The strength of clinical evidence is recoverable from language model representations but not from their stated grades
Pith reviewed 2026-06-30 09:28 UTC · model grok-4.3
The pith
Language models carry a recoverable signal for clinical evidence strength in their representations, but their stated grades perform at chance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
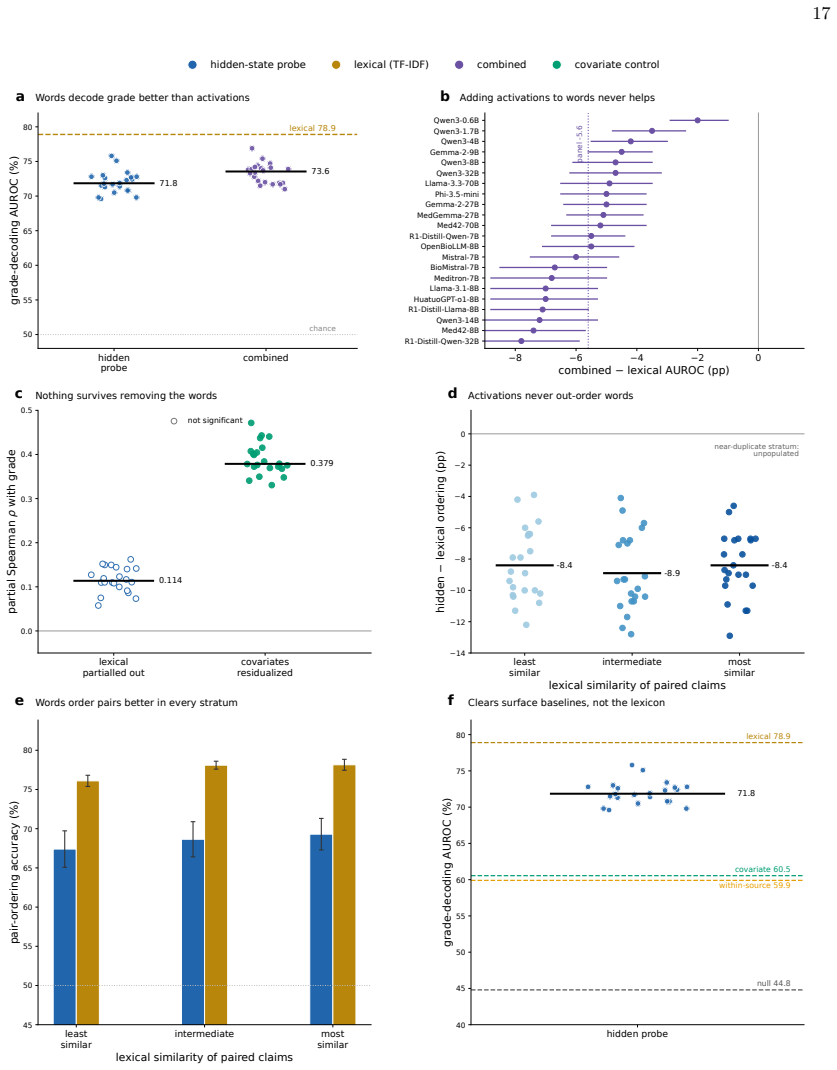
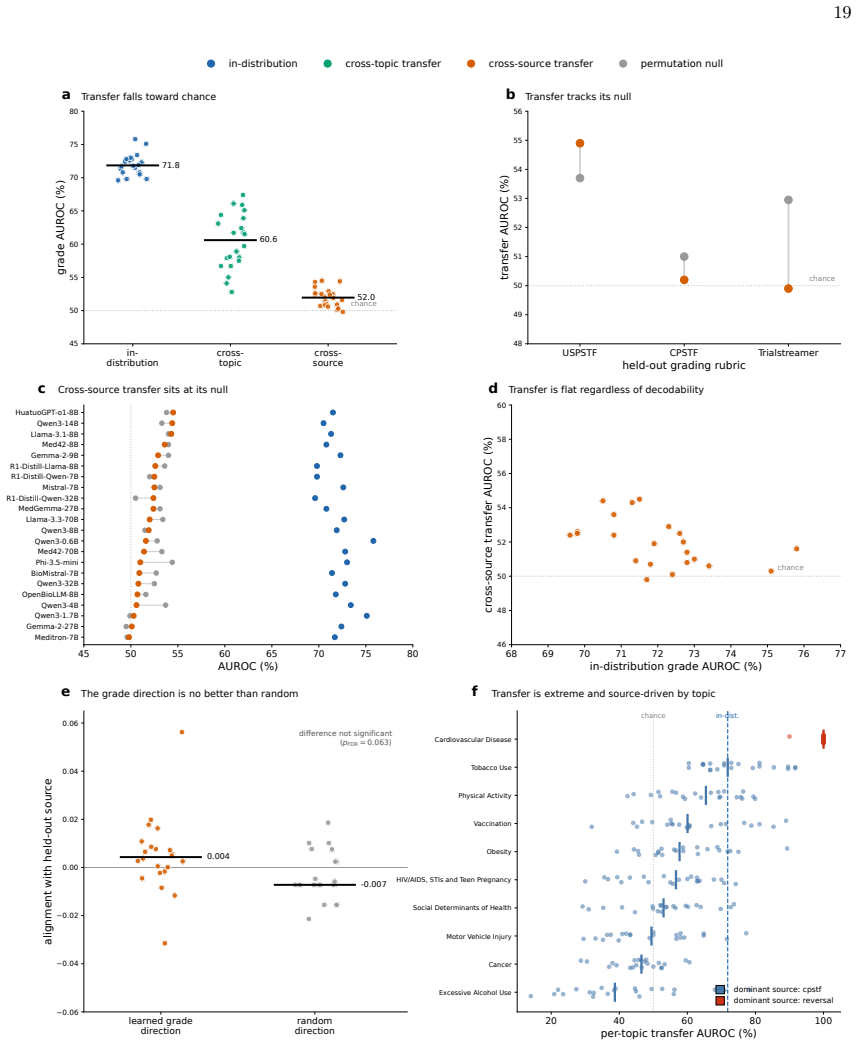
