Toward Pre-Deployment Assurance for Enterprise AI Agents: Ontology-Grounded Simulation and Trust Certification
Pith reviewed 2026-06-28 10:39 UTC · model grok-4.3
The pith
Ontology-grounded scenario generation for enterprise AI agents covers more regulatory requirements than persona-based baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
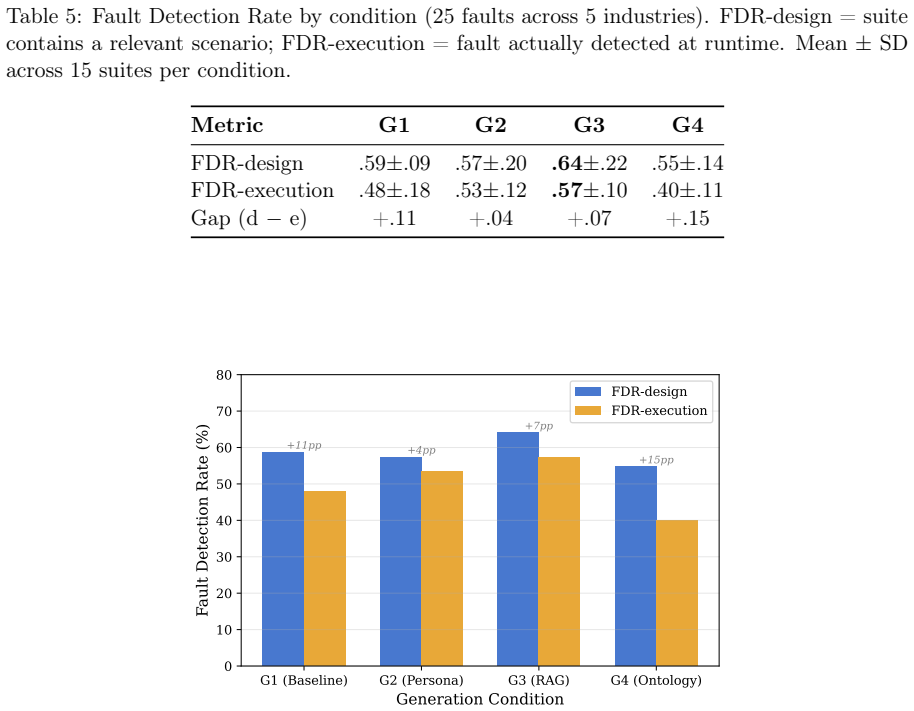
The ontology-grounded verification framework combines an Agent Operational Envelope that defines the certification space, an ontology-to-scenario generation pipeline that derives regulatory, operational, and adversarial tests automatically from primary sources, and a machine-verifiable Trust Certificate. In controlled tests generating 1,800 scenarios across five industry-by-regime cells and validating against 125 regulatory requirements, ontology-grounded generation achieved 48.3 percent coverage versus 33.1 percent for persona-based generation, with the highest domain specificity score; the pattern held across three LLM families.
What carries the argument
The ontology-to-scenario generation pipeline, which encodes permissions, constraints, safety properties, and governance rules into an ontology and then derives test scenarios directly from those encodings.
If this is right
- Supplies a reproducible, regulation-grounded route to pre-deployment assurance that produces auditable deployment gates.
- Complements post-deployment monitoring and human-in-the-loop controls with an earlier verification step.
- Applies directly to settings where AI verification is legally mandated, such as financial services under Vietnam's 2025 AI Law.
- Demonstrates consistent performance across multiple large language model families when used to generate the scenarios.
- Allows graduated trust certificates that can support staged or conditional deployment decisions.
Where Pith is reading between the lines
- Updating the ontology with new regulations could allow the same pipeline to adapt to evolving legal requirements without redesigning test suites from scratch.
- The framework might be combined with runtime monitoring data to create a closed-loop system that refines the ontology over time.
- Extending the approach to non-regulated but high-stakes domains such as autonomous systems could test whether the coverage gains hold outside the pilot industries.
- If the ontology is maintained as a shared resource across organizations, it could reduce duplicated compliance effort while preserving auditability.
Load-bearing premise
The ontology accurately and completely encodes the relevant regulatory requirements, domain constraints, and safety properties so that the generated scenarios are representative and free of selection bias.
