Aloe-Vision: Robust Vision-Language Models for Healthcare
Pith reviewed 2026-06-29 01:59 UTC · model grok-4.3
The pith
High-quality training mixtures produce balanced medical vision-language models that gain on specialized tasks without losing general capabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
High quality training mixtures produce balanced LVLMs which yield significant gains over the baseline models without compromising general capabilities, achieving competitive performance with respect to state-of-the-art alternatives.
What carries the argument
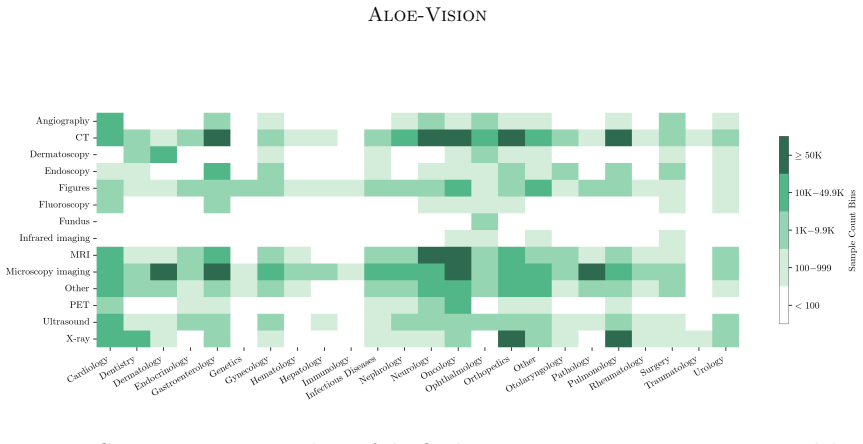
Aloe-Vision-Data, the large-scale quality-filtered mixture of medical and general multimodal and text sources used for fine-tuning the models.
If this is right
- The 7B and 72B Aloe-Vision models improve on medical vision-language benchmarks relative to their base models.
- General capabilities remain intact after the medical-domain fine-tuning step.
- Performance reaches levels competitive with closed state-of-the-art medical LVLMs.
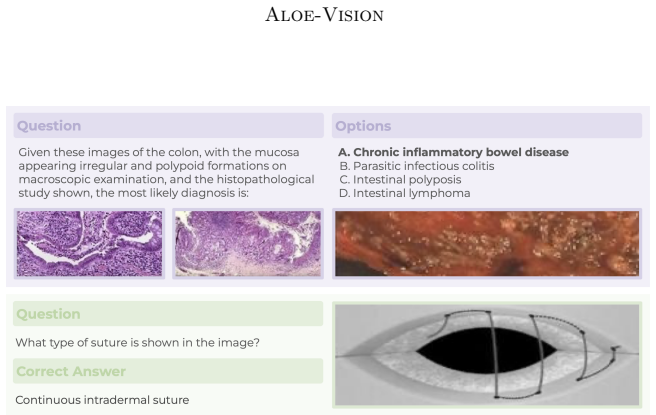
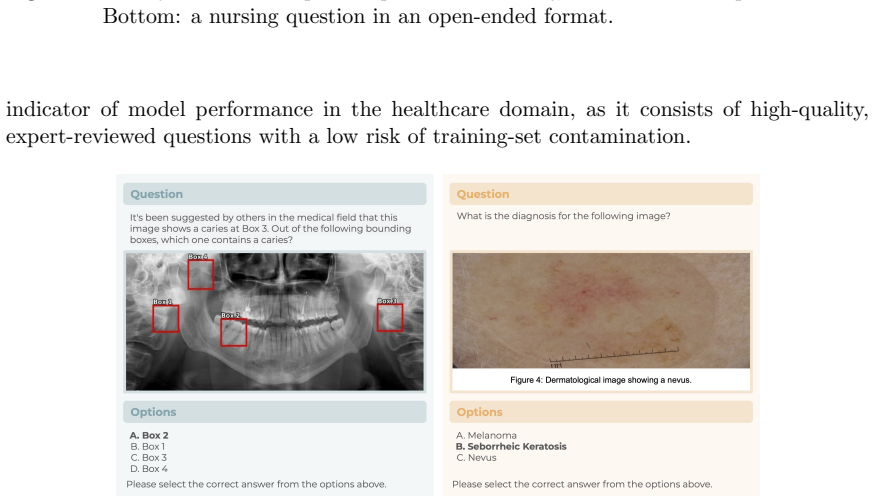
- CareQA-Vision supplies a new, lower-contamination vision benchmark derived from real medical residency exams.
