Compute Aligned Training: Optimizing for Test Time Inference
Pith reviewed 2026-05-21 08:37 UTC · model grok-4.3
The pith
Training language models with losses that anticipate test-time strategies improves results when those strategies are later applied.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
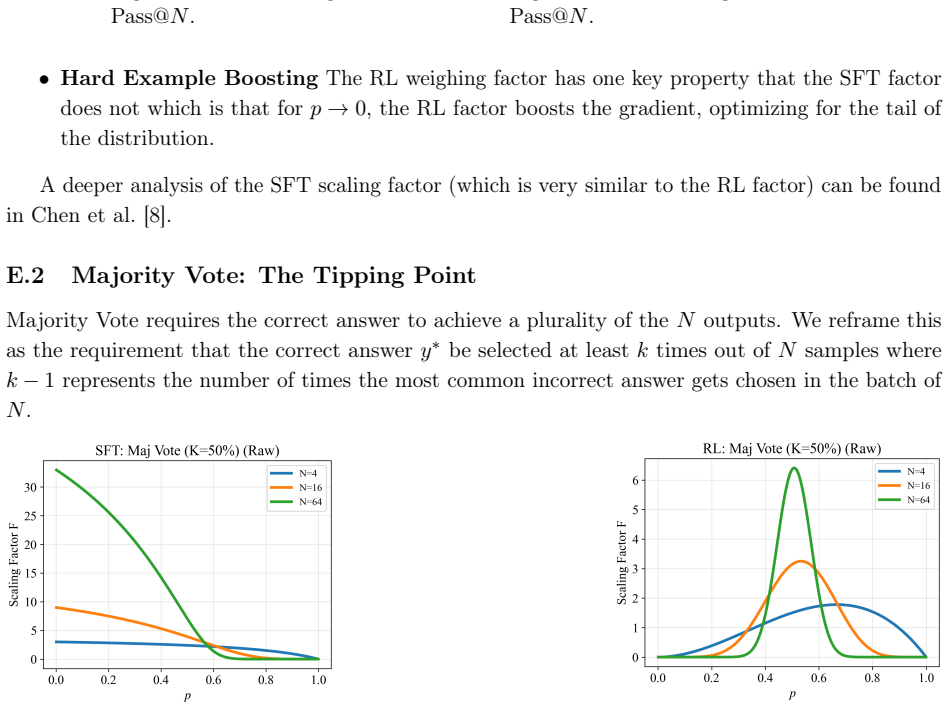
By conceptualizing inference strategies as operators on the base policy, new loss functions are derived that maximize performance when said strategies are applied. The approach is instantiated for SFT and RL across common test-time strategies, and empirical results indicate substantial gains in test-time scaling over standard training.
What carries the argument
Modeling inference strategies as operators on the base policy in order to derive loss functions aligned with their use at test time.
If this is right
- Models trained with the derived losses exhibit higher final accuracy when the corresponding test-time operator is applied.
- The alignment method extends to both supervised fine-tuning and reinforcement learning training regimes.
- Performance improves more steeply as additional compute is allocated at inference time compared with conventionally trained models.
- New loss functions become available for any inference strategy once a suitable operator is defined.
Where Pith is reading between the lines
- The same operator-based alignment could be applied to training pipelines that use search or planning at test time.
- Developers might begin designing inference procedures first and then back-propagate the required losses into training.
- Models could be trained under explicit assumptions about the inference budget rather than pure next-token likelihood.
- Hybrid systems that jointly optimize training losses and test-time operators may emerge as a next step.
Load-bearing premise
Test-time strategies can be modeled as operators on the base policy such that the resulting losses improve actual inference procedures without creating new failure modes.
What would settle it
A direct comparison in which a model trained with the new loss for a chosen strategy, such as best-of-N, shows no accuracy gain over a standard model when best-of-N is actually run at test time on new tasks.
Figures














read the original abstract
Scaling test-time compute has emerged as a powerful mechanism for enhancing Large Language Model (LLM) performance. However, standard post-training paradigms, Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), optimize the likelihood of individual samples under a base policy, creating a misalignment with test time procedures that rely on aggregated or filtered outputs. In this work, we propose Compute Aligned Training, which aligns training objectives with test-time strategies. By conceptualizing inference strategies as operators on the base policy, we derive new loss functions that maximize performance when said strategies are applied. We instantiate such loss functions for SFT and RL across common test time strategies. Finally, we provide empirical evidence that this training method substantially improves test time scaling over standard training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Compute Aligned Training for LLMs, framing test-time inference strategies (e.g., self-consistency, best-of-N) as operators O acting on a base policy π. It derives new loss functions for both SFT and RL that optimize expected performance under O(π) rather than under the base policy alone, and reports empirical results showing improved test-time scaling compared to standard SFT/RL baselines.
