AXIOM: A Trust-First Neuro-Symbolic Execution Architecture for Verifiable Mathematical Reasoning
Pith reviewed 2026-06-28 18:41 UTC · model grok-4.3
The pith
AXIOM restricts the LLM to rewriting math problems into schemas for a deterministic CAS pipeline, yielding 94.36 percent correctness at 100 percent trust with zero confident errors on 2747 problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
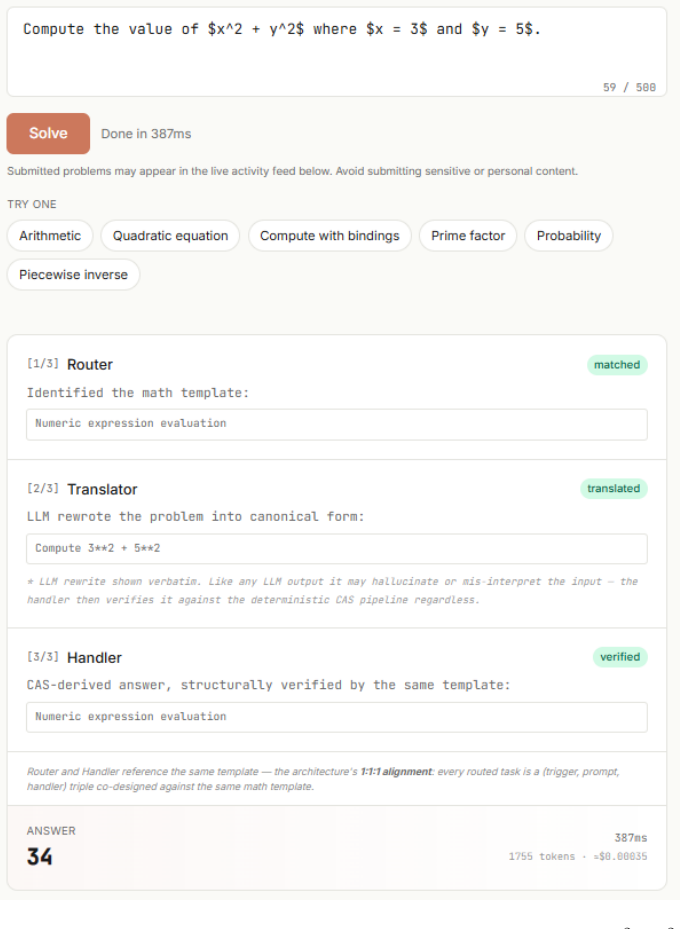
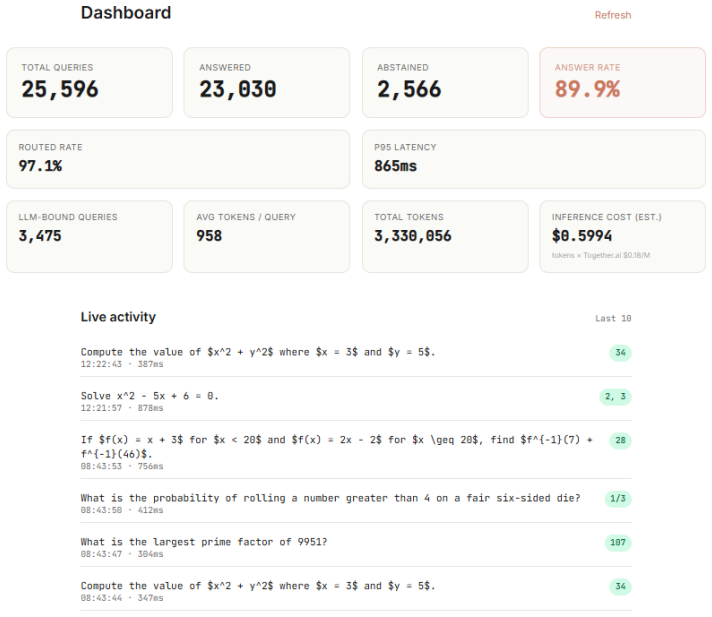
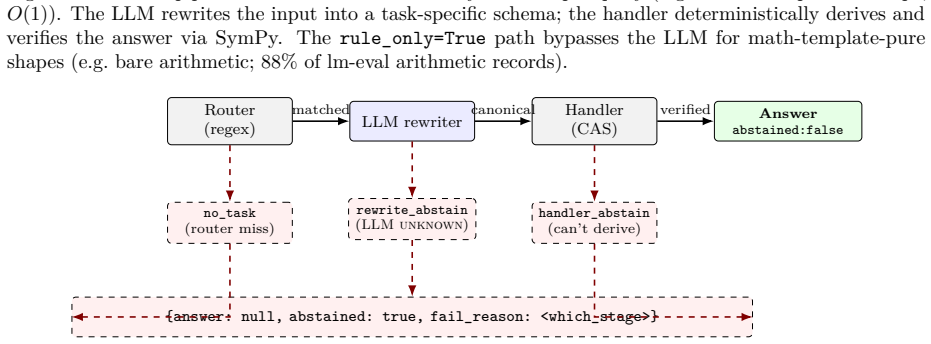
AXIOM confines the language model to canonicalization: it rewrites problem text into a schema consumed by a closed-form CAS handler. Routing follows a strict 1:1:1 alignment between problem-shape regex, schema-specific prompt, and CAS handler. With 3100-plus such routes the system achieves 94.36 percent correctness (2592 of 2747) at 100 percent trust on parseable outputs and zero confident-wrong answers across the full benchmark, while every abstain remains a candidate for correction in the next ship cycle without regressing the registry.
What carries the argument
The 1:1:1 alignment between problem-shape regex, schema-specific prompt, and closed-form CAS handler.
If this is right
- New problem types can be added by shipping additional routes without causing LOST_CORRECT regressions on existing routes.
- Every abstain observed in production directly identifies a task that can be made correct in the next update cycle.
- The system maintains 100 percent trust on all parseable outputs, with no confident-wrong answers across the 2747-problem benchmark.
- Rule-only handlers achieve 1 ms median latency and cover 88 percent of records on the 20000-record arithmetic benchmark.
Where Pith is reading between the lines
- The same canonicalizer-plus-CAS pattern could be applied to other domains that already possess reliable symbolic solvers.
- Production abstention logs become a direct, low-cost source of training or route-creation data for the next iteration.
- The architecture supplies a concrete regression oracle (the LOST_CORRECT scan) that any neuro-symbolic system could adopt to keep trust at 100 percent while accuracy improves.
Load-bearing premise
The language model produces only correct schemas for every problem it routes, so that no parseable-but-wrong schema ever reaches the CAS.
What would settle it
A single logged case in which the LLM outputs a schema that the CAS accepts yet yields an incorrect answer on a problem whose correct solution is known.
