How Human Feedback Shapes AI-generated Community Notes
Pith reviewed 2026-07-01 01:13 UTC · model grok-4.3
The pith
Human feedback improves AI-generated Community Notes, with the largest gains from suggestions that challenge the main claim in prior drafts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Human feedback on LLM-drafted Community Notes produces more helpful versions, driven especially by suggestions that contest the main claim of the previous draft and come from frequent contributors. Although scores rise, the notes achieve helpful status and visibility less often than human-only or AI-only notes, with low participation acting as the main constraint. Collaborative notes do not replace the other two types but instead cover a largely separate set of posts.
What carries the argument
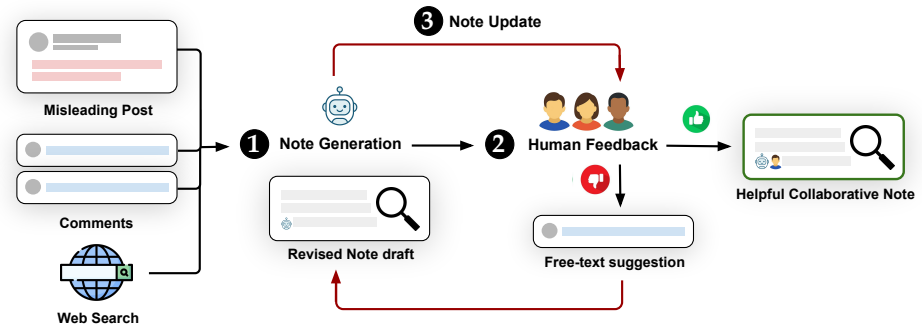
Iterative refinement loop in which humans submit categorized suggestions to LLM-drafted notes, with selective incorporation of those suggestions into later versions.
If this is right
- Suggestions that challenge the main claim produce larger helpfulness increases than other feedback types.
- Feedback from more active contributors has greater effect than feedback from less active ones.
- Limited human participation prevents collaborative notes from matching the display rates of human-only or AI-only notes.
- Collaborative notes address posts that receive neither human-only nor AI-only notes.
Where Pith is reading between the lines
- Increasing participation rates could raise the overall share of posts that receive any note.
- Design changes that surface challenging suggestions might accelerate quality gains in future iterations.
- The same feedback taxonomy could be applied to test whether similar patterns appear on other platforms using Community Notes.
Load-bearing premise
The platform's internal helpfulness metric and visibility rules measure note quality independently of whether the note was produced through collaborative drafting.
What would settle it
A controlled comparison that holds the post fixed and randomly assigns either human feedback iterations or no feedback, then measures the resulting helpfulness ratings and display rates, would test whether feedback itself drives the observed gains.
Figures





read the original abstract
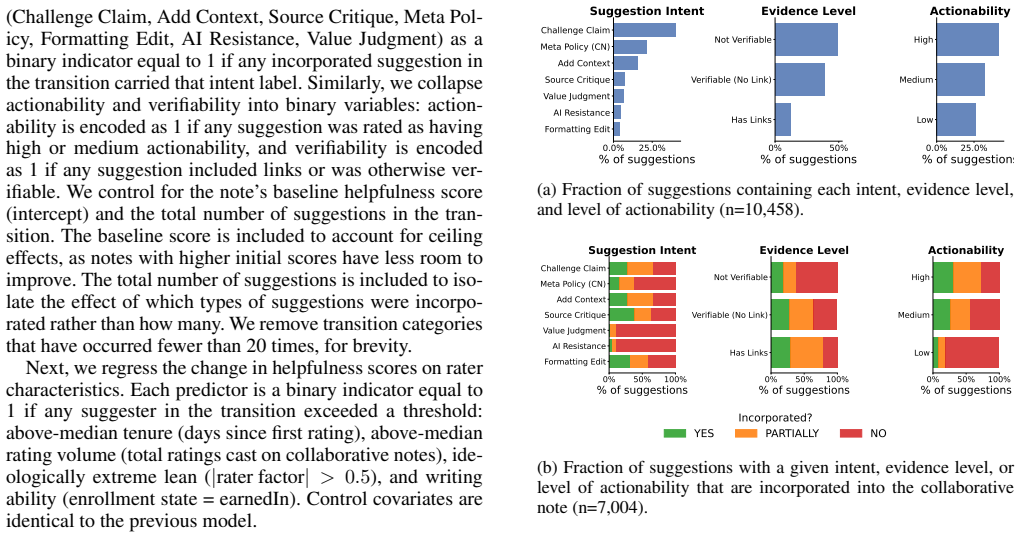
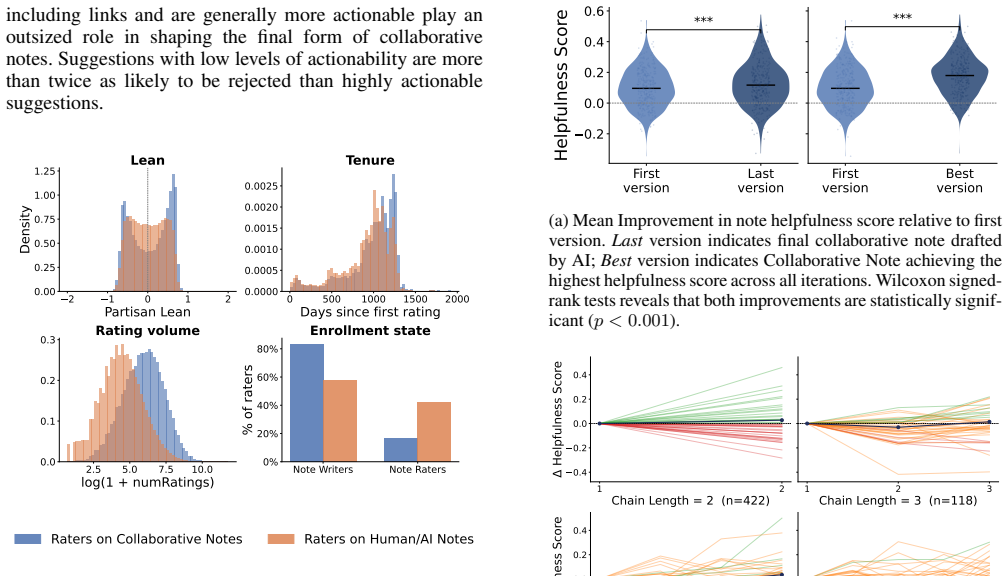