Significance. If the operator-based losses are correctly derived and the reported gains are robust, the work would offer a principled route to close the train-test mismatch that currently limits returns from test-time compute. The framing could generalize across multiple aggregation strategies and provide a template for future alignment of training objectives with inference procedures.
major comments (3)
- [§3] §3 (Loss Derivation): For non-linear operators such as majority vote or self-consistency, the effective operator O(π) changes as π is updated during training. The gradient of the proposed loss therefore depends on the current policy; the manuscript does not show that the final model is a stationary point of the intended test-time objective or provide a convergence argument that accounts for this non-stationarity.
- [§4] §4 (Empirical Evaluation): The abstract and results claim substantial improvements in test-time scaling, yet no equations, exact loss formulations, baseline details, or error bars are visible in the provided text. Without these, it is impossible to verify whether the gains survive the non-stationarity concern or simply reflect higher base likelihoods.
- [§2] §2 (Operator Definition): The claim that any test-time strategy can be usefully modeled as a fixed operator on the base policy is load-bearing. For strategies that involve sampling multiple trajectories and then aggregating, the mapping is stochastic and policy-dependent; the paper does not demonstrate that the derived losses remain well-defined or produce models that generalize to real inference pipelines without additional hyperparameter tuning.
minor comments (2)
- [§3] Notation for the operator O and the resulting loss should be introduced with an explicit equation early in §3 rather than described only in prose.
- [§3] The manuscript should include a short table comparing the proposed losses to standard SFT/RL objectives side-by-side.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, clarifying our approach and indicating where revisions have been made to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Loss Derivation): For non-linear operators such as majority vote or self-consistency, the effective operator O(π) changes as π is updated during training. The gradient of the proposed loss therefore depends on the current policy; the manuscript does not show that the final model is a stationary point of the intended test-time objective or provide a convergence argument that accounts for this non-stationarity.
Authors: We agree that non-linear operators introduce non-stationarity because O(π) depends on the evolving policy. Our derivation computes the gradient with respect to the current policy at each step, treating the operator application as fixed for that gradient computation—an approximation common in policy optimization. In the revised manuscript we have added a paragraph in §3 discussing this dependence, along with a simple argument that under sufficiently slow policy updates the procedure reaches an approximate stationary point of the test-time objective. We also report additional training curves showing convergence to improved test-time performance. A fully rigorous convergence proof for arbitrary non-linear operators is left for future work. revision: partial
-
Referee: [§4] §4 (Empirical Evaluation): The abstract and results claim substantial improvements in test-time scaling, yet no equations, exact loss formulations, baseline details, or error bars are visible in the provided text. Without these, it is impossible to verify whether the gains survive the non-stationarity concern or simply reflect higher base likelihoods.
Authors: The complete manuscript contains the exact loss derivations (Equations 3–7 in §3) for both the SFT and RL cases, together with the operator definitions and baseline implementations. Standard SFT and RLHF objectives serve as the baselines. We have revised §4 to include error bars computed over five random seeds for all scaling curves and have added a table listing the precise loss formulations and hyper-parameters. These additions allow direct verification that the reported gains arise from alignment with the test-time operator rather than from increased base likelihood alone. revision: yes
-
Referee: [§2] §2 (Operator Definition): The claim that any test-time strategy can be usefully modeled as a fixed operator on the base policy is load-bearing. For strategies that involve sampling multiple trajectories and then aggregating, the mapping is stochastic and policy-dependent; the paper does not demonstrate that the derived losses remain well-defined or produce models that generalize to real inference pipelines without additional hyperparameter tuning.
Authors: We define each test-time strategy as a (possibly stochastic) operator O that maps the base policy π to an effective output distribution or selection process; the training loss is the expected performance under samples drawn from O(π). Although the mapping is stochastic and policy-dependent for multi-sample aggregation, the loss remains well-defined as an expectation that can be estimated by sampling during training. Experiments in §4 demonstrate that models trained with these losses improve scaling curves when evaluated in standard inference pipelines using the same hyper-parameters reported in the paper, without requiring additional tuning. We have added a clarifying sentence in §2 on the stochastic nature of the operator and how it is handled in the Monte-Carlo estimate of the loss. revision: partial
Circularity Check
Derivation self-contained with no reduction to inputs by construction
full rationale
The paper models test-time strategies as operators on the base policy and derives aligned loss functions for SFT and RL to optimize performance under those operators. No equations, self-citations, or fitted parameters are presented that reduce the claimed losses or predictions directly back to the same test-time behaviors by definition or statistical forcing. The conceptual framing introduces an independent alignment objective rather than renaming or tautologically re-expressing existing quantities, and the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By conceptualizing inference strategies as operators on the base policy, we derive new loss functions... ˜πθ(y|x) = T(πθ(·|x), ϕ)(y)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
wpass,SFT(p,N) = N p (1-p)^{N-1} / (1-(1-p)^N)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
What should post-training optimize? A test-time scaling law perspective
Tail-extrapolated estimators approximate best-of-N policy gradients from limited training rollouts by leveraging upper-tail reward statistics under structural assumptions.
