SurgVLA-Bench: Towards Evaluating Vision-Language-Action Models for Laparoscopic Surgical Robotics
Pith reviewed 2026-06-30 07:41 UTC · model grok-4.3
The pith
SurgVLA-Bench shows current VLA models remain limited by endoscopic view constraints in laparoscopic robotics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SurgVLA-Bench establishes a simulation-based benchmark on the SurRoL platform that includes a hierarchical task taxonomy and multi-dimensional scoring, and demonstrates that autoregressive VLA models tend to excel in semantic consistency while flow-matching models tend to achieve higher action precision, yet all tested models fall short because of the constrained endoscopic field of view, restricted angles, and frequent occlusions.
What carries the argument
SurgVLA-Bench, a benchmark platform that organizes laparoscopic tasks hierarchically from atomic actions to complete procedures and applies multi-dimensional scoring for accuracy and semantic consistency.
Load-bearing premise
The SurRoL simulation environment together with the authors' task hierarchy and scoring rules capture the essential difficulties and success criteria of real laparoscopic procedures.
What would settle it
Running the same evaluated VLA models on physical laparoscopic robots and observing success rates that exceed the simulation shortfalls would falsify the claim that view constraints remain fundamental bottlenecks.
Figures

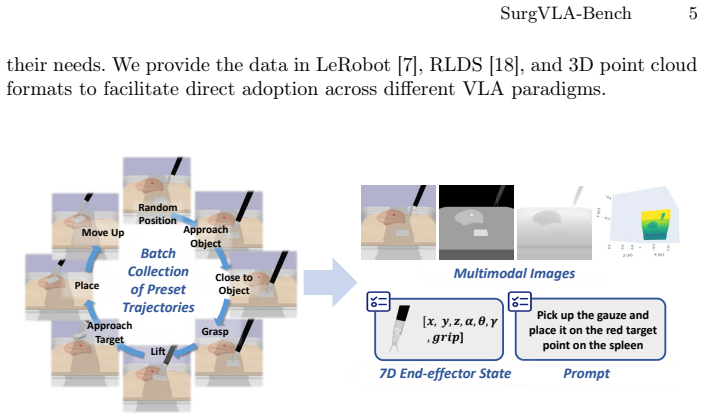
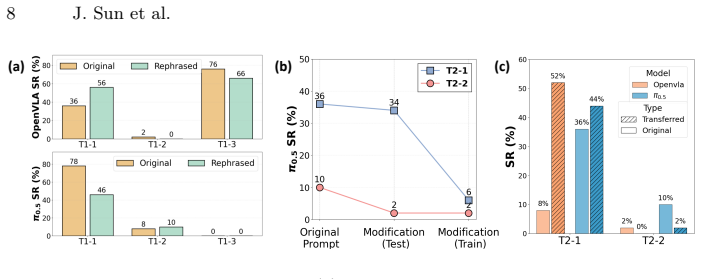
read the original abstract
Vision-Language-Action (VLA) models represent a promising direction for embodied intelligence in surgical robotics. Despite the prevalence of VLA benchmarks for general robotics, standardized evaluation platforms specifically designed for surgical contexts remain absent. To address this limitation, we present SurgVLA-Bench, the first comprehensive benchmark for evaluating VLA models in laparoscopic surgical robotics. Leveraging the SurRoL simulation platform, we construct a hierarchical task taxonomy ranging from atomic actions to complete surgical procedures, complemented by a multi-dimensional evaluation framework assessing action accuracy and semantic consistency. We then systematically evaluate two representative paradigms, including autoregressive models such as OpenVLA, and flow matching models such as $\pi_{0}$, $\pi_{0.5}$, and SmolVLA. Our experiments show that autoregressive models tend to excel in semantic understanding, while flow matching models often achieve higher task precision but may face generalization trade-offs. However, even the best-performing models remain far from satisfactory, as the constrained endoscopic field of view, restricted viewing angles, and frequent occlusions persist as fundamental physical bottlenecks. The code and data are available at https://github.com/VCL-HNU/SurgVLA
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SurgVLA-Bench as the first comprehensive benchmark for Vision-Language-Action (VLA) models in laparoscopic surgical robotics, built on the SurRoL simulator. It defines a hierarchical task taxonomy from atomic actions to full procedures and a multi-dimensional evaluation framework measuring action accuracy and semantic consistency. The work evaluates autoregressive models (e.g., OpenVLA) and flow-matching models (e.g., π₀, π₀.₅, SmolVLA), reporting that autoregressive models perform better on semantic tasks while flow-matching models achieve higher precision at the cost of generalization. The central conclusion is that even the strongest models fall short, with failures attributed to irreducible physical constraints including constrained endoscopic field of view, restricted viewing angles, and frequent occlusions. Code and data are released.
