PointDiT: Pixel-Space Diffusion for Monocular Geometry Estimation
Pith reviewed 2026-07-03 14:32 UTC · model grok-4.3
The pith
A plain ViT diffusion model operating directly on raw point map patches outperforms latent diffusion models for single-image 3D geometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A pixel-space Diffusion Transformer using a plain ViT backbone, trained from scratch on raw 3D point map patches and conditioned solely on DINOv3 image tokens, surpasses complex latent-based diffusion models while remaining simpler than hybrid alternatives and yields sharper geometric structure with greater robustness in ambiguous regions.
What carries the argument
PointDiT: a pixel-space Diffusion Transformer that operates directly on raw 3D point map patches without any tokenizer, conditioned on DINOv3 image tokens.
If this is right
- Sharper geometric structure emerges without specialized loss formulations.
- Robustness improves in regions with transparency or depth ambiguity.
- Deployment simplifies by removing the need for point-map tokenizers and latent encoders.
- Training remains feasible entirely from scratch on the target geometry representation.
Where Pith is reading between the lines
- The method may extend naturally to other dense prediction tasks where direct pixel-space modeling avoids quantization artifacts.
- Removing reliance on pre-trained latent spaces could allow faster adaptation when new sensor modalities appear.
- The approach suggests that diffusion on explicit geometric outputs can serve as a baseline for comparing future architectural additions.
Load-bearing premise
That training a standard ViT diffusion model from scratch directly on point-map patches without tokenizers or pre-trained latents suffices to exceed the performance of more elaborate latent and hybrid systems.
What would settle it
A controlled experiment in which a latent diffusion model with equivalent training compute and data produces equal or superior results on standard monocular geometry benchmarks.
Figures




read the original abstract
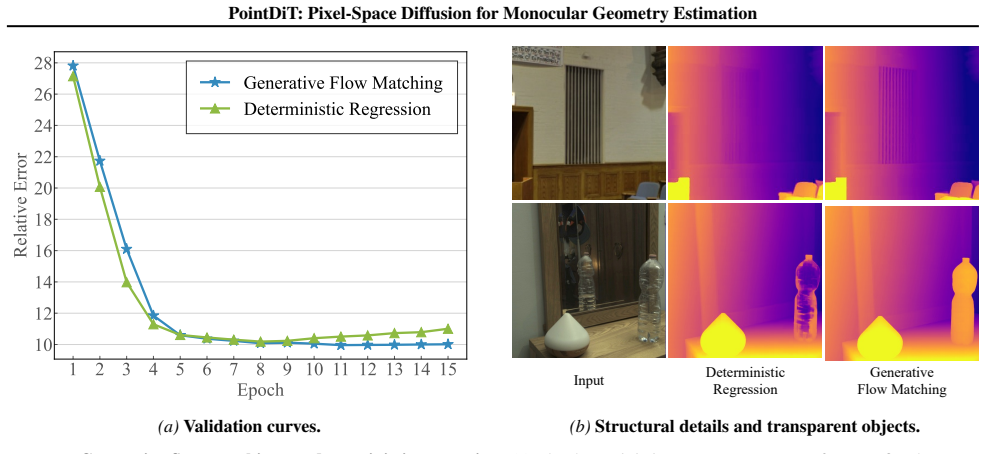
State-of-the-art single-image 3D reconstruction methods often rely on complex hybrid architectures and loss functions, or compress geometry into latent spaces in order to leverage pre-trained latent diffusion models. In this work, we show that such architectural overhead and intricate loss formulations are unnecessary. We introduce a minimalist pixel-space Diffusion Transformer, built on a plain ViT, that operates directly on raw 3D point map patches and is conditioned on image tokens from a pre-trained DINOv3. Unlike existing latent diffusion approaches, we train our diffusion backbone entirely from scratch, eliminating the need for point map tokenizers. Despite its simplicity, our approach surpasses complex latent-based diffusion models while remaining significantly simpler than hybrid alternatives. Notably, it produces sharper geometric structure and is more robust in highly ambiguous regions, such as transparent objects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PointDiT, a minimalist pixel-space Diffusion Transformer built on a plain ViT that operates directly on raw 3D point map patches conditioned solely on frozen DINOv3 image tokens. It is trained entirely from scratch without any point-map tokenizer or latent compression, and claims to surpass complex latent-based diffusion models and hybrid alternatives in accuracy while producing sharper geometric structure and greater robustness in ambiguous regions such as transparent objects for monocular geometry estimation.
