 . Batch-1 decode across H100/A100/L40S/L4; L4 reaches 81% of analytic memory floor vs H100 27%
Pith/arXiv arXiv 2026
-
[12]
Peng Chen, Jiaji Zhang, Hailiang Zhao, Yirong Zhang, Shenyao Chen, Jiahong Yu, Xueyan Tang, Yixuan Wang, Hao Li, Jianping Zou, Gang Xiong, Kingsum Chow, Shuibing He, and Shuiguang Deng. Toward robust and efficient ML-based GPU caching for modern inference (lcr/laru).arXiv preprint arXiv:2509.20979, 2025. URLhttps://arxiv.org/abs/2509.20979
Pith/arXiv arXiv 2025
-
[13]
Token economics for LLM agents
Yuxi Chen, Junming Chen, Chenyu He, Yiwei Li, et al. Token economics for LLM agents. arXiv preprint arXiv:2605.09104, 2026. URLhttps://arxiv.org/abs/2605.09104
Pith/arXiv arXiv 2026
-
[14]
Network offloading policies for 30 cloud robotics: A learning-based approach
Sandeep Chinchali, Apoorva Sharma, James Harrison, Amine Elhafsi, Daniel Kang, Evgenya Pergament, Eyal Cidon, Sachin Katti, and Marco Pavone. Network offloading policies for 30 cloud robotics: A learning-based approach. InProceedings of Robotics: Science and Systems (RSS), Freiburg im Breisgau, Germany, 2019. doi: 10.15607/RSS.2019.XV.063. URL https://www...
-
[15]
Server memory prices could double by 2026 as AI demand strains supply, November 2025
Counterpoint Research. Server memory prices could double by 2026 as AI demand strains supply, November 2025. URLhttps://www.networkworld.com/article/4093752/serve r-memory-prices-could-double-by-2026-as-ai-demand-strains-supply.html . Via Network World; 32GB DDR5 module $149 to $239; server DDR5 $1.50/Gb
arXiv 2026
-
[16]
Flashield: a hybrid key-value cache that controls flash write amplification
Assaf Eisenman, Asaf Cidon, Evgenya Pergament, Or Haimovich, Ryan Stutsman, Mohammad Alizadeh, and Sachin Katti. Flashield: a hybrid key-value cache that controls flash write amplification. In16th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’19), pages 65–78. USENIX Association, 2019. URLhttps://www.usenix.org/confe rence/nsdi19/...
2019
-
[17]
NAND flash prices are surging in 2026: +33–38% q1, +70–75% q2, April 2026
Elinfor (relaying TrendForce). NAND flash prices are surging in 2026: +33–38% q1, +70–75% q2, April 2026. URLhttps://www.elinfor.com/knowledge/nand-flash-prices-are-sur ging-in-2026-what-it-means-for-your-supply-chain-and-how-to-prepare-p-11312
2026
-
[18]
B200 cost breakdown, 2024
Epoch AI. B200 cost breakdown, 2024. URLhttps://epoch.ai/data-insights/b200-cos t-breakdown. HBM3E component cost $14–17/GB on 192 GB B200
2024
-
[19]
Regulation (eu) 2024/1781 establishing a framework for the setting of ecodesign requirements for sustainable products (espr) and the digital product passport, 2024
European Parliament and Council. Regulation (eu) 2024/1781 establishing a framework for the setting of ecodesign requirements for sustainable products (espr) and the digital product passport, 2024. URL https://data.europa.eu/en/news-events/news/eus-digital -product-passport-advancing-transparency-and-sustainability . In force 18 Jul 2024; product-specific...
