Learning Video Dynamics with Predictive Differentiable Rendering
Pith reviewed 2026-07-01 06:51 UTC · model grok-4.3
The pith
Predictive Differentiable Rendering integrates a 2D Gaussian adapter to predict video frames with preserved spatial details instead of blurred pixel outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
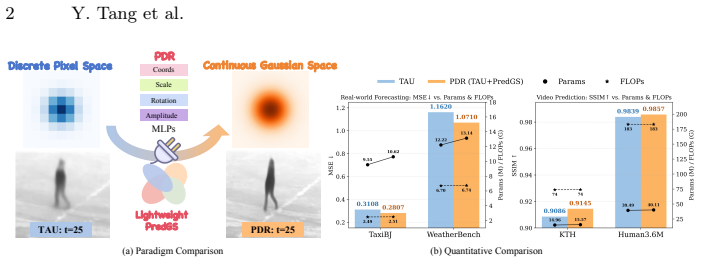
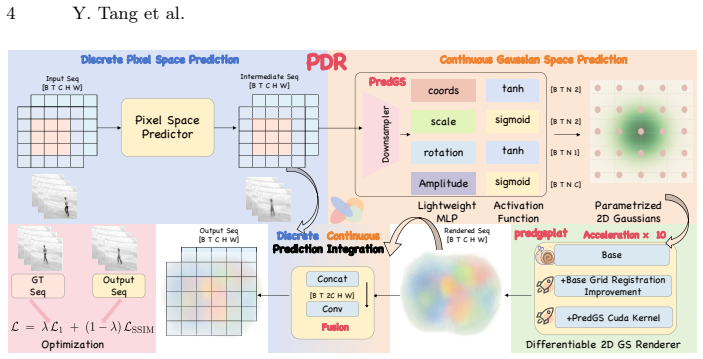
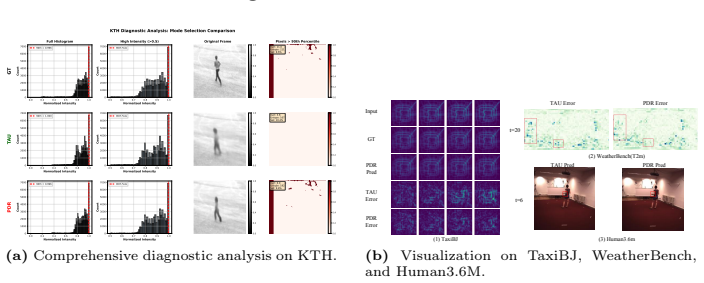
PDR bridges discrete pixel prediction and continuous world modeling by inserting PredGS, a 2D Gaussian-based adapter, into existing predictors and rendering it with predgsplat. Each Gaussian carries position, scale, rotation and channel amplitudes; the system is trained end-to-end with combined L1 and SSIM losses. On TaxiBJ, WeatherBench, KTH and Human3.6M this yields higher visual fidelity and predictive accuracy than prior methods while adding negligible overhead.
What carries the argument
PredGS, a lightweight plug-and-play adapter that represents predicted frames with 2D Gaussians (5+C parameters per Gaussian) and renders them differentiably to preserve spatial detail.
If this is right
- Existing pixel predictors gain detail preservation with only small added cost.
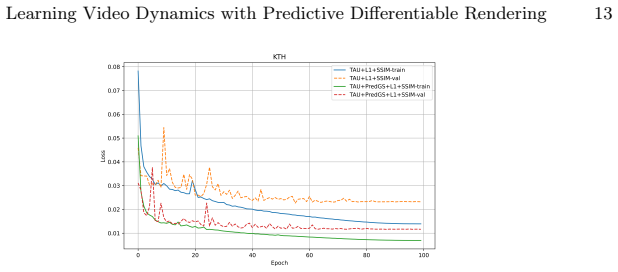
- L1+SSIM training avoids the over-smoothing produced by pure MSE.
- The CUDA renderer delivers up to 10x speed-up while supporting arbitrary channels.
- Performance gains appear consistently across weather, traffic, action and human-motion benchmarks.
Where Pith is reading between the lines
- The same adapter pattern could be tested on predictors that already use latent spaces rather than raw pixels.
- Because the renderer is differentiable and fast, it might support online fine-tuning during deployment.