What would settle it
An experiment in which domain experts identify a primary regulatory requirement that the ontology-generated scenarios systematically miss while alternative generation methods catch it, or in which the scenarios fail to surface injected faults that agents actually exhibit in live operation.
Figures
read the original abstract
Pre-deployment verification of enterprise artificial intelligence (AI) agents remains a critical gap between large language model (LLM) capability benchmarking and production deployment. Post-deployment monitoring, human-in-the-loop controls, and prompt-level guardrails offer limited assurance once an agent is operating in production. We present an ontology-grounded verification framework -- to our knowledge the first to combine three components: an Agent Operational Envelope formalizing the certification space across permissions, domain constraints, safety properties, governance rules, and autonomy levels; an ontology-to-scenario generation pipeline that derives regulatory, operational, and adversarial test scenarios automatically; and a machine-verifiable Trust Certificate with graduated deployment verdicts. A controlled pilot across four regulated industries (Fintech, Banking, Insurance, Healthcare), instantiated as five industry-by-regulatory-regime cells across the United States and Vietnam (where Vietnam's 2025 AI Law makes such verification legally mandated for financial services), generated 1,800 scenarios evaluated against 125 primary-source regulatory requirements and 25 injected faults. Ontology-grounded generation significantly outperformed the dominant persona-based baseline on regulatory coverage (48.3% versus 33.1%; corrected p_c = .0006) and attained the highest domain specificity (4.77/5.0; p = 2e-6); transparently, its advantage over plain and retrieval-augmented prompting did not survive Bonferroni correction. Cross-validation across three LLM families (Claude Sonnet 4, Qwen 2.5 72B, Gemma 4 26B; 5,400 total scenarios) replicated the persona-versus-ontology pattern. The framework offers a reproducible, regulation-grounded route to pre-deployment assurance for enterprise AI agents, complementing runtime governance with an auditable deployment gate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an ontology-grounded verification framework for pre-deployment assurance of enterprise AI agents. It defines an Agent Operational Envelope ontology spanning permissions, domain constraints, safety properties, governance rules, and autonomy levels; an automatic ontology-to-scenario generation pipeline deriving regulatory, operational, and adversarial test scenarios from primary-source requirements; and a machine-verifiable Trust Certificate with graduated verdicts. A pilot across four regulated industries (Fintech, Banking, Insurance, Healthcare) in the US and Vietnam generated 1,800 scenarios evaluated against 125 regulatory requirements and 25 injected faults, reporting that ontology-grounded generation achieved 48.3% regulatory coverage (vs. 33.1% for persona baseline, corrected p_c=.0006) and highest domain specificity (4.77/5.0), with replication across three LLM families (Claude Sonnet 4, Qwen 2.5 72B, Gemma 4 26B).
Significance. If the central empirical results hold under proper validation of the ontology, the work supplies a reproducible, regulation-grounded pre-deployment gate that complements runtime monitoring. The cross-LLM replication, use of primary-source requirements, and explicit comparison to persona, plain, and RAG baselines are concrete strengths that could support auditable deployment decisions in regulated domains.
major comments (2)
- [Abstract and §3] Abstract and §3 (Ontology Construction): The headline claim that scenarios are 'derived automatically from primary-source requirements' and the reported coverage advantage both presuppose that the Agent Operational Envelope ontology completely and faithfully encodes the 125 requirements. The manuscript supplies no account of elicitation procedure, per-requirement mapping, coverage/consistency checks performed, or external domain-expert audit of the mapping; without this, the measured superiority over the persona baseline could be an artifact of author-curated content rather than the generation method.
- [§4] §4 (Evaluation Protocol): No description is given of how the 25 injected faults were selected, whether scenario evaluation was blinded to condition, or what inter-rater reliability was obtained for the domain-specificity and coverage judgments. These omissions directly affect the interpretability of the 48.3% vs. 33.1% coverage result and the p-values reported.
minor comments (1)
- [Table 2] Table 2: the Bonferroni-corrected p-values for the plain and RAG comparisons are reported but the exact number of comparisons and the correction factor applied are not stated, making it impossible to verify the 'did not survive correction' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments identify genuine gaps in methodological transparency that affect the interpretability of our results. We address each point below and will incorporate revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Ontology Construction): The headline claim that scenarios are 'derived automatically from primary-source requirements' and the reported coverage advantage both presuppose that the Agent Operational Envelope ontology completely and faithfully encodes the 125 requirements. The manuscript supplies no account of elicitation procedure, per-requirement mapping, coverage/consistency checks performed, or external domain-expert audit of the mapping; without this, the measured superiority over the persona baseline could be an artifact of author-curated content rather than the generation method.