2024
-
[20]
Directive (eu) 2024/1799 on common rules promoting the repair of goods (right-to-repair directive), 2024
European Parliament and Council. Directive (eu) 2024/1799 on common rules promoting the repair of goods (right-to-repair directive), 2024. URLhttps://commission.europa.eu/law/l aw-topic/consumer-protection-law/directive-repair-goods_en. Adopted 13 Jun 2024; in force 30 Jul 2024; transposition by 31 Jul 2026; servers and data-storage products in Annex II
2024
-
[21]
John C. Gittins. Bandit processes and dynamic allocation indices.Journal of the Royal Statistical Society, Series B, 41(2):148–164, 1979. doi: 10.1111/j.2517-6161.1979.tb01068.x
-
[22]
Wise, Alberto Speranzon, and Luca Carlone
Nicolas Gorlo, Derek K. Wise, Alberto Speranzon, and Luca Carlone. Worth remembering: Surprise-gated robot episodic memory, 2026. URLhttps://arxiv.org/abs/2606.03787
Pith/arXiv arXiv 2026
-
[23]
Lee, David Brooks, and Carole-Jean Wu
Udit Gupta, Mariam Elgamal, Gage Hills, Gu-Yeon Wei, Hsien-Hsin S. Lee, David Brooks, and Carole-Jean Wu. ACT: Designing sustainable computer systems with an architectural carbon modeling tool. InProc. 49th Annual Int. Symp. Computer Architecture (ISCA), 2022. doi: 10.1145/3470496.3527408. URLhttps://ugupta.com/files/Gupta_ISCA2022_ACT.pdf
-
[24]
Hall and Dale W
Robert E. Hall and Dale W. Jorgenson. Tax policy and investment behavior.American Economic Review, 57(3):391–414, 1967. URLhttp://piketty.pse.ens.fr/files/HallJor genson67.pdf
1967
-
[25]
The economics of exhaustible resources.Journal of Political Economy, 39(2): 137–175, 1931
Harold Hotelling. The economics of exhaustible resources.Journal of Political Economy, 39(2): 137–175, 1931. doi: 10.1086/254195. 31
-
[26]
Rotman, P
Nathan Jay, Noga H. Rotman, P. Brighten Godfrey, Michael Schapira, and Aviv Tamar. A deep reinforcement learning perspective on internet congestion control. InProceedings of the 36th International Conference on Machine Learning (ICML), pages 3050–3059, 2019. URL http://proceedings.mlr.press/v97/jay19a/jay19a.pdf
2019
-
[27]
Jorgenson
Dale W. Jorgenson. The theory of investment behavior. In Robert Ferber, editor,Determinants of Investment Behavior, pages 129–175. National Bureau of Economic Research (Columbia Univ. Press), 1967. URLhttps://www.nber.org/system/files/chapters/c1235/c1235.pdf
1967
-
[28]
Yiping Kang, Johann Hauswald, Cao Gao, Austin Rovinski, Trevor Mudge, Jason Mars, and Lingjia Tang. Neurosurgeon: Collaborative intelligence between the cloud and mobile edge.ACM SIGARCH Computer Architecture News (ASPLOS ’17), 45(1):615–629, 2017. doi: 10.1145/3093337.3037698. URLhttps://dl.acm.org/doi/10.1145/3093337.3037698
-
[29]
DROID: A large-scale in-the-wild robot manipulation dataset, 2024
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, et al. DROID: A large-scale in-the-wild robot manipulation dataset, 2024. URL https://arxiv.org/abs/2403.12945
Pith/arXiv arXiv 2024
-
[30]
Edge computing and GDPR: A technical security and legal compliance analysis
Jonathan Kilit and Joel Bobin Blychert. Edge computing and GDPR: A technical security and legal compliance analysis. Bachelor’s thesis, Jönköping University, School of Engineering, 2025. URL https://www.diva-portal.org/smash/get/diva2:1982107/FULLTEXT01.pdf. GDPR Arts. 5, 25, 32, 44, 48; edge processing for data residency and the GDPR vs. US CLOUD Act conflict
2025
-
[31]
OpenVLA: An open-source vision-language-action model, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. OpenVLA: An open-source vision-language-action model, 2024. URLhttps: //arxiv.org/abs/2...
