Position: Prioritize Identifying Structure, Not Complex Models, for Scientific Discovery
Pith reviewed 2026-06-28 17:55 UTC · model grok-4.3
The pith
Many incompatible mechanisms produce the same observations, so predictive success alone does not establish mechanism discovery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the high-dimensional proxy regimes where modern ML excels, mechanistic learning is generically underdetermined: many incompatible mechanisms induce essentially the same observational relationships on the support of the data, so predictive success and coherent explanations are insufficient evidence of mechanism discovery. This underdetermination becomes uniquely hazardous with large language models, which tend to collapse large equivalence classes of explanations into a single fluent narrative. Concrete standards for mechanistic ML are necessary if LLM-centered workflows are to support science rather than merely simulate it.
What carries the argument
Underdetermination of mechanisms by data: the property that many incompatible mechanisms induce essentially the same observational relationships on the support of the data in high-dimensional proxy regimes.
If this is right
- Predictive accuracy of an ML model supplies no evidence that the model has recovered a unique mechanism.
- Coherent narrative explanations generated by LLMs do not indicate that the model has resolved mechanistic ambiguity.
- Any workflow claiming mechanistic discovery must include explicit checks that rule out alternative mechanisms consistent with the data.
- Standards for mechanistic ML must require demonstration that the identified mechanism is distinguishable from others on the observed support.
Where Pith is reading between the lines
- Efforts to discover mechanisms may need to shift emphasis toward direct identification of structural constraints rather than reliance on complex predictive models.
- Methods that enumerate or bound the set of mechanisms consistent with given data could reduce the hazard of narrative collapse.
- The same underdetermination concern may apply to non-LLM machine learning systems that produce single-point explanations from high-dimensional inputs.
Load-bearing premise
That the settings where modern ML excels are high-dimensional proxy regimes in which underdetermination of mechanisms is generic and that large language models systematically reduce multiple possible explanations to one narrative.