Significance. If the benchmark's simulation fidelity, task taxonomy, and scoring framework prove representative of real laparoscopic procedures, the work would fill a clear gap by providing the first standardized evaluation platform for VLA models in surgery. The release of code and data supports reproducibility. The empirical comparison between model paradigms is useful for the community, though the attribution of performance gaps specifically to physical bottlenecks requires additional validation to be fully actionable.
major comments (2)
- [Conclusion / Experiments] Conclusion / Experiments section: The claim that 'the constrained endoscopic field of view, restricted viewing angles, and frequent occlusions persist as fundamental physical bottlenecks' is not supported by ablations that isolate these factors (e.g., varying FOV or occlusion parameters while holding model and task fixed), quantitative sim-to-real image statistics, or any mapping of the multi-dimensional scores to clinical outcomes such as tissue damage or procedure time. Without these, the attribution of model shortfalls to irreducible physical constraints rather than benchmark design, model capacity, or training data cannot be secured.
- [Evaluation framework] Evaluation framework description: The multi-dimensional scoring framework (action accuracy + semantic consistency) and hierarchical taxonomy are presented as capturing essential surgical difficulties, yet no validation is provided against real laparoscopic data or expert clinical metrics, leaving open whether the observed performance ceilings reflect simulation artifacts rather than true task demands.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from explicit quantitative metrics (e.g., success rates, error bars) rather than qualitative statements about model performance differences.
- [Experiments] Baseline details (training data, fine-tuning procedures, exact task instances) are referenced but not fully enumerated in the provided summary; ensure these are tabulated for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and limitations of our benchmark. We respond to each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Conclusion / Experiments] Conclusion / Experiments section: The claim that 'the constrained endoscopic field of view, restricted viewing angles, and frequent occlusions persist as fundamental physical bottlenecks' is not supported by ablations that isolate these factors (e.g., varying FOV or occlusion parameters while holding model and task fixed), quantitative sim-to-real image statistics, or any mapping of the multi-dimensional scores to clinical outcomes such as tissue damage or procedure time. Without these, the attribution of model shortfalls to irreducible physical constraints rather than benchmark design, model capacity, or training data cannot be secured.
Authors: We agree that the attribution in the conclusion relies on observed failure modes within the SurRoL environment rather than controlled ablations or quantitative mappings to clinical metrics. The current experiments demonstrate consistent shortfalls across models under the simulator's fixed endoscopic constraints, but do not isolate individual factors. In the revised manuscript we will qualify this statement as an observed hypothesis supported by the benchmark results and add an explicit limitations paragraph noting the absence of such isolating experiments and clinical outcome mappings. We view full validation of this hypothesis as valuable future work beyond the scope of establishing the initial benchmark. revision: partial
-
Referee: [Evaluation framework] Evaluation framework description: The multi-dimensional scoring framework (action accuracy + semantic consistency) and hierarchical taxonomy are presented as capturing essential surgical difficulties, yet no validation is provided against real laparoscopic data or expert clinical metrics, leaving open whether the observed performance ceilings reflect simulation artifacts rather than true task demands.
