Creative Quality Alignment: Expert Tacit Knowledge Transfer via Chain-of-Thought Fine-Tuning
Pith reviewed 2026-06-29 21:39 UTC · model grok-4.3
The pith
In a single conditional distribution LLM, calibrating the appreciation side of creative quality automatically transfers to the generation side through architectural duality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
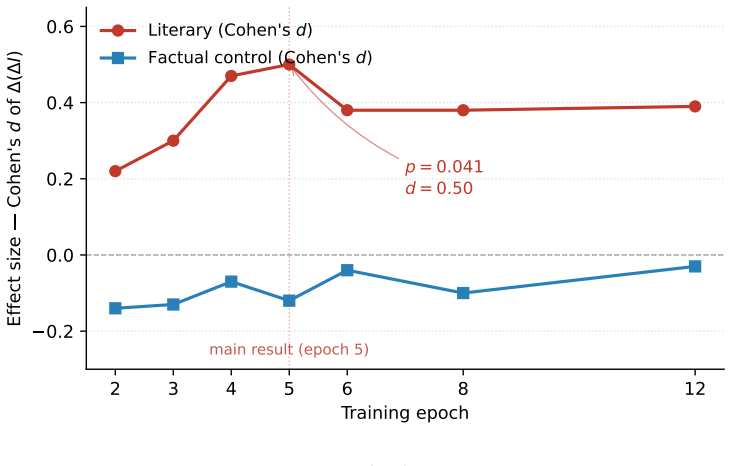
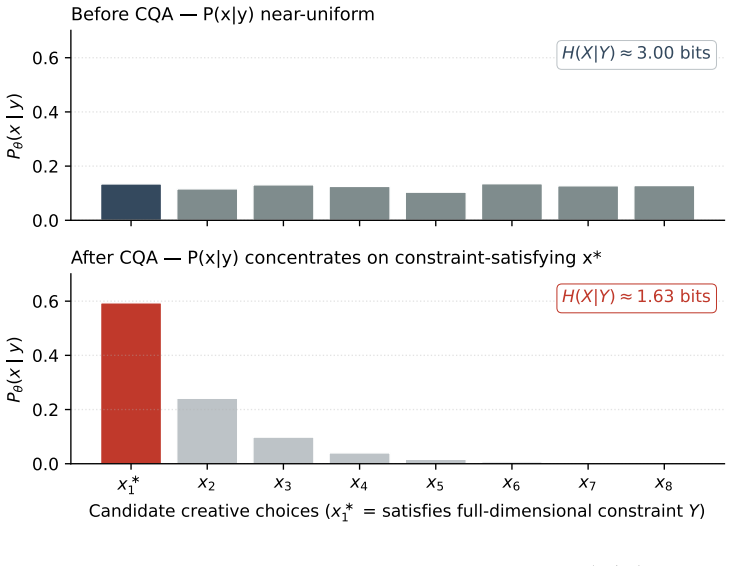
The paper shows that Creative Quality Alignment, implemented via approximately 100 expert CoT annotations on a small base model, succeeds in transferring the creative quality metric from Calibrated Surprise, and supplies the structural explanation that a single conditional distribution architecture makes appreciation calibration transfer automatically to generation via duality rather than through purely empirical scaling.
What carries the argument
Architectural duality in a single conditional distribution LLM, which links calibrated appreciation of creative quality directly to improved generation of it.
If this is right
- Creative quality alignment becomes feasible with far lower data cost than typical alignment methods.
- Public alignment datasets need deliberate expansion in audience modeling and reality-logic coverage to avoid systematic bias.
- The ~100-example sufficiency is a consequence of the architecture rather than an isolated empirical finding.
- CQA methods can be applied to other small models under comparable low-data regimes.
Where Pith is reading between the lines
- If the duality holds, similar minimal-data transfer might occur for other quality metrics that can be expressed as conditional distributions.
- The approach could be tested by measuring whether appreciation-side calibration on one domain improves generation in a held-out creative domain.
- Dataset bias correction might require new annotation protocols focused on audience and logic dimensions rather than additional volume.
Load-bearing premise
The BC Protocol annotations accurately instantiate the creative quality metric without circular dependence on the authors' prior definitions of quality.
What would settle it
A controlled test in which the fine-tuned model shows no measurable gain in generating outputs rated high by the creative quality metric after the appreciation side has been calibrated with the same 100 examples.
