Intelligence per Watt: Measuring Intelligence Efficiency of Local AI
Pith reviewed 2026-05-22 12:16 UTC · model grok-4.3
The pith
Local models answer 88.7 percent of real queries while delivering higher intelligence per watt than cloud accelerators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
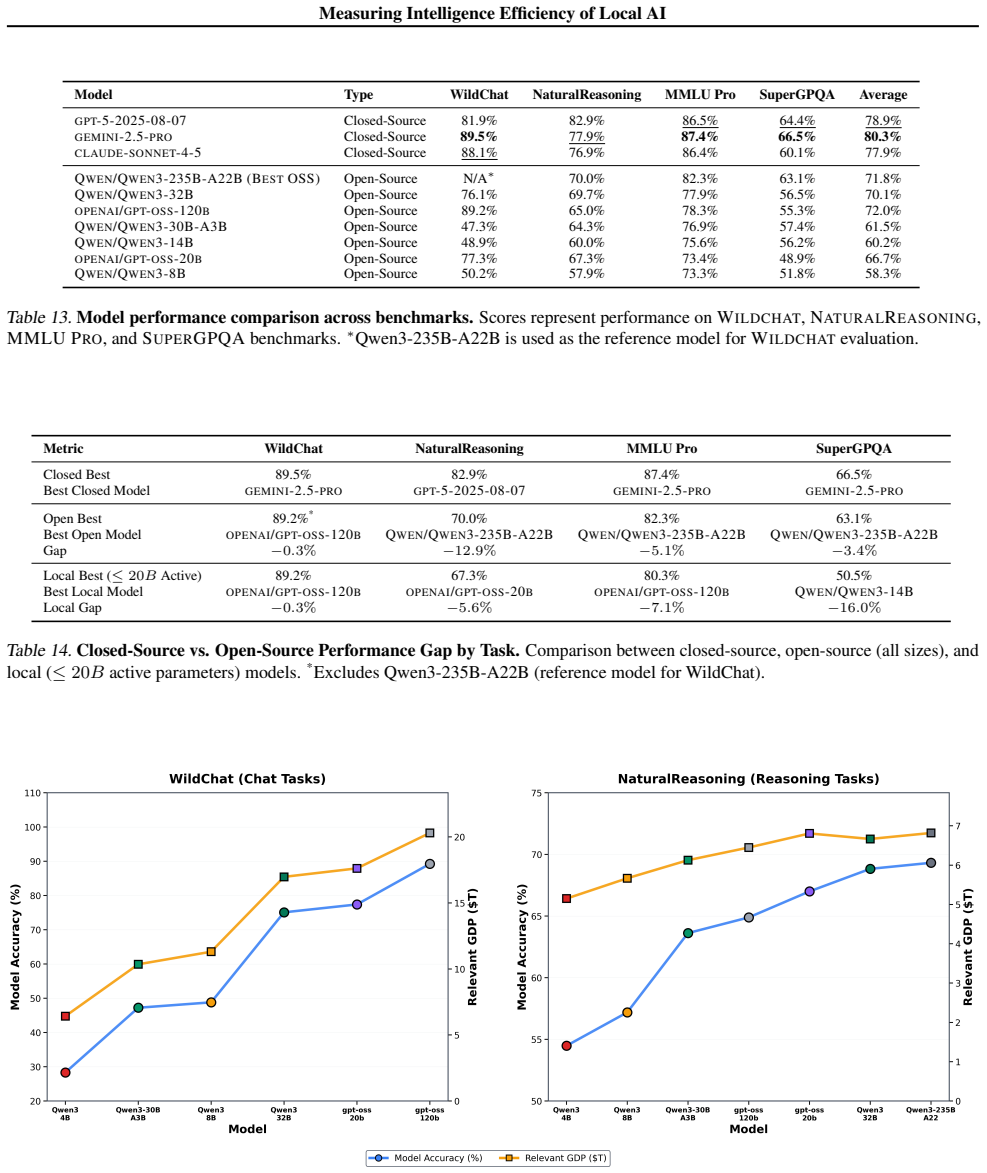
Local language models with at most 20 billion active parameters achieve an 88.7 percent win rate against frontier models across one million single-turn chat and reasoning queries drawn from real user traffic. When this accuracy is divided by measured power draw, the resulting intelligence-per-watt figure improves 5.3 times between 2023 and 2025. Local accelerators consistently record at least 1.4 times higher IPW than cloud accelerators running the same models, while the share of queries that can be served entirely on-device rises from 23.2 percent to 71.3 percent.
