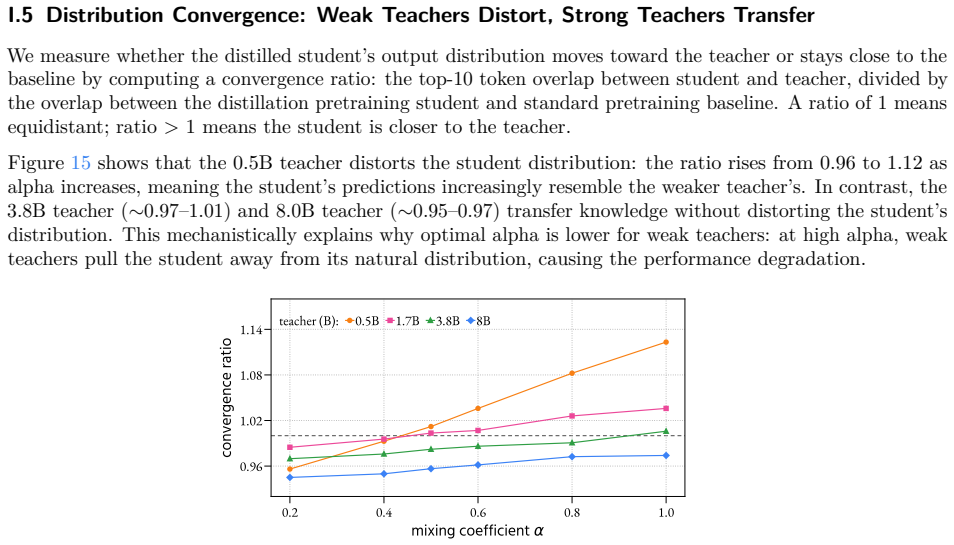
Strong Teacher Not Needed? On Distillation in LLM Pretraining
Pith reviewed 2026-05-25 04:39 UTC · model grok-4.3
The pith
Even small undertrained teachers can improve larger LLM students when language modeling and distillation losses are mixed properly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
With appropriate mixing of the language modeling objective and the knowledge distillation loss, distillation from small or undertrained teachers improves larger student models during LLM pretraining, while increasing teacher parameters or training tokens can saturate or reverse the gains; distillation also aids generalization more than in-domain performance.
What carries the argument
The weighted sum of language modeling loss and knowledge distillation loss applied during student pretraining.
If this is right
- Distillation remains useful in weak-to-strong setups when losses are mixed correctly.
- Increasing teacher strength yields diminishing or negative returns past a saturation point.
- Generalization metrics improve more consistently than in-domain perplexity under distillation.
Where Pith is reading between the lines
- Training budgets for teachers could be reduced without losing distillation value to students.
- The saturation effect may appear when the teacher has seen more data than the student relative to model capacity.
- The same loss-mixing approach might apply when distilling across different architectures rather than size differences.
Load-bearing premise
Observed gains and reversals stem from the teacher-student relationship and loss weighting rather than differences in total compute, data order, or hyperparameter choices.
What would settle it
Equalizing total compute and data exposure across teacher strengths while keeping loss mixing fixed, then checking whether the reported saturation or reversal of student gains still appears.
Figures
















read the original abstract
Knowledge distillation generally assumes a strong-to-weak relationship where stronger teachers yield better students. In this work, we examine this assumption about distillation in large language model pretraining. By varying architecture sizes and training token budgets, we create strong-to-weak, same-level, and weak-to-strong teacher-student relationships, and study distillation's effectiveness under each. We find that the teacher need not be strong: with proper mixing of the language modeling and knowledge distillation losses, even small and undertrained teachers improve larger students. At the same time, a stronger teacher is not always better: pushing the teacher further, through more parameters or more training tokens, can saturate or even reverse the distillation gains. We further observe that distillation improves generalization (out-of-distribution and downstream performance) more readily than in-domain fitting. Together, these results challenge the common belief that distillation pretraining always requires a strong teacher.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines the assumption that knowledge distillation in LLM pretraining requires a strong teacher. By varying teacher architecture sizes and training token budgets to create strong-to-weak, same-level, and weak-to-strong pairings, the authors report that appropriate mixing of language modeling and distillation losses allows even small or undertrained teachers to improve larger students. They further find that increasing teacher strength (via parameters or tokens) can saturate or reverse gains, and that distillation improves out-of-distribution and downstream performance more readily than in-domain fitting.