Community Notes, a bridging-based crowd-sourced fact-checking system, has emerged as a new mechanism for moderating misleading information on social media and has been adopted by major platforms including X, Facebook, Instagram, Threads, and TikTok. Since its introduction, there has been an open question about what role AI could play in scaling and optimizing the system. Recently, X extended its Community Notes system by introducing Collaborative Notes: notes initially drafted by an LLM and iteratively refined based on feedback from human contributors. In this work, we systematically analyze the complete corpus of 19,146 collaborative notes and 211,850 instances of human feedback. First, we develop a taxonomy of human suggestions for improving AI-generated note drafts and find that suggestions involving factual corrections and additional context are most likely to be incorporated, while subjective policy judgments rarely are. Second, we examine changes in helpfulness across versions of collaborative notes and find that human feedback leads to more helpful notes, with the greatest impact coming from suggestions that challenge the main claim in the previous draft, particularly when submitted by more active contributors. Finally, we find that although collaborative notes improve through human feedback, they reach helpful status and are shown on the platform at lower rates than human-only or AI-only notes, with limited human participation emerging as a key bottleneck. Nevertheless, rather than serving as a weaker substitute, collaborative notes tend to play a complementary role, predominantly targeting posts that do not attract human-only or AI-only notes. Our analysis provides an initial description of efforts to use AI to improve crowdsourced content moderation in a real-world moderation system and outlines pathways for future improvements to such features.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes the full corpus of 19,146 collaborative notes and 211,850 human feedback instances on X's Community Notes platform. It first develops a taxonomy of suggestion types, then tracks version-to-version changes in helpfulness ratings to claim that human feedback improves notes (with largest gains from claim-challenging suggestions by active contributors), and finally compares success rates and post-targeting patterns to show that collaborative notes underperform human-only and AI-only notes in reaching visibility but serve a complementary role by addressing posts that attract neither.