Authors: The taxonomy and scoring dimensions were derived from standard surgical procedure decompositions in the literature and the SurRoL task structure. We acknowledge the lack of direct empirical validation against real laparoscopic recordings or surgeon-rated clinical metrics. This is a recognized limitation of simulation-first benchmarks. In revision we will expand the limitations section to state this explicitly and outline planned directions for expert review and sim-to-real correlation studies. revision: yes
Circularity Check
No circularity: benchmark construction and empirical evaluation only
full rationale
The paper presents SurgVLA-Bench as a new evaluation platform built on the external SurRoL simulator, defines a task taxonomy and scoring framework, then reports empirical results on existing VLA models (OpenVLA, π0, etc.). No equations, fitted parameters, predictions derived from inputs, or self-citations appear in the provided text. The central claim about physical bottlenecks is an interpretive summary of observed performance gaps rather than a derivation that reduces to the benchmark design itself. The work is self-contained against external simulation and models, with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Annual Review of Control, Robotics, and Autonomous Systems 4(1), 651–679 (2021)
Attanasio, A., Scaglioni, B., De Momi, E., Fiorini, P., Valdastri, P.: Autonomy in surgical robotics. Annual Review of Control, Robotics, and Autonomous Systems 4(1), 651–679 (2021)
2021
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al.:π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
RynnVLA-002: A Unified Vision-Language-Action and World Model
Cen, J., Huang, S., Yuan, Y., Li, K., Yuan, H., Yu, C., Jiang, Y., Guo, J., Li, X., Luo, H., et al.: Rynnvla-002: A unified vision-language-action and world model. arXiv preprint arXiv:2511.17502 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
https://pybullet.org (2016)
Coumans, E., Bai, Y.: Pybullet, a python module for physics simulation for games, robotics and machine learning. https://pybullet.org (2016)
2016
-
[5]
Driess, D., Xia, F., Sajjadi, M.S., Lynch, C., Chowdhery, A., Wahid, A., Tompson, J.,Vuong,Q.,Yu,T.,Huang,W.,etal.:Palm-e:Anembodiedmultimodallanguage model (2023)
2023
-
[6]
In: International Conference on Learning Representations (2022), https://openreview.net/forum?id=nZeVKeeFYf9
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language mod- els. In: International Conference on Learning Representations (2022), https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[7]
https://github.com/huggingface/lerobot (2024), version 0.4+ includes v3.0 dataset format
Hugging Face Team: LeRobot: A Library for Real-World Robot Learning. https://github.com/huggingface/lerobot (2024), version 0.4+ includes v3.0 dataset format
2024
-
[8]
Intelligence, P., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., et al.:π 0.5: a vision-language-action model with open-world generalization.π 0.5: a vision-language-action model with open-world generalization (2025)
2025
-
[9]
IEEE Robotics and Automation Letters5(2), 3019– 3026 (2020)
James, S., Ma, Z., Arrojo, D.R., Davison, A.J.: Rlbench: The robot learning bench- mark & learning environment. IEEE Robotics and Automation Letters5(2), 3019– 3026 (2020)
2020
- [10]
-
[11]
arXiv preprint arXiv:2407.12998 (2024)
Kim, J.W., Zhao, T.Z., Schmidgall, S., Deguet, A., Kobilarov, M., Finn, C., Krieger, A.: Surgical robot transformer (srt): Imitation learning for surgical tasks. arXiv preprint arXiv:2407.12998 (2024)
-
[12]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., et al.: Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246 (2024) 10 J. Sun et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
arXiv preprint arXiv:2503.05777 (2025)
Kim, Y., Jeong, H., Chen, S., Li, S.S., Park, C., Lu, M., Alhamoud, K., Mun, J., Grau, C., Jung, M., et al.: Medical hallucinations in foundation models and their impact on healthcare. arXiv preprint arXiv:2503.05777 (2025)
-
[14]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Advances in Neural Information Processing Systems36, 44776–44791 (2023)