Significance. If the central empirical observations hold after controlling for student-side factors, the results would challenge the prevailing strong-to-weak paradigm in distillation for pretraining and suggest more flexible, compute-efficient teacher choices. The work's strength lies in its systematic variation of teacher configurations and its observation that distillation aids generalization; however, the absence of reported effect sizes, run counts, and variance measures in the abstract limits immediate impact.
major comments (3)
- [Section 3] Section 3 (Experimental Setup): the description of the distillation experiments does not state whether student training token count, optimizer settings, data ordering, and total compute are held exactly constant when the teacher size or token budget is varied. This control is load-bearing for the claim that observed gains and reversals arise from the teacher-student loss interaction rather than incidental differences in student optimization effort.
- [Section 4] Section 4 (Results): the saturation and reversal claims when increasing teacher parameters or tokens are presented without error bars, number of independent runs, or statistical tests. Without these, it is impossible to assess whether the reversals are robust or could be explained by run-to-run variance.
- [Section 3.2] Section 3.2 (Loss Mixing): the phrase 'proper mixing' of LM and KD losses is central to the positive results with weak teachers, yet the procedure for choosing or validating the mixing coefficient (grid search, fixed value, or post-hoc selection) is not specified. If the coefficient was tuned after observing outcomes, the attribution to teacher quality is weakened.
minor comments (2)
- [Table 2] Table 2: column headers for teacher and student configurations are abbreviated without a clear legend, making it difficult to map rows to the strong-to-weak vs. weak-to-strong cases discussed in the text.
- [Figure 3] Figure 3: axis labels for 'distillation gain' do not indicate the exact baseline (pure LM loss or another control) against which gains are measured.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on experimental controls, statistical reporting, and loss mixing. We address each point below with clarifications from our setup and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Section 3] Section 3 (Experimental Setup): the description of the distillation experiments does not state whether student training token count, optimizer settings, data ordering, and total compute are held exactly constant when the teacher size or token budget is varied. This control is load-bearing for the claim that observed gains and reversals arise from the teacher-student loss interaction rather than incidental differences in student optimization effort.
Authors: Student training token count (fixed at 50B tokens), optimizer (AdamW with identical hyperparameters and schedule), data ordering (fixed random seed for the same dataset shuffle), and total compute budget were held exactly constant across all teacher variations. This isolates effects to the loss interaction. We will add an explicit paragraph in Section 3 stating these controls. revision: yes
-
Referee: [Section 4] Section 4 (Results): the saturation and reversal claims when increasing teacher parameters or tokens are presented without error bars, number of independent runs, or statistical tests. Without these, it is impossible to assess whether the reversals are robust or could be explained by run-to-run variance.
Authors: We acknowledge the need for variance reporting. Main results used single runs due to compute limits, but we performed 3 independent runs with different seeds on representative configurations showing saturation/reversal. We will add error bars, report run counts, and include a brief note that variance is smaller than the effect sizes in the revised Section 4. revision: yes
-
Referee: [Section 3.2] Section 3.2 (Loss Mixing): the phrase 'proper mixing' of LM and KD losses is central to the positive results with weak teachers, yet the procedure for choosing or validating the mixing coefficient (grid search, fixed value, or post-hoc selection) is not specified. If the coefficient was tuned after observing outcomes, the attribution to teacher quality is weakened.
