General Agentic Planning Through Simulative Reasoning with World Models
Pith reviewed 2026-05-22 12:33 UTC · model grok-4.3
The pith
Simulative reasoning with world models enables general agentic planning beyond reactive policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
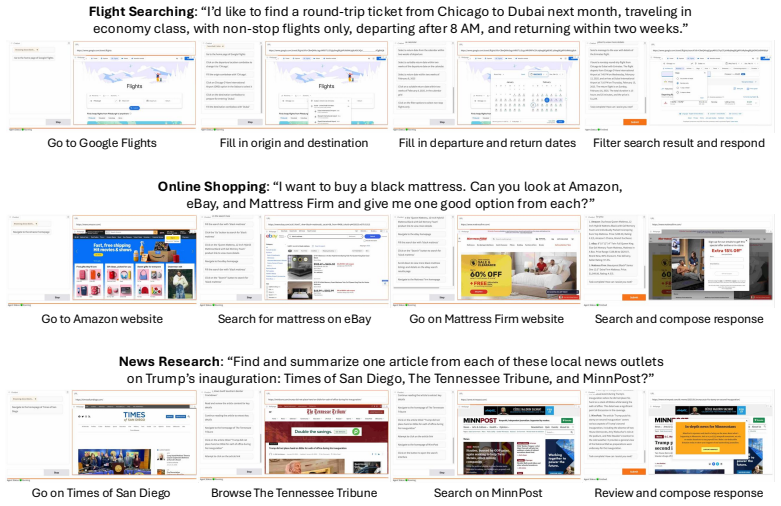
SiRA instantiates simulative reasoning by using an LLM-based world model with natural-language belief states to predict future outcomes of candidate actions before selecting the next step. Across three qualitatively distinct task categories in a web-browser environment, this produces up to 124% higher task completion rates than a matched reactive baseline and raises constrained navigation success from 0% to 32.2% compared with a representative open-web agent. The persistent advantage across task types indicates that the benefit arises from generalizable counterfactual evaluation rather than task-specific tuning.
What carries the argument
SiRA, the Simulative Reasoning Architecture, which maintains natural-language belief states inside an LLM-based world model to support counterfactual evaluation of candidate actions before execution.
If this is right
- Agents achieve higher success rates on complex web tasks by grounding each decision in predicted future states rather than immediate pattern matching.
- The same reasoning capacity transfers across constrained navigation, multi-hop aggregation, and general instruction following without per-task re-engineering.
- Constrained navigation tasks become solvable where purely reactive methods achieve zero success.
- Natural-language belief states make the agent's internal predictions inspectable and reusable across goals.
Where Pith is reading between the lines
- If world-model accuracy improves, the same architecture could transfer to non-web environments such as code execution or robotic control.
- The separation of world-model prediction from action selection suggests a route for combining simulative reasoning with learned policies or search algorithms.
- Natural-language state representations may allow human users to audit or correct the agent's internal model before execution.
Load-bearing premise
The LLM-based world model produces sufficiently accurate natural-language predictions of future states to support effective counterfactual evaluation in the tested web-browser tasks.
What would settle it
Replacing the world-model predictions with inaccurate or random forecasts and observing that task-completion rates fall to the level of the reactive baseline or below.
Figures








read the original abstract
What does it mean to plan? Current agentic systems, whether scaffolded workflows or end-to-end policies, rely on reactive decision-making: selecting the next action via a fixed procedure with at most undifferentiated adaptive computation (e.g., chain-of-thought) lacking explicit modeling of future outcomes. This limits generalizability, as each new task demands re-engineering rather than transfer of shared reasoning capacity. Humans, by contrast, plan by mentally simulating consequences of candidate actions within an internal world model, a capacity known as simulative reasoning (System II) that supports flexible, goal-directed behavior across diverse contexts. We argue that simulative reasoning through a world model provides a general-purpose planning mechanism for agentic systems, improving upon reactive policies (System I) by grounding decisions in predicted future states rather than pattern-matched responses. To verify this, we introduce SiRA (Simulative Reasoning Architecture), a goal-oriented architecture instantiating simulative reasoning using an LLM-based world model with natural-language belief states, while remaining model-agnostic. We evaluate across three qualitatively distinct task categories: constrained navigation, multi-hop information aggregation, and general instruction following, in a web-browser environment. Across all categories, simulative reasoning achieves up to 124% higher task completion rates than a matched reactive baseline, and increases constrained navigation success from 0% to 32.2% compared to a representative open-web agent. The persistent advantage across distinct task types suggests the benefit stems from generalizable counterfactual evaluation rather than task-specific tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SiRA (Simulative Reasoning Architecture), a model-agnostic goal-oriented framework that performs agentic planning via simulative reasoning over an LLM-based world model with natural-language belief states. It contrasts this explicit counterfactual evaluation of future outcomes against reactive (System I) policies that rely on pattern-matched next-action selection without internal simulation. The approach is evaluated on three distinct task categories in a web-browser environment—constrained navigation, multi-hop information aggregation, and general instruction following—reporting up to 124% higher task completion rates than a matched reactive baseline and lifting constrained navigation success from 0% to 32.2% relative to a representative open-web agent. The authors argue that the persistent cross-category gains indicate a generalizable benefit from grounded simulation rather than task-specific tuning.