Reference graph
Works this paper leans on
-
[1]
Richard S Sutton. The bitter lesson. http://www.incompleteideas.net/IncIdeas/ BitterLesson.html, 2019. Blog post, Incomplete Ideas
work page 2019
-
[2]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020. URLhttps://arxiv.org/abs/2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[4]
URLhttps://arxiv.org/abs/2408.03314
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Chain-of-thought prompting elicits reason- ing in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reason- ing in large language models. InAdvances in Neural Information Processing Sys- tems, 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/file/ 9d5609613524ecf4f15af0f7b31abca4-Paper-Conference.pdf
work page 2022
-
[6]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021. URLhttps: //arxiv.org/abs/2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations, 2023. URL https:// openreview.net/forum?id=1PL1NIMMrw
work page 2023
-
[8]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021. URLhttps://arxiv.org/ abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Feng Chen, Allan Raventós, Nan Cheng, Surya Ganguli, and Shaul Druckmann. Rethinking fine- tuning when scaling test-time compute: Limiting confidence improves mathematical reasoning. InAdvances in Neural Information Processing Systems, 2025. URLhttps://openreview.net/ forum?id=jvVQeSMeGM
work page 2025
-
[10]
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? InAdvances in Neural Information Processing Systems, 2025. URLhttps://openreview.net/ forum?id=4OsgYD7em5
work page 2025
-
[11]
Weight ensembling improves reasoning in language models
Xingyu Dang, Christina Baek, Kaiyue Wen, J Zico Kolter, and Aditi Raghunathan. Weight ensembling improves reasoning in language models. InConference on Language Modeling, 2025. URLhttps://openreview.net/forum?id=S2IKxulLT1. 13
work page 2025
- [13]
-
[14]
Inference-aware fine- tuning for best-of-n sampling in large language models
Yinlam Chow, Guy Tennenholtz, Izzeddin Gur, Vincent Zhuang, Bo Dai, Aviral Kumar, Rishabh Agarwal, Sridhar Thiagarajan, Craig Boutilier, and Aleksandra Faust. Inference-aware fine- tuning for best-of-n sampling in large language models. InInternational Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=77gQUdQhE7
work page 2025
-
[15]
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Chaplot Devendra, Guillaume Lample, et al. Mistral 7b.arXiv preprint arXiv:2310.06825, 2023. URL https: //arxiv.org/abs/2310.06825. License: Apache 2.0
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. InAdvances in Neural Information Processing Systems, 2021. URLhttps://arxiv.org/abs/ 2103.03874. License: MIT
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Protgpt2 is a deep unsupervised language model for protein design.Nature Communications, 13, 2022
Noelia Ferruz, Steffen Schmidt, and Birte Höcker. Protgpt2 is a deep unsupervised language model for protein design.Nature Communications, 13, 2022. URLhttps://www.nature.com/ articles/s41467-022-32007-7. License: MIT
work page 2022
-
[18]
Accurate computational design of multipass transmembrane proteins.Science, 359(6379):1042–1046, 2018
Peilong Lu, Duan Min, Frank DiMaio, Karen Y Wei, Michael D Vahorn, Jacob M Snyder, Thomas J Riley, and David Baker. Accurate computational design of multipass transmembrane proteins.Science, 359(6379):1042–1046, 2018
work page 2018
-
[19]
Protein folding and misfolding.Nature, 426(6968):884–890, 2003
Christopher M Dobson. Protein folding and misfolding.Nature, 426(6968):884–890, 2003
work page 2003
-
[20]
Dominic Esposito and Deb K Chatterjee. Enhancement of soluble protein expression through the use of fusion tags.Current opinion in biotechnology, 17(4):353–358, 2006
work page 2006
-
[21]
Soraia Costa, Andreia Almeida, Artur Castro, and Lucília Domingues. Fusion tags for protein solubility, purification and immunogenicity in escherichia coli: the novel fh8 system.Frontiers in microbiology, 5:63, 2014
work page 2014
-
[22]
University of Michigan Press, 1975
John H Holland.Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence. University of Michigan Press, 1975
work page 1975
-
[23]
Bandit based monte-carlo planning
Levente Kocsis and Csaba Szepesvári. Bandit based monte-carlo planning. InEuropean Conference on Machine Learning, pages 282–293, 2006
work page 2006
-
[24]
Scaling Test-Time Compute for Agentic Coding
