REVIEW 3 major objections 2 minor 2 cited by
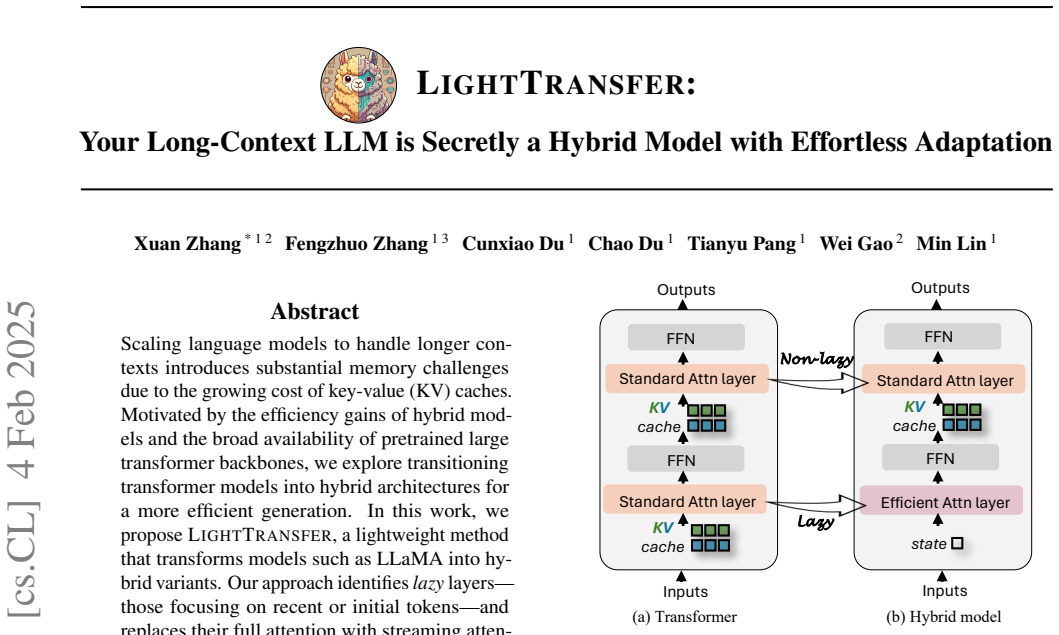
Pretrained LLMs convert to hybrid models by replacing attention in lazy layers with streaming attention, needing little or no retraining.
Reviewed by Pith at T0; open to challenge. T0 means a machine referee read the full paper against a public rubric. the ladder, T0–T4 →
T0 review · grok-4.3
2026-05-23 18:28 UTC pith:BO4RFU3N
load-bearing objection LightTransfer gives a simple post-hoc swap to hybrid attention in pretrained models with reported speedups, but the lazy-layer selection needs checks for stability across data. the 3 major comments →
LightTransfer: Your Long-Context LLM is Secretly a Hybrid Model with Effortless Adaptation
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By identifying lazy layers that attend mainly to recent or initial tokens and replacing their full attention with streaming attention, transformer models can be converted into hybrid models. This conversion works without training for long-context understanding tasks and with minimal fine-tuning for o1-like long reasoning, delivering up to 2.17 times higher throughput and less than 1.5 percent performance drop on LongBench, while reaching 53.3 percent on AIME24 for advanced models.
What carries the argument
Lazy layers, defined as those focusing on recent or initial tokens, whose full attention is replaced by streaming attention to form hybrid models.
Load-bearing premise
Layers identified as lazy by their attention focus can have full attention swapped for streaming attention without harming the model's core capabilities.
What would settle it
A test where lazy layers are accurately identified but replacing their attention causes more than 5 percent drop in accuracy on LongBench or similar long-context tasks.
If this is right
- Even with half the layers replaced, throughput improves by up to 2.17 times.
- Performance loss stays below 1.5 percent on LongBench across tested models.