Authors: The mixing coefficient was chosen via a grid search (0.0 to 1.0 in steps of 0.1) on a small held-out validation set prior to main experiments, selecting the value maximizing validation performance for each teacher-student pair. This was not post-hoc. We will specify the grid-search procedure and validation protocol in the revised Section 3.2. revision: yes
Circularity Check
No circularity; purely empirical study with no derivations or self-referential fits
full rationale
The paper reports experimental results on varying teacher-student sizes and token budgets in LLM distillation, with no equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations. All claims rest on direct observations from controlled runs rather than any reduction to inputs by construction, satisfying the criteria for a self-contained empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AI@Meta. The llama 3 herd of models.arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
Hamel Husain, Hongqiu Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. Codesearchnet challenge: Evaluating the state of semantic code search.arXiv:1909.09436,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[8]
Sachin Mehta, Mohammad Hossein Sekhavat, Qingqing Cao, Maxwell Horton, Yanzi Jin, Chenfan Sun, Iman Mirzadeh, Mahyar Najibi, Dmitry Belenko, Peter Zatloukal, and Mohammad Rastegari. Openelm: An efficient language model family with open training and inference framework.arXiv:2404.14619,
-
[9]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Phi3@Microsoft. Phi-3 technical report: A highly capable language model locally on your phone. arXiv:2404.14219,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Qwen. Qwen2.5 technical report.arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Qwen. Qwen3 technical report.arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter.arXiv:1910.01108,
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[13]
Jiaxi Tang, Rakesh Shivanna, Zhe Zhao, Dong Lin, Anima Singh, Ed H. Chi, and Sagar Jain. Understanding and improving knowledge distillation.arXiv:2002.03532,
-
[14]
TinyLlama: An Open-Source Small Language Model
Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, and Wei Lu. Tinyllama: An open-source small language model.arXiv:2401.02385,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
is a widely used technique to transfer knowledge from a teacher model to a student model by training the student to match the teacher’s predictive distribution. The key insight is that the teacher’s soft predictions contain “dark knowledge,” information about the relative similarities between classes that is not present in hard labels (Neyshabur et al., 2...
work page 2020
-
[16]
in vision, KD has since been extended in many directions, including distilling intermediate representations (Romero et al., 2015), attention maps (Zagoruyko and Komodakis, 2017), and relational information between samples (Park et al., 2019). Various works have also studied the theoretical foundations of why distillation works, attributing its success to ...
work page 2015
-
[17]
can qualitatively change distillation outcomes. Moreover, KD is not monotonic in teacher strength: for autoregressive LMs, stronger teachers can sometimes degrade student performance (Zhong et al., 2024; Busbridge et al., 2025). Prior work has shown that stronger teachers can sometimes degrade performance, but has not systematically characterized when thi...
work page 2024
-
[18]
first showed that same-architecture distillation can still improve the student, with subsequent work clarifying why this effect holds (Zhang et al., 2019; Cho and Hariharan, 2019; Mobahi et al., 2020). In LLMs, while distillation remains a standard compression approach, strict strong-to-weak supervision may be unrealistic in the long run (Burns et al., 20...
work page 2019
-
[19]
and DeepSeek-R1 (DeepSeek-AI, 2025). Despite these developments, systematic studies of how the scale of different components governs logit-level distillation in LLM pretraining remain limited. Busbridge et al. (2025) studies distillation scaling laws, but constrains teachers to a fixed budget distribution, while Peng et al. (2025) studies how student size...
work page 2025
-
[20]
Results show percentage improvement over stan- dard pretraining 300B baseline
Distillation improvement at 300B training to- kens with𝛼= 0.2.Student is 1.7B trained on 300B tokens. Results show percentage improvement over stan- dard pretraining 300B baseline. G.1 Generalization to Different Architecture Families Our main experiments use the Llama3 architecture family. We now test whether our findings transfer to a different architec...
work page 2025
-
[21]
Entropy change vs. PPL improvement.Each point is one distilled student. Most successful students show increased entropy (less confident) yet improved PPL (more accurate), indicating distillation redistributes probability rather than sharpening predictions. Strong teachers achieve high improvement with modest entropy change; the 0.5B teacher at high alpha ...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.