Authors: We agree the manuscript currently provides insufficient detail on ontology construction. The 125 requirements were drawn from primary regulatory texts, but the mapping process, consistency validation, and any external review are not described. This is a substantive limitation that could indeed affect attribution of the coverage gains. In revision we will add a new subsection to §3 titled 'Ontology Elicitation and Validation' that specifies: (i) the requirement extraction protocol from source documents, (ii) the two-author independent mapping procedure with disagreement resolution, (iii) automated consistency checks performed with an OWL reasoner, and (iv) an explicit statement that no external domain-expert audit was conducted (a limitation we will flag and propose to address in future work). A supplementary mapping table will also be provided. These additions will allow readers to assess whether the advantage is method-driven or content-driven. revision: yes
-
Referee: [§4] §4 (Evaluation Protocol): No description is given of how the 25 injected faults were selected, whether scenario evaluation was blinded to condition, or what inter-rater reliability was obtained for the domain-specificity and coverage judgments. These omissions directly affect the interpretability of the 48.3% vs. 33.1% coverage result and the p-values reported.
Authors: We concur that the evaluation protocol description is incomplete. The 25 faults were selected to reflect documented failure modes from regulatory enforcement actions and industry reports in each domain, but selection criteria, blinding status, and inter-rater reliability are not reported. In the revised §4 we will add: (i) explicit fault-selection rationale with citations to source literature, (ii) confirmation that evaluations were not blinded, and (iii) inter-rater reliability statistics (Cohen's kappa) for the manual domain-specificity and coverage judgments. If formal IRR was not computed in the original study we will state this as a limitation and describe how replications can incorporate blinding and multiple raters. These changes will improve the credibility of the statistical comparisons. revision: yes
Circularity Check
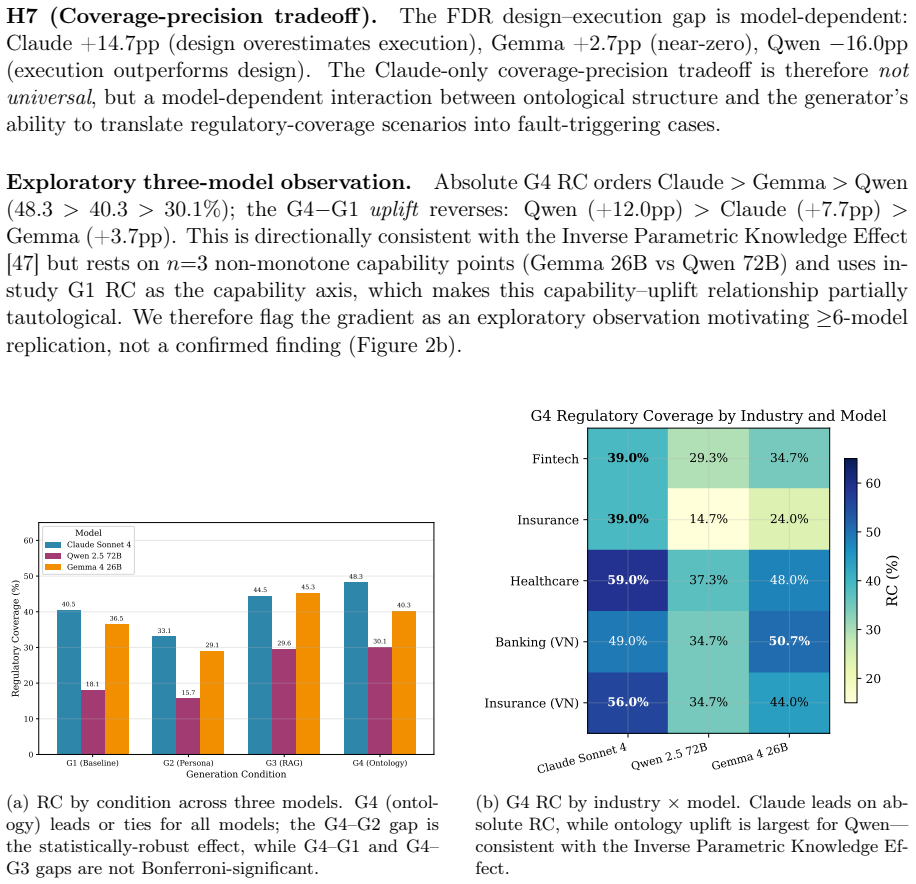
No significant circularity detected
full rationale
The paper's derivation chain consists of an empirical comparison: ontology-grounded scenario generation is evaluated against a persona-based baseline on regulatory coverage (48.3% vs 33.1%) and domain specificity, with cross-validation across three LLM families and 5,400 total scenarios. This rests on external measurement against primary-source requirements and an independent baseline rather than any self-definitional equivalence, fitted parameter renamed as prediction, or load-bearing self-citation. No equations, ansatzes, or uniqueness theorems are invoked that reduce the reported advantage to a tautology by construction. The ontology is treated as an input encoding requirements, but the performance delta is not forced by how the metrics are defined.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The chosen ontology faithfully encodes permissions, domain constraints, safety properties, governance rules, and autonomy levels for the target regulated industries.