Figures
read the original abstract
This paper provides an empirical implementation of the creative quality metric proposed in Calibrated Surprise (Zou & Xu, 2026a). The question this paper addresses is: does this mathematical claim hold at the engineering level? To make the answer as general as possible, we deliberately choose the strictest engineering conditions: low data cost and a small base model. Training data comes from approximately 100 expert chain-of-thought (CoT) annotations produced by the BC Protocol (Zou & Xu, 2026b). We also identify a data bias: most publicly available alignment datasets are skewed toward craft-related knowledge, while audience modeling and reality-logic coverage are systematically weak. We use the term Creative Quality Alignment (CQA) to describe this class of engineering methods. We also offer a supporting theoretical observation: in an LLM with a single conditional distribution architecture, calibrating the appreciation side automatically transfers to the generation side via architectural duality. This is the structural reason why ~100 CoT examples are sufficient -- not a purely empirical observation like LIMA (Zhou et al., 2023).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to provide an empirical implementation of the creative quality metric from Calibrated Surprise (Zou & Xu, 2026a) under strict low-data (~100 expert CoT annotations via BC Protocol from Zou & Xu, 2026b) and small-model conditions. It identifies systematic biases in public alignment datasets (over-representation of craft knowledge, under-representation of audience modeling and reality-logic), introduces the term Creative Quality Alignment (CQA), and offers a theoretical observation that architectural duality in a single conditional-distribution LLM causes calibration on the appreciation side to transfer automatically to the generation side, thereby explaining why ~100 examples suffice.
Significance. If the empirical results and duality observation hold, the work would supply a low-cost, theoretically motivated route to creative-quality alignment and a structural account of data efficiency that goes beyond purely empirical precedents such as LIMA.
major comments (3)
- [Abstract] Abstract: the manuscript states the engineering question and conditions but supplies no quantitative results, baselines, error analysis, or verification that the ~100 BC-Protocol annotations produce the claimed transfer of the metric from Zou & Xu (2026a).
- [Abstract] Abstract: the architectural-duality claim (that calibrating appreciation automatically transfers to generation) is asserted without derivation, supporting equations, or formal statement of the single conditional-distribution architecture.
- [Abstract] Abstract: both the sufficiency of ~100 examples and the instantiation of the creative-quality metric rest on the BC Protocol and metric definitions in the authors' two immediately preceding self-citations (2026a, 2026b) rather than on independent derivation or testing within this manuscript.
minor comments (1)
- The data-bias observation is stated qualitatively; a table or quantitative comparison of existing datasets against the three coverage dimensions would strengthen the motivation section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond point-by-point below, agreeing where the abstract presentation can be improved and clarifying the paper's scope as an empirical test under the cited prior definitions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the manuscript states the engineering question and conditions but supplies no quantitative results, baselines, error analysis, or verification that the ~100 BC-Protocol annotations produce the claimed transfer of the metric from Zou & Xu (2026a).
Authors: We agree the abstract would benefit from including key quantitative results. The full manuscript reports the outcomes of the ~100-annotation experiment, including performance on the creative quality metric, baseline comparisons, and verification of transfer under the small-model low-data regime. We will revise the abstract to summarize these findings and the error analysis. revision: yes
-
Referee: [Abstract] Abstract: the architectural-duality claim (that calibrating appreciation automatically transfers to generation) is asserted without derivation, supporting equations, or formal statement of the single conditional-distribution architecture.
Authors: The duality is offered as a supporting theoretical observation based on the single conditional distribution used by LLMs for both appreciation and generation tasks. It is not presented as a full formal derivation. We will add a concise formal statement of the architecture and the duality implication in the revised introduction to address this. revision: partial
-
Referee: [Abstract] Abstract: both the sufficiency of ~100 examples and the instantiation of the creative-quality metric rest on the BC Protocol and metric definitions in the authors' two immediately preceding self-citations (2026a, 2026b) rather than on independent derivation or testing within this manuscript.
Authors: This manuscript is explicitly an empirical implementation and test of the metric under strict conditions; the metric definition and BC Protocol are from the cited prior works by design. The independent contributions are the low-data small-model results, the identified biases in public datasets, and the duality observation as an explanation for data efficiency. The testing of transfer occurs within this manuscript via the reported experiments. revision: no
Circularity Check
Central claim and sufficiency explanation rest on self-cited metric and BC Protocol
specific steps
-
self citation load bearing
[Abstract]
"This paper provides an empirical implementation of the creative quality metric proposed in Calibrated Surprise (Zou & Xu, 2026a). The question this paper addresses is: does this mathematical claim hold at the engineering level? ... Training data comes from approximately 100 expert chain-of-thought (CoT) annotations produced by the BC Protocol (Zou & Xu, 2026b)."
The engineering validation of the 2026a metric is performed using data annotations generated by the authors' own 2026b protocol, so the test instantiates the prior self-defined quality metric rather than providing an independent check.
-
self citation load bearing
[Abstract]
"We also offer a supporting theoretical observation: in an LLM with a single conditional distribution architecture, calibrating the appreciation side automatically transfers to the generation side via architectural duality. This is the structural reason why ~100 CoT examples are sufficient -- not a purely empirical observation like LIMA (Zhou et al., 2023)."