What carries the argument
Intelligence per watt (IPW), the ratio of task accuracy to power consumed, used to rank model-accelerator pairs and to track how much real-world demand can shift to local hardware.
If this is right
- Local accelerators already outperform cloud accelerators on identical models, so further hardware tuning can increase the share of queries that stay on-device.
- The 71.3 percent locally serviceable coverage means a large slice of daily traffic can move away from centralized infrastructure without loss of accuracy.
- Continued 5x-scale IPW growth would make local inference the default choice for most chat and reasoning tasks within a few more hardware generations.
- Domain variation in accuracy shows that routing decisions can be made per query type rather than blanket adoption of local or cloud paths.
Where Pith is reading between the lines
- Hybrid systems could automatically send only the hardest queries to the cloud while keeping the rest local, cutting both latency and energy for the average user.
- Because local processing keeps data on the device, the shift measured by IPW would also improve privacy for the subset of queries that never leave the laptop.
- Manufacturers could publish IPW ratings for new chips the way they publish battery life, giving consumers a direct way to compare AI performance across devices.
Load-bearing premise
The one million single-turn queries are representative of actual user demand and that win rate against frontier models is a reliable stand-in for correctness on local models.
What would settle it
A fresh sample of several hundred thousand queries drawn from the same distribution but collected after 2025 would show local-model win rates falling below 70 percent or IPW gains stalling.
Figures












read the original abstract
Large language model (LLM) queries are predominantly processed by frontier models in centralized cloud infrastructure. Demand growth strains this paradigm faster than providers can scale. Two advances create an opportunity to rethink it: small, local LMs (<=20B active parameters) now achieve competitive performance to frontier models on many tasks, and local accelerators (e.g., Apple M4 Max) can host these models at interactive latencies. This raises the question: can local inference viably redistribute demand from centralized infrastructure? This requires measuring both whether local LMs can accurately answer real-world queries and whether they can do so efficiently on power-constrained devices (e.g., laptops). We propose intelligence per watt (IPW), task accuracy per unit of power, as a unified metric for the capability and efficiency of local inference across model-accelerator configurations. We evaluate 20+ state-of-the-art local LMs, 8 hardware accelerators (local and cloud), and 1M real-world single-turn chat and reasoning queries. For each query, we measure accuracy (local LM win rate against frontier models), energy, latency, and power. We find three key results. First, local LMs successfully answer 88.7% of these queries, with accuracy varying by domain. Second, longitudinal analysis from 2023-2025 shows IPW improved 5.3x, driven by both algorithmic and accelerator advances, with locally-serviceable query coverage rising from 23.2% to 71.3%. Third, local accelerators achieve at least 1.4x lower IPW than cloud accelerators running identical models, revealing significant headroom for local accelerator optimization. These findings demonstrate that local inference can meaningfully redistribute demand from centralized infrastructure for a substantial subset of queries, with IPW serving as the critical metric for tracking this transition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Intelligence per Watt (IPW) as a metric combining task accuracy and power consumption to assess local LLMs (≤20B parameters) on accelerators. Using 1M single-turn chat and reasoning queries, it evaluates 20+ local models across 8 hardware platforms and reports three main findings: local models achieve an 88.7% success rate (defined via win rate against frontier models), IPW improved 5.3× from 2023–2025 with locally serviceable coverage rising from 23.2% to 71.3%, and local accelerators show at least 1.4× lower IPW than cloud accelerators for identical models, supporting the potential for demand redistribution from centralized infrastructure.
Significance. If the empirical measurements are robust, the work provides a practical, unified metric for tracking local inference efficiency and quantifies the scale at which local models could offload cloud demand. The direct measurement approach on real queries and fixed model-hardware pairs, without reliance on fitted parameters or circular definitions, strengthens the contribution as a benchmark for sustainable distributed AI systems.
major comments (2)
- [Abstract] Abstract: The headline claim that local LMs 'successfully answer 88.7%' of queries (and the derived 71.3% coverage) is defined solely via win rate against frontier models. This proxy does not establish objective accuracy, as both models may err on the same query, LLM judges can exhibit style/length biases, and many single-turn queries lack verifiable ground truth. Without calibration against human judgment or objective answers, the accuracy figures and all downstream IPW and redistribution conclusions rest on an unvalidated assumption.