Joongwon Kim, Wannan Yang, Kelvin Niu, Hongming Zhang, Yun Zhu, Eryk Helenowski, Ruan Silva, Zhengxing Chen, Srinivasan Iyer, Manzil Zaheer, Daniel Fried, Hannaneh Hajishirzi, Sanjeev Arora, Gabriel Synnaeve, Ruslan Salakhutdinov, and Anirudh Goyal. Scaling test-time compute for agentic coding, 2026. URLhttps://arxiv.org/abs/2604.16529
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Ian Goodfellow, Yoshua Bengio, and Aaron Courville.Deep Learning. MIT Press, 2016. URL http://www.deeplearningbook.org. 14
work page 2016
-
[26]
Policy gradient methods for reinforcement learning with function approximation
Richard S Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient methods for reinforcement learning with function approximation. InAdvances in Neural Information Processing Systems, volume 12, 1999. URLhttps://proceedings.neurips.cc/ paper/1999/file/464d828b85b0bed98e80ade0a5c43b0f-Paper.pdf
work page 1999
-
[27]
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist rein- forcement learning.Machine Learning, 8:229–256, 1992. URLhttps://link.springer.com/ article/10.1007/BF00992696
-
[28]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Alan Song, Mingchuan Xiao, et al. Deepseek- math: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. URLhttps://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. URLhttps://arxiv. org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation. InInternational Con- ference on Learning Representations, 2016. URLhttps://arxiv.org/abs/1506.02438
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[31]
Understanding the impact of entropy on policy optimization
Zafarali Ahmed, Nicolas Le Roux, Mohammad Norouzi, and Dale Schuurmans. Understanding the impact of entropy on policy optimization. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 151–160. PMLR, 09–15 Jun 2019. URL htt...
work page 2019
-
[32]
Maximum entropy RL (provably) solves some robust RL problems
Benjamin Eysenbach and Sergey Levine. Maximum entropy RL (provably) solves some robust RL problems. InInternational Conference on Learning Representations, 2022. URLhttps: //arxiv.org/abs/2103.06257
-
[33]
Parikshit Gopalan, Adam Tauman Kalai, Omer Reingold, Vatsal Sharan, and Udi Wieder. Omnipredictors, 2021. URLhttps://arxiv.org/abs/2109.05389
-
[34]
Unsloth: Accelerating large language model fine-tuning, 2023
Daniel Han and Michael Han. Unsloth: Accelerating large language model fine-tuning, 2023. URLhttps://github.com/unslothai/unsloth. License: Apache 2.0
work page 2023
-
[35]
Peft: State-of-the-art parameter-efficient fine-tuning methods, 2022
Sourab Mangrulkar, Sylvain Gugger, Lysandre Debut, Younes Belkada, Sayak Paul, and Benjamin Bossan. Peft: State-of-the-art parameter-efficient fine-tuning methods, 2022. URL https://github.com/huggingface/peft. License: Apache 2.0
work page 2022
-
[36]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Transformers: State-of- the-ar...
work page 2020
-
[37]
Trl: Transformer reinforcement learning, 2020
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. Trl: Transformer reinforcement learning, 2020. URLhttps://github.com/huggingface/trl. License: Apache 2.0
work page 2020
-
[38]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022. URLhttps://openreview.net/forum?id= nZeVKeeFYf9
work page 2022
-
[39]
Qlora: Ef- ficient finetuning of quantized llms
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Ef- ficient finetuning of quantized llms. InAdvances in Neural Information Processing Systems, 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 1feb87871436031bdc0f2beaa62a049b-Abstract-Conference.html
work page 2023
-
[40]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. URLhttps://openreview.net/forum?id= Bkg6RiCqY7
work page 2019
-
[41]
bitsandbytes: Accessible large language models via k-bit quantization for pytorch, 2022
Tim Dettmers, Mike Lewis, Sam Shleifer, and Luke Zettlemoyer. bitsandbytes: Accessible large language models via k-bit quantization for pytorch, 2022. URLhttps://github.com/ bitsandbytes-foundation/bitsandbytes. License: MIT
work page 2022
-
[42]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems, volume 35, pages 27730–27744, 2022. URLhttps://proceedings.neurips.cc/paper_files/ pa...
work page 2022
-
[43]
Pairwise Contrastive (Hybrid):A joint objective combining standard SFT with a token- level contrastive loss, weighted equally (0.5· LCE + 0.5· L Contrast). Contrastive ImplementationInstead of explicitly calculating the full margin over the sequence, we implemented a computationally efficient pairwise approximation. For each valid token in the ground trut...