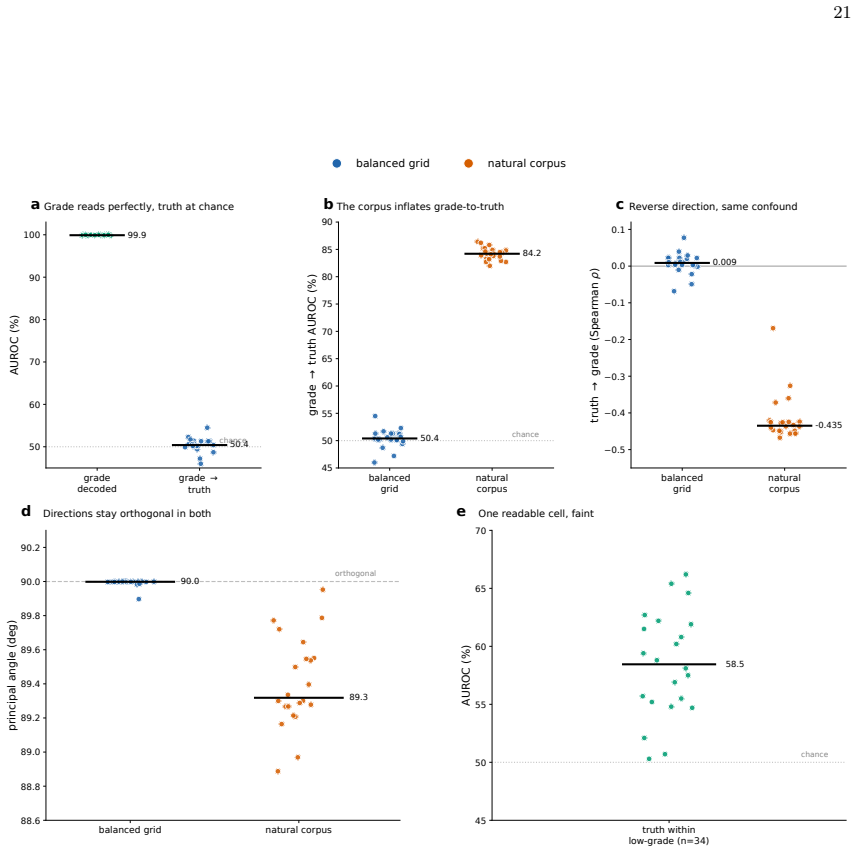
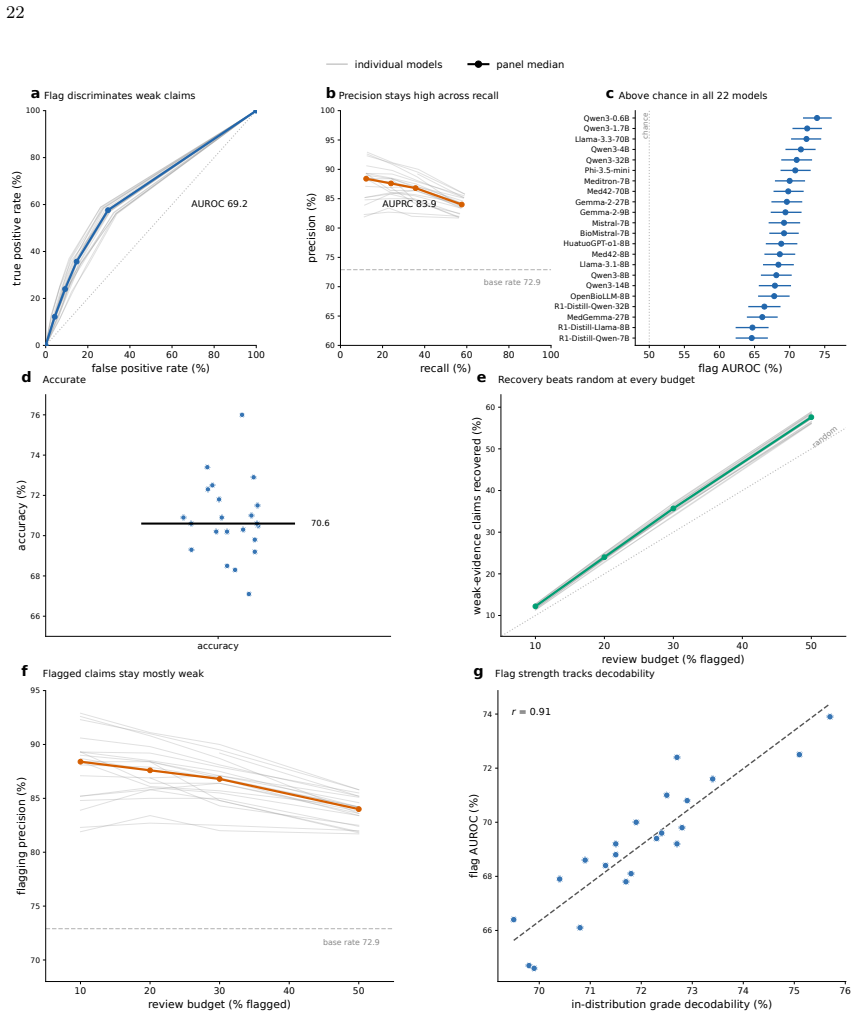
Clinical LLMs register an ordered evidence-strength signal that a linear readout can extract from their activations across all tested models and sizes, but the same models state grades no better than random when asked, with the internal signal being mostly lexical, non-transferable across domains or frameworks, and separable from factual accuracy.