- Advanced reasoning models achieve 53.3 percent on the AIME24 math benchmark after the change.
- The method applies to multiple model families including LLaMA, Mistral, and QwQ-STILL.
- Transformation needs no training for understanding tasks and only light fine-tuning for reasoning.
Where Pith is reading between the lines
- Many existing models may already contain underused layers that could be optimized this way without redesign.
- Hybrid architectures might become standard by retrofitting rather than building new models.
- Further gains could come from applying similar identification to other components like feed-forward layers.
- The approach might generalize to other efficiency methods such as selective KV cache eviction in lazy layers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LightTransfer, a method to transform standard transformer-based LLMs (e.g., LLaMA, Mistral, QwQ-STILL) into hybrid architectures by identifying 'lazy layers'—those whose attention focuses primarily on recent or initial tokens—and replacing their full attention with streaming attention. Identification is performed by inspecting attention patterns; the transformation requires no training for long-context tasks or only minimal fine-tuning for reasoning tasks. Experiments claim up to 2.17× throughput improvement with <1.5% drop on LongBench even when half the layers are replaced, plus 53.3% on AIME24.
Significance. If the lazy-layer identification proves robust across distributions, the work would offer a low-cost route to hybrid-model efficiency gains on existing pretrained backbones, directly addressing KV-cache scaling issues in long-context inference. The reported throughput numbers and cross-model results (LLaMA/Mistral/QwQ) constitute concrete empirical support for effortless adaptation.
major comments (3)
- [§3] §3 (Lazy Layer Identification): The central claim rests on reliable detection of layers whose attention concentrates on recent/initial tokens, yet no cross-task or cross-prompt stability test is reported for the selected layer set. Without this, the <1.5% LongBench drop could be an artifact of identification tuned to the evaluation distribution.
- [§4] §4 (Experiments): No ablation replaces a random or attention-entropy-matched set of layers with streaming attention. Such a control is required to confirm that performance preservation stems from the lazy-layer criterion rather than incidental properties of the model or task.
- [Results] Results on AIME24: The 53.3% figure for QwQ-STILL after minimal fine-tuning is presented without a matched baseline (full-attention QwQ-STILL) or details on the fine-tuning data distribution, leaving the incremental benefit of the LightTransfer swap unclear.
minor comments (2)
- [Methods] The precise definition and implementation of 'streaming attention' (e.g., window size, eviction policy) should be stated explicitly in the methods rather than assumed from prior work.
- [Experiments] Throughput and accuracy tables would be strengthened by reporting standard deviations or multiple random seeds, as noted in the abstract's numerical claims.
Simulated Author's Rebuttal
Thank you for the detailed review and constructive feedback. We appreciate the opportunity to strengthen the manuscript and address each major comment below. We will incorporate revisions to improve clarity and robustness where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (Lazy Layer Identification): The central claim rests on reliable detection of layers whose attention concentrates on recent/initial tokens, yet no cross-task or cross-prompt stability test is reported for the selected layer set. Without this, the <1.5% LongBench drop could be an artifact of identification tuned to the evaluation distribution.
Authors: We thank the referee for highlighting this. The lazy-layer identification was derived from attention patterns observed on a diverse set of long-context examples, and the selected layers showed consistent behavior across the LongBench tasks we evaluated. However, we agree that explicit cross-task and cross-prompt stability analysis would strengthen the claim. In the revised manuscript, we will add a new subsection with overlap statistics for the identified lazy layers across different LongBench subsets, prompt lengths, and task types to demonstrate that the selection is not tuned to the evaluation distribution. revision: yes
-
Referee: [§4] §4 (Experiments): No ablation replaces a random or attention-entropy-matched set of layers with streaming attention. Such a control is required to confirm that performance preservation stems from the lazy-layer criterion rather than incidental properties of the model or task.