Liu, B., Zhu, Y., Gao, C., Feng, Y., Liu, Q., Zhu, Y., Stone, P.: Libero: Benchmark- ing knowledge transfer for lifelong robot learning. Advances in Neural Information Processing Systems36, 44776–44791 (2023)
2023
-
[16]
IEEE Robotics and Automation Letters7(3), 7327–7334 (2022)
Mees, O., Hermann, L., Rosete-Beas, E., Burgard, W.: Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks. IEEE Robotics and Automation Letters7(3), 7327–7334 (2022)
2022
-
[17]
Medical Image Analysis86, 102803 (2023)
Nwoye, C.I., Alapatt, D., Yu, T., Vardazaryan, A., Xia, F., Zhao, Z., Xia, T., Jia, F., Yang, Y., Wang, H., et al.: Cholectriplet2021: A benchmark challenge for surgical action triplet recognition. Medical Image Analysis86, 102803 (2023)
2023
-
[18]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
O’Neill, A., Rehman, A., Maddukuri, A., Gupta, A., Padalkar, A., Lee, A., Pooley, A., Gupta, A., Mandlekar, A., Jain, A., et al.: Open x-embodiment: Robotic learn- ing datasets and rt-x models: Open x-embodiment collaboration 0. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 6892–6903. IEEE (2024)
2024
-
[19]
In: 2021 interna- tional symposium on medical robotics (ISMR)
Pore, A., Tagliabue, E., Piccinelli, M., Dall’Alba, D., Casals, A., Fiorini, P.: Learn- ing from demonstrations for autonomous soft-tissue retraction. In: 2021 interna- tional symposium on medical robotics (ISMR). pp. 1–7. IEEE (2021)
2021
-
[20]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Shukor, M., Aubakirova, D., Capuano, F., Kooijmans, P., Palma, S., Zoui- tine, A., Aractingi, M., Pascal, C., Russi, M., Marafioti, A., et al.: Smolvla: A vision-language-action model for affordable and efficient robotics. arXiv preprint arXiv:2506.01844 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Bull Am Coll Surg93(9), 30–32 (2008)
Soper, N.J., Fried, G.M.: The fundamentals of laparoscopic surgery: its time has come. Bull Am Coll Surg93(9), 30–32 (2008)
2008
-
[22]
IEEE transactions on medical imaging36(1), 86–97 (2016)
Twinanda, A.P., Shehata, S., Mutter, D., Marescaux, J., De Mathelin, M., Padoy, N.: Endonet: a deep architecture for recognition tasks on laparoscopic videos. IEEE transactions on medical imaging36(1), 86–97 (2016)
2016
-
[23]
arXiv preprint arXiv:2509.09372 (2025)
Wang, Y., Ding, P., Li, L., Cui, C., Ge, Z., Tong, X., Song, W., Zhao, H., Zhao, W., Hou, P., et al.: Vla-adapter: An effective paradigm for tiny-scale vision-language- action model. arXiv preprint arXiv:2509.09372 (2025)
-
[24]
In: 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Xu, J., Li, B., Lu, B., Liu, Y.H., Dou, Q., Heng, P.A.: Surrol: An open-source reinforcement learning centered and dvrk compatible platform for surgical robot learning. In: 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 1821–1828. IEEE (2021)
2021
-
[25]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
Yu, Q., Moghani, M., Dharmarajan, K., Schorp, V., Panitch, W.C.H., Liu, J., Hari, K., Huang, H., Mittal, M., Goldberg, K., et al.: Orbit-surgical: An open-simulation framework for learning surgical augmented dexterity. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 15509–15516. IEEE (2024)
2024
-
[26]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Yuan, K., Srivastav, V., Navab, N., Padoy, N.: Hecvl: Hierarchical video-language pretraining for zero-shot surgical phase recognition. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 306–316. Springer (2024)
2024
-
[27]
arXiv preprint arXiv:2509.19012 (2025)
Zhang, D., Sun, J., Hu, C., Wu, X., Yuan, Z., Zhou, R., Shen, F., Zhou, Q.: Pure vision language action (vla) models: A comprehensive survey. arXiv preprint arXiv:2509.19012 (2025)
-
[28]
ICML (2025) SurgVLA-Bench 11
Zhuoling, L., Liangliang, R., Jinrong, Y., Yong, Z., et al.: Vip: Vision instructed pre-training for robotic manipulation. ICML (2025) SurgVLA-Bench 11
2025
-
[29]
In: Conference on Robot Learning
Zitkovich, B., Yu, T., Xu, S., Xu, P., Xiao, T., Xia, F., Wu, J., Wohlhart, P., Welker, S., Wahid, A., et al.: Rt-2: Vision-language-action models transfer web knowledge to robotic control. In: Conference on Robot Learning. pp. 2165–2183. PMLR (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.