Is One Score Enough? Rethinking the Evaluation of Sequentially Evolving LLM Memory
Pith reviewed 2026-05-19 16:39 UTC · model grok-4.3
The pith
Aggregate accuracy scores can mask forgetting and negative transfer in sequentially evolving LLM memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
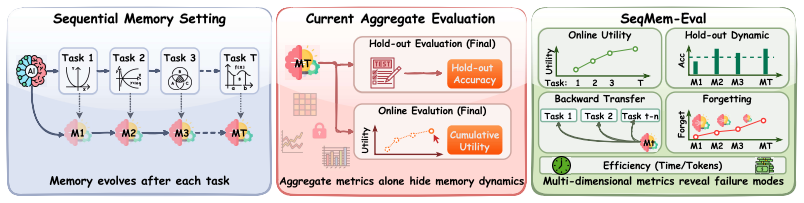
Existing evaluations of LLM memory in sequential settings rely on aggregate metrics such as final hold-out accuracy or cumulative online performance, which can obscure critical failure modes like forgetting and negative transfer. SeqMem-Eval instead measures how memory states evolve by tracking online utility, hold-out generalization, backward transfer, and forgetting in a test-time setting where memory is external and prompt-mediated. Experiments across diverse tasks and methods show that higher final or cumulative accuracy does not necessarily indicate better memory quality, as many approaches exhibit strong gains alongside substantial forgetting or negative transfer, exposing distinct but
What carries the argument
SeqMem-Eval, a diagnostic evaluation framework that tracks memory evolution through online utility, hold-out generalization, backward transfer, and forgetting in external prompt-mediated updates.
If this is right
- Memory methods can be ranked by their stability-adaptability trade-offs that remain invisible under standard final-performance scores.
- Evaluation protocols should track how memory consolidates experience and retains information rather than stopping at cumulative accuracy.
- Design choices in memory updating can be diagnosed for harmful interference between sequential tasks.
- Strong performance gains in online settings may still come at the cost of degraded retention of earlier knowledge.
Where Pith is reading between the lines
- Future memory architectures could be developed by directly optimizing for the new metrics rather than aggregate accuracy.
- This evaluation approach might transfer to other sequential decision systems where external state accumulation is used.
- Long-term deployment of LLMs in interactive environments could benefit from periodic checks using these finer-grained measures to detect drift.
Load-bearing premise
The four proposed metrics provide a meaningfully finer-grained and more informative assessment of memory quality than aggregate metrics alone.
What would settle it
Applying the four metrics to a set of existing memory methods and finding that they produce no new distinctions beyond what final accuracy already shows, with no evidence of hidden forgetting or negative transfer in high-performing cases.
Figures








read the original abstract
Memory plays a central role in enabling large language models (LLMs) to operate over sequential tasks by accumulating and reusing experience over time. However, existing evaluations of LLM memory mostly rely on aggregate metrics such as final hold-out accuracy or cumulative online performance, which can obscure critical failure modes such as forgetting and negative transfer. In this paper, we introduce SeqMem-Eval, a diagnostic evaluation framework for sequentially evolving LLM memory. Drawing inspiration from continual learning, it targets a test-time setting in which memory is external, prompt-mediated, and updated without modifying model parameters. Rather than focusing only on final performance, SeqMem-Eval evaluates how memory states evolve, generalize, consolidate experience, and retain useful information during sequential inference. Specifically, it measures online utility, hold-out generalization, backward transfer, and forgetting, providing a finer-grained view of memory quality. Through extensive experiments across diverse tasks and memory methods, we show that higher final or cumulative accuracy does not necessarily imply better memory quality: many methods exhibit strong performance gains while suffering from substantial forgetting or negative transfer. Moreover, different memory designs exhibit distinct trade-offs between adaptability and stability that remain invisible under standard evaluation metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SeqMem-Eval, a diagnostic framework for evaluating sequentially evolving LLM memory in an external, prompt-mediated, test-time setting without parameter updates. Drawing from continual learning, it argues that aggregate metrics such as final hold-out accuracy or cumulative online performance can mask critical issues like forgetting and negative transfer. The framework defines four metrics—online utility, hold-out generalization, backward transfer, and forgetting—to assess how memory states evolve, generalize, consolidate, and retain information. Experiments across diverse tasks and memory methods demonstrate that higher final or cumulative accuracy does not necessarily indicate superior memory quality, revealing distinct adaptability-stability trade-offs invisible under standard evaluations.