- If the 2D Gaussian assumption holds for video, similar representations might reduce blurring in related tasks such as future-frame interpolation.
Load-bearing premise
A 2D Gaussian representation can be added to any pixel-space predictor without creating new inconsistencies or artifacts in the rendered output.
What would settle it
On the Human3.6M or TaxiBJ test sets, run the PDR model and a strong baseline; if SSIM and perceptual detail scores show no gain or if visible rendering artifacts appear, the claim fails.
Figures

read the original abstract
How to accurately predict a high-fidelity future world? While the visual world is inherently continuous, existing deterministic video prediction models operate in discrete pixel space and are mainly optimized with pixel-wise mean squared error (MSE), which often leads to over-smoothed predictions and a lack of fine-grained visual details. To address these limitations, we propose Predictive Differentiable Rendering (PDR), a novel end-to-end video prediction paradigm that bridges the gap between discrete and continuous representations. Inspired by recent progress in 3D reconstruction with 3D Gaussian Splatting, we introduce PredGS, a lightweight and plug-and-play adapter based on 2D Gaussian representation, which could be seamlessly integrated with existing pixel space predictors, significantly improving spatial detail preservation with negligible computational overhead. Furthermore, we develop predgsplat, a CUDA-accelerated differentiable 2D Gaussian renderer supporting arbitrary channels. Each Gaussian is defined by 5 + C learnable parameters (position, scale, rotation, and C channel amplitudes) and achieves up to 10x faster rendering than the baseline. Optimized by a combined L1 and SSIM loss, PDR overcomes the inherent blurring tendencies of MSE Loss, significantly enhancing the prediction performance. Extensive experiments on diverse real-world benchmarks, including TaxiBJ, WeatherBench, KTH, and Human3.6M, demonstrate that PDR consistently surpasses existing methods, delivering superior detail preservation, visual fidelity, and predictive accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Predictive Differentiable Rendering (PDR), an end-to-end video prediction framework that augments existing discrete pixel-space predictors with a lightweight 2D Gaussian adapter (PredGS) and a CUDA-accelerated differentiable renderer (predgsplat). Each Gaussian is parameterized by 5 + C learnable values (position, scale, rotation, channel amplitudes) and is optimized via combined L1 + SSIM loss rather than MSE; the method is claimed to preserve fine details with negligible overhead and is evaluated on TaxiBJ, WeatherBench, KTH, and Human3.6M, where it reportedly outperforms prior approaches in visual fidelity and predictive accuracy.
Significance. If the integration of the continuous 2D Gaussian representation with pixel predictors succeeds without introducing temporal inconsistencies or new artifacts, the approach would provide a practical route to higher-fidelity video dynamics modeling while retaining compatibility with existing architectures. The plug-and-play design, reported 10x rendering speedup, and use of L1+SSIM to mitigate blurring are potentially useful contributions if substantiated by the experiments.
major comments (2)
- [Abstract / Method description] The central claim that PredGS (5 + C parameters per Gaussian, rendered via predgsplat) integrates seamlessly with pixel-space predictors while preserving spatial coherence and avoiding motion artifacts across frames is load-bearing for the entire contribution. The abstract asserts this integration is “plug-and-play” with “negligible computational overhead,” yet the provided text supplies no derivation, ablation, or quantitative check (e.g., optical-flow consistency or per-frame detail metrics on KTH/Human3.6M) that would confirm the continuous Gaussian output remains consistent with the discrete predictor’s dynamics.
- [Abstract / Experiments] The assertion that L1 + SSIM optimization “overcomes the inherent blurring tendencies of MSE Loss” and yields “superior detail preservation” is presented as a direct consequence of the representation change, but no controlled comparison isolating the loss versus the Gaussian adapter is referenced, leaving open whether the reported gains on the four benchmarks are attributable to the proposed continuous representation or to other factors.
minor comments (2)
- [Abstract] The phrase “up to 10x faster rendering than the baseline” is stated without identifying the baseline renderer or reporting wall-clock numbers on the target hardware.