Significance. If the performance claims are substantiated by rigorous experiments, the result would indicate that direct pixel-space diffusion on raw point maps can eliminate the need for latent spaces, tokenizers, or hybrid architectural scaffolding in single-image 3D reconstruction, offering a simpler and potentially more scalable alternative to current state-of-the-art methods.
major comments (2)
- [Abstract] Abstract: The central claim that the approach 'surpasses complex latent-based diffusion models' and is 'more robust in highly ambiguous regions' is asserted without any quantitative results, baseline comparisons, ablation studies, or error metrics. This absence makes it impossible to evaluate whether the minimalist ViT diffusion on raw patches actually delivers the stated superiority.
- [Abstract] Method description (inferred from abstract): The premise that a plain ViT diffusion process on raw 3D point-map patches requires 'no auxiliary representation learning' is load-bearing for the simplicity argument, yet the text provides no details on point-map normalization, patch embedding, or handling of scale/ambiguity that might implicitly reintroduce complexity equivalent to a tokenizer.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to clarify points raised about the abstract. The manuscript provides supporting experiments and method details in later sections; we address the specific concerns below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the approach 'surpasses complex latent-based diffusion models' and is 'more robust in highly ambiguous regions' is asserted without any quantitative results, baseline comparisons, ablation studies, or error metrics. This absence makes it impossible to evaluate whether the minimalist ViT diffusion on raw patches actually delivers the stated superiority.
Authors: We agree the abstract presents claims at a high level without numbers. The full manuscript contains quantitative results in the Experiments section, including tables with RMSE, accuracy@threshold metrics, and direct comparisons against latent diffusion baselines, plus ablations on ambiguous regions. To make the abstract self-contained, we will revise it to include one or two key quantitative highlights from the main results. revision: yes
-