Figures

read the original abstract
We present AXIOM, a trust-first neuro-symbolic execution architecture for natural-language mathematical reasoning. In AXIOM, the language model functions strictly as a canonicalizer: it rewrites informal problem text into a narrow schema consumed by a deterministic Computer-Algebra-System (CAS) pipeline, which derives and verifies the answer or abstains as a first-class output. Routing follows a 1:1:1 alignment between problem-shape regex, schema-specific prompt, and closed-form CAS handler, with 3,100+ such routes shipped and zero LOST_CORRECT regressions across 250+ consecutive ship commits. We report empirical results on 4 MATH categories with a cumulative correctness of 94.36% (2,592/2,747) at 100.00% trust on parseable (zero confident-wrong answers across the full 2,747-record benchmark), all four domains above the per-domain 70/90/70 floor with per-domain trust at 100.0%, and median latency of 1 ms on rule-only handlers (88% of records on the lm-eval arithmetic 20,000-record benchmark). The architecture has served ~30,000 production queries through a public deployment. The contribution we emphasize is not a final accuracy figure but the forward dynamic the architecture establishes: every logged abstain in production is a candidate correct after one ship cycle, since new tasks compose without regressing the registry. The operational discipline behind this property -- math-template bucketing, LOST_CORRECT scan as regression oracle, parseable-first onboarding, and abstain as first-class output -- constitutes a transferable framework for trustworthy neuro-symbolic systems beyond mathematics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AXIOM, a neuro-symbolic architecture in which an LLM is restricted to canonicalizing natural-language mathematical problems into narrow schemas that are then executed by a deterministic CAS pipeline. Routing uses a 1:1:1 alignment of problem-shape regex, schema-specific prompts, and closed-form CAS handlers (3,100+ shipped), with explicit abstain on non-parseable cases and a LOST_CORRECT regression discipline. On four MATH categories (2,747 records) the system reports 94.36% correctness (2,592/2,747) at 100% trust on parseable outputs (zero confident-wrong answers), all domains above the 70/90/70 floor, median 1 ms latency on rule-only handlers, and ~30,000 production queries served. The emphasized contribution is the forward dynamic: every logged abstain becomes a candidate for a future ship without regressing existing handlers.
Significance. If the central claims hold, the work supplies a concrete, transferable framework for trustworthy neuro-symbolic systems that prioritizes verifiable execution and continuous improvement over raw accuracy. Credit is due for the explicit production deployment, the LOST_CORRECT regression oracle, the large registry of handlers, and the clear separation of LLM canonicalization from deterministic verification. These elements could inform design patterns in other domains where abstention and regression-free extension are required.
major comments (2)
- [§5 (Empirical Results)] §5 (Empirical Results): The claim of 100% trust on parseable outputs (zero confident-wrong answers across the full 2,747-record benchmark) rests on the untested premise that the LLM canonicalizer never emits a parseable-but-incorrect schema that reaches the CAS; no quantitative sampling, error-rate measurement, or ablation of canonicalization failures is reported to support this premise.
- [§4 (Architecture) and §5] §4 (Architecture) and §5: No baseline systems or alternative canonicalization strategies are evaluated, so it is impossible to determine whether the observed correctness and trust figures are attributable to the 1:1:1 routing discipline or would arise under simpler prompting; this gap directly affects assessment of the architecture's contribution to the reported trust metric.
minor comments (2)
- The description of the public deployment and ~30,000 queries would benefit from a brief statement of the distribution of problem types encountered in production versus the MATH benchmark.
- Notation for the per-domain 70/90/70 floor is introduced without an explicit definition or reference to prior work; a short footnote or sentence would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the manuscript. We address each major comment below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: The claim of 100% trust on parseable outputs (zero confident-wrong answers across the full 2,747-record benchmark) rests on the untested premise that the LLM canonicalizer never emits a parseable-but-incorrect schema that reaches the CAS; no quantitative sampling, error-rate measurement, or ablation of canonicalization failures is reported to support this premise.
Authors: We acknowledge that the manuscript reports the 100% trust figure as an empirical result on the 2,747-record subset (zero confident-wrong answers among parseable cases) without a separate quantitative sampling or ablation that isolates canonicalization error rates on parseable-but-incorrect schemas. The architecture relies on narrow, schema-specific prompts and deterministic CAS handlers to constrain outputs, and the benchmark results show no such errors occurred in practice. However, we agree that an explicit measurement or discussion of canonicalization fidelity would strengthen support for the premise. In the revised manuscript we will add a paragraph in §5 addressing this limitation and its implications for the trust claim. revision: yes
-
Referee: No baseline systems or alternative canonicalization strategies are evaluated, so it is impossible to determine whether the observed correctness and trust figures are attributable to the 1:1:1 routing discipline or would arise under simpler prompting; this gap directly affects assessment of the architecture's contribution to the reported trust metric.