Authors: This is a fair criticism and a useful control. We will add the requested ablation in the revised experiments section: we will replace an equal number of randomly chosen layers (and separately, layers matched on attention entropy) with streaming attention and report the resulting performance on LongBench. This will allow direct comparison to our lazy-layer selection and help isolate the contribution of the identification criterion. revision: yes
-
Referee: [Results] Results on AIME24: The 53.3% figure for QwQ-STILL after minimal fine-tuning is presented without a matched baseline (full-attention QwQ-STILL) or details on the fine-tuning data distribution, leaving the incremental benefit of the LightTransfer swap unclear.
Authors: We agree that the presentation can be improved. In the revision we will report the AIME24 score of the original full-attention QwQ-STILL model under identical evaluation conditions and provide additional details on the fine-tuning data distribution, number of examples, and training hyperparameters used for the hybrid model. This will make the incremental effect of the LightTransfer replacement clearer. revision: yes
Circularity Check
No circularity: empirical identification and replacement method
full rationale
The paper describes an empirical procedure: inspect attention patterns to label layers as lazy, then replace full attention with streaming attention (with optional minimal fine-tuning). No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Claims rest on benchmark measurements (LongBench, AIME24) rather than any derivation that reduces to its own inputs by construction. This is the common case of a self-contained empirical transformation.
Axiom & Free-Parameter Ledger
free parameters (1)
- lazy-layer identification threshold or criterion
axioms (1)
- domain assumption Streaming attention in lazy layers preserves sufficient information for downstream task performance
invented entities (1)
-
lazy layers
no independent evidence
read the original abstract
Scaling language models to handle longer contexts introduces substantial memory challenges due to the growing cost of key-value (KV) caches. Motivated by the efficiency gains of hybrid models and the broad availability of pretrained large transformer backbones, we explore transitioning transformer models into hybrid architectures for a more efficient generation. In this work, we propose LightTransfer, a lightweight method that transforms models such as LLaMA into hybrid variants. Our approach identifies lazy layers -- those focusing on recent or initial tokens -- and replaces their full attention with streaming attention. This transformation can be performed without any training for long-context understanding tasks or with minimal fine-tuning for o1-like long reasoning generation tasks that require stronger reasoning capabilities. Experiments across diverse benchmarks and models (e.g., LLaMA, Mistral, QwQ-STILL) demonstrate that, even when half of the layers are identified as lazy, LightTransfer achieves up to 2.17$\times$ throughput improvement with minimal performance loss ($<1.5\%$ on LongBench) and achieves 53.3\% on math benchmark AIME24 of advanced o1-like long reasoning model QwQ-STILL.
Figures







Forward citations
Cited by 2 Pith papers
-
MoBA: Mixture of Block Attention for Long-Context LLMs
MoBA routes attention over blocks via MoE-style gating to enable dynamic, bias-light long-context attention that matches full attention performance at lower cost.
-
The Pitfalls of KV Cache Compression
KV cache compression causes certain instructions to degrade rapidly and be ignored in multi-instruction prompting, with system prompt leakage worsened by method choice, instruction order, and eviction bias; simple pol...