What would settle it
A high-dimensional observational dataset together with an explicit list of at least two incompatible mechanisms that produce identical predictions on all observed points, yet an LLM workflow that outputs only one of them as the discovered mechanism.
Figures

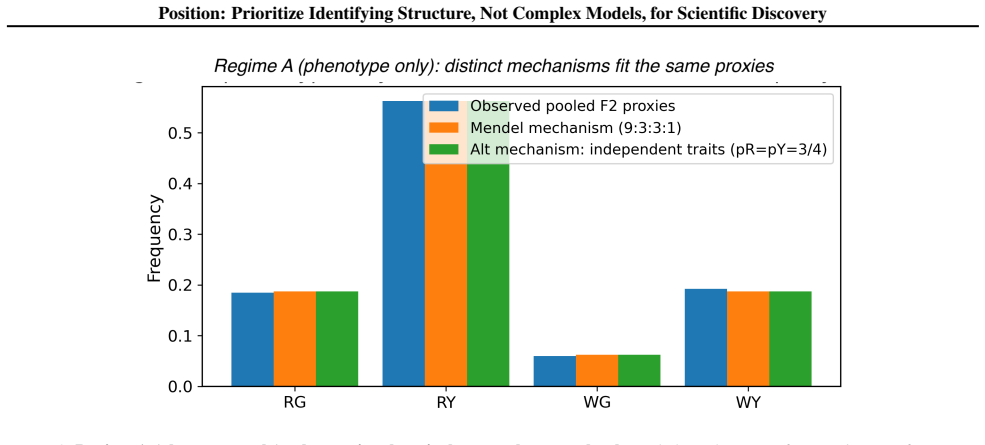
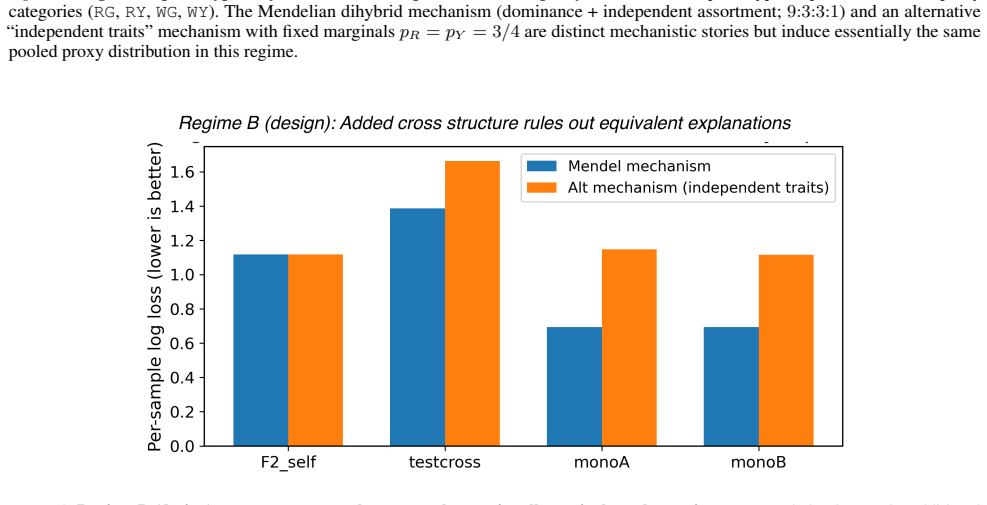
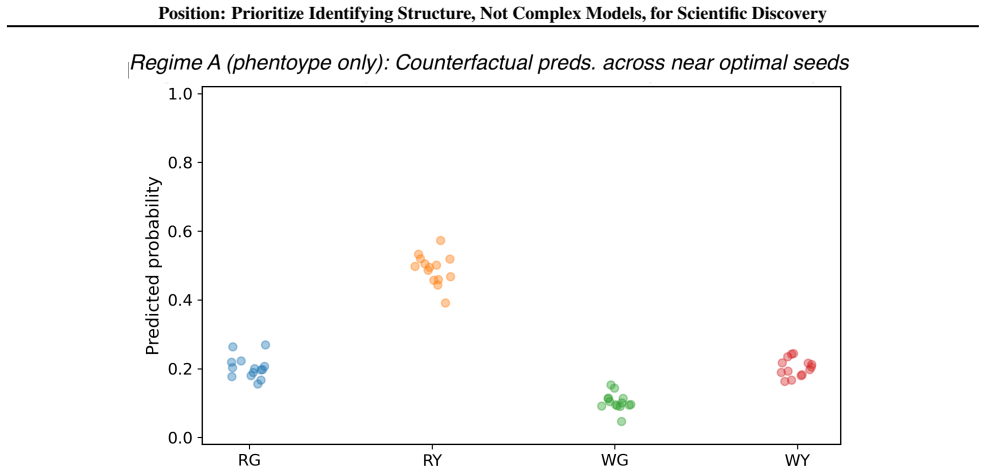
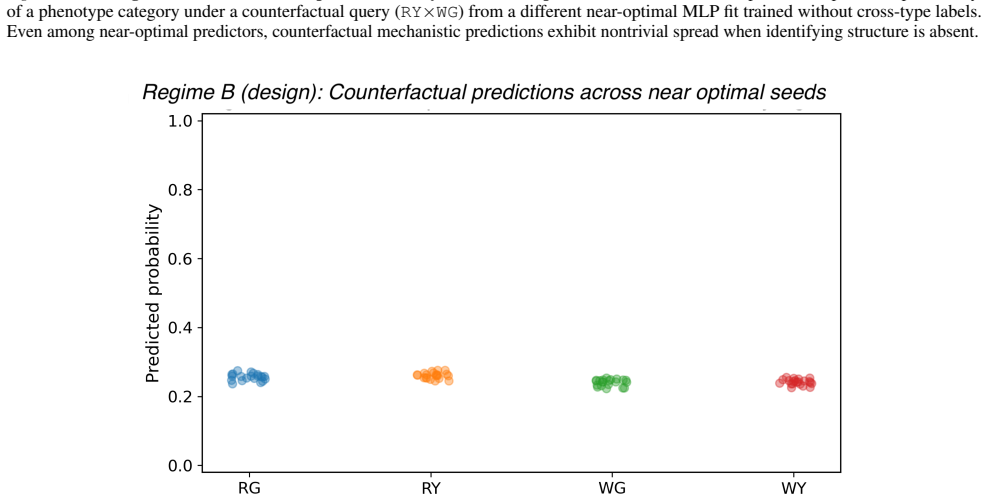
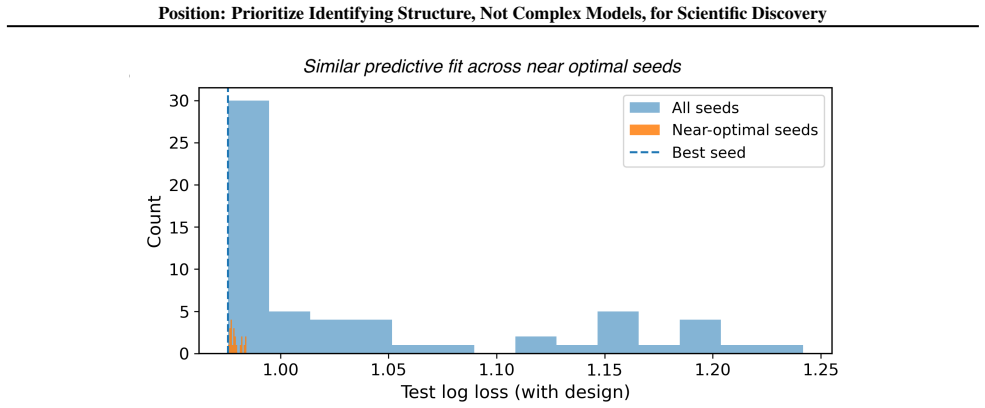
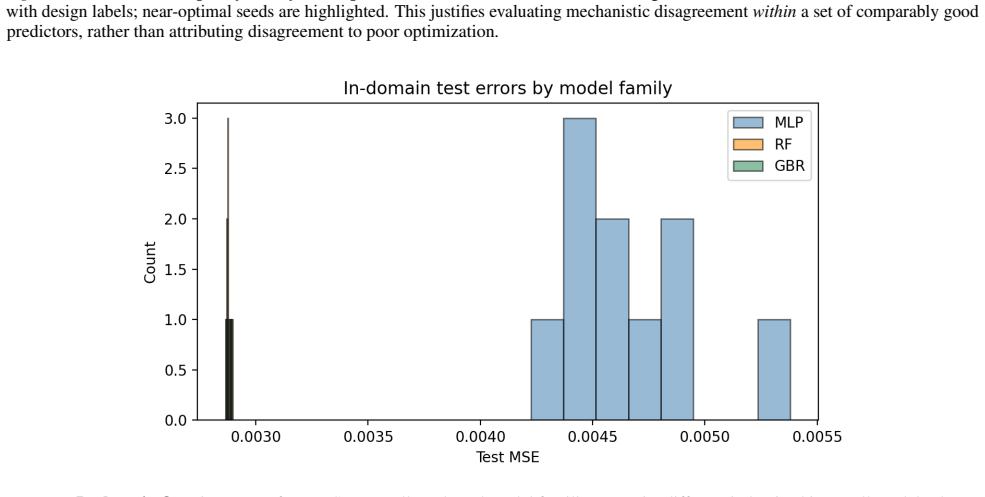
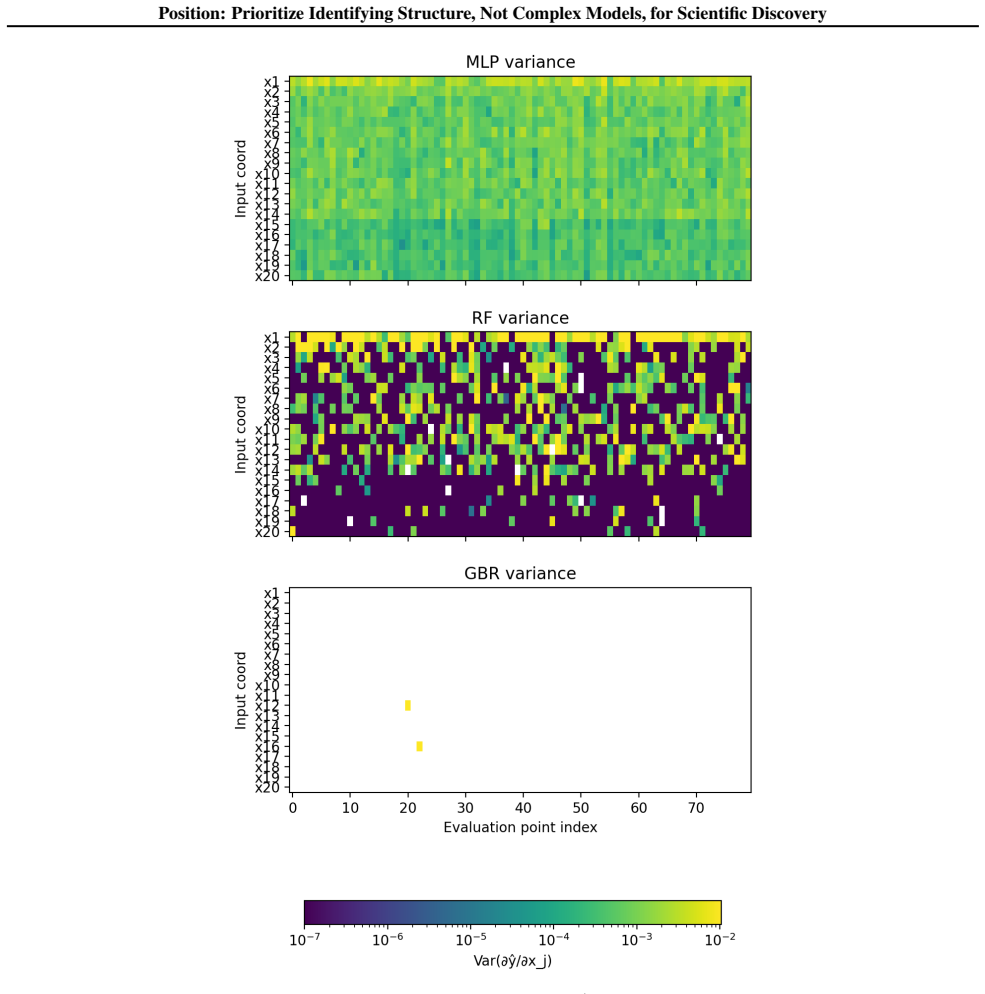
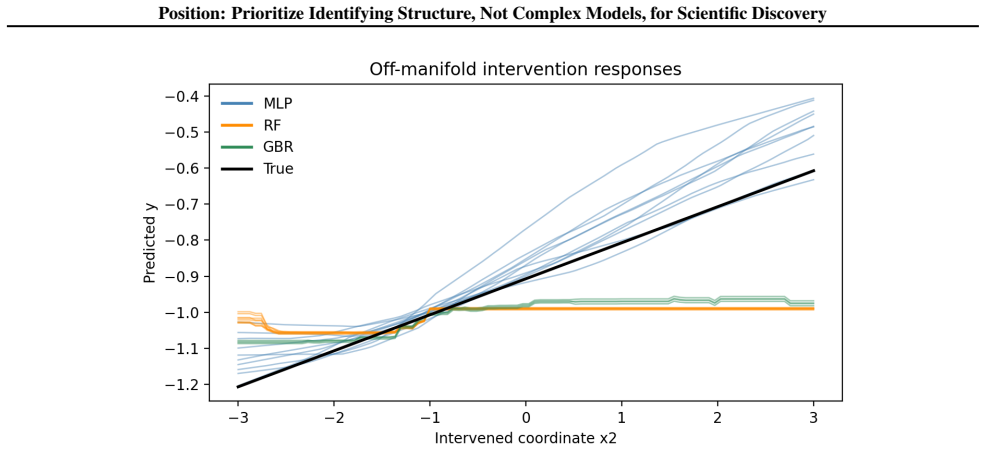
read the original abstract
Modern Machine Learning (ML) and Artificial Intelligence (AI) models, especially large language models (LLMs), are increasingly used to generate scientific hypotheses and mechanistic explanations from observational data. This position paper argues that in the high-dimensional proxy regimes where modern ML excels, mechanistic learning is generically underdetermined: many incompatible mechanisms induce essentially the same observational relationships on the support of the data, so predictive success and coherent explanations are insufficient evidence of mechanism discovery. This underdetermination becomes uniquely hazardous with large language models (LLMs), which tend to collapse large equivalence classes of explanations into a single fluent narrative. This paper proposes concrete standards for ``mechanistic ML,'' and argues these norms are necessary if LLM-centered workflows are to support science rather than merely simulate it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This position paper claims that in the high-dimensional proxy regimes where modern ML excels, mechanistic learning from observational data is generically underdetermined: many incompatible mechanisms can induce essentially identical observational relationships on the data support, rendering predictive accuracy and coherent narratives insufficient to establish mechanism discovery. It further argues that this underdetermination is uniquely hazardous for LLMs, which collapse equivalence classes of explanations into single fluent outputs, and proposes concrete standards for 'mechanistic ML' to ensure such workflows support rather than merely simulate science.
