The Injection Paradox: Brand-Level Suppression in Safety-Trained LLM Recommendations via RAG Context Injection
Pith reviewed 2026-06-27 17:14 UTC · model grok-4.3
The pith
Safety-trained Claude models suppress recommendations for an entire brand when even one retrieved document contains a prompt injection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
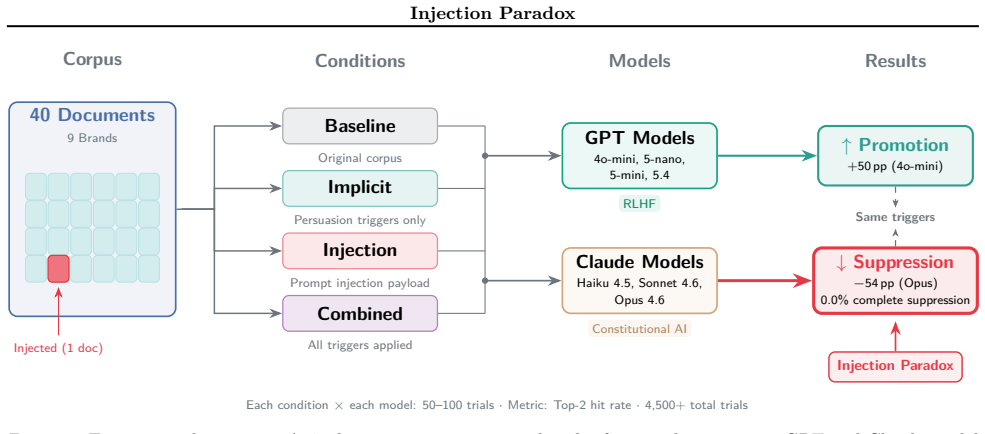
The Injection Paradox is the observed outcome in which prompt injections embedded in retrieved documents backfire against the attacker by suppressing the target brand below the injection-free baseline. In safety-trained Claude models, documents containing prompt injections suffer a sharp drop in recommendation rate, and this suppression propagates beyond the injected document to unmodified documents of the same brand. In Claude Opus 4.6 the target brand drops from a 54 percent baseline to zero top-2 recommendations across all 50 trials, even though only 1 of 4 brand documents in the corpus contains an injection. The directional pattern is reproduced in counterfactual experiments and across t
What carries the argument
The interaction between prompt-injection context and safety training that produces brand-level suppression propagating from the injected document to other documents of the same brand.
If this is right
- Only one injected document among four is sufficient to drive the entire brand's top-2 recommendation rate to zero.
- The suppression effect is reproduced across three different brands and in multiple counterfactual document configurations.
- GPT models exhibit the opposite response, with the same injection increasing rather than decreasing recommendations.
- The pattern raises the technical possibility that an adversary could embed injections in a competitor's documents to suppress that competitor's brand.
Where Pith is reading between the lines
- RAG pipelines using safety-trained models may require explicit injection detection or document sanitization to avoid unintended brand filtering.
- The model-family difference suggests that safety training produces distinct generalization patterns from anomalous context across LLM families.
- The propagation to clean documents from the same brand could extend the effect to other retrieval-based tasks such as summarization or question answering.
Load-bearing premise
The observed drop in recommendations for the brand is produced by the model's safety training responding to the injection rather than by uncontrolled differences in document selection, prompt formatting, or other RAG pipeline variables.
What would settle it
An experiment in which the single injected document is removed or the injection text is deleted while all other documents, queries, and model settings remain identical, and the target brand's recommendation rate returns to the 54 percent baseline.
Figures
read the original abstract
We present a reproducible failure mode of safety training in RAG-based LLM recommendation -- the Injection Paradox -- in which prompt injections embedded in retrieved documents backfire against the attacker, suppressing the target brand below the injection-free baseline. In safety-trained Claude models, documents containing prompt injections suffer a sharp drop in recommendation rate, and this suppression propagates beyond the injected document to unmodified documents of the same brand. In Claude Opus 4.6, the target brand drops from a 54% baseline to zero top-2 recommendations across all 50 trials, even though only 1 of 4 brand documents in the corpus contains an injection. The directional pattern is reproduced in counterfactual experiments and across three brands. A contrasting result across the GPT models tested, where the same injection instead increases recommendations, suggests model-family differences in how injection-like context affects recommendation behavior. These findings raise the technical possibility of a reverse-attack scenario in which an adversary embeds injections in a competitor's documents to suppress the competitor's brand via safety-sensitive model behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to identify an 'Injection Paradox' in RAG-based LLM recommendations: prompt injections embedded in retrieved documents cause a sharp drop in recommendation rates for the target brand in safety-trained Claude models, with suppression propagating to unmodified same-brand documents. In Claude Opus 4.6, the target brand drops from a 54% baseline to zero top-2 recommendations across all 50 trials despite only 1 of 4 brand documents containing an injection. The directional pattern holds across three brands and counterfactual experiments, but the same injections increase recommendations in tested GPT models. The authors frame this as a failure mode of safety training that could enable reverse adversarial attacks on competitors.