Reference graph
Works this paper leans on
-
[1]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Bai, Y ., Lv, X., Zhang, J., Lyu, H., Tang, J., Huang, Z., Du, Z., Liu, X., Zeng, A., Hou, L., et al. Longbench: A bilingual, multitask benchmark for long context under- standing. arXiv preprint arXiv:2308.14508,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Titans: Learning to Memorize at Test Time
Behrouz, A., Zhong, P., and Mirrokni, V . Titans: Learning to memorize at test time. arXiv preprint arXiv:2501.00663,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Longformer: The Long-Document Transformer
Beltagy, I., Peters, M. E., and Cohan, A. Long- former: The long-document transformer. arXiv preprint arXiv:2004.05150,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[4]
arXiv preprint arXiv:2408.10189 (2024)
Bick, A., Li, K. Y ., Xing, E. P., Kolter, J. Z., and Gu, A. Transformers to ssms: Distilling quadratic knowledge to subquadratic models. arXiv preprint arXiv:2408.10189,
- [5]
-
[6]
Brandon, W., Mishra, M., Nrusimha, A., Panda, R., and Kelly, J. R. Reducing transformer key-value cache size with cross-layer attention. arXiv preprint arXiv:2405.12981,
-
[7]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Dao, T. Flashattention-2: Faster attention with bet- ter parallelism and work partitioning. arXiv preprint arXiv:2307.08691,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Dao, T. and Gu, A. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality. arXiv preprint arXiv:2405.21060,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
De, S., Smith, S. L., Fernando, A., Botev, A., Cristian- Muraru, G., Gu, A., Haroun, R., Berrada, L., Chen, Y ., Srinivasan, S., et al. Griffin: Mixing gated linear recur- rences with local attention for efficient language models. arXiv preprint arXiv:2402.19427,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Flex Attention: A Programming Model for Generating Optimized Attention Kernels
Dong, J., Feng, B., Guessous, D., Liang, Y ., and He, H. Flex attention: A programming model for gen- erating optimized attention kernels. arXiv preprint arXiv:2412.05496,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
A little goes a long way: Efficient long context training and inference with partial contexts
Ge, S., Lin, X., Zhang, Y ., Han, J., and Peng, H. A little goes a long way: Efficient long context training and inference with partial contexts. arXiv preprint arXiv:2410.01485,
-
[14]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma, T., Riviere, M., Pathak, S., Sessa, P. G., Hardin, C., Bhupatiraju, S., Hussenot, L., Mesnard, T., Shahri- ari, B., Ram ´e, A., et al. Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Goldstein, D., Obeid, F., Alcaide, E., Song, G., and Cheah, E. Goldfinch: High performance rwkv/transformer hybrid with linear pre-fill and extreme kv-cache compression. arXiv preprint arXiv:2407.12077,
-
[16]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Gu, A. and Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
When Attention Sink Emerges in Language Models: An Empirical View
Gu, X., Pang, T., Du, C., Liu, Q., Zhang, F., Du, C., Wang, Y ., and Lin, M. When attention sink emerges in language models: An empirical view. arXiv preprint arXiv:2410.10781,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Hsieh, C.-P., Sun, S., Kriman, S., Acharya, S., Rekesh, D., Jia, F., and Ginsburg, B. Ruler: What’s the real context size of your long-context language models?arXiv preprint arXiv:2404.06654,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., Casas, D. d. l., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., et al. Mistral 7b. arXiv preprint arXiv:2310.06825,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
GitHub repository. Kasai, J., Peng, H., Zhang, Y ., Yogatama, D., Ilharco, G., Pappas, N., Mao, Y ., Chen, W., and Smith, N. A. Fine- tuning pretrained transformers into rnns. arXiv preprint arXiv:2103.13076,
-
[21]
MiniMax-01: Scaling Foundation Models with Lightning Attention
9 LIGHT TRANSFER : Your Long-Context LLM is Secretly a Hybrid Model with Effortless Adaptation Li, A., Gong, B., Yang, B., Shan, B., Liu, C., Zhu, C., Zhang, C., Guo, C., Chen, D., Li, D., et al. Minimax-01: Scaling foundation models with lightning attention.arXiv preprint arXiv:2501.08313,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
A Survey on Large Language Model Acceleration based on KV Cache Management
Li, H., Li, Y ., Tian, A., Tang, T., Xu, Z., Chen, X., Hu, N., Dong, W., Li, Q., and Chen, L. A survey on large lan- guage model acceleration based on kv cache management. arXiv preprint arXiv:2412.19442, 2024a. Li, Y ., Huang, Y ., Yang, B., Venkitesh, B., Locatelli, A., Ye, H., Cai, T., Lewis, P., and Chen, D. Snapkv: Llm knows what you are looking for ...