- [Abstract] Abstract and evaluation description: Concrete percentages (88.7%, 71.3%, 5.3×, 1.4×) are reported without error bars, query sampling methodology, domain stratification details, or statistical tests for significance. This makes it impossible to assess whether the observed trends and coverage claims are robust to sampling variation or measurement noise.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our use of win-rate proxies and the need for greater statistical transparency. We address each major comment below and will incorporate revisions to clarify limitations and add methodological details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that local LMs 'successfully answer 88.7%' of queries (and the derived 71.3% coverage) is defined solely via win rate against frontier models. This proxy does not establish objective accuracy, as both models may err on the same query, LLM judges can exhibit style/length biases, and many single-turn queries lack verifiable ground truth. Without calibration against human judgment or objective answers, the accuracy figures and all downstream IPW and redistribution conclusions rest on an unvalidated assumption.
Authors: We agree that win rate against frontier models via LLM judges is a proxy metric rather than objective accuracy, and that it does not rule out joint errors or judge biases. This is a standard evaluation approach for open-ended real-world queries where ground truth is often absent, but we acknowledge the limitation. In revision we will rephrase the abstract and results to state that local models achieve competitive performance as measured by win rate, add explicit discussion of LLM-judge biases and lack of human calibration, and note that a subset of reasoning queries admit objective verification. We will also qualify the 71.3% coverage claim as the fraction of queries where local models are preferred or tied under this proxy. These changes temper absolute claims while preserving the relative efficiency comparisons that are the paper's core contribution. revision: partial
-
Referee: [Abstract] Abstract and evaluation description: Concrete percentages (88.7%, 71.3%, 5.3×, 1.4×) are reported without error bars, query sampling methodology, domain stratification details, or statistical tests for significance. This makes it impossible to assess whether the observed trends and coverage claims are robust to sampling variation or measurement noise.
Authors: We agree that the current presentation lacks error bars, detailed sampling description, and significance testing, which weakens assessment of robustness. The 1M queries were drawn from production logs with explicit stratification across chat and reasoning domains, but these details and variance estimates were omitted from the abstract and main text. In the revised manuscript we will add bootstrap-derived error bars to all headline percentages and improvement factors, expand the evaluation section with the full sampling methodology and domain stratification procedure, and include statistical significance tests (e.g., paired t-tests or bootstrap confidence intervals) for the reported trends and the 1.4× local-vs-cloud comparison. revision: yes
Circularity Check
No significant circularity; results from direct empirical measurements
full rationale
The paper's central claims rest on empirical measurements: win-rate accuracy of local LMs against frontier models on 1M single-turn queries, plus direct energy/power/latency readings across model-hardware pairs. IPW is defined explicitly as accuracy per watt and computed from these observed values. Longitudinal IPW trends (5.3x improvement, coverage from 23.2% to 71.3%) are reported from data collected over 2023-2025 rather than from any fitted parameter or self-referential equation. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the derivation chain. The win-rate proxy raises a separate validity question but does not create circularity under the specified patterns.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose intelligence per watt (IPW), task accuracy per unit of power, as a unified metric...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
local LMs successfully answer 88.7% of these queries... IPW improved 5.3x
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Llamas on the Web: Memory-Efficient, Performance-Portable, and Multi-Precision LLM Inference with WebGPU
LlamaWeb is a WebGPU backend for llama.cpp that uses static memory planning, tunable kernels, and templated multi-precision support to cut memory use by 29-33% and raise decode throughput by 45-69% versus prior browse...
-
The xPU-athalon: Quantifying the Competition of AI Acceleration
Quantitative benchmarks across recent AI accelerators reveal that optimal hardware choice varies with workload parameters and that several platforms incur substantially higher idle power than GPUs.
-
AgentStop: Terminating Local AI Agents Early to Save Energy in Consumer Devices
AgentStop uses execution signals to early-terminate failing local LLM agent trajectories, cutting energy use 15-20% with minimal utility loss.