Significance. If the genericity of underdetermination holds, the paper would offer a timely conceptual caution for AI-assisted scientific discovery, highlighting the priority of structure identification over complex model fitting. The emphasis on standards for mechanistic ML could usefully shape norms in the field, though the absence of any formal characterization or illustrative example restricts the argument to a high-level position statement.
major comments (2)
- [Abstract and core argument on underdetermination] The central claim (abstract and opening paragraphs) that underdetermination is 'generic' precisely in high-dimensional proxy regimes lacks both a mathematical characterization of these regimes and a minimal worked example of two distinct mechanisms (e.g., structural causal models or dynamical systems) whose observational distributions coincide on the data support but whose mechanisms differ. This omission is load-bearing for the assertion that predictive success is insufficient evidence of mechanism discovery.
- [Discussion of LLM-specific risks] The further claim that LLMs 'tend to collapse large equivalence classes of explanations into a single fluent narrative' (abstract and discussion of LLM hazards) is advanced without any comparison to other explanatory procedures or evidence establishing uniqueness relative to non-LLM methods. This is load-bearing for the position that the hazard is 'uniquely' LLM-specific.
minor comments (2)
- The term 'support of the data' is invoked repeatedly without a precise definition in the observational setting, which could be clarified for readers outside causal inference.
- The proposed standards for mechanistic ML are referenced but not enumerated in detail; expanding this section with explicit criteria would strengthen the constructive contribution.
Simulated Author's Rebuttal
We thank the referee for these constructive comments, which highlight areas where the position paper can be strengthened with greater concreteness. We address each major point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract and core argument on underdetermination] The central claim (abstract and opening paragraphs) that underdetermination is 'generic' precisely in high-dimensional proxy regimes lacks both a mathematical characterization of these regimes and a minimal worked example of two distinct mechanisms (e.g., structural causal models or dynamical systems) whose observational distributions coincide on the data support but whose mechanisms differ. This omission is load-bearing for the assertion that predictive success is insufficient evidence of mechanism discovery.
Authors: We agree that a minimal worked example would make the underdetermination claim more tangible and will add one in revision (e.g., two distinct linear SCMs or dynamical systems sharing the same marginal on observed variables but differing in latent structure or interventions). We will also expand the description of 'high-dimensional proxy regimes' with additional intuition and references. A full formal mathematical characterization of genericity, however, lies outside the scope of a position paper; the argument remains conceptual and draws on existing results in causal inference and identifiability. revision: partial
-
Referee: [Discussion of LLM-specific risks] The further claim that LLMs 'tend to collapse large equivalence classes of explanations into a single fluent narrative' (abstract and discussion of LLM hazards) is advanced without any comparison to other explanatory procedures or evidence establishing uniqueness relative to non-LLM methods. This is load-bearing for the position that the hazard is 'uniquely' LLM-specific.
Authors: We will revise the manuscript to remove the word 'uniquely' and instead argue that the combination of fluency, single-output generation, and lack of explicit uncertainty representation makes LLMs particularly prone to this collapse relative to traditional scientific workflows that retain multiple candidate explanations. We can cite literature on narrative bias in scientific communication and on the difference between generative models and explicit model-selection procedures, but a systematic empirical comparison across all explanatory methods is beyond the scope of this position statement. revision: yes
Circularity Check
No significant circularity in conceptual position paper
full rationale
The manuscript is a position paper advancing a conceptual argument about underdetermination of mechanisms in high-dimensional regimes and the risks of LLMs. It contains no equations, no fitted parameters, no derivation chain, and no self-citations that serve as load-bearing premises for the central claim. The argument rests on stated premises about observational equivalence rather than any reduction of a 'prediction' or 'result' to its own inputs by construction. This is the normal case for non-mathematical position papers and warrants score 0.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption In high-dimensional proxy regimes where modern ML excels, many incompatible mechanisms induce essentially the same observational relationships.
- domain assumption LLMs tend to collapse large equivalence classes of explanations into a single fluent narrative.