Significance. If the reported patterns survive controls for selection and metric dependence, the work supplies the first large-scale empirical description of LLM-initiated notes refined by human feedback inside a live bridging-based moderation system, quantifying which feedback types are incorporated, identifying participation bottlenecks, and documenting complementarity rather than substitution.
major comments (2)
- [Abstract / Helpfulness analysis] Abstract and the section on helpfulness changes across versions: the claim that feedback (especially challenging suggestions from active contributors) causes increases in helpfulness is presented without any reported controls, matching, fixed effects, or robustness checks that would separate the effect from selection into which drafts receive iteration or from platform rating rules that may treat collaborative drafts differently. This identification gap is load-bearing for the central causal attribution.
- [Comparison of success rates] Section comparing rates to human-only and AI-only notes: the lower helpful-status and visibility rates for collaborative notes are reported without evidence that the platform's internal helpfulness metric and visibility rules are independent of the collaborative drafting process itself, leaving open the possibility that the metric is partly endogenous to the presence of human-AI iteration.
minor comments (2)
- [Taxonomy development] The taxonomy construction and inter-annotator agreement statistics are not described in sufficient detail to allow replication of the classification of suggestion types.
- [Data and methods] The manuscript would benefit from an explicit statement of the time window and any filtering criteria applied to the 19,146 collaborative notes.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important limitations in our observational analysis regarding causal identification and potential metric endogeneity. We address each major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [Abstract / Helpfulness analysis] Abstract and the section on helpfulness changes across versions: the claim that feedback (especially challenging suggestions from active contributors) causes increases in helpfulness is presented without any reported controls, matching, fixed effects, or robustness checks that would separate the effect from selection into which drafts receive iteration or from platform rating rules that may treat collaborative drafts differently. This identification gap is load-bearing for the central causal attribution.
Authors: We agree that the manuscript presents version-to-version changes without fixed effects, matching, or explicit robustness checks to isolate feedback effects from selection into iteration or platform rating differences. The analysis is observational, and while within-note changes provide suggestive evidence, we cannot fully rule out confounding. We will revise the abstract and main text to replace causal phrasing ('leads to', 'causes') with associative language ('associated with increases in'). We will add a limitations subsection explicitly discussing selection biases and the absence of controls. If data permit, we will include supplementary robustness checks (e.g., stratification by contributor activity). This constitutes a partial revision. revision: partial
-
Referee: [Comparison of success rates] Section comparing rates to human-only and AI-only notes: the lower helpful-status and visibility rates for collaborative notes are reported without evidence that the platform's internal helpfulness metric and visibility rules are independent of the collaborative drafting process itself, leaving open the possibility that the metric is partly endogenous to the presence of human-AI iteration.
Authors: We acknowledge that the paper reports observed rates without direct evidence that X's internal metrics are independent of the collaborative process. Endogeneity is a plausible concern we cannot directly test. We will add an explicit discussion of this limitation in the relevant section. The complementarity result relies primarily on post-targeting patterns rather than the helpfulness metric itself, which may be less sensitive to this issue. We plan a partial revision to incorporate this caveat. revision: partial
- Direct evidence on whether X's internal helpfulness algorithm or visibility rules treat collaborative notes differently, as this would require access to proprietary platform code and data not available to external researchers.