- [Abstract] The abstract lists four benchmarks but does not indicate whether the same pixel-space backbone is used across all comparisons or whether any architecture-specific tuning was required for the PredGS adapter.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, agreeing that additional controlled experiments are needed to fully substantiate the claims. We will incorporate the requested ablations and metrics in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / Method description] The central claim that PredGS (5 + C parameters per Gaussian, rendered via predgsplat) integrates seamlessly with pixel-space predictors while preserving spatial coherence and avoiding motion artifacts across frames is load-bearing for the entire contribution. The abstract asserts this integration is “plug-and-play” with “negligible computational overhead,” yet the provided text supplies no derivation, ablation, or quantitative check (e.g., optical-flow consistency or per-frame detail metrics on KTH/Human3.6M) that would confirm the continuous Gaussian output remains consistent with the discrete predictor’s dynamics.
Authors: The integration is realized by directly mapping the pixel predictor outputs to the 5+C Gaussian parameters and rendering them differentiably with predgsplat, enabling end-to-end training. The plug-and-play property and negligible overhead are supported by the reported 10x rendering speedup and successful attachment to multiple base predictors. We agree, however, that explicit quantitative validation of temporal coherence is absent from the current text. We will add optical-flow consistency metrics, per-frame detail preservation scores, and corresponding ablations on KTH and Human3.6M in the revision. revision: yes
-
Referee: [Abstract / Experiments] The assertion that L1 + SSIM optimization “overcomes the inherent blurring tendencies of MSE Loss” and yields “superior detail preservation” is presented as a direct consequence of the representation change, but no controlled comparison isolating the loss versus the Gaussian adapter is referenced, leaving open whether the reported gains on the four benchmarks are attributable to the proposed continuous representation or to other factors.
Authors: The manuscript reports results from the joint use of the Gaussian adapter and L1+SSIM loss. We acknowledge the lack of an isolating ablation. In the revised version we will include a controlled study comparing (i) baseline predictors with MSE, (ii) baselines with L1+SSIM, and (iii) the full PDR (PredGS + L1+SSIM) on all four benchmarks to separate the contributions of the representation and the loss function. revision: yes
Circularity Check
No circularity; method empirically validated on external benchmarks
full rationale
The paper proposes PredGS (2D Gaussian adapter with 5+C parameters per Gaussian, rendered via predgsplat) as a plug-and-play module integrated with existing pixel predictors, trained end-to-end using combined L1+SSIM loss, and reports superior results on TaxiBJ, WeatherBench, KTH, and Human3.6M. No derivation reduces predictions or claims to fitted parameters by construction, no self-citation chains are load-bearing, and no ansatz or uniqueness is smuggled in. The central claims rest on external benchmark comparisons rather than internal redefinition.
Axiom & Free-Parameter Ledger
free parameters (1)
- 5 + C learnable parameters per Gaussian
axioms (1)
- domain assumption The visual world is inherently continuous
invented entities (2)
-
PredGS
no independent evidence
-
predgsplat
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: ICLR (2018)