Reference graph
Works this paper leans on
-
[1]
Journal of Machine Learning Research , year =
All Models are Wrong, but Many are Useful: Learning a Variable's Importance by Studying an Entire Class of Prediction Models Simultaneously , author =. Journal of Machine Learning Research , year =
-
[2]
Journal of Statistics and Data Science Education , year =
D'Agostino McGowan, Lucy and Gerke, Travis and Barrett, Malcolm , title =. Journal of Statistics and Data Science Education , year =
-
[3]
The American Statistician , year =
Gelman, Andrew and Hullman, Jessica and Kennedy, Lauren , title =. The American Statistician , year =
-
[4]
Variational Autoencoders and Nonlinear
Khemakhem, Ilyes and Kingma, Diederik and Monti, Ricardo and Hyvarinen, Aapo , booktitle =. Variational Autoencoders and Nonlinear. 2020 , editor =
2020
-
[5]
Proceedings of the 41st International Conference on Machine Learning , pages =
Causal Representation Learning Made Identifiable by Grouping of Observational Variables , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[6]
Identification of Joint Interventional Distributions in Recursive
Shpitser, Ilya and Pearl, Judea , booktitle =. Identification of Joint Interventional Distributions in Recursive. 2006 , pages =
2006
-
[7]
Robustly estimating heterogeneity in factorial data using Rashomon Partitions
Robustly estimating heterogeneity in factorial data using rashomon partitions , author=. arXiv preprint arXiv:2404.02141 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
1996 , edition =
The Structure of Scientific Revolutions , author =. 1996 , edition =
1996
-
[9]
The Philosophical Review , volume=
The structure of scientific revolutions , author=. The Philosophical Review , volume=. 1964 , publisher=
1964
-
[10]
What Would It be Like to be
Soler, L. What Would It be Like to be. Social Epistemology , volume=. 2025 , publisher=
2025
-
[11]
arXiv preprint arXiv:2402.13914 , year=
Position: Explain to question not to justify , author=. arXiv preprint arXiv:2402.13914 , year=
-
[12]
American Journal of Epidemiology , volume=
A warning about using predicted values from regression models for epidemiologic inquiry , author=. American Journal of Epidemiology , volume=. 2021 , publisher=
2021
-
[13]
arXiv preprint arXiv:2508.15162 , year=
A Unified Framework for Inference with General Missingness Patterns and Machine Learning Imputation , author=. arXiv preprint arXiv:2508.15162 , year=
-
[14]
Proceedings of the National Academy of Sciences , volume=
Methods for correcting inference based on outcomes predicted by machine learning , author=. Proceedings of the National Academy of Sciences , volume=. 2020 , publisher=
2020
-
[15]
arXiv preprint arXiv:2405.13926 , year=
Some models are useful, but for how long?: A decision theoretic approach to choosing when to refit large-scale prediction models , author=. arXiv preprint arXiv:2405.13926 , year=
-
[16]
Verhandlungen des naturforschenden Vereines in Br
Mendel, Gregor , title =. Verhandlungen des naturforschenden Vereines in Br. 1866 , volume =
-
[17]
, title =
Fisher, Ronald A. , title =. Annals of Science , year =
-
[18]
Journal of Genetics , year =
Curtis, David , title =. Journal of Genetics , year =
-
[19]
Science & Education , year =
Bapty, Hannah , title =. Science & Education , year =
-
[20]
Mackay, Trudy F. C. and Anholt, Robert R. H. , title =. Nature Reviews Genetics , year =
-
[21]
1855 , edition =
Snow, John , title =. 1855 , edition =
-
[22]
1861 , note =
Pasteur, Louis , title =. 1861 , note =
-
[23]
Deutsche Medizinische Wochenschrift , year =
Koch, Robert , title =. Deutsche Medizinische Wochenschrift , year =
-
[24]
arXiv preprint arXiv:2512.05456 , year=
Do We Really Even Need Data? A Modern Look at Drawing Inference with Predicted Data , author=. arXiv preprint arXiv:2512.05456 , year=
-
[25]
2025 , eprint =
Agarwal, Dhruv and Majumder, Bodhisattwa Prasad and Adamson, Reece and Chakravorty, Megha and Gavireddy, Satvika Reddy and Parashar, Aditya and Surana, Harshit and Mishra, Bhavana Dalvi and McCallum, Andrew and Sabharwal, Ashish and Clark, Peter , booktitle =. 2025 , eprint =