Circularity Check
No circularity: observational analysis of platform data with no self-referential derivations
full rationale
The paper conducts empirical analysis on a corpus of 19,146 collaborative notes and 211,850 feedback instances. It develops a taxonomy of suggestions, tracks version-to-version changes in platform helpfulness scores, and compares rates of reaching helpful status. No equations, fitted models, or parameters are defined in terms of the target outcomes; no predictions reduce to inputs by construction; and no self-citations serve as load-bearing uniqueness theorems or ansatzes. The central claims rest on direct data patterns rather than any closed derivation loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the ACM on Web Conference 2025 , pages=
Supernotes: Driving consensus in crowd-sourced fact-checking , author=. Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[2]
arXiv preprint arXiv:2509.11052 , year=
Commenotes: Synthesizing organic comments to support community-based fact-checking , author=. arXiv preprint arXiv:2509.11052 , year=
-
[3]
Proceedings of the 31st annual ACM symposium on user interface software and technology , pages=
Believe it or not: designing a human-ai partnership for mixed-initiative fact-checking , author=. Proceedings of the 31st annual ACM symposium on user interface software and technology , pages=
-
[4]
Birdwatch: Crowd wisdom and bridging algorithms can inform understanding and reduce the spread of misinformation , author=. arXiv preprint arXiv:2210.15723 , year=
-
[5]
Information Processing & Management , volume=
Crowdsourced fact-checking: Does it actually work? , author=. Information Processing & Management , volume=. 2024 , publisher=
2024
-
[6]
Proceedings of the National Academy of Sciences , volume=
Community notes reduce engagement with and diffusion of false information online , author=. Proceedings of the National Academy of Sciences , volume=. 2025 , publisher=
2025
-
[7]
Nature Communications , volume=
Community-based fact-checking reduces the spread of misleading posts on X (formerly Twitter) , author=. Nature Communications , volume=. 2026 , publisher=
2026
-
[8]
Althea: Human-AI Collaboration for Fact-Checking and Critical Reasoning
Althea: Human-AI Collaboration for Fact-Checking and Critical Reasoning , author=. arXiv preprint arXiv:2602.11161 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
News Verifiers Showdown: A Comparative Performance Evaluation of ChatGPT 3.5, ChatGPT 4.0, Bing AI, and Bard in News Fact-Checking , author=. arXiv: 2306.17176 , year=
-
[10]
arXiv preprint arXiv:2402.05904 , year=
FACT-GPT: Fact-Checking Augmentation via Claim Matching with LLMs , author=. arXiv preprint arXiv:2402.05904 , year=
-
[11]
arXiv preprint arXiv:2312.13096 , year=
In Generative AI We Trust: Can Chatbots Effectively Verify Political Information? , author=. arXiv preprint arXiv:2312.13096 , year=
-
[12]
arXiv preprint arXiv:2503.08404 , year=
Fact-Checking with Generative AI: A Systematic Cross-Topic Examination of LLMs Capacity to Detect Veracity of Political Information , author=. arXiv preprint arXiv:2503.08404 , year=
-
[13]
Journal of Medical Internet Research , year=
Use of Retrieval-Augmented Large Language Model for COVID-19 Fact-Checking: Development and Usability Study , author=. Journal of Medical Internet Research , year=
-
[14]
arXiv preprint arXiv:2505.18596 , year=
Debate-to-Detect: Reformulating Misinformation Detection as a Real-World Debate with Large Language Models , author=. arXiv preprint arXiv:2505.18596 , year=
-
[15]
Proceedings of the ACM on Human-Computer Interaction , volume =
Liu, Houjiang and Das, Anubrata and Boltz, Alexander and Zhou, Didi and Pinaroc, Daisy and Lease, Matthew and Lee, Min Kyung , title =. Proceedings of the ACM on Human-Computer Interaction , volume =. 2024 , month =
2024
-
[16]
Perspectives on Psychological Science , volume=
Crowds can effectively identify misinformation at scale , author=. Perspectives on Psychological Science , volume=. 2024 , publisher=
2024
-
[17]
PNAS nexus , volume=
Community notes increase trust in fact-checking on social media , author=. PNAS nexus , volume=. 2024 , publisher=
2024
-
[18]
Quality-Sensitive Matrix Factorization for Community Notes: Towards Sample Efficiency and Manipulation Resistance , author=. arXiv preprint arXiv:2604.11224 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Beyond the Crowd: LLM-Augmented Community Notes for Governing Health Misinformation