What carries the argument
Linear estimator applied to model hidden states to decode harmonized evidence grade
Load-bearing premise
The four-level grades harmonized from three independent frameworks correctly reflect the true strength of support for each clinical claim.
What would settle it
A replication in which stated grades from the same models reach within 5 points of the linear estimator's AUROC on held-out claims.
Figures
read the original abstract
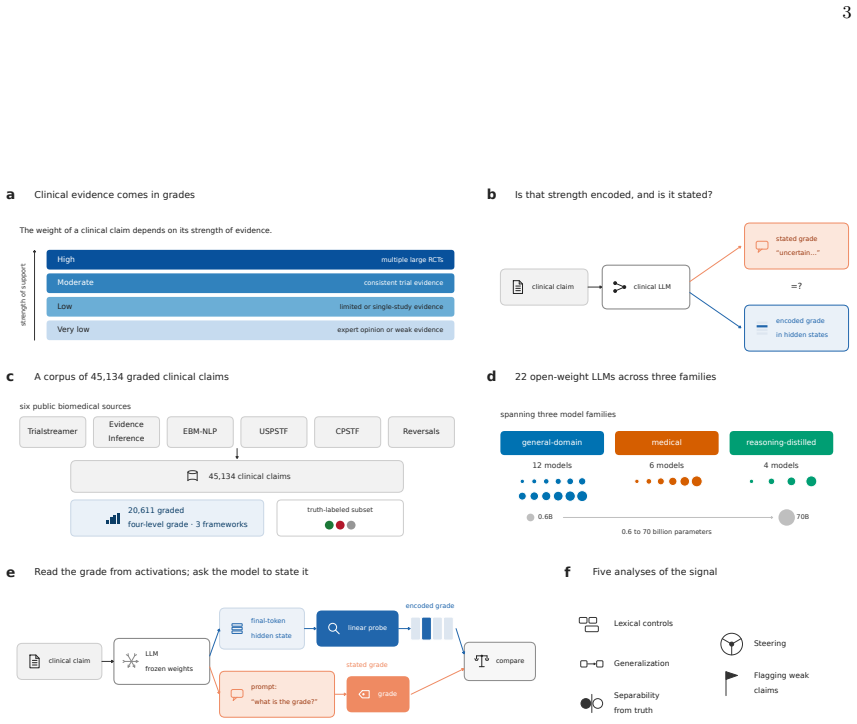
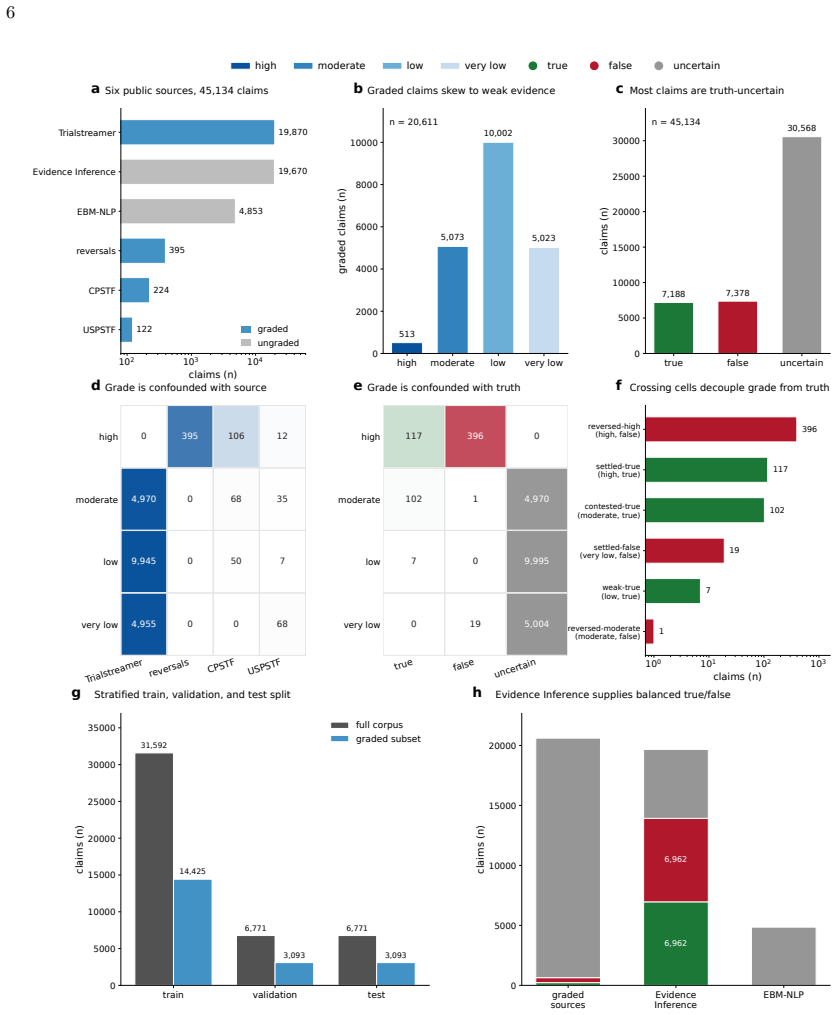
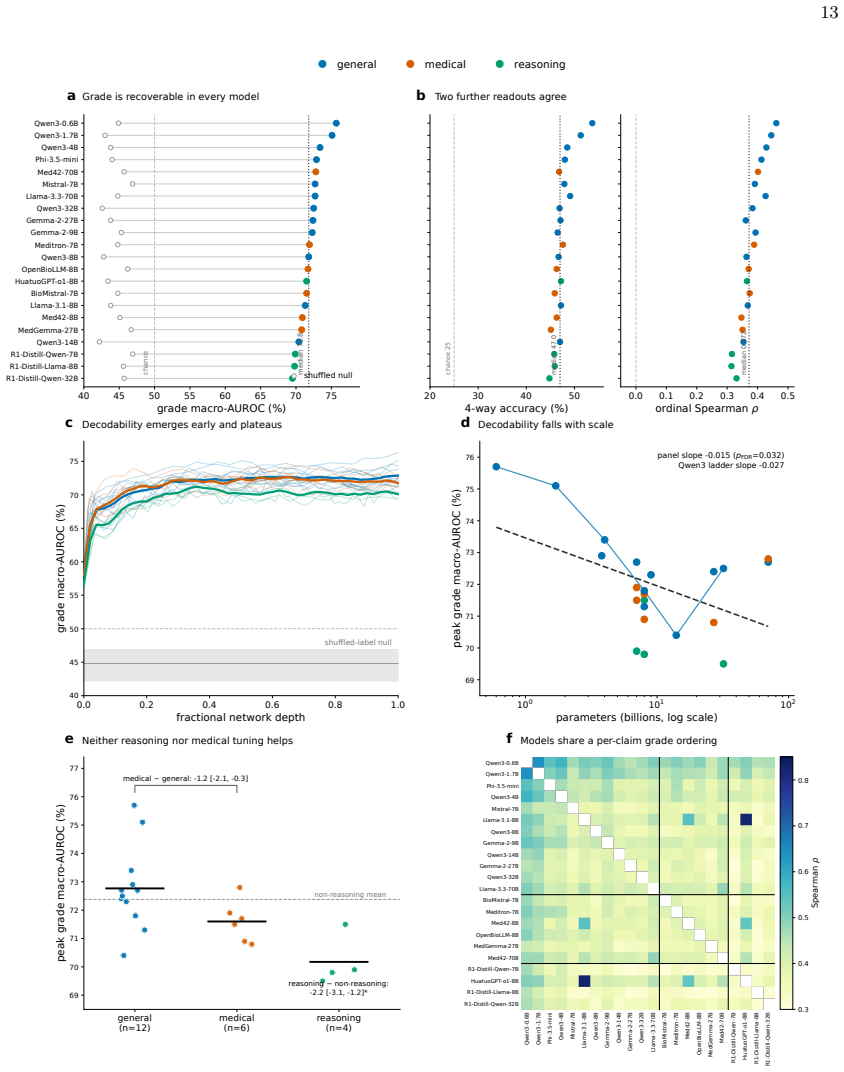
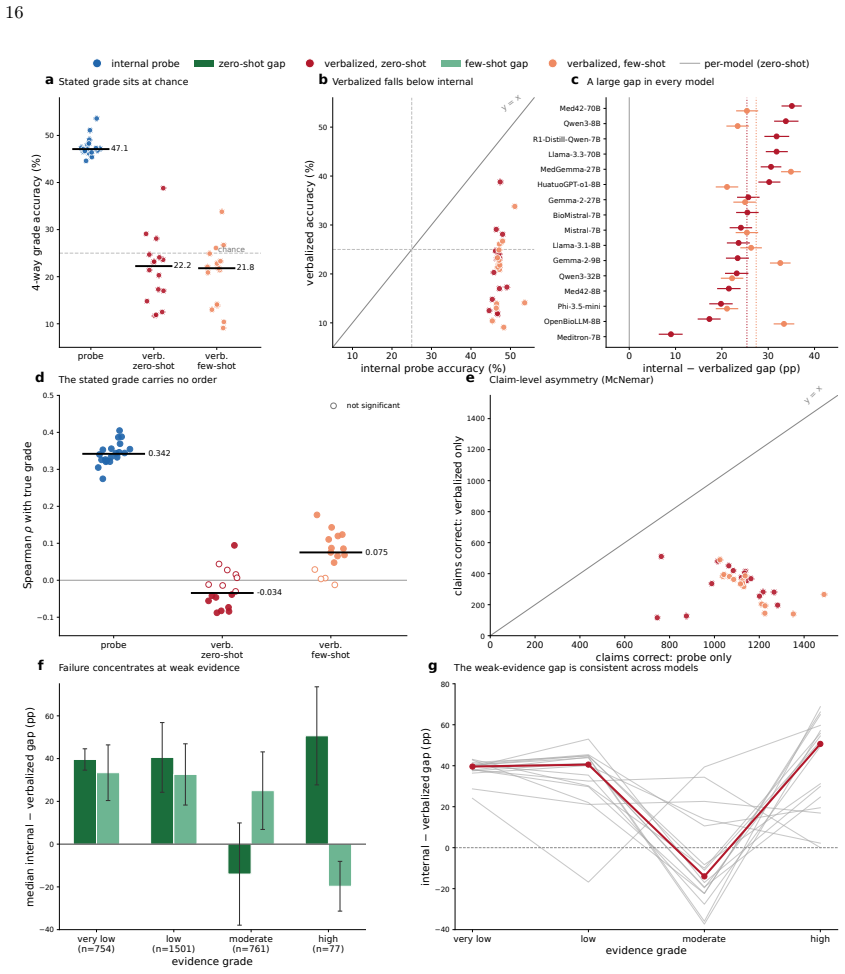
Large language models (LLMs) increasingly summarize clinical evidence, where a claim's weight depends on how strongly it is supported. Yet these models convey confidence poorly, and properties they never state, such as truth, are often readable from their activations. Whether a clinical model registers evidence strength, distinct from truth, and states it when asked is untested, and any such signal could be lexical. We compiled 45,134 clinical claims from six public sources, harmonized 20,611 into a four-level evidence grade under three independent frameworks, and tested 22 local, open-weight LLMs from several developers (0.6-70 billion parameters; general, medical, and reasoning), with lexical, truth, and cross-framework controls. A linear estimator recovered the grade in every model (median AUROC 71.8), yet decodability did not rise with scale and was weakest in reasoning models. The grade the models stated fell to chance, 25-27 percentage points below the estimator. The recoverable signal was largely lexical and did not transfer across topics or frameworks, yet it was distinct from factual truth and still flagged weakly supported claims (AUROC 69.2). Clinical LLMs thus carry an ordered evidence-strength signal they do not express, so their stated grades fail to convey a claim's support even when it is recoverable from their representations and text.