Significance. If the central observations hold, the work could meaningfully improve evaluation practices for LLM memory systems by highlighting the limitations of single-score metrics and promoting finer-grained analysis of temporal dynamics. The adaptation of established continual-learning metrics to the prompt-mediated external-memory setting is a clear strength, as is the empirical demonstration that performance gains can coexist with substantial forgetting or negative transfer. The framework provides a structured, falsifiable way to compare memory designs that could influence future method development.
major comments (2)
- [§4.2] §4.2, metric definitions: the claim that the four metrics provide a 'finer-grained view' independent of aggregate accuracy requires explicit verification that backward transfer and forgetting are not partially redundant with the online utility computation; if the hold-out set overlaps with online data in any task sequence, the independence assumption may not hold.
- [Table 3] Table 3 and §5.3: the reported trade-offs (e.g., high accuracy with high forgetting for certain methods) are load-bearing for the central claim, yet the manuscript does not report run-to-run variance or statistical tests; without these, it is unclear whether the observed differences exceed noise and support the conclusion that aggregate scores are insufficient.
minor comments (3)
- [§3.1] §3.1: the description of the external memory update procedure could include a small pseudocode snippet to clarify how prompt-mediated updates differ from parameter-based continual learning.
- [Figure 2] Figure 2: axis labels and legend entries are too small for readability; increasing font size would improve clarity of the trade-off visualizations.
- [Related Work] Related work section: add a brief comparison to recent LLM memory papers that also use sequential task streams (e.g., those evaluating long-context or retrieval-augmented generation) to better situate the novelty of SeqMem-Eval.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the constructive comments. We address each major comment below and have incorporated revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4.2] §4.2, metric definitions: the claim that the four metrics provide a 'finer-grained view' independent of aggregate accuracy requires explicit verification that backward transfer and forgetting are not partially redundant with the online utility computation; if the hold-out set overlaps with online data in any task sequence, the independence assumption may not hold.
Authors: We thank the referee for this observation on metric independence. Online utility measures immediate performance on tasks as they arrive in the sequence. Backward transfer and forgetting, following continual learning conventions, quantify retention and interference effects on prior tasks after new information is incorporated. These are evaluated on separate hold-out sets for each previous task, which are constructed to be disjoint from the online task data. This design ensures the metrics capture distinct dimensions, as evidenced by our experimental cases where high online utility coexists with substantial forgetting. We have revised §4.2 to explicitly discuss the non-overlapping evaluation sets and the complementary nature of the metrics. revision: yes
-
Referee: [Table 3] Table 3 and §5.3: the reported trade-offs (e.g., high accuracy with high forgetting for certain methods) are load-bearing for the central claim, yet the manuscript does not report run-to-run variance or statistical tests; without these, it is unclear whether the observed differences exceed noise and support the conclusion that aggregate scores are insufficient.
Authors: We agree that reporting variability and statistical significance would strengthen the empirical support for the observed trade-offs. The current results were obtained with fixed random seeds for reproducibility, but we recognize the value of multi-run analysis. In the revised manuscript we will rerun the primary experiments across multiple seeds, add standard deviations to Table 3, and include statistical tests (such as paired t-tests) to confirm that differences in forgetting and transfer metrics are significant and exceed noise levels. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's core contribution is the SeqMem-Eval framework, which adapts four standard metrics (online utility, hold-out generalization, backward transfer, and forgetting) from the established continual learning literature to the specific setting of prompt-mediated external LLM memory. These metrics are defined directly from observable performance quantities on sequential tasks rather than being fitted to the paper's own results or reducing to self-referential quantities. The claim that aggregate accuracy can obscure forgetting and negative transfer follows from experimental comparisons across methods and tasks, with no load-bearing steps that equate outputs to inputs by construction, no self-citation chains justifying uniqueness, and no ansatzes smuggled in via prior work. The derivation remains self-contained against external continual-learning benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Memory is external, prompt-mediated, and updated without modifying model parameters.