Beyond the Crowd: LLM-Augmented Community Notes for Governing Health Misinformation , author=. arXiv preprint arXiv:2510.11423 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
AI Fact-Checking in the Wild: A Field Evaluation of LLM-Written Community Notes on X
AI Fact-Checking in the Wild: A Field Evaluation of LLM-Written Community Notes on X , author=. arXiv preprint arXiv:2604.02592 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Journal of Online Trust and Safety , volume=
Scaling human judgment in community notes with llms , author=. Journal of Online Trust and Safety , volume=. doi:10.54501/jots.v3i1.255 , year=
-
[22]
arXiv preprint arXiv:2603.11120 , year=
The Laziness of the Crowd: Effort Aversion Among Raters Risks Undermining the Efficacy of X's Community Notes Program , author=. arXiv preprint arXiv:2603.11120 , year=
-
[23]
Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages =
Hassan, Naeemul and Arslan, Fatma and Li, Chengkai and Tremayne, Mark , title =. Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages =. 2017 , publisher =
2017
-
[24]
Nature human behaviour , volume=
A consensus-based transparency checklist , author=. Nature human behaviour , volume=. 2020 , publisher=
2020
-
[25]
Communications of the ACM , volume=
Datasheets for datasets , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[26]
Centre for the Governance of AI
A guide to writing the NeurIPS impact statement , author=. Centre for the Governance of AI. URL: https://perma. cc/B5R8-2B9V , year=
-
[27]
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics: Tutorial Abstracts , pages=
Understanding Ethics in NLP Authoring and Reviewing , author=. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics: Tutorial Abstracts , pages=
-
[28]
NeurIPS 2021 Paper Checklist Guidelines
NeurIPS. NeurIPS 2021 Paper Checklist Guidelines
2021
-
[29]
The FAIR Data principles
FORCE11. The FAIR Data principles
-
[30]
arXiv preprint arXiv:2506.15168 , year=
Algorithmic resolution of crowd-sourced moderation on X in polarized settings across countries , author=. arXiv preprint arXiv:2506.15168 , year=
-
[31]
Proceedings of the 29th International Conference on Computational Linguistics , pages=
Twitter topic classification , author=. Proceedings of the 29th International Conference on Computational Linguistics , pages=
-
[32]
Journal of Machine Learning Research , volume=
Beyond english-centric multilingual machine translation , author=. Journal of Machine Learning Research , volume=
-
[33]
Proceedings of the ACM Web Conference , year=
Hoaxy: A platform for tracking online misinformation , author=. Proceedings of the ACM Web Conference , year=
-
[34]
Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , year=
Toward automated fact-checking: Detecting check-worthy factual claims by claimbuster , author=. Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , year=
-
[35]
Proceedings of the National Academy of Sciences , year=
Fighting misinformation on social media using crowdsourced judgments of news source quality , author=. Proceedings of the National Academy of Sciences , year=
-
[36]
Poynter Institute
Most Republicans don’t trust fact-checkers, and most Americans don’t trust the media , author=. Poynter Institute. , year=
-
[37]
Behavioral Sciences , year=
Americans’ perspectives on online media warning labels , author=. Behavioral Sciences , year=
-
[38]
HKS Misinformation Review , year=
Leveraging volunteer fact checking to identify misinformation about COVID-19 in social media , author=. HKS Misinformation Review , year=
-
[39]
Frontiers in Artificial Intelligence , year=
The perils and promises of fact-checking with large language models , author=. Frontiers in Artificial Intelligence , year=
-
[40]
Science Advances , year=
Scaling up fact-checking using the wisdom of crowds , author=. Science Advances , year=
-
[41]
Collective Intelligence , year=
Searching for or reviewing evidence improves crowdworkers’ misinformation judgments and reduces partisan bias , author=. Collective Intelligence , year=
-
[42]
Proceedings of the Conference on Human Factors in Computing Systems , year=