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript compiles 45,134 clinical claims from six public sources, harmonizes 20,611 of them into four-level evidence grades using three independent frameworks, and evaluates 22 open-weight LLMs (0.6-70B parameters). Linear probes recover the harmonized grade from model representations (median AUROC 71.8) while stated grades perform at chance; the signal is largely lexical, fails to transfer across topics or frameworks, is distinct from factual truth, and still identifies weakly supported claims (AUROC 69.2).
Significance. If the harmonized grades are a faithful proxy, the result shows that LLMs internally encode ordered evidence-strength information they do not verbalize, with direct implications for clinical summarization reliability. The study is strengthened by its scale (22 models across families), inclusion of lexical and truth controls, and cross-framework checks.
major comments (2)
- [Methods (harmonization and data construction)] The headline claim that LLMs 'register evidence strength' rests on the harmonized four-level grades faithfully capturing underlying clinical support. The mapping of 20,611 claims from three frameworks into a single ordered scale is the sole source of the probe targets; while cross-framework controls and lexical ablations are reported, they still use these same harmonized labels and do not test whether the grades align with independent expert judgments of evidential support drawn directly from the source documents.
- [Results] Results (AUROC reporting): the median AUROC of 71.8 is presented without accompanying per-model ranges, confidence intervals, or details on the exact probe architecture (layer selection, regularization, training/validation split), making it impossible to assess whether the reported gap to stated grades (25-27 points) is robust to implementation choices.
minor comments (2)
- [Abstract] Abstract: 'median AUROC 71.8' would be clearer if accompanied by the interquartile range or min/max across the 22 models.
- [Methods] Notation for the four evidence levels is introduced without an explicit table mapping the original framework categories to the harmonized scale.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, proposing revisions where feasible while noting genuine limitations.