invented entities (2)
-
Agent Operational Envelope
no independent evidence
-
Trust Certificate
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Concrete Problems in AI Safety
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. Concrete problems in AI safety.arXiv preprint arXiv:1606.06565, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei
Paul F. Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems (NeurIPS), volume 30, pages 4299–4307, 2017
2017
-
[3]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitu- tional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
CRC Press, 2017
Leanna Rierson.Developing Safety-Critical Software: A Practical Guide for Aviation Soft- ware and DO-178C Compliance. CRC Press, 2017. ISBN 978-1-4398-1368-3
2017
-
[5]
IEC 62304:2006+amd1:2015 — medical device software — software life cycle processes
International Electrotechnical Commission. IEC 62304:2006+amd1:2015 — medical device software — software life cycle processes. International Standard, 2015
2006
-
[6]
ISO 26262:2018 — road vehicles — func- tional safety
International Organization for Standardization. ISO 26262:2018 — road vehicles — func- tional safety. International Standard, 2018
2018
-
[7]
Lua.t phòng, chóng ru.a tiên [law on prevention and com- bat of money laundering], law no
National Assembly of Vietnam. Lua.t phòng, chóng ru.a tiên [law on prevention and com- bat of money laundering], law no. 14/2022/qh15. Passed November 15, 2022; effective March 1, 2023, 2022. Supersedes Law 07/2012/QH13; mandates risk-based customer due diligence and beneficial-ownership identification for credit institutions; aligned with FATF Recommenda...
2022
-
[8]
A., Mateos-Garcia, J., Bergman, S., Kay, J., Griffin, C., Bariach, B., et al
Laura Weidinger, Jonathan Uesato, Maribeth Rauh, Conor Griffin, Po-Sen Huang, John Mellor, Amelia Glaese, Myra Cheng, Borja Balle, Atoosa Kasirzadeh, et al. Sociotechnical safety evaluation of generative AI systems.arXiv preprint arXiv:2310.11986, 2023
-
[9]
AgentHarm: A benchmark for measur- ing harmfulness of LLM agents
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, Eric Winsor, Jerome Wynne, Yarin Gal, and Xander Davies. AgentHarm: A benchmark for measur- ing harmfulness of LLM agents. InInternational Conference on Learning Representations (ICLR), 2025. 110 maliciou...