-
[44]
Conservative Magnitude:Because the error vector aligns with our approximation, our calculated scalar weight strictly underestimates the true learning signal. Theorem 3(Directional Alignment and Conservative Bound).Assuming proportional decay and a competitive test-time strategy, the off-diagonal error aligns with the diagonal approximation (⟨gdiag, ϵvec⟩ ...
work page 2000
-
[45]
Luckily, if the answer is incorrect,R(yi|x)is0anyways. Thus the RL update weight for a sampleyi is: ˜Rpass(yi|x) =R(y i|x)·N(1−p) N−1 (54) B.2.2 Majority Vote (Dynamic Threshold) Previously, we computed˜p=PN i=k N i pi(1 −p )N−i and ∂˜p ∂p = N N−1 k−1 pk−1(1 −p )N−k with k being the threshold required for the answer to be chosen. Previously, we had chosen...
-
[46]
Step Size Stability:The expected magnitude of the CAT multiplier across the batch is exactly 1 (E[ ˜w] = 1). This completely decouples the scale of the learning rate from the test-time budgetN, ensuring optimization stability regardless of the strategy used. 2.Preservation of Relative Capacity:Because the normalization factor is shared across all prompts ...
work page 2000
-
[47]
Winner-Take-All Dynamics.As visualized in Figure 16, the gradient weight vanishes for the bottom percentile of samples and explodes for the top percentile. The objective effectively ignores "average" performance. If a sample is not in the top quantile of the model’s potential outputs, it contributes zero signal. The model is only updated based on its best...
-
[48]
Breaking Mode Collapse.Standard objectives maximizeexpectedutility. To minimize variance and maximize the average, these objectives encourage the model to collapse probability mass onto a single mode, usually a "safe," generic response. Diverging from this safe mode is typically penalized, as low-probability paths are treated as noise. Best-of-N inverts t...
-
[49]
The "Safety Net" Effect.Because the inference strategy acts as a filter, the model is not penalized for generatingN− 1failures, provided the N-th sample succeeds. This effectively creates a safety net during training. The objective signals to the model:"You are allowed to failN− 1times, as long as your variance is high enough to produce one winner."This t...
-
[50]
Gradients here are "wasted" on perfecting samples that are already good enough
The Waste Region (Ωwaste):Where the training objective applies pressure, but the test metric is already satiated (wtest ≈ 0). Gradients here are "wasted" on perfecting samples that are already good enough
-
[51]
The Starvation Region (Ωstarve):Where the test metric demands improvement (wtest > 0), but the training objective provides no signal (wtrain ≈0). 51 The Alignment Coefficient A is mathematically dominated by the integral over the overlap Soverlap. Therefore, a lowA guarantees high gradient misallocation. It allows us to detect inefficiency without needing...
-
[52]
on the 4-bit quantized [37] Mistral-7B-Instruct-v0.2 model. We use the AdamW [38] optimizer. A critical detail of our GRPO setup is the group size (number of generations per prompt), which we set toG = 4to balance variance reduction with memory constraints. The full optimization hyperparameters are detailed in Table 11. J.2 Reward Formulation Because Pass...
-
[53]
SFT Warmup:The model was first fine-tuned for 3 epochs on the target dataset (MATH levels 1–3) using standard Cross-Entropy loss. This phase stabilizes the instruction-following capabilities and ensures the model outputs valid reasoning traces
-
[54]
Strategy-Aware RL:The warmed-up model was then trained for 1 epoch using our custom weighted gradient estimator. K.2 Dynamic Consensus Thresholding A critical challenge in optimizing for Majority Vote is determining the required consensus threshold k during training. While at test timek is fixed (e.g.,⌊N/2⌋ + 1), during training with small batch sizes (ro...
-
[55]
Superiority of RL Weights:The RL_Wt_Maj4 model achieves the highest asymptotic performance (23.00% at Maj@16), outperforming both the baseline and the SFT-weighted variants. This supports the hypothesis that the "spotlight" behavior of the raw derivative, which vanishes for easy/hard samples and explodes at the boundary,is a feature, not a bug, for consen...
- [56]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.