Referee: [Abstract] Method description (inferred from abstract): The premise that a plain ViT diffusion process on raw 3D point-map patches requires 'no auxiliary representation learning' is load-bearing for the simplicity argument, yet the text provides no details on point-map normalization, patch embedding, or handling of scale/ambiguity that might implicitly reintroduce complexity equivalent to a tokenizer.
Authors: The abstract summarizes the approach; the method section details the processing: point maps are normalized to a fixed range per scene, embedded via a simple linear projection on the raw (x,y,z) patches with no learned tokenizer or VQ, and scale/ambiguity is handled through the diffusion objective and DINO conditioning alone. We will add a short clarifying sentence in the abstract to explicitly note the direct raw-patch embedding and absence of auxiliary representation learning. revision: yes
Circularity Check
No circularity: method trained from scratch on raw patches with external conditioning
full rationale
The paper presents an empirical method: a plain ViT diffusion model trained entirely from scratch directly on raw 3D point-map patches, conditioned only on frozen pre-trained DINOv3 tokens, with no point-map tokenizer. No equations, predictions, or first-principles derivations are shown that reduce the claimed superiority to a fitted quantity or self-citation chain by construction. The abstract explicitly contrasts the approach against latent/hybrid methods without invoking authors' prior uniqueness theorems or ansatzes. The central claim rests on experimental comparison rather than definitional equivalence, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2001.10773,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[2]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[3]
Lotus: Diffusion-based visual foundation model for high-quality dense prediction, 2025
He, J., Li, H., Yin, W., Liang, Y ., Li, L., Zhou, K., Zhang, H., Liu, B., and Chen, Y .-C. Lotus: Diffusion-based visual foundation model for high-quality dense prediction.arXiv preprint arXiv:2409.18124,
-
[4]
Jung, H., Ruhkamp, P., Zhai, G., Brasch, N., Li, Y ., Verdie, Y ., Song, J., Zhou, Y ., Armagan, A., Ilic, S., et al. Is my depth ground-truth good enough? hammer – highly ac- curate multi-modal dataset for dense 3d scene regression. arXiv preprint arXiv:2205.04565,
-
[5]
Progressive Distillation for Fast Sampling of Diffusion Models