read point-by-point responses
-
Referee: [Methods (harmonization and data construction)] The headline claim that LLMs 'register evidence strength' rests on the harmonized four-level grades faithfully capturing underlying clinical support. The mapping of 20,611 claims from three frameworks into a single ordered scale is the sole source of the probe targets; while cross-framework controls and lexical ablations are reported, they still use these same harmonized labels and do not test whether the grades align with independent expert judgments of evidential support drawn directly from the source documents.
Authors: We agree the harmonized grades derive solely from the three frameworks rather than new direct expert re-annotation of source documents. Cross-framework agreement and controls provide internal consistency checks, but do not substitute for independent expert validation. This is a real methodological limitation of the study design. In revision we will expand the limitations section to state this reliance explicitly and note that future work should include such expert judgments. revision: partial
-
Referee: [Results] Results (AUROC reporting): the median AUROC of 71.8 is presented without accompanying per-model ranges, confidence intervals, or details on the exact probe architecture (layer selection, regularization, training/validation split), making it impossible to assess whether the reported gap to stated grades (25-27 points) is robust to implementation choices.
Authors: We accept this criticism. The manuscript omitted these implementation details. In the revised version we will add: per-model AUROC ranges with 95% CIs, exact probe architecture (layer selection, regularization strength, and train/validation/test splits). This will allow direct assessment of the gap's robustness. revision: yes
- Absence of independent expert judgments of evidential support drawn directly from source documents to validate the harmonized grades.