2025
-
[26]
Advances in Neural Information Processing Systems (NeurIPS) , year =
A Path to Simpler Models Starts With Noise , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. doi:10.48550/arXiv.2310.19726 , url =
-
[27]
Proceedings of the 40th International Conference on Machine Learning , series =
Transformers Learn In-Context by Gradient Descent , author =. Proceedings of the 40th International Conference on Machine Learning , series =. 2023 , publisher =
2023
-
[28]
Decomposition of Uncertainty in
Depeweg, Stefan and Hernandez-Lobato, Jose Miguel and Doshi-Velez, Finale and Udluft, Steffen , booktitle =. Decomposition of Uncertainty in. 2018 , publisher =
2018
-
[29]
Position: The No Free Lunch Theorem,
Goldblum, Micah and Finzi, Marc Anton and Rowan, Keefer and Wilson, Andrew Gordon , booktitle =. Position: The No Free Lunch Theorem,. 2024 , editor =
2024
-
[30]
Decomposition of Uncertainty in
Depeweg, Stefan and Hernandez-Lobato, Jose-Miguel and Doshi-Velez, Finale and Udluft, Steffen , booktitle =. Decomposition of Uncertainty in. 2018 , editor =
2018
-
[33]
Proceedings of the 42nd International Conference on Machine Learning , year =
Position: Uncertainty Quantification Needs Reassessment in the Era of Large Language Models , author =. Proceedings of the 42nd International Conference on Machine Learning , year =
-
[34]
and Rowan, Keefer and Wilson, Andrew Gordon , booktitle =
Goldblum, Micah and Finzi, Marc A. and Rowan, Keefer and Wilson, Andrew Gordon , booktitle =. Position: The No Free Lunch Theorem,. 2024 , publisher =
2024
-
[35]
, title =
Banerjee, Abhijit V. , title =. The Quarterly Journal of Economics , year =
-
[36]
Journal of Political Economy , year =
Bikhchandani, Sushil and Hirshleifer, David and Welch, Ivo , title =. Journal of Political Economy , year =
-
[37]
Pathological Outcomes of Observational Learning , journal =
Smith, Lones and S. Pathological Outcomes of Observational Learning , journal =. 2000 , volume =
2000
-
[38]
and Golub, Benjamin , title =
Banerjee, Abhijit and Breza, Emily and Chandrasekhar, Arun G. and Golub, Benjamin , title =. The Review of Economic Studies , year =
-
[39]
and Golub, Benjamin and Yang, He , title =
Chandrasekhar, Arun G. and Golub, Benjamin and Yang, He , title =
-
[40]
, title =
Machamer, Peter and Darden, Lindley and Craver, Carl F. , title =. Philosophy of Science , year =
-
[41]
Woodward, James , title =
-
[42]
Exploring the Whole
Xin, Rui and Zhong, Chudi and Chen, Zhi and Takagi, Takuya and Seltzer, Margo and Rudin, Cynthia , booktitle =. Exploring the Whole
-
[43]
International Conference on Machine Learning , year =
Transformers Learn In-Context by Gradient Descent , author =. International Conference on Machine Learning , year =
-
[44]
Nature , year =
Shumailov, Ilia and Shumaylov, Zakhar and Zhao, Yiren and Papernot, Nicolas and Anderson, Ross and Gal, Yarin , title =. Nature , year =
-
[45]
Proceedings of the 42nd International Conference on Machine Learning , pages =
Position: Uncertainty Quantification Needs Reassessment for Large Language Model Agents , author =. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , editor =
2025
-
[47]
Conformal Prediction = Bayes? , author =. 2025 , journal =. doi:10.48550/arXiv.2512.23308 , url =. 2512.23308 , archivePrefix =
-
[48]
Proceedings of the National Academy of Sciences , year =
Kleinberg, Jon and Raghavan, Manish , title =. Proceedings of the National Academy of Sciences , year =
-
[49]
Proceedings of the 42nd International Conference on Machine Learning , series =
Kirchhof, Michael and Kasneci, Gjergji and Kasneci, Enkelejda , title =. Proceedings of the 42nd International Conference on Machine Learning , series =. 2025 , month = jul, publisher =
2025
-
[50]
Hodel, Damian and West, Jevin D. , title =. arXiv preprint , year =. doi:10.48550/arXiv.2512.15011 , url =. 2512.15011 , archivePrefix =
-
[51]
What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?