Significance. If the performance advantages can be causally attributed to accurate simulative reasoning rather than ancillary factors, the work offers a promising general-purpose mechanism for improving transfer and flexibility in agentic systems beyond current scaffolded or end-to-end reactive approaches. The model-agnostic design and evaluation across qualitatively different task types are constructive elements that support broader applicability claims.
major comments (2)
- [Experimental results and analysis sections] Experimental results and analysis sections: No direct measurement or error analysis of the LLM world model's natural-language future-state prediction accuracy (e.g., state match rate, trajectory-level fidelity, or held-out prediction error) is reported. This is load-bearing for the central claim that gains arise from reliable counterfactual evaluation, because without evidence that the predicted states are sufficiently faithful to actual dynamic web-browser states, the 124% completion improvement and 0%-to-32.2% navigation lift could instead result from extra inference steps, prompt structure, or implicit search.
- [Baseline and evaluation protocol] Baseline and evaluation protocol: The manuscript provides insufficient detail on run counts, variance, exact matching of reactive baselines (including total LLM calls and prompt length), and controls for model scale or compute budget. These omissions undermine interpretation of the reported percentage gains, as simulative reasoning inherently involves additional forward simulation steps whose contribution must be isolated from confounding factors.
minor comments (2)
- [Method] Notation for belief states and world-model outputs could be formalized more explicitly (e.g., with a consistent mathematical description) to aid reproducibility.
- [Results figures] Figure captions and axis labels in the results figures would benefit from explicit indication of error bars or trial counts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional evidence and transparency can strengthen the attribution of gains to simulative reasoning. We address each major comment below and will incorporate revisions to improve the manuscript.
read point-by-point responses
-
Referee: Experimental results and analysis sections: No direct measurement or error analysis of the LLM world model's natural-language future-state prediction accuracy (e.g., state match rate, trajectory-level fidelity, or held-out prediction error) is reported. This is load-bearing for the central claim that gains arise from reliable counterfactual evaluation, because without evidence that the predicted states are sufficiently faithful to actual dynamic web-browser states, the 124% completion improvement and 0%-to-32.2% navigation lift could instead result from extra inference steps, prompt structure, or implicit search.
Authors: We agree that direct metrics on the world model's predictive accuracy would provide stronger causal support for the role of simulative reasoning. While the manuscript prioritizes end-to-end task performance across diverse categories as evidence of generalizability, we recognize this as a valuable addition. In revision, we will add an analysis subsection reporting state prediction accuracy on held-out trajectories, including state match rates, trajectory-level fidelity, and examples of prediction errors. revision: yes
-
Referee: Baseline and evaluation protocol: The manuscript provides insufficient detail on run counts, variance, exact matching of reactive baselines (including total LLM calls and prompt length), and controls for model scale or compute budget. These omissions undermine interpretation of the reported percentage gains, as simulative reasoning inherently involves additional forward simulation steps whose contribution must be isolated from confounding factors.