Circularity Check
No significant circularity; empirical probe on externally sourced labels
full rationale
The paper compiles 45,134 claims from six public sources and harmonizes 20,611 into four-level grades using three independent frameworks. These grades serve as fixed target labels. A linear probe is then trained on model activations to recover the labels, with AUROC measuring empirical recoverability. No equations, derivations, or self-citations reduce the reported AUROC to a quantity defined by construction from the same fitted values. Lexical controls, truth controls, and cross-framework tests operate on the harmonized targets but do not create a self-referential loop. The central result (recoverable signal distinct from stated grades) is an empirical measurement, not a tautology. Minor self-citation risk is absent from the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Clinical claims can be reliably assigned and harmonized into a consistent four-level evidence grade across three independent frameworks.
Reference graph
Works this paper leans on
-
[1]
Nature620(7972), 172–180 (2023)
Singhal, K., Azizi, S., Tu, T., Mahdavi, S.S., Wei, J., Chung, H.W., Scales, N., Tanwani, A., Cole- Lewis, H., Pfohl, S., et al.: Large language models encode clinical knowledge. Nature620(7972), 172–180 (2023)
2023
-
[2]
Nature medicine29(8), 1930–1940 (2023)
Thirunavukarasu, A.J., Ting, D.S.J., Elangovan, K., Gutierrez, L., Tan, T.F., Ting, D.S.W.: Large language models in medicine. Nature medicine29(8), 1930–1940 (2023)
1930
-
[3]
Nature medicine30(4), 1134–1142 (2024)
Van Veen, D., Van Uden, C., Blankemeier, L., et al.: Adapted large language models can outperform medical experts in clinical text summarization. Nature medicine30(4), 1134–1142 (2024)
2024
-
[4]
Nature medicine31(3), 943–950 (2025)
Singhal, K., Tu, T., Gottweis, J., et al.: Toward expert-level medical question answering with large language models. Nature medicine31(3), 943–950 (2025)
2025
-
[5]
Kadavath, S., Conerly, T., Askell, A., et al.: Language models (mostly) know what they know (2022), https://arxiv.org/abs/2207.05221
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Transactions on Machine Learning Research (2022),https://openreview.net/forum?id=8s8K2UZGTZ
Lin, S., Hilton, J., Evans, O.: Teaching models to express their uncertainty in words. Transactions on Machine Learning Research (2022),https://openreview.net/forum?id=8s8K2UZGTZ
2022
-
[7]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Tian, K., Mitchell, E., Zhou, A., Sharma, A., Rafailov, R., Yao, H., Finn, C., Manning, C.: Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 5433–5442. Association for Computati...
2023
-
[8]
In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum?id=gjeQKFxFpZ
Xiong, M., Hu, Z., Lu, X., LI, Y., Fu, J., He, J., Hooi, B.: Can LLMs express their uncertainty? an empirical evaluation of confidence elicitation in LLMs. In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum?id=gjeQKFxFpZ
2024
-
[9]
Nature Machine Intelligence7(2), 221–231 (2025)
Steyvers, M., Tejeda, H., Kumar, A., Belem, C., Karny, S., Hu, X., Mayer, L.W., Smyth, P.: What large language models know and what people think they know. Nature Machine Intelligence7(2), 221–231 (2025)
2025
-
[10]
Nature medicine30(9), 2613–2622 (2024)
Hager, P., Jungmann, F., Holland, R., Bhagat, K., et al.: Evaluation and mitigation of the limitations of large language models in clinical decision-making. Nature medicine30(9), 2613–2622 (2024)
2024
-
[11]
In: The 2023 Conference on Empirical Methods in Natural Language Processing (2023),https://openreview.net/forum?id= y2V6YgLaW7
Azaria, A., Mitchell, T.: The internal state of an LLM knows when it’s lying. In: The 2023 Conference on Empirical Methods in Natural Language Processing (2023),https://openreview.net/forum?id= y2V6YgLaW7
2023
-
[12]
Burns, C., Ye, H., Klein, D., Steinhardt, J.: Discovering latent knowledge in language models without supervision (2024),https://arxiv.org/abs/2212.03827
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
In: NeurIPS 2023 (2023) 28
Li, K., Patel, O., Viégas, F., Pfister, H., Wattenberg, M.: Inference-time intervention: eliciting truthful answers from a language model. In: NeurIPS 2023 (2023) 28
2023
-
[14]
Marks, S., Tegmark, M.: The geometry of truth: Emergent linear structure in large language model representations of true/false datasets (2024),https://openreview.net/forum?id=CeJEfNKstt
2024
-
[15]
In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum?id= KRnsX5Em3W
Orgad, H., Toker, M., Gekhman, Z., Reichart, R., Szpektor, I., Kotek, H., Belinkov, Y.: LLMs know more than they show: On the intrinsic representation of LLM hallucinations. In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum?id= KRnsX5Em3W
2025
-
[16]
Prasad, M.: Introduction to the grade tool for rating certainty in evidence and recommendations. Clinical Epidemiology and Global Health25, 101484 (2024).https://doi.org/https://doi.org/10 .1016/j.cegh.2023.101484
-
[17]
Procedure manual.https://www.uspreventiveservic estaskforce.org/uspstf/about-uspstf/methods-and-processes/procedure-manual(Accessed Nov 24, 2021)