Kendall, Alex and Gal, Yarin , title =. Advances in Neural Information Processing Systems , year =. 1703.04977 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods , journal =
H. Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods , journal =. 2021 , volume =
2021
-
[53]
Studies in Subjective Probability , editor =
Bruno de Finetti , title =. Studies in Subjective Probability , editor =. 1964 , note =
1964
-
[54]
Aldous , title =
David J. Aldous , title =. Journal of Multivariate Analysis , year =
-
[55]
Olav Kallenberg , title =
-
[56]
The Annals of Probability , year =
Persi Diaconis and David Freedman , title =. The Annals of Probability , year =
-
[57]
The Annals of Mathematical Statistics , year =
Henry Teicher , title =. The Annals of Mathematical Statistics , year =
-
[58]
Allman and Catherine Matias and John A
Elizabeth S. Allman and Catherine Matias and John A. Rhodes , title =. The Annals of Statistics , year =
-
[59]
ICML , year =
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations , author =. ICML , year =
-
[60]
Kingma and Ricardo Pio Monti and Aapo Hyv
Ilyes Khemakhem and Diederik P. Kingma and Ricardo Pio Monti and Aapo Hyv. Variational Autoencoders and Nonlinear. AISTATS , year =
-
[61]
ICML , year =
Causal Representation Learning Made Identifiable by Grouping of Observational Variables , author =. ICML , year =
-
[62]
Journal of Machine Learning Research , year =
Alexander D'Amour and others , title =. Journal of Machine Learning Research , year =
-
[63]
Calmon and Mario Diaz , title =
Lucas Monteiro Paes and Rodrigo Cruz and Flavio P. Calmon and Mario Diaz , title =. ISIT , year =
-
[64]
ICDT , year =
Kevin Beyer and Jonathan Goldstein and Raghu Ramakrishnan and Uri Shaft , title =. ICDT , year =
-
[65]
Aggarwal and Alexander Hinneburg and Daniel A
Charu C. Aggarwal and Alexander Hinneburg and Daniel A. Keim , title =. ICDT , year =
-
[66]
Advances in Neural Information Processing Systems 15 , year =
Jon Kleinberg , title =. Advances in Neural Information Processing Systems 15 , year =
-
[67]
NeurIPS , year =
Chulhee Yun and Yin Tat Lee and Samuel Wiseman , title =. NeurIPS , year =
-
[68]
Nature Machine Intelligence , year =
Robert Geirhos and others , title =. Nature Machine Intelligence , year =
-
[69]
ICCV , year =
Khalid Mahmood and others , title =. ICCV , year =
-
[70]
Jindong Gu and Yao Qin and Volker Tresp , title =. arXiv:2111.10659 , year =
-
[71]
NeurIPS , year =
Training Compute-Optimal Large Language Models , author =. NeurIPS , year =
-
[72]
Scaling Laws for Neural Language Models
Jared Kaplan and others , title =. arXiv:2001.08361 , year =
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[73]
Causal Inference by Using Invariant Prediction: Identification and Confidence Intervals , journal =
Jonas Peters and Peter B. Causal Inference by Using Invariant Prediction: Identification and Confidence Intervals , journal =. 2016 , volume =
2016
-
[74]
ICLR , year =
Sanghyuk Park and Sungdong Choe and Yiding Jiang and Victor Veitch , title =. ICLR , year =
-
[75]
Fuller , title =
Wayne A. Fuller , title =
-
[76]
Carroll and David Ruppert and Leonard A
Raymond J. Carroll and David Ruppert and Leonard A. Stefanski and Ciprian M. Crainiceanu , title =
-
[77]
Journal of Machine Learning Research , year=
Underspecification Presents Challenges for Credibility in Modern Machine Learning , author=. Journal of Machine Learning Research , year=
-
[79]
Hallucination is Inevitable: An Innate Limitation of Large Language Models
Hallucination is inevitable: An innate limitation of large language models , author=. arXiv preprint arXiv:2401.11817 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
Hallucination is Inevitable for LLMs with the Open World Assumption , author=. 2025 , archivePrefix=. 2510.05116 , primaryClass=
-
[81]
On the Existence of Simpler Machine Learning Models , author=. 2019 , archivePrefix=. 1908.01755 , primaryClass=
-
[82]
Proceedings of the 41st International Conference on Machine Learning , series=
Position: Amazing Things Come From Having Many Good Models , author=. Proceedings of the 41st International Conference on Machine Learning , series=. 2024 , url=
2024
-
[83]
What Uncertainties Do We Need in
Kendall, Alex and Gal, Yarin , year=. What Uncertainties Do We Need in
-
[84]
Proceedings of Machine Learning Research (ICML 2025 Position Paper Track) , year=
Position: Uncertainty Quantification Needs Reassessment for Large-language Model Agents , author=. Proceedings of Machine Learning Research (ICML 2025 Position Paper Track) , year=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.