-
[23]
Linearizing Large Language Models
Lightman, H., Kosaraju, V ., Burda, Y ., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. Let’s verify step by step. In The Twelfth International Conference on Learning Representations. Liu, A., Liu, J., Pan, Z., He, Y ., Haffari, G., and Zhuang, B. Minicache: Kv cache compression in depth dimension for large language...
-
[24]
Imitate, Explore, and Self-Improve: A Reproduction Report on Slow-thinking Reasoning Systems
Min, Y ., Chen, Z., Jiang, J., Chen, J., Deng, J., Hu, Y ., Tang, Y ., Wang, J., Cheng, X., Song, H., et al. Imitate, explore, and self-improve: A reproduction report on slow-thinking reasoning systems. arXiv preprint arXiv:2412.09413 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Nawrot, P., Ła´ncucki, A., Chochowski, M., Tarjan, D., and Ponti, E. M. Dynamic memory compression: Retrofitting llms for accelerated inference. arXiv preprint arXiv:2403.09636,
-
[26]
RWKV: Reinventing RNNs for the Transformer Era
Peng, B., Alcaide, E., Anthony, Q., Albalak, A., Arcadinho, S., Biderman, S., Cao, H., Cheng, X., Chung, M., Grella, M., et al. Rwkv: Reinventing rnns for the transformer era. arXiv preprint arXiv:2305.13048,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
arXiv preprint arXiv:2401.04658 , year =
Qin, Z., Sun, W., Li, D., Shen, X., Sun, W., and Zhong, Y . Lightning attention-2: A free lunch for handling unlim- ited sequence lengths in large language models. arXiv preprint arXiv:2401.04658,
-
[28]
Fast Transformer Decoding: One Write-Head is All You Need
Shazeer, N. Fast transformer decoding: One write-head is all you need. arXiv preprint arXiv:1911.02150,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[29]
Shi, L., Zhang, H., Yao, Y ., Li, Z., and Zhao, H. Keep the cost down: A review on methods to optimize llm’s kv-cache consumption. arXiv preprint arXiv:2407.18003,
-
[30]
You Only Cache Once: Decoder-Decoder Architectures for Language Models
Sun, Y ., Dong, L., Zhu, Y ., Huang, S., Wang, W., Ma, S., Zhang, Q., Wang, J., and Wei, F. You only cache once: Decoder-decoder architectures for language models. arXiv preprint arXiv:2405.05254,
-
[31]
Jamba-1.5: Technical Report.arXiv preprint arXiv:2408.12570, 2024
Team, J., Lenz, B., Arazi, A., Bergman, A., Manevich, A., Peleg, B., Aviram, B., Almagor, C., Fridman, C., Padnos, D., et al. Jamba-1.5: Hybrid transformer-mamba models at scale. arXiv preprint arXiv:2408.12570,
-
[32]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine- tuned chat models. arXiv preprint arXiv:2307.09288 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Wang, J., Paliotta, D., May, A., Rush, A. M., and Dao, T. The mamba in the llama: Distilling and accelerating hybrid models. arXiv preprint arXiv:2408.15237, 2024a. Wang, Z., Cui, B., and Gan, S. Squeezeattention: 2d man- agement of kv-cache in llm inference via layer-wise opti- mal budget. arXiv preprint arXiv:2404.04793, 2024b. Wang, Z., Jin, B., Yu, Z....