Will the crowd game the algorithm? Using layperson judgments to combat misinformation on social media by downranking distrusted sources , author=. Proceedings of the Conference on Human Factors in Computing Systems , year=
-
[43]
IEEE international Conference on Big Data , year=
The role of the crowd in countering misinformation: A case study of the COVID-19 infodemic , author=. IEEE international Conference on Big Data , year=
-
[44]
Mediashift , year=
Crowdsourced fact-checking? What we learned from Truthsquad , author=. Mediashift , year=
-
[45]
Proceedings of the 15th International Symposium on Open Collaboration , year=
Do you have a source for that? Understanding the Challenges of Collaborative Evidence-based Journalism , author=. Proceedings of the 15th International Symposium on Open Collaboration , year=
-
[46]
Proceedings of the International AAAI Conference on Web and Social Media , year=
Community-based fact-checking on Twitter’s Birdwatch platform , author=. Proceedings of the International AAAI Conference on Web and Social Media , year=
-
[47]
Proceedings of the ACM on Human-Computer Interaction , year=
Diffusion of community fact-checked misinformation on Twitter , author=. Proceedings of the ACM on Human-Computer Interaction , year=
-
[48]
osf.io/preprints/osf/3a4fe , year=
Community notes reduce the spread of misleading posts on X , author=. osf.io/preprints/osf/3a4fe , year=
-
[49]
PNAS Nexus , year=
Community notes increase trust in fact-checking on social media , author=. PNAS Nexus , year=
-
[50]
Snoping: How the Crowd Selects Fact-Checking Targets on Social Media , author=
Community Notes vs. Snoping: How the Crowd Selects Fact-Checking Targets on Social Media , author=. Proceedings of the International AAAI Conference on Web and Social Media , year=
-
[51]
osf.io/preprints/psyarxiv/qnjkf , year=
Leveraging ChatGPT for efficient fact-checking , author=. osf.io/preprints/psyarxiv/qnjkf , year=
-
[52]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
SNIFFER: Multimodal Large Language Model for Explainable Out-of-Context Misinformation Detection , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[53]
Explainable claim verification via knowledge-grounded reasoning with large language models , author=. arXiv:2310.05253 , year=
-
[54]
Transactions of the Association for Computational Linguistics , year=
JustiLM: Few-shot Justification Generation for Explainable Fact-Checking of Real-world Claims , author=. Transactions of the Association for Computational Linguistics , year=
-
[55]
Correcting misinformation on social media with a large language model , author=. arXiv:2403.11169 , year=
-
[56]
2016 , publisher=
Detecting rumors from microblogs with recurrent neural networks , author=. 2016 , publisher=
2016
-
[57]
Proceedings of the 2011 conference on empirical methods in natural language processing , year=
Rumor has it: Identifying misinformation in microblogs , author=. Proceedings of the 2011 conference on empirical methods in natural language processing , year=
2011
-
[58]
ACM SIGKDD explorations newsletter , year=
Misinformation in social media: definition, manipulation, and detection , author=. ACM SIGKDD explorations newsletter , year=
-
[59]
Artificial intelligence is ineffective and potentially harmful for fact checking , author=. arXiv:2308.10800 , year=
-
[60]
arXiv preprint arXiv:2511.02615 , year=
Community Notes are vulnerable to rater bias and manipulation , author=. arXiv preprint arXiv:2511.02615 , year=
-
[61]
AI Feedback Enhances Community-Based Content Moderation through Engagement with Counterarguments
AI feedback enhances community-based content moderation through engagement with counterarguments , author=. arXiv preprint arXiv:2507.08110 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
The Benefit of Collective Intelligence in Community-Based Content Moderation is Limited by Overt Political Signalling , author=. arXiv preprint arXiv:2601.22201 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
arXiv preprint arXiv:2602.08970 , year=
Hyperactive Minority Alters the Stability of Community Notes , author=. arXiv preprint arXiv:2602.08970 , year=
-
[64]
Grok in the Wild: Characterizing the Roles and Uses of Large Language Models on Social Media
Grok in the wild: Characterizing the roles and uses of large language models on social media , author=. arXiv preprint arXiv:2602.11286 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.