US preventive services task force (USPSTF). Procedure manual.https://www.uspreventiveservic estaskforce.org/uspstf/about-uspstf/methods-and-processes/procedure-manual(Accessed Nov 24, 2021)
2021
-
[18]
Elife8, e45183 (2019)
Herrera-Perez, D., Haslam, A., Crain, T., Gill, J., Livingston, C., Kaestner, V., Hayes, M., Morgan, D., Cifu, A.S., Prasad, V.: A comprehensive review of randomized clinical trials in three medical journals reveals 396 medical reversals. Elife8, e45183 (2019)
2019
-
[19]
Cheang, C.S., Chan, H.P., Zhang, W., Deng, Y.: Do llms really know what they don’t know? internal states mainly reflect knowledge recall rather than truthfulness (2026),https://arxiv.org/abs/2510 .09033
2026
-
[20]
In: Findings of the association for computational linguistics: acl 2024
Labrak, Y., Bazoge, A., Morin, E., Gourraud, P.A., Rouvier, M., Dufour, R.: Biomistral: A collection of open-source pretrained large language models for medical domains. In: Findings of the association for computational linguistics: acl 2024. pp. 5848–5864 (2024)
2024
-
[21]
Nature645(8081), 633–638 (2025)
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., et al.: Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature645(8081), 633–638 (2025)
2025
-
[22]
In: Findings of the Association for Computational Linguistics: ACL 2025
Chen, J., Cai, Z., Ji, K., Wang, X., Liu, W., Wang, R., Wang, B.: Towards medical complex reasoning with LLMs through medical verifiable problems. In: Findings of the Association for Computational Linguistics: ACL 2025. pp. 14552–14573 (2025).https://doi.org/10.18653/v1/2025.findings-acl .751
-
[23]
Journal of the American Medical Informatics Association27(12), 1903–1912 (2020)
Marshall, I.J., Nye, B., Kuiper, J., Noel-Storr, A., Marshall, R., Maclean, R., Soboczenski, F., Nenkova, A., Thomas, J., Wallace, B.C.: Trialstreamer: A living, automatically updated database of clinical trial reports. Journal of the American Medical Informatics Association27(12), 1903–1912 (2020)
1903
-
[24]
In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)
Lehman, E., DeYoung, J., Barzilay, R., Wallace, B.C.: Inferring which medical treatments work from reports of clinical trials. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). pp. 3705–3717 (2019)
2019
-
[25]
In: Proceedings of the 56th Annual Meeting ofthe Association for Computational Linguistics (Volume 1: Long Papers)
Nye, B., Li, J.J., Patel, R., Yang, Y., Marshall, I., Nenkova, A., Wallace, B.C.: A corpus with multi- level annotations of patients, interventions and outcomes to support language processing for medical literature. In: Proceedings of the 56th Annual Meeting ofthe Association for Computational Linguistics (Volume 1: Long Papers). pp. 197–207 (2018)
2018
-
[26]
American journal of preventive medicine18(1), 35–43 (2000)
Briss,P.A.,Zaza,S.,Pappaioanou,M.,Fielding,J.,Wright-DeAgüero,L.,Truman,B.I.,Hopkins,D.P., Mullen, P.D., Thompson, R.S., Woolf, S.H., et al.: Developing an evidence-based guide to community preventive services—methods. American journal of preventive medicine18(1), 35–43 (2000)
2000
-
[27]
Cramér, H.: Mathematical methods of statistics, vol. 9. Princeton university press (1999)
1999
-
[28]
Yang, A., Li, A., et al.: Qwen3 technical report (2025),https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Abdin, M., Aneja, J., Awadalla, H., et al.: Phi-3 technical report: A highly capable language model locally on your phone (2024),https://arxiv.org/abs/2404.14219
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Jiang, A.Q., Sablayrolles, A., Mensch, A., et al.: Mistral 7b (2023),https://arxiv.org/abs/2310.0 6825
2023
-
[31]
Grattafiori, A., Dubey, A., Jauhri, A., et al.: The llama 3 herd of models (2024),https://arxiv.or g/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Team, G., Riviere, M., Pathak, S., et al.: Gemma 2: Improving open language models at a practical size (2024),https://arxiv.org/abs/2408.00118
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Chen,Z.,Cano,A.H.,Romanou,A.,etal.:Meditron-70b:Scalingmedicalpretrainingforlargelanguage models (2023),https://arxiv.org/abs/2311.16079 29
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Ankit Pal, M.S.: Openbiollms: Advancing open-source large language models for healthcare and life sciences.https://huggingface.co/aaditya/OpenBioLLM-Llama3-70B(2024)
2024
- [35]
-
[36]
Sellergren, A., Kazemzadeh, S., et al.: Medgemma technical report (2026),https://arxiv.org/abs/ 2507.05201
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
John Wiley & Sons (2003)
Seber, G.A., Lee, A.J.: Linear regression analysis. John Wiley & Sons (2003)
2003
-
[38]
Chapman and Hall/CRC (1994)
Efron, B., Tibshirani, R.J.: An introduction to the bootstrap. Chapman and Hall/CRC (1994)
1994
-
[39]
Psychometrika12(2), 153–157 (1947)
McNemar, Q.: Note on the sampling error of the difference between correlated proportions or percent- ages. Psychometrika12(2), 153–157 (1947)
1947
-
[40]
Sparck Jones, K.: A statistical interpretation of term specificity and its application in retrieval, p. 132–142. Taylor Graham Publishing, GBR (1988)
1988
-
[41]