- Current LVLMs stay vulnerable to adversarial and misleading inputs even after this training regime.
Where Pith is reading between the lines
- Full open release of data, weights, and recipes allows external groups to test robustness improvements or extend the mixture.
- Persistent vulnerability to misleading inputs implies that deployment in clinical settings would still require additional guardrails or verification layers.
- Using real residency exam questions for the benchmark may better reflect practical diagnostic reasoning than synthetic or web-sourced tests.
- The same mixture approach could be tested on other domain-specialized vision-language tasks outside healthcare.
Load-bearing premise
Aloe-Vision-Data is a high-quality non-contaminated mixture and CareQA-Vision has low likelihood of contamination so that measured gains reflect real improvement.
What would settle it
Retraining the models on the same mixture and finding no statistically significant gains on CareQA-Vision compared with the baselines, or discovering substantial contamination in either dataset.
Figures
read the original abstract
Large Vision-Language Models (LVLMs) specialized in healthcare are emerging as a promising research direction due to their potential impact in clinical and biomedical applications. However, progress is constrained by the scarcity of high-quality medical multimodal data, concerns about robustness in safety-critical settings, and the narrow and potentially contaminated evaluation benchmarks that limit reliable assessment. To address these issues, the field requires state-of-the-art solutions to be fully open and reproducible systems in which all components can be inspected, evaluated, and improved. This work introduces Aloe-Vision-Data, a large-scale, quality-filtered mixture which integrates both medical and general domains across multimodal and text-only sources, designed for direct use in model fine-tuning. Building on this dataset, we train the Aloe-Vision family of medical LVLMs, openly released with full weights, training recipes and data, in two scales (7B and 72B). Through comprehensive benchmarking, we demonstrate that high quality training mixtures produce balanced LVLMs which yield significant gains over the baseline models without compromising general capabilities, achieving competitive performance with respect to state-of-the-art alternatives. To support reliable evaluation, we introduce CareQA-Vision, a carefully curated vision benchmark derived from MIR and EIR exams, the residency entrance exams for medical and nursing specialists in Spain, offering novel vision questions with low likelihood of contamination. Finally, we show that current LVLMs remain vulnerable to adversarial and misleading inputs, underscoring reliability challenges in clinical contexts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Aloe-Vision-Data, a large-scale quality-filtered mixture integrating medical and general multimodal/text sources for LVLM fine-tuning. It trains and openly releases the Aloe-Vision family of models (7B and 72B scales) with full weights, recipes, and data. The central claim is that high-quality mixtures yield balanced LVLMs with significant gains on medical tasks over baselines, without compromising general capabilities, while remaining competitive with SOTA; it also introduces CareQA-Vision (derived from MIR/EIR exams) as a low-contamination vision benchmark and demonstrates LVLMs' vulnerability to adversarial inputs.
Significance. If the empirical claims hold after verification of data integrity, the open release of models, data, and training recipes would strengthen reproducibility in medical LVLMs, while CareQA-Vision could provide a useful contamination-resistant evaluation resource for the field.
major comments (2)
- [Abstract] Abstract: the central claim that 'high quality training mixtures produce balanced LVLMs which yield significant gains over the baseline models without compromising general capabilities' is asserted without any quantitative results, baselines, error bars, or evaluation details, preventing assessment of whether gains are isolated from leakage.
- [Abstract] Abstract: the assertions that Aloe-Vision-Data is a 'quality-filtered mixture' and that CareQA-Vision offers 'novel vision questions with low likelihood of contamination' are load-bearing for attributing performance gains to data quality rather than leakage, yet supply no concrete details on filtering criteria, deduplication method, or contamination audit (e.g., n-gram overlap statistics or embedding similarity thresholds).
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments. We appreciate the focus on ensuring the abstract accurately reflects the manuscript's contributions and will revise it to incorporate key quantitative highlights and methodological references from the main text.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'high quality training mixtures produce balanced LVLMs which yield significant gains over the baseline models without compromising general capabilities' is asserted without any quantitative results, baselines, error bars, or evaluation details, preventing assessment of whether gains are isolated from leakage.