Pith/arXiv arXiv 2024
-
[32]
Understanding TBW versus P/E cycles in managed flash memory
KIOXIA. Understanding TBW versus P/E cycles in managed flash memory. KIOXIA technical brief, 2023. URL https://americas.kioxia.com/content/dam/kioxia/en-us/business/m emory/mlc-nand/asset/KIOXIA-TBW-vs-PE-Cycles-Tech-Brief.pdf . P/E endurance for SLC/MLC/TLC; eMMC/UFS rated in P/E cycles
2023
-
[33]
Managed-retention memory: A new class of memory for the ai era.arXiv preprint arXiv:2501.09605, 2025
Sergey Legtchenko, Ioan Stefanovici, Richard Black, Antony Rowstron, Junyi Liu, Paolo Costa, Burcu Canakci, Dushyanth Narayanan, and Xingbo Wu. Managed-retention memory: A new class of memory for the ai era.arXiv preprint arXiv:2501.09605, 2025. URL https: //arxiv.org/abs/2501.09605
arXiv 2025
-
[34]
LIBERO: Benchmarking knowledge transfer for lifelong robot learning, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning, 2023. URLhttps: //arxiv.org/abs/2306.03310
Pith/arXiv arXiv 2023
-
[35]
Liu, Milad Hashemi, Kevin Swersky, Parthasarathy Ranganathan, and Junwhan Ahn
Evan Z. Liu, Milad Hashemi, Kevin Swersky, Parthasarathy Ranganathan, and Junwhan Ahn. An imitation learning approach for cache replacement. InProceedings of the 37th International Conference on Machine Learning (ICML), pages 6237–6247, 2020. URLhttps: //proceedings.mlr.press/v119/liu20f.html
2020
-
[36]
Guangzhou Liu, Zhen Qian, and Guanghui Li. Proactive retention-aware online video caching scheme in mobile edge computing (dpro).Computer Communications, 239:108313, 2025. doi: 32 10.1016/j.comcom.2025.108313. URL https://www.sciencedirect.com/science/article/ abs/pii/S0140366425002701
-
[37]
Resource man- agement with deep reinforcement learning
Hongzi Mao, Mohammad Alizadeh, Ishai Menache, and Srikanth Kandula. Resource man- agement with deep reinforcement learning. InProceedings of the 15th ACM Workshop on Hot Topics in Networks (HotNets), pages 50–56, 2016. doi: 10.1145/3005745.3005750. URL https://people.csail.mit.edu/alizadeh/papers/deeprm-hotnets16.pdf
-
[38]
Yoshitomo Matsubara, Marco Levorato, and Francesco Restuccia. Split computing and early exiting for deep learning applications: Survey and research challenges.ACM Computing Surveys, 55(5):1–30, 2022. doi: 10.1145/3527155. URLhttps://arxiv.org/abs/2103.04505
-
[39]
Berger, Nathan Beckmann, and Gregory R
Sara McAllister, Benjamin Berg, Julian Tutuncu-Macias, Juncheng Yang, Sathya Gunasekar, Jimmy Lu, Daniel S. Berger, Nathan Beckmann, and Gregory R. Ganger. Kangaroo: Caching billions of tiny objects on flash. InProceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles (SOSP ’21), pages 243–262, 2021. doi: 10.1145/3477132.3483568. URLhtt...
-
[40]
Le, Benoit Steiner, Rasmus Larsen, Yuefeng Zhou, Naveen Kumar, Mohammad Norouzi, Samy Bengio, and Jeff Dean
Azalia Mirhoseini, Hieu Pham, Quoc V. Le, Benoit Steiner, Rasmus Larsen, Yuefeng Zhou, Naveen Kumar, Mohammad Norouzi, Samy Bengio, and Jeff Dean. Device placement opti- mization with reinforcement learning. InProceedings of the 34th International Conference on Machine Learning (ICML), pages 2430–2439, 2017. URLhttps://proceedings.mlr.press/ v70/mirhosein...