Babaeizadeh, M., Finn, C., Erhan, D., Campbell, R.H., Levine, S.: Stochastic vari- ational video prediction. In: ICLR (2018)
2018
-
[2]
In: Nature (2023)
Bi, K., Xie, L., Zhang, H., Chen, X., Gu, X., Tian, Q.: Accurate medium-range global weather forecasting with 3d neural networks. In: Nature (2023)
2023
-
[3]
In: NeurIPS (2021)
Chang, Z., Zhang, X., Wang, S., Ma, S., Ye, Y., Xinguang, X., Gao, W.: Mau: A motion-aware unit for video prediction and beyond. In: NeurIPS (2021)
2021
-
[4]
Chen, Z., Wang, F., Wang, Y., Liu, H.: Text-to-3d using gaussian splatting (2024)
2024
-
[5]
Facebook AI Research: fvcore.https://github.com/facebookresearch/fvcore (2019), accessed: 2026-06-25
2019
-
[6]
In: IJCAI (2019)
Fang, S., Zhang, Q., Meng, G., Xiang, S., Pan, C.: Gstnet: Global spatial-temporal network for traffic flow prediction. In: IJCAI (2019)
2019
-
[7]
In: CVPR (2022)
Gao, Z., Tan, C., Wu, L., Li, S.Z.: Simvp: Simpler yet better video prediction. In: CVPR (2022)
2022
-
[8]
In: NeurIPS (2023)
Gao, Z., Shi, X., Han, B., Wang, H., Jin, X., Maddix, D., Zhu, Y., Li, M., Wang, Y.B.: Prediff: Precipitation nowcasting with latent diffusion models. In: NeurIPS (2023)
2023
-
[9]
In: NeurIPS (2022)
Gao, Z., Shi, X., Wang, H., Zhu, Y., Wang, Y.B., Li, M., Yeung, D.Y.: Earthformer: Exploring space-time transformers for earth system forecasting. In: NeurIPS (2022)
2022
-
[10]
In: CVPR (2020)
Guen, V.L., Thome, N.: Disentangling physical dynamics from unknown factors for unsupervised video prediction. In: CVPR (2020)
2020
-
[11]
In: AAAI (2025)
Hu, J., Xia, B., Chen, B., Yang, W., Zhang, L.: Gaussiansr: High fidelity 2d gaus- sian splatting for arbitrary-scale image super-resolution. In: AAAI (2025)
2025
-
[12]
In: CVPR (2023)
Hu, X., Huang, Z., Huang, A., Xu, J., Zhou, S.: A dynamic multi-scale voxel flow network for video prediction. In: CVPR (2023)
2023
-
[13]
Huang, Y.H., Sun, Y.T., Yang, Z., Lyu, X., Cao, Y.P., Qi, X.: Sc-gs: Sparse-controlled gaussian splatting for editable dynamic scenes. arXiv preprint arXiv:2312.14937 (2023)
-
[14]
ACM Transactions on Graphics42(4) (2023)
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics42(4) (2023)
2023
-
[15]
ICIP (2025)
Ko, W., Park, J.B., Chun, I.Y.: Autoregression-free video prediction using diffusion model for mitigating error propagation. ICIP (2025)
2025
-
[16]
In: Arxiv (2025)
Li, H., Chen, C., Li, X., Lu, G.: 2d gaussian splatting with semantic alignment for image inpainting. In: Arxiv (2025)
2025
-
[17]
In: ICLR (2025)
Lin, X., Luo, S., Shan, X., Zhou, X., Ren, C., Qi, L., Yang, M.H., Vasconcelos, N.: Hqgs: High-quality novel view synthesis with gaussian splatting in degraded scenes. In: ICLR (2025)
2025
-
[18]
In: ICLR (2017)
Lotter, W., Kreiman, G., Cox, D.: Deep predictive coding networks for video pre- diction and unsupervised learning. In: ICLR (2017)
2017
-
[19]
Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis, 2023
Luiten, J., Kopanas, G., Leibe, B., Ramanan, D.: Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis. arXiv preprint arXiv:2308.09713 (2023)
-
[20]
In: ICLR (2016)
Mathieu, M., Couprie, C., LeCun, Y.: Deep multi-scale video prediction beyond mean square error. In: ICLR (2016)
2016
-
[21]
In: cvpr (2024)
Matsuki, H., Murai, R., Kelly, P.H.J., Davison, A.J.: Gaussian Splatting SLAM. In: cvpr (2024)
2024
-
[22]
In: CVPR (2023)
Ni, H., Shi, C., Li, K., Huang, S.X., Min, M.R.: Conditional image-to-video gen- eration with latent flow diffusion models. In: CVPR (2023)
2023
-
[23]
In: AAAI (2024) Learning Video Dynamics with Predictive Differentiable Rendering 17