Authors: We appreciate the call for greater experimental detail. The current version reports comparative results but omits full statistical and matching information. We will revise the evaluation section to specify the number of independent runs per task, report variance via standard deviations, confirm equivalent total LLM calls and prompt lengths for the reactive baseline, and explicitly note that all methods share the same underlying LLM to control for scale and compute budget. revision: yes
Circularity Check
No significant circularity; empirical comparison to baselines is independent of fitted parameters or self-referential definitions
full rationale
The paper introduces the SiRA architecture to instantiate simulative reasoning via an LLM-based world model and reports empirical performance gains (up to 124% higher task completion, 0% to 32.2% navigation success) from direct comparison against matched reactive and open-web agent baselines across three task categories. No equations, fitted parameters, or self-citations are described that would reduce the reported advantage to a construction by definition or to a renamed input. The central claim rests on external experimental benchmarks rather than internal redefinition or load-bearing self-reference, making the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can maintain accurate enough natural-language belief states to support useful simulative reasoning about future outcomes.
invented entities (1)
-
SiRA architecture
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SIMURA ... world model f ... predicts the next belief state ŝ_{t+1} ... natural language as a compact but complete representation
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hierarchical architecture that isolates perception, simulative planning, and action selection
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Efficient Agentic Reasoning Through Self-Regulated Simulative Planning
SR²AM achieves competitive Pass@1 accuracy on diverse tasks with 25.8-95.3% fewer reasoning tokens than much larger models by using self-regulated simulative planning trained via supervised learning and RL.
-
GUI Agents with Reinforcement Learning: Toward Digital Inhabitants
The paper delivers the first comprehensive overview of RL for GUI agents, organizing methods into offline, online, and hybrid strategies while analyzing trends in rewards, efficiency, and deliberation to outline a fut...
Reference graph
Works this paper leans on
- [1]
-
[2]
DeepMind. Project mariner. https://deepmind.google/models/project-mariner/,
-
[3]
Accessed: 2025-07-16
work page 2025
-
[4]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments, 2024
work page 2024
-
[6]
OpenAI. Introducing Deep Research. https://openai.com/index/ introducing-deep-research/, February 2025. Deep Research agent release an- nouncement
work page 2025
-
[7]
Anthropic. Introducing computer use, a new claude 3.5 sonnet, and claude 3.5 haiku. https: //www.anthropic.com/news/3-5-models-and-computer-use , October 22 2024. Public beta “computer use” feature for Claude 3.5 Sonnet
work page 2024
-
[8]
Gemini Deep Research: Your Personal Research Assistant
Google. Gemini Deep Research: Your Personal Research Assistant. https://gemini. google/overview/deep-research/?hl=en, December 2024. Overview of Gemini Deep Research agent feature
work page 2024
-
[9]
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior, 2023. 14
work page 2023
-
[10]
Anysphere Inc. Cursor: The ai code editor. https://cursor.com, 2025. Accessed: 2025-07- 16
work page 2025
-
[11]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. Openhands: An open platform for ai soft...
work page 2025
-
[12]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, Khaled Saab, Dan Popovici, Jacob Blum, Fan Zhang, Katherine Chou, Avinatan Hassidim, Burak Gokturk, Amin Vahdat, Pushmeet Kohli, Yossi Matias, Andrew Carroll, Kavita Kulkarni, Nenad Tomasev, Yuan Guan, Vi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search, 2025
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search, 2025
work page 2025
-
[14]
Bang Liu, Xinfeng Li, Jiayi Zhang, Jinlin Wang, Tanjin He, Sirui Hong, Hongzhang Liu, Shaokun Zhang, Kaitao Song, Kunlun Zhu, Yuheng Cheng, Suyuchen Wang, Xiaoqiang Wang, Yuyu Luo, Haibo Jin, Peiyan Zhang, Ollie Liu, Jiaqi Chen, Huan Zhang, Zhaoyang Yu, Haochen Shi, Boyan Li, Dekun Wu, Fengwei Teng, Xiaojun Jia, Jiawei Xu, Jinyu Xiang, Yizhang Lin, Tianmi...