2017
-
[41]
SSD endurance and NAND types explained for 2026: TLC, QLC and more
Newegg Insider. SSD endurance and NAND types explained for 2026: TLC, QLC and more. Newegg Insider, 2026. URL https://www.newegg.com/insider/ssd-lifespan-decod ed-understanding-nand-types-and-write-endurance-in-2026/ . Quality TLC NVMe: 1,500–3,000 P/E; 1 TB TLC = 300–1,200 TBW
2026
-
[42]
NVIDIA Jetson AGX Orin series technical brief
NVIDIA. NVIDIA Jetson AGX Orin series technical brief. NVIDIA technical brief, 2022. URL https://www.nvidia.com/content/dam/en-zz/Solutions/gtcf21/jetson-orin/nvidia -jetson-agx-orin-technical-brief.pdf. 64 GB 256-bit LPDDR5, 204.8 GB/s; 15–60 W; up to 275 TOPS INT8
2022
-
[43]
Introducing NVIDIA Jetson Thor, the ultimate platform for physical AI
NVIDIA. Introducing NVIDIA Jetson Thor, the ultimate platform for physical AI. NVIDIA Developer Blog, 2025. URLhttps://developer.nvidia.com/blog/introducing-nvidia-j etson-thor-the-ultimate-platform-for-physical-ai/ . Jetson AGX Thor / T5000: 128 GB 256-bit LPDDR5X, 273 GB/s, 40–130 W, up to 2070 FP4 TFLOPS
2025
-
[44]
Yasmine Omri, Ziyu Gan, Zachary Broveak, Robin Geens, Zexue He, Alex Pentland, Marian Verhelst, Tsachy Weissman, and Thierry Tambe. Agent memory: Characterization and system implications of stateful long-horizon workloads.arXiv preprint arXiv:2606.06448, 2026. URL https://arxiv.org/abs/2606.06448
Pith/arXiv arXiv 2026
-
[45]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems, 2023. URLhttps: //arxiv.org/abs/2310.08560
Pith/arXiv arXiv 2023
-
[46]
Chitral Patil. Beyond per-token pricing: A concurrency-aware methodology for LLM infras- tructure cost estimation, 2026. URLhttps://arxiv.org/abs/2606.11690. Underutilization penalty 2.5–24x (1–10 rps), up to 36.3x near idle; cost off by exactly 1/U. 33
Pith/arXiv arXiv 2026
-
[47]
Thibault Pirson and David Bol. Assessing the embodied carbon footprint of IoT edge devices with a bottom-up life-cycle approach.Journal of Cleaner Production, 2021. doi: 10.1016/j.jcle pro.2021.128966. URLhttps://arxiv.org/abs/2105.02082
-
[48]
What is QLC SSD
Pure Storage. What is QLC SSD. Pure Storage knowledge base, 2025. URLhttps://www. everpuredata.com/knowledge/what-is-qlc-flash.html . QLC 1,000 P/E cycles; SLC 100,000 P/E cycles
2025
-
[49]
FrozenHot cache: Rethinking cache management for modern hardware
Ziyue Qiao, Xiaocheng Wu, Yiding Zhang, Yang Gao, Yuhao Zhou, Juncheng Yang, et al. FrozenHot cache: Rethinking cache management for modern hardware. InProceedings of the 18th European Conference on Computer Systems (EuroSys), 2023. doi: 10.1145/3552326.3587446. URLhttps://www.pdl.cmu.edu/ftp/Storage/FrozenHot-Eurosys23.pdf
-
[51]
URLhttps://arxiv.org/abs/2401.00448
-
[52]
Life-cycle emissions of AI hardware: A cradle-to-grave approach and generational trends, 2025
Ian Schneider, Hui Xu, Stephan Benecke, David Patterson, Keguo Huang, Parthasarathy Ranganathan, and Cooper Elsworth. Life-cycle emissions of AI hardware: A cradle-to-grave approach and generational trends, 2025. URLhttps://arxiv.org/abs/2502.01671
arXiv 2025
-
[53]
SmolVLA: A vision-language-action model for affordable and efficient robotics, 2025
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, Simon Alibert, Matthieu Cord, Thomas Wolf, and Remi Cadene. SmolVLA: A vision-language-action model for affordable and efficient robotics, 2025. URLhttps://arxiv.org/abs/2506.01844
Pith/arXiv arXiv 2025
-
[54]
Berger, Kai Li, and Wyatt Lloyd
Zhenyu Song, Daniel S. Berger, Kai Li, and Wyatt Lloyd. Learning relaxed Belady for content distribution network caching. In17th USENIX Symposium on Networked Systems Design and Implementation (NSDI), pages 529–544, 2020. URLhttps://www.usenix.org/system/file s/nsdi20-paper-song.pdf
2020
-
[55]
MemER: Scaling up memory for robot control via experience retrieval, 2025
Ajay Sridhar, Jennifer Pan, Satvik Sharma, and Chelsea Finn. MemER: Scaling up memory for robot control via experience retrieval, 2025. URLhttps://arxiv.org/abs/2510.20328