Authors: We agree that the manuscript does not include comparisons against baseline canonicalization strategies such as simpler prompting without the 1:1:1 routing discipline. The primary contribution emphasized is the overall framework (handler registry, LOST_CORRECT regression oracle, abstain as first-class output, and regression-free extension) rather than a claim that the specific canonicalizer is optimal or solely responsible for the trust metric. The zero confident-wrong and regression-free properties follow directly from the deterministic CAS execution and 1:1:1 alignment, which simpler prompting would not guarantee. To improve assessment of the routing discipline's role, we will add a short clarification in §4 and §5 on the scope of the claims and, if space permits, a limited baseline comparison in the revision. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper reports direct empirical measurements of correctness (94.36%) and trust (100%) on external MATH benchmark categories, with the zero confident-wrong outcome tied to explicit abstain-on-non-parseable and LOST_CORRECT regression rules rather than any fitted parameter or self-referential definition. The 1:1:1 routing and handler registry are presented as engineering mechanisms whose performance is observed on held-out records, not quantities derived by construction from the same data. No load-bearing self-citations, uniqueness theorems, or ansatzes appear in the central claims; the architecture is self-contained against the stated external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption CAS handlers produce correct results for every schema they accept.
- domain assumption The 1:1:1 regex-prompt-handler mapping covers problems without producing parseable incorrect schemas.
Reference graph
Works this paper leans on
-
[1]
Llemma: An Open Language Model For Mathematics
Zhangir Azerbayev, Hailey Schoelkopf, Keiran Paster, Marco Dos Santos, Stephen McAleer, Albert Q. Jiang, Jia Deng, Stella Biderman, and Sean Welleck. Llemma: An open language model for mathematics. arXiv preprint arXiv:2310.10631, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
From statistical relational to neurosymbolic artificial intelligence: A survey.Artificial Intelligence Journal, 2024
Luc De Raedt, Robin Dušek, Robin Manhaeve, and Giuseppe Marra. From statistical relational to neurosymbolic artificial intelligence: A survey.Artificial Intelligence Journal, 2024
2024
-
[4]
A framework for few-shot language model evaluation (lm-eval-harness), 2023
Leo Gao, Jonathan Tow, Baber Abbasi, et al. A framework for few-shot language model evaluation (lm-eval-harness), 2023
2023
-
[5]
Artur d’Avila Garcez and Luis C. Lamb. Neurosymbolic AI: The third wave.Artificial Intelligence Review, 2023
2023
-
[6]
Measuring mathematical problem solving with the MATH dataset.NeurIPS Datasets and Benchmarks Track, 2021
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset.NeurIPS Datasets and Benchmarks Track, 2021
2021
-
[7]
TrustLLM: Trustworthiness in Large Language Models
Yue Huang, Lichao Sun, et al. TrustLLM: Trustworthiness in large language models.arXiv preprint arXiv:2401.05561, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
SymPy: symbolic computing in Python.PeerJ Computer Science, 3:e103, 2017
Aaron Meurer, Christopher P Smith, Mateusz Paprocki, Ondřej Čertík, Sergey B Kirpichev, Matthew Rocklin, AmiT Kumar, Sergiu Ivanov, Jason K Moore, Sartaj Singh, et al. SymPy: symbolic computing in Python.PeerJ Computer Science, 3:e103, 2017
2017
-
[10]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Lean Copilot: Large language models as copilots for theorem proving in Lean
Peiyang Song, Kaiyu Yang, and Anima Anandkumar. Lean Copilot: Large language models as copilots for theorem proving in Lean. InNeurIPS Datasets and Benchmarks Track, 2024
2024
-
[12]
Wolfram Alpha computational knowledge engine.https://www.wolframalpha
Wolfram Research. Wolfram Alpha computational knowledge engine.https://www.wolframalpha. com, 2009. First released 2009; closed-source proprietary system. 14
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.