2025
-
[10]
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Zhexin Zhang, Shiyao Cui, Yida Lu, Jingzhuo Zhou, Junxiao Yang, Hongning Wang, and Minlie Huang. Agent-SafetyBench: Evaluating the safety of LLM agents.arXiv preprint arXiv:2412.14470, 2025. 349 environments, 2,000 test cases, 8 risk categories. 22
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Visibility into AI agents.arXiv preprint arXiv:2401.13138, 2024
Alan Chan, Carson Ezell, Max Kaufmann, Kevin Wei, Lewis Hammond, Herbie Bradley, Emma Bluemke, Nitarshan Rajkumar, David Krueger, Noam Kolt, Lennart Heim, and Markus Anderljung. Visibility into AI agents.arXiv preprint arXiv:2401.13138, 2024
-
[12]
Xiaowei Huang, Daniel Kroening, Wenjie Ruan, James Sharp, Youcheng Sun, Emese Thesing, Min Wu, and Xinping Yi. A survey of safety and trustworthiness of deep neural networks: Formal verification, testing, adversarial attack and defence, and interpretability. Computer Science Review, 37:100270, 2020. doi: 10.1016/j.cosrev.2020.100270
-
[13]
Dill, Kyle Ju- lian, and Mykel J
Guy Katz, Clark Barrett, David L. Dill, Kyle Julian, and Mykel J. Kochenderfer. Re- luplex: An efficient SMT solver for verifying deep neural networks. InInternational Conference on Computer Aided Verification (CAV), pages 97–117. Springer, 2017. doi: 10.1007/978-3-319-63387-9_5
-
[14]
Hoang-Dung Tran, Xiaodong Yang, Diego Manzanas Lopez, Patrick Musau, Luan Viet Nguyen, Weiming Xiang, Stanley Bak, and Taylor T. Johnson. NNV: The neural network verification tool for deep neural networks and learning-enabled cyber-physical systems. In International Conference on Computer Aided Verification (CAV), pages 3–17. Springer, 2020
2020
-
[15]
Gagandeep Singh, Timon Gehr, Markus Püschel, and Martin Vechev. An abstract domain for certifying neural networks. InProceedings of the ACM on Programming Languages (POPL), volume 3, pages 1–30, 2019. doi: 10.1145/3290354
-
[16]
Alessio Lomuscio, Hongyang Qu, and Franco Raimondi. MCMAS: An open-source model checker for the verification of multi-agent systems.International Journal on Software Tools for Technology Transfer, 19(1):9–30, 2017. doi: 10.1007/s10009-015-0378-x
-
[17]
Towards guaranteed safe ai: A framework for ensuring robust and reliable ai systems, 2024
David Dalrymple, Joar Skalse, Yoshua Bengio, Stuart Russell, Max Tegmark, Sanjit Seshia, Steve Omohundro, Christian Szegedy, Ben Goldhaber, Nora Ammann, et al. Towards guaranteed safe AI: A framework for ensuring robust and reliable AI systems.arXiv preprint arXiv:2405.06624, 2024
-
[18]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. AgentBench: Evaluating LLMs as agents.arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36, 2023
2023
-
[20]
Red Teaming Language Models with Language Models
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red teaming language models with language models.arXiv preprint arXiv:2202.03286, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST), 2023. doi: 10.1145/3586183.3606763
-
[22]
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, and Tatsunori Hashimoto. Identifying the risks of LM agents with an LM-emulated sandbox.arXiv preprint arXiv:2309.15817, 2024. ICLR 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
The Rise and Potential of Large Language Model Based Agents: A Survey
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. The rise and potential of large language model based agents: A survey.arXiv preprint arXiv:2309.07864, 2023. 23
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024. doi: 10.1007/ s11704-024-40231-1
2024
-
[25]
Zhexin Zhang, Shiyao Cui, Yida Lu, Jingzhuo Zhou, Junxiao Yang, Hongning Wang, and Minlie Huang
Tongxin Yuan, Zhiwei He, Lingzhong Dong, Yiming Wang, Ruijie Zhao, Tian Xia, Lizhen Xu, Binglin Zhou, Fangqi Li, Zhuosheng Zhang, et al. R-Judge: Benchmarking safety risk awareness for LLM agents.arXiv preprint arXiv:2401.10019, 2024. EMNLP 2024
-
[26]
arXiv preprint arXiv:2412.13178 , year =
Sheng Yin, Xianghe Pang, Yuanzhuo Ding, Menglan Chen, Yutong Bi, Yichen Xiong, Wen- hao Huang, Zhen Xiang, Jing Shao, and Siheng Chen. SafeAgentBench: A benchmark for safe task planning of embodied LLM agents.arXiv preprint arXiv:2412.13178, 2025. 750 tasks, 10 hazard types, embodied environments