Salimans, T. and Ho, J. Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Sim´eoni, O., V o, H. V ., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V ., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al. Dinov3.arXiv preprint arXiv:2508.10104,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Vasiljevic, I., Kolkin, N., Zhang, S., Luo, R., Wang, H., Dai, F. Z., Daniele, A. F., Mostajabi, M., Basart, S., Walter, M. R., and Shakhnarovich, G. Diode: A dense indoor and outdoor depth dataset.arXiv preprint arXiv:1908.00463,
-
[8]
Vggt: Visual geometry grounded transformer
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., and Novotny, D. Vggt: Visual geometry grounded transformer. InCVPR, 2025a. Wang, Q., Zheng, S., Yan, Q., Deng, F., Zhao, K., and Chu, X. Irs: A large synthetic indoor robotics stereo dataset for disparity and surface normal estimation.arXiv preprint arXiv:1912.09632,
-
[9]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
Wang, R., Xu, S., Dai, C., Xiang, J., Deng, Y ., Tong, X., and Yang, J. Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InCVPR, 2025b. Wang, R., Xu, S., Dong, Y ., Deng, Y ., Xiang, J., Lv, Z., Sun, G., Tong, X., and Yang, J. Moge-2: Accurate monocu- lar geometry with metric scale and sharp ...
work page internal anchor Pith review Pith/arXiv arXiv
- [10]
-
[11]
Diffusion Transformers with Representation Autoencoders
Zheng, B., Ma, N., Tong, S., and Xie, S. Diffusion trans- formers with representation autoencoders.arXiv preprint arXiv:2510.11690,
work page internal anchor Pith review Pith/arXiv arXiv
- [12]
-
[13]
12 PointDiT: Pixel-Space Diffusion for Monocular Geometry Estimation Appendix A. Experimental Details We train our PointDiT on synthetic datasets that provide dense, accurate ground-truth depth together with known camera intrinsics, and we evaluate zero-shot on unseen real-world benchmarks. From each image we back-project the depth map through the intrins...
2017
-
[14]
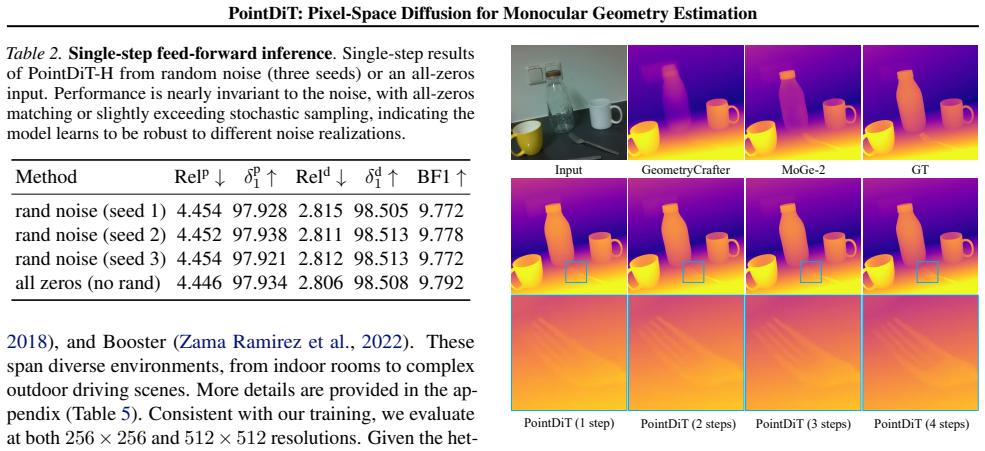
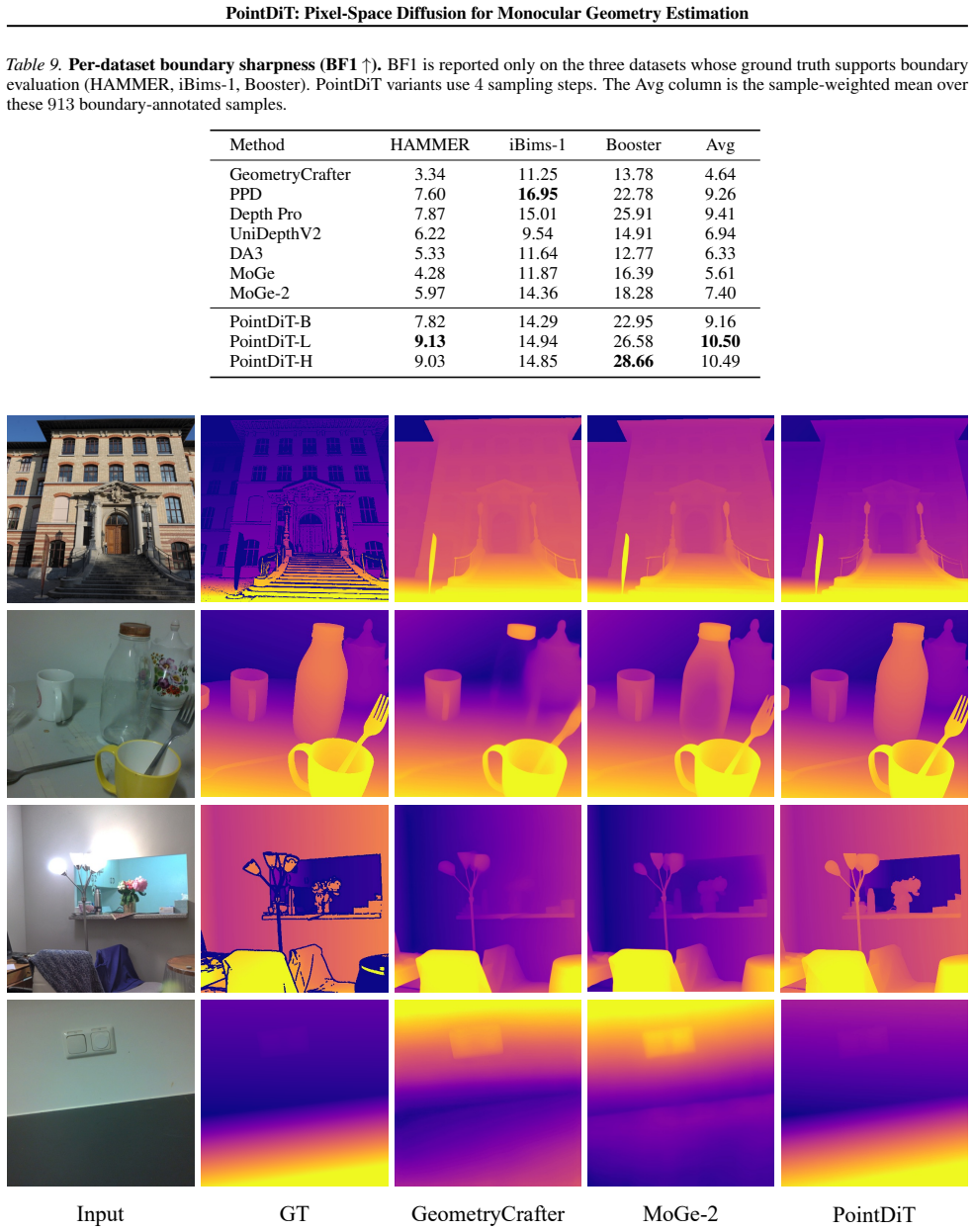
PointDiT variants use 4 sampling steps, and the Avg column is the sample-weighted mean over all evaluation samples. Overall, PointDiT-H attains the best average depth accuracy, PointDiT achieves the sharpest 14 PointDiT: Pixel-Space Diffusion for Monocular Geometry Estimation Table 7.Per-dataset point map results.Rel p ↓ and δp 1 ↑ for each of the seven e...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.