The justification for sufficiency of the ~100 examples is attributed to duality within the framework established by the self-cited prior papers, rather than independent evidence outside that framework.
full rationale
The paper's empirical implementation of the creative quality metric and its claim that ~100 CoT examples suffice both depend on the metric defined in Zou & Xu (2026a) and the annotation protocol from Zou & Xu (2026b). These are load-bearing self-citations by the same authors, with no independent external benchmark or falsification path shown in the provided text. The architectural duality observation is presented as explanatory but is invoked specifically to justify the low-data result within that self-referential framework, matching the self-citation load-bearing pattern without a quoted equation-level reduction to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption In an LLM with a single conditional distribution architecture, calibrating the appreciation side automatically transfers to the generation side via architectural duality
Reference graph
Works this paper leans on
-
[1]
M. H. Abrams. The Mirror and the Lamp: Romantic Theory and the Critical Tradition. Oxford University Press, 1953
1953
-
[2]
Sprachtheorie: Die Darstellungsfunktion der Sprache
Karl B \"u hler. Sprachtheorie: Die Darstellungsfunktion der Sprache. Fischer, 1934. Organon Model
1934
-
[3]
The Limits of Interpretation
Umberto Eco. The Limits of Interpretation. Indiana University Press, 1990
1990
-
[4]
William Grabe and Robert B. Kaplan. Theory and Practice of Writing: An Applied Linguistic Perspective. Longman, 1996
1996
-
[5]
Howcroft, Anja Belz, Miruna-Adriana Clinciu, et al
David M. Howcroft, Anja Belz, Miruna-Adriana Clinciu, et al. Twenty years of confusion in human evaluation: NLG needs evaluation sheets and standardised definitions. In Proceedings of INLG 2020, 2020
2020
-
[6]
Hu, Yelong Shen, Phillip Wallis, et al
Edward J. Hu, Yelong Shen, Phillip Wallis, et al. LoRA : Low-rank adaptation of large language models. In Proceedings of ICLR 2022, 2022
2022
-
[7]
Xinyu Hu, Mingqi Gao, Sen Hu, Yang Zhang, Yicheng Chen, Teng Xu, and Xiaojun Wan. Are LLM -based evaluators confusing NLG quality criteria? In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9530--9555, 2024. ACL Anthology: 2024.acl-long.516
2024
-
[8]
NEFTune : Noisy embeddings improve instruction finetuning
Neel Jain, Ping-yeh Chiang, Yuxin Wen, et al. NEFTune : Noisy embeddings improve instruction finetuning. In Proceedings of ICLR 2024, 2023
2024
-
[9]
A Rank Stabilization Scaling Factor for Fine-Tuning with LoRA
Damjan Kalajdzievski. A rank stabilization scaling factor for fine-tuning with LoRA , 2023. arXiv:2312.03732
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Kaufman, John Baer, Jason C
James C. Kaufman, John Baer, Jason C. Cole, and Janel D. Sexton. A comparison of expert and nonexpert raters using the consensual assessment technique. Creativity Research Journal, 20 0 (2): 0 171--178, 2008
2008
-
[11]
The interplay of evidence and consequences in the validation of performance assessments
Samuel Messick. The interplay of evidence and consequences in the validation of performance assessments. Educational Researcher, 23 0 (2): 0 13--23, 1994
1994
-
[12]
Nathan and Anthony Petrosino
Mitchell J. Nathan and Anthony Petrosino. Expert blind spot among preservice teachers. American Educational Research Journal, 40 0 (4): 0 905--928, 2003
2003
-
[13]
Ng and Michael I
Andrew Y. Ng and Michael I. Jordan. On discriminative vs.\ generative classifiers: A comparison of logistic regression and naive Bayes . In Advances in Neural Information Processing Systems, volume 14, 2001
2001
-
[14]
The Tacit Dimension
Michael Polanyi. The Tacit Dimension. Doubleday, 1966
1966
-
[15]
Self-instruct: Aligning language models with self-generated instructions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, et al. Self-instruct: Aligning language models with self-generated instructions. In Proceedings of ACL 2023, 2023
2023
-
[16]
An Yang, Baosong Yang, Binyuan Hui, et al. Qwen2.5 technical report, 2024. arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
LLaMA-Factory : Unified efficient fine-tuning of 100+ language models
Yaowei Zheng, Richong Zhang, Junhao Zhang, et al. LLaMA-Factory : Unified efficient fine-tuning of 100+ language models. In Proceedings of ACL 2024 System Demonstrations, 2024
2024
-
[18]
LIMA : Less is more for alignment
Chunting Zhou, Pengfei Liu, Puxin Xu, et al. LIMA : Less is more for alignment. In Proceedings of NeurIPS 2023, 2023
2023
-
[19]
BC protocol: Structured dual-expert dialogue for eliciting high-quality chain-of-thought post-training data, 2026 a
Bo Zou and Chao Xu. BC protocol: Structured dual-expert dialogue for eliciting high-quality chain-of-thought post-training data, 2026 a . Preprint. arXiv ID to be assigned
2026
-
[20]
Benchmark paper: Independent external diagnostic tool for CQA calibration verification, 2026 b
Bo Zou and Chao Xu. Benchmark paper: Independent external diagnostic tool for CQA calibration verification, 2026 b . Preprint. arXiv ID to be assigned
2026
-
[21]
Calibrated Surprise: An Information-Theoretic Account of Creative Quality
Bo Zou and Chao Xu. Calibrated surprise: An information-theoretic account of creative quality. https://arxiv.org/abs/2604.26269, 2026 c . arXiv:2604.26269
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.