-
[27]
Agent simulation engine (A-SIM): Enterprise agent hardening at scale
Lyzr AI. Agent simulation engine (A-SIM): Enterprise agent hardening at scale. Technical documentation,https://www.lyzr.ai, 2026. Accessed March 2026
2026
-
[28]
A taxonomy of model-based testing approaches,
Mark Utting, Alexander Pretschner, and Bruno Legeard. A taxonomy of model-based testing approaches.Software Testing, Verification and Reliability, 22(5):297–312, 2012. doi: 10.1002/stvr.456
-
[29]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena.Advances in Neural Information Processing Systems (NeurIPS), 36, 2023
2023
-
[30]
Zamfirescu-Pereira, Björn Hartmann, Aditya G
Shreya Shankar, J.D. Zamfirescu-Pereira, Björn Hartmann, Aditya G. Parameswaran, and Ian Arawjo. Who validates the validators? Aligning LLM-assisted evaluation of LLM outputs with human preferences.arXiv preprint arXiv:2404.12272, 2024
-
[31]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al. A survey on LLM-as-a-judge.arXiv preprint arXiv:2411.15594, 2024. Comprehensive survey on reliability, bias, and domain- specific evaluation
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
AgentAuditor: Human-level safety and security evaluation for LLM agents
Hanjun Luo, Shenyu Dai, Chiming Ni, Xinfeng Li, Guibin Zhang, Kun Wang, Tongliang Liu, and Hanan Salam. AgentAuditor: Human-level safety and security evaluation for LLM agents. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. ASSEBench: 2,293 records, 15 risk types, 29 scenarios
2025
-
[33]
A survey on agent-as-a-judge.arXiv preprint arXiv:2601.05111, 2026
Runyang You, Hongru Cai, Caiqi Zhang, Qiancheng Xu, Meng Liu, Tiezheng Yu, Yongqi Li, and Wenjie Li. A survey on agent-as-a-judge.arXiv preprint arXiv:2601.05111, 2026. Survey: planning, tool-augmented verification, multi-agent collaboration for evaluation
-
[34]
Debnath, Abhijit Sanyal, Anirban Sarkar, Sankhayan Choudhury, and Wan D
Narayan C. Debnath, Abhijit Sanyal, Anirban Sarkar, Sankhayan Choudhury, and Wan D. Bae. Graph–semantic based web data model: Conceptual design to logical representation. Journal of Computational Methods in Sciences and Engineering (JCMSE), 11:77–88, 2011. doi: 10.3233/JCM-2011-0379
-
[35]
Automating web data model: Conceptual design to logical representation
Abhijit Sanyal, Anirban Sarkar, Sankhayan Choudhury, and Parag Kumar Guha Thakurta. Automating web data model: Conceptual design to logical representation. InProceedings of the ISCA 19th International Conference on Software Engineering and Data Engineering (SEDE), pages 179–184, 2010
2010
-
[36]
ACM Computing Surveys , author =
Aidan Hogan, Eva Blomqvist, Michael Cochez, Claudia d’Amato, Gerard de Melo, Claudio Gutierrez, Sabrina Kirrane, José Emilio Labra Gayo, Roberto Navigli, Sebastian Neumaier, etal. Knowledgegraphs.ACM Computing Surveys, 54(4):1–37, 2021. doi: 10.1145/3447772. 24
-
[37]
IEEE Transactions on Knowledge and Data Engineering36, 7 (2024), 3580–3599
Shirui Pan, Linhao Luo, Yufei Wang, Chen Chen, Jiapu Wang, and Xindong Wu. Uni- fying large language models and knowledge graphs: A roadmap.IEEE Transactions on Knowledge and Data Engineering, 36:3580–3599, 2024. doi: 10.1109/TKDE.2024.3352100
-
[38]
Artificial intelligence risk management framework (AI RMF 1.0)
National Institute of Standards and Technology. Artificial intelligence risk management framework (AI RMF 1.0). Technical Report NIST AI 100-1, U.S. Department of Commerce, 2023
2023
-
[39]
Regulation (EU) 2024/1689 — artificial intelligence act
European Parliament and Council. Regulation (EU) 2024/1689 — artificial intelligence act. Official Journal of the European Union, L series, 2024. Entered into force August 1, 2024
2024
-
[40]
Model AI governance framework
Infocomm Media Development Authority. Model AI governance framework. Technical report, IMDA, Singapore, 2020. Developed with PDPC
2020
-
[41]
ISO/IEC 42001:2023 — artificial intelli- gence — management system
International Organization for Standardization. ISO/IEC 42001:2023 — artificial intelli- gence — management system. International Standard, 2023
2023
-
[42]
OWASP top 10 for agentic applications for 2026