work page 2025
-
[15]
Roy-Chowdhury, and Chengyu Song
Trishna Chakraborty, Udita Ghosh, Xiaopan Zhang, Fahim Faisal Niloy, Yue Dong, Jiachen Li, Amit K. Roy-Chowdhury, and Chengyu Song. Heal: An empirical study on hallucinations in embodied agents driven by large language models, 2025
work page 2025
-
[16]
The general-purpose intelligent agent.Engineering, 6(3):221–226, 2020
Cewu Lu and Shiquan Wang. The general-purpose intelligent agent.Engineering, 6(3):221–226, 2020
work page 2020
-
[17]
Language models as agent models, 2022
Jacob Andreas. Language models as agent models, 2022
work page 2022
-
[18]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[19]
A path towards autonomous machine intelligence
Yann LeCun. A path towards autonomous machine intelligence. OpenReview preprint, June
-
[20]
Version 0.9.2, June 27 2022
work page 2022
-
[21]
Shibo Hao, Yi Gu, Haotian Luo, Tianyang Liu, Xiyan Shao, Xinyuan Wang, Shuhua Xie, Haodi Ma, Adithya Samavedhi, Qiyue Gao, et al. Llm reasoners: New evaluation, library, and analysis of step-by-step reasoning with large language models.arXiv preprint arXiv:2404.05221, 2024
-
[22]
Brandon Chiou, Mason Choey, Mingkai Deng, Jinyu Hou, Jackie Wang, Ariel Wu, Frank Xu, Zhiting Hu, Hongxia Jin, Li Erran Li, Graham Neubig, Yilin Shen, and Eric P. Xing. Reasoneragent: A fully open source, ready-to-run agent that does research in a web browser and answers your queries, February 2025
work page 2025
-
[23]
Autowebglm: A large language model-based web navigating agent, 2024
Hanyu Lai, Xiao Liu, Iat Long Iong, Shuntian Yao, Yuxuan Chen, Pengbo Shen, Hao Yu, Hanchen Zhang, Xiaohan Zhang, Yuxiao Dong, and Jie Tang. Autowebglm: A large language model-based web navigating agent, 2024
work page 2024
-
[24]
Agent q: Advanced reasoning and learning for autonomous ai agents, 2024
Pranav Putta, Edmund Mills, Naman Garg, Sumeet Motwani, Chelsea Finn, Divyansh Garg, and Rafael Rafailov. Agent q: Advanced reasoning and learning for autonomous ai agents, 2024. 15
work page 2024
-
[25]
Ui-tars: Pioneering automated gui interaction with native agents, 2025
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, Wanjun Zhong, Kuanye Li, Jiale Yang, Yu Miao, Woyu Lin, Longxiang Liu, Xu Jiang, Qianli Ma, Jingyu Li, Xiaojun Xiao, Kai Cai, Chuang Li, Yaowei Zheng, Chaolin Jin, Chen Li, Xiao Zhou, Minchao Wang, Haoli Chen, Zhaojian Li, Haihua Ya...
work page 2025
-
[26]
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory, 2024
work page 2024
-
[27]
V oyager: An open-ended embodied agent with large language models, 2023
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models, 2023
work page 2023
-
[28]
Hyungjoo Chae, Namyoung Kim, Kai Tzu-iunn Ong, Minju Gwak, Gwanwoo Song, Jihoon Kim, Sunghwan Kim, Dongha Lee, and Jinyoung Yeo. Web agents with world models: Learning and leveraging environment dynamics in web navigation.arXiv preprint arXiv:2410.13232, 2024
-
[29]
Action- conditional video prediction using deep networks in atari games, 2015
Junhyuk Oh, Xiaoxiao Guo, Honglak Lee, Richard Lewis, and Satinder Singh. Action- conditional video prediction using deep networks in atari games, 2015
work page 2015
-
[30]
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy Lillicrap, and David Silver. Mastering atari, go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, December 2020
work page 2020
-
[31]
When to trust your model: Model-based policy optimization, 2021
Michael Janner, Justin Fu, Marvin Zhang, and Sergey Levine. When to trust your model: Model-based policy optimization, 2021
work page 2021
-
[32]
Temporal difference learning for model predictive control, 2022
Nicklas Hansen, Xiaolong Wang, and Hao Su. Temporal difference learning for model predictive control, 2022
work page 2022
-
[33]
Reasoning with language model is planning with world model, 2023
Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. Reasoning with language model is planning with world model, 2023
work page 2023
-
[34]
Mastering diverse domains through world models, 2024
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models, 2024
work page 2024
-
[35]
Is your llm secretly a world model of the internet? model-based planning for web agents, 2025
Yu Gu, Kai Zhang, Yuting Ning, Boyuan Zheng, Boyu Gou, Tianci Xue, Cheng Chang, Sanjari Srivastava, Yanan Xie, Peng Qi, Huan Sun, and Yu Su. Is your llm secretly a world model of the internet? model-based planning for web agents, 2025
work page 2025
-
[36]
Lisa Feldman Barrett.How emotions are made: The secret life of the brain. Pan Macmillan, 2017
work page 2017
-
[37]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. OpenHands: An Open Platform for AI Soft...