- domain assumption Aggregate metrics such as final hold-out accuracy or cumulative online performance can obscure failure modes like forgetting and negative transfer.
invented entities (1)
-
SeqMem-Eval
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SEQMEM-EVAL measures online utility, hold-out generalization, backward transfer, and forgetting... higher final or cumulative accuracy does not necessarily imply better memory quality
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Drawing inspiration from continual learning... external, prompt-mediated, and updated without modifying model parameters
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
L. A. Agrawal, S. Tan, D. Soylu, N. Ziems, R. Khare, K. Opsahl-Ong, A. Singhvi, H. Shandilya, M. J. Ryan, M. Jiang, et al. Gepa: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
M. Biesialska, K. Biesialska, and M. R. Costa-Jussa. Continual lifelong learning in natu- ral language processing: A survey. InProceedings of the 28th international conference on computational linguistics, pages 6523–6541, 2020
work page 2020
-
[3]
Efficient Lifelong Learning with A-GEM
A. Chaudhry, M. Ranzato, M. Rohrbach, and M. Elhoseiny. Efficient lifelong learning with a-gem.arXiv preprint arXiv:1812.00420, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
On Tiny Episodic Memories in Continual Learning
A. Chaudhry, M. Rohrbach, M. Elhoseiny, T. Ajanthan, P. K. Dokania, P. H. Torr, and M. Ran- zato. On tiny episodic memories in continual learning.arXiv preprint arXiv:1902.10486, 2019. 12
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[5]
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Her...
work page 2021
- [6]
-
[7]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
P. Chhikara, D. Khant, S. Aryan, T. Singh, and D. Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
J. Fang, Y . Peng, X. Zhang, Y . Wang, X. Yi, G. Zhang, Y . Xu, B. Wu, S. Liu, Z. Li, et al. A comprehensive survey of self-evolving ai agents: A new paradigm bridging foundation models and lifelong agentic systems.arXiv preprint arXiv:2508.07407, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
R. Fang, Y . Liang, X. Wang, J. Wu, S. Qiao, P. Xie, F. Huang, H. Chen, and N. Zhang. Memp: Exploring agent procedural memory.arXiv preprint arXiv:2508.06433, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [10]
-
[11]
H.-a. Gao, J. Geng, W. Hua, M. Hu, X. Juan, H. Liu, S. Liu, J. Qiu, X. Qi, Y . Wu, et al. A survey of self-evolving agents: What, when, how, and where to evolve on the path to artificial super intelligence.arXiv preprint arXiv:2507.21046, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt. Measuring mathematical problem solving with the math dataset, 2021
work page 2021
- [13]
-
[14]
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
work page 2017
- [15]
- [16]
-
[17]
D. Lopez-Paz and M. Ranzato. Gradient episodic memory for continual learning.Advances in neural information processing systems, 30, 2017
work page 2017
- [18]
-
[19]
MiniMax M2.7: Early echoes of self-evolution
MiniMax. MiniMax M2.7: Early echoes of self-evolution. https://www.minimax.io/news/ minimax-m27-en, 2026. Accessed: 2026-05-04
work page 2026
-
[20]
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
S. Ouyang, J. Yan, I. Hsu, Y . Chen, K. Jiang, Z. Wang, R. Han, L. T. Le, S. Daruki, X. Tang, et al. Reasoningbank: Scaling agent self-evolving with reasoning memory.arXiv preprint arXiv:2509.25140, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
S. G. Patil, T. Zhang, X. Wang, and J. E. Gonzalez. Gorilla: Large language model connected with massive apis, 2023. 13
work page 2023
-
[22]
X. Qi, Y . Zeng, T. Xie, P.-Y . Chen, R. Jia, P. Mittal, and P. Henderson. Fine-tuning aligned language models compromises safety, even when users do not intend to!arXiv preprint arXiv:2310.03693, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
N. Reimers and I. Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 3982–3992, 2019
work page 2019
-
[24]