OWASP Foundation. OWASP top 10 for agentic applications for 2026. Technical report, OWASP Gen AI Security Project, 2025. First formal risk taxonomy for autonomous AI agents; T01–T17 threat model, 100+ contributors
2026
-
[43]
AI agent standards initiative
National Institute of Standards and Technology. AI agent standards initiative. Technical report, NIST Center for AI Standards and Innovation (CAISI), 2026. Announced February 2026; identity, security, interoperability for autonomous AI agents
2026
-
[44]
Agent governance toolkit: Open-source runtime security for AI agents
Microsoft. Agent governance toolkit: Open-source runtime security for AI agents. GitHub, MIT License, 2026. Addresses all 10 OWASP agentic risks; policy engine, execution sand- boxing, compliance grading
2026
-
[45]
Lua.t trí tue
National Assembly of Vietnam. Lua.t trí tue. nhân ta.o [law on artificial intelligence], law no. 134/2025/qh15. Passed December 10, 2025; effective March 1, 2026, 2025. Three- tier risk classification (low/medium/high); 18-month grace period for finance, healthcare, education
2025
-
[46]
Government of Vietnam. Nghı. d.ı.nh 94/2025/nđ-cp [decree on regulatory sandbox in the banking sector]. Effective July 1, 2025, 2025. First comprehensive fintech sandbox regula- tion; structured framework for AI-enabled financial services
2025
-
[47]
Thanh Tuan Luong. Ontology-constrained neural reasoning in enterprise agentic sys- tems: A neurosymbolic architecture for domain-grounded ai agents.arXiv preprint arXiv:2604.00555, 2026. 600 runs across 5 industries; Inverse PKE finding
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
The temporal logic of programs
Amir Pnueli. The temporal logic of programs. In18th Annual Symposium on Foundations of Computer Science (FOCS), pages 46–57. IEEE, 1977. doi: 10.1109/SFCS.1977.32
-
[49]
Clarke, Ofer Strichman, and Yunshan Zhu
Armin Biere, Alessandro Cimatti, Edmund M. Clarke, Ofer Strichman, and Yunshan Zhu. Bounded model checking.Advances in Computers, 58:117–148, 2003. doi: 10.1016/ S0065-2458(03)58003-2
2003
-
[50]
PRISM 4.0: Verification of probabilistic real-time systems.Proceedings of CAV, pages 585–591, 2011
Marta Kwiatkowska, Gethin Norman, and David Parker. PRISM 4.0: Verification of probabilistic real-time systems.Proceedings of CAV, pages 585–591, 2011. doi: 10.1007/ 978-3-642-22110-1_47
2011
-
[51]
Introduction to runtime verification
Ezio Bartocci, Yliès Falcone, Adrian Francalanza, and Giles Reger. Introduction to runtime verification. InLectures on Runtime Verification, pages 1–33. Springer, 2018. doi: 10.1007/ 978-3-319-75632-5_1. 25
2018
-
[52]
FAOS research: Code, data, and ontologies for ontology-grounded enterprise agent verification.https://github.com/frank-luongt/ faos-research/tree/main/RA-6, 2026
Thanh Tuan Luong and Abhijit Sanyal. FAOS research: Code, data, and ontologies for ontology-grounded enterprise agent verification.https://github.com/frank-luongt/ faos-research/tree/main/RA-6, 2026. GitHub repository. Analysis scripts, ontology con- text files, regulatory checklists, fault definitions, and cross-model analysis code. Raw sce- nario data a...
2026
-
[53]
Circular 06/2024/tt-btc on risk management in insurance business activity
Ministry of Finance of Vietnam. Circular 06/2024/tt-btc on risk management in insurance business activity. Issued February 16, 2024; effective April 1, 2024, 2024. Risk-management framework for insurance and reinsurance undertakings; Article 18 covers capital adequacy and solvency margin requirements; supersedes provisions of Circular 50/2017/TT-BTC
2024
-
[54]
Edmund M. Clarke, ThomasA. Henzinger, Helmut Veith, andRoderick Bloem.Handbook of Model Checking. Springer, 2018. ISBN 978-3-319-10574-1. doi: 10.1007/978-3-319-10575-8
-
[55]
RA-6: Ontology-grounded pre-deployment verifi- cation of enterprise AI agents — pilot data and judge logs.https://doi.org/10.5281/ zenodo.20484582, 2026
Thanh Tuan Luong and Abhijit Sanyal. RA-6: Ontology-grounded pre-deployment verifi- cation of enterprise AI agents — pilot data and judge logs.https://doi.org/10.5281/ zenodo.20484582, 2026. Dataset (version v0.2). 26
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.