Nie, X., Yan, Y., Li, S., Tan, C., Chen, X., Jin, H., Zhu, Z., Li, S.Z., Qi, D.: Wavelet-driven spatiotemporal predictive learning: Bridging frequency and time variations. In: AAAI (2024) Learning Video Dynamics with Predictive Differentiable Rendering 17
2024
-
[24]
In: CVPR (2025)
Pallotta, E., Azar, S.M., Li, S., Zatsarynna, O., Gall, J.: Syncvp: joint diffusion for synchronous multi-modal video prediction. In: CVPR (2025)
2025
-
[25]
In: Arxiv (2022)
Pathak, J., Subramanian, S., Harrington, P., Raja, S., Chattopadhyay, A., Mar- dani, M., Kurth, T., Hall, D., Li, Z., Azizzadenesheli, K., et al.: Fourcastnet: A global data-driven high-resolution weather model using adaptive fourier neural op- erators. In: Arxiv (2022)
2022
-
[26]
In: Arxiv (2025)
Peng, L., Wu, A., Li, W., Xia, P., Dai, X., Zhang, X., Di, X., Sun, H., Pei, R., Wang, Y., et al.: Pixel to gaussian: Ultra-fast continuous super-resolution with 2d gaussian modeling. In: Arxiv (2025)
2025
-
[27]
In: Journal of Advances in Modeling Earth Systems (2020)
Rasp, S., Dueben, P.D., Scher, S., Weyn, J.A., Mouatadid, S., Thuerey, N.: Weath- erbench: a benchmark data set for data-driven weather forecasting. In: Journal of Advances in Modeling Earth Systems (2020)
2020
-
[28]
In: Proceedings of the 17th International Conference on Pattern Recogni- tion, 2004
Schuldt, C., Laptev, I., Caputo, B.: Recognizing human actions: a local svm ap- proach. In: Proceedings of the 17th International Conference on Pattern Recogni- tion, 2004. ICPR 2004. vol. 3, pp. 32–36. IEEE (2004)
2004
-
[29]
In: NeurIPS (2015)
Shi, X., Chen, Z., Wang, H., Yeung, D.Y., Wong, W.K., Woo, W.c.: Convolu- tional lstm network: A machine learning approach for precipitation nowcasting. In: NeurIPS (2015)
2015
-
[30]
Song, M., ...: D2GS: Depth-and-density guided gaussian splatting... arXiv preprint arXiv:2510.08566 (2025)
-
[31]
In: CVPR (2023)
Tan, C., Gao, Z., Wu, L., Xu, Y., Xia, J., Li, S., Li, S.Z.: Temporal attention unit: Towards efficient spatiotemporal predictive learning. In: CVPR (2023)
2023
-
[32]
In: NeurIPS (2023)
Tan, C., Li, S., Gao, Z., Guan, W., Wang, Z., Liu, Z., Wu, L., Li, S.Z.: Openstl: A comprehensive benchmark of spatio-temporal predictive learning. In: NeurIPS (2023)
2023
-
[33]
In: TPAMI (2025)
Tan, C., Wang, J., Gao, Z., Li, S., Wu, L., Xia, J., Li, S.Z.: Ustep: Spatio-temporal predictive learning under a unified view. In: TPAMI (2025)
2025
-
[34]
In: ICCV (2023)
Tang, S., Li, C., Zhang, P., Tang, R.: Swinlstm: Improving spatiotemporal predic- tion accuracy using swin transformer and lstm. In: ICCV (2023)
2023
-
[35]
In: CVPRW (2024)
Tang, Y., Dong, P., Tang, Z., Chu, X., Liang, J.: Vmrnn: Integrating vision mamba and lstm for efficient and accurate spatiotemporal forecasting. In: CVPRW (2024)
2024
-
[36]
In: TMLR (2026)
Tang, Y., Qi, L., Xie, F., Li, X., Ma, C., Yang, M.H.: Video prediction transformers without recurrence or convolution. In: TMLR (2026)
2026
-
[37]
In: ECCV (2020)
Teed, Z., Deng, J.: RAFT: Recurrent all-pairs field transforms for optical flow. In: ECCV (2020)
2020
-
[38]
In: NeurIPS (2022)
Voleti, V., Jolicoeur-Martineau, A., Pal, C.: MCVD: Masked conditional video diffusion for prediction, generation, and interpolation. In: NeurIPS (2022)
2022
-
[39]
In: Computer Vision and Image Understanding (2018)
Wang, P., Li, W., Ogunbona, P., Wan, J., Escalera, S.: Rgb-d-based human mo- tion recognition with deep learning: A survey. In: Computer Vision and Image Understanding (2018)
2018
-
[40]
In: ICML (2018)
Wang, Y., Gao, Z., Long, M., Wang, J., Philip, S.Y.: Predrnn++: Towards a reso- lution of the deep-in-time dilemma in spatiotemporal predictive learning. In: ICML (2018)