H. Shi, Z. Xu, H. Wang, W. Qin, W. Wang, Y . Wang, Z. Wang, S. Ebrahimi, and H. Wang. Continual learning of large language models: A comprehensive survey.ACM Computing Surveys, 58(5):1–42, 2025
work page 2025
-
[25]
M. Shridhar, X. Yuan, M.-A. Côté, Y . Bisk, A. Trischler, and M. Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning, 2021
work page 2021
- [26]
- [27]
-
[28]
Q. Team. Qwen3 technical report, 2025
work page 2025
-
[29]
J. Wang, Z. Guo, W. Ma, and M. Zhang. How far can llms improve from experience? measuring test-time learning ability in llms with human comparison. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25688–25702, 2025
work page 2025
-
[30]
J. Wang, Q. Yan, Y . Wang, Y . Tian, S. S. Mishra, Z. Xu, M. Gandhi, P. Xu, and L. L. Cheong. Reinforcement learning for self-improving agent with skill library.arXiv preprint arXiv:2512.17102, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
L. Wang, X. Zhang, H. Su, and J. Zhu. A comprehensive survey of continual learning: Theory, method and application.IEEE transactions on pattern analysis and machine intelligence, 46(8):5362–5383, 2024
work page 2024
- [32]
-
[33]
Y . Wang, X. Ma, G. Zhang, Y . Ni, A. Chandra, S. Guo, W. Ren, A. Arulraj, X. He, Z. Jiang, T. Li, M. Ku, K. Wang, A. Zhuang, R. Fan, X. Yue, and W. Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark, 2024
work page 2024
-
[34]
Z. Z. Wang, J. Mao, D. Fried, and G. Neubig. Agent workflow memory, 2024
work page 2024
-
[35]
T. Wei, N. Sachdeva, B. Coleman, Z. He, Y . Bei, X. Ning, M. Ai, Y . Li, J. He, E. H. Chi, et al. Evo-memory: Benchmarking llm agent test-time learning with self-evolving memory.arXiv preprint arXiv:2511.20857, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
R. Wu, X. Wang, J. Mei, P. Cai, D. Fu, C. Yang, L. Wen, X. Yang, Y . Shen, Y . Wang, et al. Evolver: Self-evolving llm agents through an experience-driven lifecycle.arXiv preprint arXiv:2510.16079, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
T. Wu, M. Caccia, Z. Li, Y . F. Li, G. Qi, and G. Haffari. Pretrained language model in continual learning: A comparative study. InInternational Conference on Learning Representations 2022. OpenReview, 2022
work page 2022
- [38]
-
[39]
P. Xia, J. Chen, H. Wang, J. Liu, K. Zeng, Y . Wang, S. Han, Y . Zhou, X. Zhao, H. Chen, et al. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning.arXiv preprint arXiv:2602.08234, 2026. 14
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [40]
-
[41]
W. Xu, Z. Liang, K. Mei, H. Gao, J. Tan, and Y . Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [42]
-
[43]
A. Zhao, D. Huang, Q. Xu, M. Lin, Y .-J. Liu, and G. Huang. Expel: Llm agents are experiential learners, 2024
work page 2024
-
[44]
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
B. Zheng, M. Y . Fatemi, X. Jin, Z. Z. Wang, A. Gandhi, Y . Song, Y . Gu, J. Srinivasa, G. Liu, G. Neubig, et al. Skillweaver: Web agents can self-improve by discovering and honing skills. arXiv preprint arXiv:2504.07079, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [45]
- [46]
-
[47]
Memento: Fine-tuning llm agents without fine-tuning llms
H. Zhou, Y . Chen, S. Guo, X. Yan, K. H. Lee, Z. Wang, K. Y . Lee, G. Zhang, K. Shao, L. Yang, et al. Memento: Fine-tuning llm agents without fine-tuning llms.arXiv preprint arXiv:2508.16153, 2025. 15 A Detailed Experimental Setup A.1 Dataset configuration. We evaluate on a diverse set of benchmarks spanning programming, mathematical reasoning, factual an...
-
[48]
$DOMAIN should be inferred from the task description
-
[49]
$API_CALL should have only one line of code that calls the API
-
[50]
$API_PROVIDER should be the programming framework used
-
[51]
$EXPLANATION should be a step-by-step explanation
-
[52]
$CODE is the Python code
-
[53]
Do not repeat the format in your answer. F Case Study: Useful Memory State Destroyed by Subsequent Updates This case study isolates a representative failure mode in sequentially evolving memory systems: a memory state that is initially useful gradually becomes corrupted or overwritten by later updates, eventually reducing downstream performance despite co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.