work page 2024
-
[38]
Webvoyager: Building an end-to-end web agent with large multimodal models, 2024
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models, 2024
work page 2024
-
[39]
Cogagent: A visual language model for gui agents, 2024
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxuan Zhang, Juanzi Li, Bin Xu, Yuxiao Dong, Ming Ding, and Jie Tang. Cogagent: A visual language model for gui agents, 2024
work page 2024
-
[40]
A real-world webagent with planning, long context understanding, and program synthesis, 2024
Izzeddin Gur, Hiroki Furuta, Austin Huang, Mustafa Safdari, Yutaka Matsuo, Douglas Eck, and Aleksandra Faust. A real-world webagent with planning, long context understanding, and program synthesis, 2024. 16
work page 2024
-
[41]
Reinforcement learning on web interfaces using workflow-guided exploration
Evan Zheran Liu, Kelvin Guu, Panupong Pasupat, Tianlin Shi, and Percy Liang. Reinforcement learning on web interfaces using workflow-guided exploration. InInternational Conference on Learning Representations (ICLR), 2018
work page 2018
-
[42]
Mind2web: Towards a generalist agent for the web, 2023
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web, 2023
work page 2023
-
[43]
Webshop: Towards scalable real-world web interaction with grounded language agents, 2023
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents, 2023
work page 2023
-
[44]
Mengkang Hu, Yuhang Zhou, Wendong Fan, Yuzhou Nie, Bowei Xia, Tao Sun, Ziyu Ye, Zhaoxuan Jin, Yingru Li, Qiguang Chen, Zeyu Zhang, Yifeng Wang, Qianshuo Ye, Bernard Ghanem, Ping Luo, and Guohao Li. Owl: Optimized workforce learning for general multi-agent assistance in real-world task automation, 2025
work page 2025
-
[45]
Long term memory: The foundation of ai self-evolution, 2025
Xun Jiang, Feng Li, Han Zhao, Jiahao Qiu, Jiaying Wang, Jun Shao, Shihao Xu, Shu Zhang, Weiling Chen, Xavier Tang, Yize Chen, Mengyue Wu, Weizhi Ma, Mengdi Wang, and Tianqiao Chen. Long term memory: The foundation of ai self-evolution, 2025
work page 2025
-
[46]
Agentorchestra: A hierarchical multi-agent framework for general-purpose task solving, 2025
Wentao Zhang, Ce Cui, Yilei Zhao, Rui Hu, Yang Liu, Yahui Zhou, and Bo An. Agentorchestra: A hierarchical multi-agent framework for general-purpose task solving, 2025
work page 2025
-
[47]
Magentic-one: A generalist multi-agent system for solving complex tasks, 2024
Adam Fourney, Gagan Bansal, Hussein Mozannar, Cheng Tan, Eduardo Salinas, Erkang, Zhu, Friederike Niedtner, Grace Proebsting, Griffin Bassman, Jack Gerrits, Jacob Alber, Peter Chang, Ricky Loynd, Robert West, Victor Dibia, Ahmed Awadallah, Ece Kamar, Rafah Hosn, and Saleema Amershi. Magentic-one: A generalist multi-agent system for solving complex tasks, 2024
work page 2024
-
[48]
Executable code actions elicit better llm agents, 2024
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better llm agents, 2024
work page 2024
-
[49]
‘smolagents‘: a smol library to build great agentic systems
Aymeric Roucher, Albert Villanova del Moral, Thomas Wolf, Leandro von Werra, and Erik Kaunismäki. ‘smolagents‘: a smol library to build great agentic systems. https://github. com/huggingface/smolagents, 2025
work page 2025
-
[50]
Jiahao Qiu, Xuan Qi, Tongcheng Zhang, Xinzhe Juan, Jiacheng Guo, Yifu Lu, Yimin Wang, Zixin Yao, Qihan Ren, Xun Jiang, Xing Zhou, Dongrui Liu, Ling Yang, Yue Wu, Kaixuan Huang, Shilong Liu, Hongru Wang, and Mengdi Wang. Alita: Generalist agent enabling scalable agentic reasoning with minimal predefinition and maximal self-evolution, 2025
work page 2025
-
[51]
Critiques of world models.arXiv preprint arXiv:2507.05169, 2025
Eric Xing, Mingkai Deng, Jinyu Hou, and Zhiting Hu. Critiques of world models.arXiv preprint arXiv:2507.05169, 2025
-
[52]
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
work page 1998
- [53]
-
[54]
Mas- tering the game of go with deep neural networks and tree search.nature, 529(7587):484–489, 2016
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driess- che, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mas- tering the game of go with deep neural networks and tree search.nature, 529(7587):484–489, 2016