2018
-
[41]
In: ICLR (2018)
Wang, Y., Jiang, L., Yang, M.H., Li, L.J., Long, M., Fei-Fei, L.: Eidetic 3d lstm: A model for video prediction and beyond. In: ICLR (2018)
2018
-
[42]
In: NeurIPS (2017)
Wang, Y., Long, M., Wang, J., Gao, Z., Yu, P.S.: Predrnn: Recurrent neural net- works for predictive learning using spatiotemporal lstms. In: NeurIPS (2017)
2017
-
[43]
In: TPAMI (2022) 18 Y
Wang, Y., Wu, H., Zhang, J., Gao, Z., Wang, J., Philip, S.Y., Long, M.: Predrnn: A recurrent neural network for spatiotemporal predictive learning. In: TPAMI (2022) 18 Y. Tang et al
2022
-
[44]
In: CVPR (2019)
Wang, Y., Zhang, J., Zhu, H., Long, M., Wang, J., Yu, P.S.: Memory in mem- ory: A predictive neural network for learning higher-order non-stationarity from spatiotemporal dynamics. In: CVPR (2019)
2019
-
[45]
In: ICLR (2025)
Wang, Z., Qin, Y., Zeng, L., Zhang, R.: High-dynamic radar sequence prediction for weather nowcasting using spatiotemporal coherent gaussian representation. In: ICLR (2025)
2025
-
[46]
arXiv preprint arXiv:2310.08528 (2023)
Wu, G., Yi, T., Fang, J., Xie, L., Zhang, X., Wei, W., Liu, W., Tian, Q., Xinggang, W.: 4d gaussian splatting for real-time dynamic scene rendering. arXiv preprint arXiv:2310.08528 (2023)
-
[47]
In: CVPR (2024)
Yan, C., Qu, D., Xu, D., Zhao, B., Wang, Z., Wang, D., Li, X.: Gs-slam: Dense visual slam with 3d gaussian splatting. In: CVPR (2024)
2024
-
[48]
arXiv preprint arXiv:2401.01339 (2024)
Yan, Y., Lin, H., Zhou, C., Wang, W., Sun, H., Zhan, K., Lang, X., Zhou, X., Peng, S.: Street gaussians for modeling dynamic urban scenes. arXiv preprint arXiv:2401.01339 (2024)
-
[49]
arXiv preprint arXiv:2203.09481 (2022)
Yang, R., Srivastava, P., Mandt, S.: Diffusion probabilistic modeling for video generation. arXiv preprint arXiv:2203.09481 (2022)
-
[50]
In: International Conference on Learning Representations (ICLR) (2024)
Yang, Z., Yang, H., Pan, Z., Zhang, L.: Real-time photorealistic dynamic scene rep- resentation and rendering with 4d gaussian splatting. In: International Conference on Learning Representations (ICLR) (2024)
2024
-
[51]
In: AAAI (2024)
Ye, X., Bilodeau, G.A.: STDiff: Spatio-temporal diffusion for continuous stochastic video prediction. In: AAAI (2024)
2024
-
[52]
In: CVPR (2024)
Yu, D., Li, X., Ye, Y., Zhang, B., Luo, C., Dai, K., Wang, R., Chen, X.: Diffcast: A unified framework via residual diffusion for precipitation nowcasting. In: CVPR (2024)
2024
-
[53]
In: AAAI (2017)
Zhang, J., Zheng, Y., Qi, D.: Deep spatio-temporal residual networks for citywide crowd flows prediction. In: AAAI (2017)
2017
-
[54]
In: ICCVW (2017)
Zhang, L., Zhu, G., Shen, P., Song, J., Afaq Shah, S., Bennamoun, M.: Learning spatiotemporalfeaturesusing3dcnnandconvolutionallstmforgesturerecognition. In: ICCVW (2017)
2017
-
[55]
In: ECCV (2024)
Zhang, X., Ge, X., Xu, T., He, D., Wang, Y., Qin, H., Lu, G., Geng, J., Zhang, J.: Gaussianimage: 1000 fps image representation and compression by 2d gaussian splatting. In: ECCV (2024)
2024
-
[56]
In: CVPR (2024)
Zhang, Z., Hu, J., Cheng, W., Paudel, D., Yang, J.: ExtDM: Distribution extrap- olation diffusion model for video prediction. In: CVPR (2024)
2024
-
[57]
In: arXiv (2024)
Zhou, X., Lin, Z., Shan, X., Wang, Y., Sun, D., Yang, M.H.: Drivinggaussian: Composite gaussian splatting for surrounding dynamic autonomous driving scenes. In: arXiv (2024)
2024
-
[58]
In: 3DV (2025)
Zielonka, W., Bagautdinov, T., Saito, S., Zollhöfer, M., Thies, J., Romero, J.: Drivable 3d gaussian avatars. In: 3DV (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.