-
[34]
PyramidInfer: Pyramid KV Cache Compression for High-throughput LLM Inference
Yang, D., Han, X., Gao, Y ., Hu, Y ., Zhang, S., and Zhao, H. Pyramidinfer: Pyramid kv cache compres- sion for high-throughput llm inference. arXiv preprint arXiv:2405.12532,
-
[35]
Gated Linear Attention Transformers with Hardware-Efficient Training
Yang, S., Wang, B., Shen, Y ., Panda, R., and Kim, Y . Gated linear attention transformers with hardware-efficient train- ing. arXiv preprint arXiv:2312.06635,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Effectively compress kv heads for llm.arXiv preprint arXiv:2406.07056, 2024
Yu, H., Yang, Z., Li, S., Li, Y ., and Wu, J. Effectively com- press kv heads for llm. arXiv preprint arXiv:2406.07056,
-
[37]
arXiv preprint arXiv:2407.01527 , year=
Yuan, J., Liu, H., Zhong, S., Chuang, Y .-N., Li, S., Wang, G., Le, D., Jin, H., Chaudhary, V ., Xu, Z., et al. Kv cache compression, but what must we give in return? a compre- hensive benchmark of long context capable approaches. arXiv preprint arXiv:2407.01527,
-
[38]
LoLCATs: On Low-Rank Linearizing of Large Language Models
Zhang, M., Arora, S., Chalamala, R., Wu, A., Spector, B., Singhal, A., Ramesh, K., and R ´e, C. Lolcats: On low- rank linearizing of large language models. arXiv preprint arXiv:2410.10254, 2024a. Zhang, M., Bhatia, K., Kumbong, H., and R ´e, C. The hedgehog & the porcupine: Expressive linear attentions with softmax mimicry. arXiv preprint arXiv:2402.04347...
-
[39]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Zhang, Y ., Gao, B., Liu, T., Lu, K., Xiong, W., Dong, Y ., Chang, B., Hu, J., Xiao, W., et al. Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling. arXiv preprint arXiv:2406.02069, 2024c. Zhang, Z., Sheng, Y ., Zhou, T., Chen, T., Zheng, L., Cai, R., Song, Z., Tian, Y ., R´e, C., Barrett, C., et al. H2o: Heavy-hitter oracle f...
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
code it references. We followed all the hyper-parameters outlined in the paper, except for the number of retention tokens. SqueezeAttention and our LIGHT TRANSFER -T EST TIME are both set to the same compression ratio, equivalent to removing KV caches from 50% of the layers (i.e., P is set to 50% of the total number of layers), whereas MiniCache is set to...
work page 2023
-
[41]
Performance under different hyperparameters. (a) Window size wrecent Window size 252 508 1020 2044 Performance 39.5 39.8 39.8 40.1 (b) Sink token count wsink Sink num 0 2 4 6 Performance 26.5 39.8 39.8 39.9 (c) wlast wlast 8 16 32 64 Performance 39.9 39.8 39.9 39.7 (a) Example 0 (b) Example 1 Figure
work page 2044
-
[42]
The analysis is conducted using LLaMA3-8B-Instruct
The examples are randomly chosen from LongBench benchmarks. The analysis is conducted using LLaMA3-8B-Instruct. E. Notation For a positive integer N ∈ N, we define the set [N ] = {1, · · · , N}. For a vector x ∈ Rd, we adopt ∥ · ∥p to denote the ℓp norm of vectors. For a matrix X = [x⊤ 1 , · · · , x⊤ d1 ]⊤ ∈ Rd1×d2, where xi ∈ Rd2 for i = 1, · · · , d1, w...
work page 2024
-
[43]
). Given any two conjugate numbers u, v ∈ [1, ∞], i.e., 1 u + 1 v = 1, and 1 ≤ p ≤ ∞, for any A ∈ Rr×c and x ∈ Rc, we have ∥Ax∥p ≤ ∥A⊤∥p,u∥x∥v and ∥Ax∥p ≤ ∥A∥u,p∥x∥v. Lemma G.3 (Lemma I.8 in (Zhang et al., 2023)). For any X, ˜X ∈ RN ×d, and any WQ,h, WK,h ∈ Rd×dh , WV,h ∈ Rd×d for h ∈ [H] , if ∥X∥2,∞, ∥ ˜X∥2,∞ ≤ BX, ∥WQ,h∥F ≤ BQ, ∥WK,h∥F, ≤ BK, ∥WV,h∥F ≤ ...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.