In: European conference on machine learning
Joachims, T.: Text categorization with support vector machines: Learning with many relevant features. In: European conference on machine learning. pp. 137–142. Springer (1998)
1998
-
[42]
Monthly weather review 78(1), 1–3 (1950)
Glenn, W.B., et al.: Verification of forecasts expressed in terms of probability. Monthly weather review 78(1), 1–3 (1950)
1950
-
[43]
Journal of the Royal statistical society: series B (Methodological)57(1), 289–300 (1995)
Benjamini, Y., Hochberg, Y.: Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal statistical society: series B (Methodological)57(1), 289–300 (1995)
1995
-
[44]
Nature630(8017), 625–630 (2024)
Farquhar, S., Kossen, J., Kuhn, L., Gal, Y.: Detecting hallucinations in large language models using semantic entropy. Nature630(8017), 625–630 (2024)
2024
-
[45]
Designing and interpreting probes with control tasks
Hewitt, J., Liang, P.: Designing and interpreting probes with control tasks. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). pp. 2733–2743 (2019).https: //doi.org/10.18653/v1/D19-1275
-
[46]
Wind, S., Nguyen, T.T., Sopa, J., Lotfinia, M., Bickelhaup, S., Uder, M., Köstler, H., Wellein, G., Nebelung, S., Truhn, D., Maier, A., Arasteh, S.T.: Safety and accuracy follow different scaling laws in clinical large language models (2026),https://arxiv.org/abs/2605.04039
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum?id=Zj12nzlQbz
Chen, C., Liu, K., Chen, Z., Gu, Y., Wu, Y., Tao, M., Fu, Z., Ye, J.: INSIDE: LLMs’ internal states retain the power of hallucination detection. In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum?id=Zj12nzlQbz
2024
-
[48]
npj Digital Medicine8, 790 (2025)
Wind, S., Sopa, J., Truhn, D., Lotfinia, M., Nguyen, T.T., Bressem, K., Adams, L., Rusu, M., Köstler, H., Wellein, G., et al.: Multi-step retrieval and reasoning improves radiology question answering with large language models. npj Digital Medicine8, 790 (2025)
2025
-
[49]
Radiology: Artificial Intelligence7(4), e240476 (2025)
Tayebi Arasteh, S., Lotfinia, M., Bressem, K., Siepmann, R., Adams, L., Ferber, D., Kuhl, C., Kather, J.N., Nebelung, S., Truhn, D.: Radiorag: online retrieval–augmented generation for radiology question answering. Radiology: Artificial Intelligence7(4), e240476 (2025)
2025
-
[50]
Zou,A.,Phan,L.,Chen,S.,Campbell,J.,Guo,P.,Ren,R.,Pan,A.,Yin,X.,Mazeika,M.,Dombrowski, A.K., Goel, S., Li, N., Byun, M.J., Wang, Z., Mallen, A., Basart, S., Koyejo, S., Song, D., Fredrikson, M., Kolter, J.Z., Hendrycks, D.: Representation engineering: A top-down approach to ai transparency (2025),https://arxiv.org/abs/2310.01405
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Turner, A.M., Thiergart, L., Leech, G., Udell, D., Vazquez, J.J., Mini, U., MacDiarmid, M.: Steering language models with activation engineering (2024),https://arxiv.org/abs/2308.10248
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
In: NeurIPS 2024 (2024),https://openreview.n et/forum?id=v8X70gTodR
Tan, D.C.H., Chanin, D., Lynch, A., Paige, B., Kanoulas, D., Garriga-Alonso, A., Kirk, R.: Analysing the generalisation and reliability of steering vectors. In: NeurIPS 2024 (2024),https://openreview.n et/forum?id=v8X70gTodR
2024
-
[53]
Nature Machine Intelligence2(11), 665–673 (2020)
Geirhos, R., Jacobsen, J.H., Michaelis, C., Zemel, R., Brendel, W., Bethge, M., Wichmann, F.A.: Shortcut learning in deep neural networks. Nature Machine Intelligence2(11), 665–673 (2020)
2020
-
[54]
Gururangan, S., Swayamdipta, S., Levy, O., Schwartz, R., Bowman, S.R., Smith, N.A.: Annotation artifacts in natural language inference data. In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). pp. 107–112 (Jun 2018).https://doi.org/10.1...
-
[55]
Lotfinia, M., Ziegelmayer, S., Adams, L., Truhn, D., Maier, A., Arasteh, S.T.: Vision-language models for chest radiography do not always need the image (2026),https://arxiv.org/abs/2606.17710 30
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[56]
Arasteh, S.T., Joodaki, M., Lotfinia, M., Nebelung, S., Truhn, D.: Case-grounded evidence verification: A framework for constructing evidence-sensitive supervision (2026),https://arxiv.org/abs/2604.0 9537
2026
-
[57]
In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/for um?id=RIu5lyNXjT
Sclar, M., Choi, Y., Tsvetkov, Y., Suhr, A.: Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting. In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/for um?id=RIu5lyNXjT
2024
-
[58]
Radiology: Artificial Intelligence8(3), e260346 (2026)
Tayebi Arasteh, S., Truhn, D.: When framing shapes the answer: Cognitive bias and large language model reliability in radiology. Radiology: Artificial Intelligence8(3), e260346 (2026)
2026
-
[59]
Belinkov, Y.: Probing classifiers: Promises, shortcomings, and advances. Computational Linguistics 48(1), 207–219 (2022).https://doi.org/10.1162/coli_a_00422 31 Supplementary information Supplementary Note 1: Clinical claim corpus construction. This note documents the full corpus-construction pipeline end to end, from the six raw public sources to the ass...
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.