arXiv 2025
-
[56]
Junkyard computing: Repurposing discarded smartphones to minimize carbon
Jennifer Switzer, Gabriel Marcano, Ryan Kastner, and Pat Pannuto. Junkyard computing: Repurposing discarded smartphones to minimize carbon. InProc. 28th ACM Int. Conf. Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2023. doi: 10.48550/arXiv.2110.06870. URLhttps://arxiv.org/abs/2110.06870
-
[57]
TrendForce. Higher DDR5 profitability intensifies capacity crowding; HBM3e–DDR5 asp gap to narrow from 4–5x to 1–2x by end-2026, December 2025. URLhttps://www.trendforce.c om/presscenter/news/20251218-12843.html
arXiv 2026
-
[58]
Efficient ssd caching by avoiding unnecessary writes using machine learning
Hua Wang, Xinbo Yi, Ping Huang, Bin Cheng, and Ke Zhou. Efficient ssd caching by avoiding unnecessary writes using machine learning. InProceedings of the 47th International Conference on Parallel Processing / ACM, 2018. doi: 10.1145/3225058.3225126. URL https://dl.acm.org/doi/10.1145/3225058.3225126
-
[59]
KARMA: Augmenting embodied AI agents with long-and-short term memory systems, 2024
Zixuan Wang, Bo Yu, Junzhe Zhao, Wenhao Sun, Sai Hou, Shuai Liang, Xing Hu, Yinhe Han, and Yiming Gan. KARMA: Augmenting embodied AI agents with long-and-short term memory systems, 2024. URLhttps://arxiv.org/abs/2409.14908. 34
arXiv 2024
-
[60]
Embodied carbon footprint of 3D NAND memories
Olivier Weppe, Thibaut Marty, Sylvain Toussaint, Nicolas Brusselmans, Jean-Christophe Prévotet, Jean-Pierre Raskin, and Maxime Pelcat. Embodied carbon footprint of 3D NAND memories. InProceedings of the 22nd ACM International Conference on Computing Frontiers: Workshops and Special Sessions (CF ’25 Companion), 2025. doi: 10.1145/3706594.3727962. URL https...
-
[61]
Western Digital industrial flash storage portfolio (industrial e.mmc/ufs/ssd)
Western Digital. Western Digital industrial flash storage portfolio (industrial e.mmc/ufs/ssd). Product portfolio brochure, 2023. URLhttps://www.marubun.co.jp/wp-content/uploads /a7ijkd000000dgaz/a7ijkd000000m6x1.pdf. Industrial 3D-NAND: 3K P/E high-endurance grade; up to 1,600 TBW
2023
-
[62]
Peter Whittle. Restless bandits: Activity allocation in a changing world.Journal of Applied Probability, 25A:287–298, 1988. doi: 10.2307/3214163
-
[63]
Berger, Nathan Beckmann, and Gregory R
Daniel Lin-Kit Wong, Hao Wu, Carson Molder, Sathya Gunasekar, Jimmy Lu, Snehal Khandkar, Abhinav Sharma, Daniel S. Berger, Nathan Beckmann, and Gregory R. Ganger. Baleen: ML admission & prefetching for flash caches. In22nd USENIX Conference on File and Storage Technologies (FAST), 2024. URLhttps://www.usenix.org/conference/fast24/presentat ion/wong
2024
-
[64]
Tzu-Wei Yang, Seth Pollen, Mustafa Uysal, Arif Merchant, Homer Wolfmeister, and Junaid Khalid. Cachesack: Theory and experience of google’s admission optimization for datacenter flash caches.ACM Transactions on Storage, 19(2):1–24, 2023. doi: 10.1145/3582014. URL https://dl.acm.org/doi/10.1145/3582014
-
[65]
Nemo: A low-write-amplification cache for tiny objects on log-structured flash devices
Xufeng Yang, Tingting Tan, Jing Hu, Congming Gao, Mingyan Liu, Tianyang Jiang, Jian Chen, Linbo Long, Yina Lv, and Jiwu Shu. Nemo: A low-write-amplification cache for tiny objects on log-structured flash devices. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’26), Vo...
-
[66]
A machine learning based write policy for ssd cache in cloud block storage
Ji Zhang, Ke Zhou, et al. A machine learning based write policy for ssd cache in cloud block storage. InDesign, Automation & Test in Europe Conference (DATE), pages 82–87, 2020. URLhttps://past.date-conference.com/proceedings-archive/2020/pdf/0022.pdf
2020
-
[67]
Siqi Zhu. Agentic AI systems should be designed as marginal token allocators.arXiv preprint arXiv:2605.01214, 2026. URLhttps://arxiv.org/abs/2605.01214. 35
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.