work page 2016
-
[55]
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, et al. Mastering chess and shogi by self-play with a general reinforcement learning algorithm.arXiv preprint arXiv:1712.01815, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[56]
Richard S Sutton. Dyna, an integrated architecture for learning, planning, and reacting.ACM Sigart Bulletin, 2(4):160–163, 1991
work page 1991
-
[57]
Language models, agent models, and world models: The law for machine reasoning and planning,
Zhiting Hu and Tianmin Shu. Language models, agent models, and world models: The law for machine reasoning and planning.arXiv preprint arXiv:2312.05230, 2023. 17
-
[58]
OpenAI. Introducing chatgpt search. https://openai.com/index/ introducing-chatgpt-search/, 2024. Accessed: 2024-12-19
work page 2024
-
[59]
Getting started with perplexity
Perplexity. Getting started with perplexity. https://www.perplexity.ai/hub/blog/ getting-started-with-perplexity, 2024. Accessed: 2024-12-19
work page 2024
-
[60]
Yu Gu, Boyuan Zheng, Boyu Gou, Kai Zhang, Cheng Chang, Sanjari Srivastava, Yanan Xie, Peng Qi, Huan Sun, and Yu Su. Is your llm secretly a world model of the internet? model-based planning for web agents.arXiv preprint arXiv:2411.06559, 2024
-
[61]
Tree search for language model agents.arXiv preprint arXiv:2407.01476, 2024
Jing Yu Koh, Stephen McAleer, Daniel Fried, and Ruslan Salakhutdinov. Tree search for language model agents.arXiv preprint arXiv:2407.01476, 2024
-
[62]
Advances in neural information processing systems, 36:11809–11822
Ori Yoran, Samuel Joseph Amouyal, Chaitanya Malaviya, Ben Bogin, Ofir Press, and Jonathan Berant. Assistantbench: Can web agents solve realistic and time-consuming tasks?arXiv preprint arXiv:2407.15711, 2024
-
[63]
Mingkai Deng, Bowen Tan, Zhengzhong Liu, Eric P Xing, and Zhiting Hu. Compression, transduction, and creation: A unified framework for evaluating natural language generation. arXiv preprint arXiv:2109.06379, 2021
-
[64]
G- eval: NLG evaluation using gpt-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G- eval: NLG evaluation using gpt-4 with better human alignment. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511–2522, Singapore, December 2023. Association for Computational...
work page 2023
-
[65]
Laradji, Manuel Del Verme, Tom Marty, David Vazquez, Nicolas Chapados, and Alexandre Lacoste
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, David Vazquez, Nicolas Chapados, and Alexandre Lacoste. WorkArena: How capable are web agents at solving common knowledge work tasks? In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, ed...
work page 2024
-
[66]
FanOutQA: A multi-hop, multi-document question answering benchmark for large language models
Andrew Zhu, Alyssa Hwang, Liam Dugan, and Chris Callison-Burch. FanOutQA: A multi-hop, multi-document question answering benchmark for large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 2: Short Papers), pages 18–37, Bangkok, Thai...
work page 2024
-
[67]
button ’Main menu’, clickable, expanded=False
-
[68]
link ’Google’, clickable StaticText ’Skip to main content’ StaticText ’Accessibility feedback’
-
[69]
link ’Vacation rentals’
-
[70]
button ’Change appearance’, hasPopup=’menu’, expanded=False
-
[71]
button ’Google apps’, clickable, expanded=False
-
[72]
link ’Sign in’, clickable
-
[73]
image ’’ StaticText ’Flights’
-
[74]
combobox ’Change ticket type. \u200bRound trip’, live=’polite’, relevant=’additions text’, hasPopup=’listbox’, expanded=False, controls=’i9’
-
[75]
button ’1 passenger, change number of passengers.’, hasPopup=’dialog’
-
[76]
combobox ’Change seating class. \u200bEconomy’, live=’polite’, relevant=’additions text’, hasPopup=’listbox’, expanded=False, controls=’i22’
-
[77]
combobox ’Where from?’ value=’Pittsburgh’, clickable, autocomplete=’inline’, hasPopup=’menu’, expanded=False
-
[78]
button ’Swap origin and destination.’, disabled=True
-
[79]
combobox ’Where to?’, clickable, focused, autocomplete=’inline’, hasPopup=’menu’, expanded=False
-
[80]
image ’’ generic ’’, hidden=True
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.