Reference graph
Works this paper leans on
-
[1]
Constitutional AI: Harmlessness from AI Feedback
URL https://assets.anthropic. com/m/12f214efcc2f457a/original/ Claude-Sonnet-4-5-System-Card.pdf. Appel, R., McCrory, P., Tamkin, A., Stern, M., McCain, M., and Neylon, T. Anthropic economic index report: Uneven geographic and enterprise ai adoption, 2025. Apple. Apple m4 max — tech specs. Apple Support / Press Releases, 2024. URL https://support.apple. c...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.5281/zenodo.14212766 2025
-
[2]
URL https://resources.nvidia. com/en-us-data-center-overview-mc/ en-us-data-center-overview/ grace-hopper-superchip-datasheet-partner . Accessed: 2025-01-15. NVIDIA Corporation. NVIDIA DGX B200 Sys- tem Architecture. Technical report, 2025a. URL https://resources.nvidia.com/ en-us-dgx-systems/dgx-b200-datasheet . Accessed: 2025-01-15. NVIDIA Corporation. ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Energy Use of AI Inference: Efficiency Pathways and Test-Time Compute
Accessed: 23 September 2025. Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022. Oviedo, F., Kazhamiaka, F., Choukse, E., Kim, A., Luers, A., Na...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/hpec58863.2023.10363447 2025
-
[4]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
doi: 10.1145/3381831. URL https://dl.acm. org/doi/10.1145/3381831. Sevilla, J., Besiroglu, T., Cottier, B., You, J., Rold´an, E., Vil- lalobos, P., and Erdil, E. Can ai scaling continue through 2030?, 2024. URL https://epoch.ai/blog/ can-ai-scaling-continue-through-2030 . Accessed: 2025-10-06. Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Zhang, M., Li, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3381831 2030
-
[5]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
URL https://www.bea.gov/data/gdp/ gdp-industry. Wang, X., Chen, Z., Ren, J., Li, Y ., Zhang, J., Sun, J., Mi, Y ., et al. MINT: Evaluating LLMs in multi-turn interac- tion with tools and language feedback. InThe Twelfth International Conference on Learning Representations, 2024a. Wang, Y ., Ma, X., Zhang, G., Ni, Y ., Chandra, A., Guo, S., Ren, W., Arulra...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3711896.3737413 2025
-
[6]
Arts, design, sports, entertainment, and media
URL https://www.epri.com/research/ products/000000003002033669. Yuan, W., Yu, J., Jiang, S., Padthe, K., Li, Y ., Wang, D., Kulikov, I., Cho, K., Tian, Y ., Weston, J. E., and Li, X. Naturalreasoning: Reasoning in the wild with 2.8m challenging questions, 2025. URL https://arxiv. org/abs/2502.13124. Zhang, Y . The avengers: A simple recipe for uniting sma...
-
[7]
Read the query carefully
-
[8]
Determine which job/occupation category the query relates to most closely
-
[9]
If the query doesn’t clearly relate to any specific occupation category, use "None"
-
[10]
Respond with ONLY the category name, exactly as listed above 35 36Category: Solvability rates vary dramatically by domain and dataset type, where a query’s solvability is defined as its ability to be answered correctly by any of the available local LMs (e.g. Qwen models or GPT OSS). WILDCHATqueries show consistently high solvability across most domains (g...
work page 2025
-
[11]
Creativity & novelty | 18| Objective / technical | 1
Conciseness 5. Creativity & novelty | 18| Objective / technical | 1. Correctness only | 19 20When using the multi-criteria rubric, note strengths and weaknesses for **each** dimension . 21When using the single-criterion rubric, focus exclusively on factual / functional accuracy Measuring Intelligence Efficiency of Local AI Category WILDCHATMMLU PROSUPERGP...
work page 2025
-
[12]
Assistant A is significantly better: [[A>>B]]
-
[13]
Assistant A is slightly better: [[A>B]]
-
[14]
Tie, Assistant A is equal: [[A=B]]
-
[15]
Assistant B is slightly better: [[B>A]]
-
[16]
Assistant B is significantly better: [[B>>A]] 32 33Choose exactly one token from: ‘[[A>>B]]‘, ‘[[A>B]]‘, ‘[[A=B]]‘, ‘[[B>A]]‘, ‘[[B>>A]]‘. 34 35--- 36 37### Output format (strict) 38Return **only** a JSON object that matches the provided schema: NATURALREASONINGLLM-judge Prompt 1You are evaluating a response to a scientific/technical question against a re...
-
[17]
Scientific accuracy of facts and concepts
-
[18]
Mathematical correctness (if applicable)
-
[19]
Completeness of the answer
-
[20]
Technical precision 10 11Question: {question} 12 13Response: {response} 14 15Reference Answer: {reference} Measuring Intelligence Efficiency of Local AI 16 17Return ONLY ’True’ if the response is correct and complete, ’False’ otherwise. Metric Description flops per request FLOPs per query. macs per request MACs per query; proxy for compute. per query joul...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.