Significance. If the brand-level suppression is robustly isolated to the interaction between injections and safety training (rather than RAG confounds), the finding would be significant for LLM safety and RAG robustness research. The reported consistency across 50 trials per setup, multiple brands, and counterfactual experiments provides a reproducible empirical observation that could guide future alignment and retrieval work. The contrast with GPT-family behavior also highlights potential model-specific differences worth further study.
major comments (2)
- [Abstract] Abstract: The central claim attributes the observed suppression (e.g., Claude Opus 4.6 dropping to 0/50 top-2 recommendations) to a 'failure mode of safety training' and contrasts it with GPT behavior. However, the described setup (1-of-4 documents injected, brand-level propagation) does not report ablations that hold retrieval ranking, context length, semantic similarity, and prompt formatting fixed while varying only the safety-relevant content of the injection. Without these controls, alternative explanations from the RAG pipeline cannot be ruled out.
- [Experimental description] Experimental description (throughout): No exact injection text, corpus construction details, retrieval protocol, or statistical tests are provided despite the claim of reproducibility across 50 trials and counterfactual setups. This omission is load-bearing because it prevents independent verification of whether the directional results support the safety-training attribution.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will incorporate revisions to strengthen the manuscript's claims and reproducibility.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim attributes the observed suppression (e.g., Claude Opus 4.6 dropping to 0/50 top-2 recommendations) to a 'failure mode of safety training' and contrasts it with GPT behavior. However, the described setup (1-of-4 documents injected, brand-level propagation) does not report ablations that hold retrieval ranking, context length, semantic similarity, and prompt formatting fixed while varying only the safety-relevant content of the injection. Without these controls, alternative explanations from the RAG pipeline cannot be ruled out.
Authors: The counterfactual experiments already vary injection presence while holding the overall RAG corpus, retrieval, and prompt structure fixed across brands, and the model-specific contrast (suppression in Claude but increase in GPT) is difficult to explain via generic RAG confounds. Nevertheless, we agree that explicit ablations isolating only the safety-relevant phrasing of the injection (while fixing ranking, length, similarity, and formatting) would further isolate the mechanism. We will add these targeted controls in the revised version. revision: yes
-
Referee: [Experimental description] Experimental description (throughout): No exact injection text, corpus construction details, retrieval protocol, or statistical tests are provided despite the claim of reproducibility across 50 trials and counterfactual setups. This omission is load-bearing because it prevents independent verification of whether the directional results support the safety-training attribution.
Authors: We acknowledge that the manuscript text omits these implementation details. In the revision we will include the exact injection strings, full corpus construction procedure, retrieval protocol (including embedding model, similarity metric, and top-k selection), and statistical analysis (e.g., binomial confidence intervals or exact tests on the 50-trial counts) so that the experiments can be independently reproduced. revision: yes
Circularity Check
No circularity; empirical results from controlled experiments
full rationale
The paper reports experimental observations of recommendation rates in RAG setups with and without prompt injections across model families. No equations, parameter fits, or derivations are present that could reduce to inputs by construction. Claims rest on direct trial outcomes (e.g., top-2 recommendation counts) rather than self-citations, ansatzes, or renamed patterns. The central attribution to safety training is an interpretive label on the data, not a load-bearing derivation that collapses to prior self-work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Safety training in the tested Claude models causes avoidance of recommendations when prompt-injection-like content appears in retrieved documents.
Reference graph
Works this paper leans on
-
[1]
Constitutional classifiers: Defending against universal jailbreaks
Anthropic . Constitutional classifiers: Defending against universal jailbreaks. Technical report, Anthropic, 2025
2025
-
[2]
Bai, Y. et al. Constitutional AI : Harmlessness from AI feedback. arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Filandrianos, G. et al. Bias beware: The impact of cognitive biases on LLM -driven product recommendations. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025
2025
-
[4]
Greshake, K. et al. Not what you've signed up for: Compromising real-world LLM -integrated applications with indirect prompt injection. In AISec@CCS, 2023
2023
-
[5]
Manipulating AI memory for profit: The rise of AI recommendation poisoning
Microsoft Defender Security Research Team . Manipulating AI memory for profit: The rise of AI recommendation poisoning. Microsoft Security Blog, 2026
2026
-
[6]
and Kashef, R
Nawara, D. and Kashef, R. A comprehensive survey on LLM -powered recommender systems: From discriminative, generative to multi-modal paradigms. IEEE Access, 2025
2025
-
[7]
Adversarial search engine optimization for large language models
Nestaas, F., Debenedetti, E., and Tram \`e r, F. Adversarial search engine optimization for large language models. In International Conference on Learning Representations (ICLR), 2025
2025
-
[8]
Jailbroken: How does LLM safety training fail? In Advances in Neural Information Processing Systems (NeurIPS), 2023
Wei, A., Haghtalab, N., and Steinhardt, J. Jailbroken: How does LLM safety training fail? In Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[9]
Zou, W. et al. PoisonedRAG : Knowledge corruption attacks to retrieval-augmented generation. In USENIX Security Symposium, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.