Authors: The abstract serves as a high-level summary of the work. All quantitative results, baseline comparisons (including error bars and statistical details), and evaluation protocols are provided in the main manuscript, specifically in Sections 4 and 5 with accompanying tables that report performance across medical and general tasks. These results support the claim of gains without compromising general capabilities. We agree the abstract would benefit from including select quantitative highlights and will revise it accordingly. revision: yes
-
Referee: [Abstract] Abstract: the assertions that Aloe-Vision-Data is a 'quality-filtered mixture' and that CareQA-Vision offers 'novel vision questions with low likelihood of contamination' are load-bearing for attributing performance gains to data quality rather than leakage, yet supply no concrete details on filtering criteria, deduplication method, or contamination audit (e.g., n-gram overlap statistics or embedding similarity thresholds).
Authors: Section 3 of the manuscript provides the concrete details on Aloe-Vision-Data construction, including quality filtering criteria, deduplication methods (such as n-gram overlap), and contamination audits for CareQA-Vision (including similarity thresholds and exam-derived question novelty). The abstract summarizes these elements at a high level. We will revise the abstract to include brief references to these methods and direct readers to Section 3 for the full details. revision: yes
Circularity Check
No circularity: purely empirical training and benchmarking with no derivations
full rationale
This paper contains no equations, derivations, first-principles results, or mathematical claims that could reduce to their inputs by construction. It describes dataset curation (Aloe-Vision-Data), model training at two scales, and benchmarking on CareQA-Vision plus other tasks. All central claims are empirical performance comparisons supported by open release of weights, recipes, and data. No self-citation load-bearing steps, no fitted parameters renamed as predictions, and no uniqueness theorems or ansatzes are invoked. The assumptions about data quality and low contamination are stated as empirical properties of the released artifacts and are subject to external verification rather than being self-referential.
Axiom & Free-Parameter Ledger
free parameters (2)
- data mixture composition
- model scales (7B and 72B)
axioms (1)
- domain assumption Quality-filtered multimodal mixture yields gains without harming general capabilities.
Reference graph
Works this paper leans on
-
[1]
Automatic evaluation of healthcare llms beyond question-answering
Anna Arias-Duart, Pablo Agustin Martin-Torres, Daniel Hinjos, Pablo Bernabeu-Perez, Lucia Urcelay Ganzabal, Marta Gonzalez Mallo, Ashwin Kumar Gururajan, Enrique Lopez-Cuena, Sergio Alvarez-Napagao, and Dario Garcia-Gasulla. Automatic evaluation of healthcare llms beyond question-answering. InProceedings of the 2025 Conference of the Nations of the Americ...
2025
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Hritik Bansal, Daniel Israel, Siyan Zhao, Shufan Li, Tung Nguyen, and Aditya Grover. Med- max: Mixed-modal instruction tuning for training biomedical assistants.arXiv preprint arXiv:2412.12661,
-
[4]
GitHub repository. Junying Chen, Chi Gui, Ruyi Ouyang, Anningzhe Gao, Shunian Chen, Guiming Hardy Chen, Xidong Wang, Ruifei Zhang, Zhenyang Cai, Ke Ji, et al. Huatuogpt-vision, to- wards injecting medical visual knowledge into multimodal llms at scale.arXiv preprint arXiv:2406.19280,
-
[5]
13 Guasch-Mart´ı et al. Zeming Chen, Alejandro Hern´ andez Cano, Angelika Romanou, Antoine Bonnet, Kyle Ma- toba, Francesco Salvi, Matteo Pagliardini, Simin Fan, Andreas K¨ opf, Amirkeivan Mo- htashami, et al. Meditron-70b: Scaling medical pretraining for large language models. arXiv preprint arXiv:2311.16079,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
URL https://zenodo.org/records/12608602. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
-
[7]
Aloe: A family of fine-tuned open healthcare llms.arXiv preprint arXiv:2405.01886,
Ashwin Kumar Gururajan, Enrique Lopez-Cuena, Jordi Bayarri-Planas, Adrian Tormos, Daniel Hinjos, Pablo Bernabeu-Perez, Anna Arias-Duart, Pablo Agustin Martin-Torres, Lucia Urcelay-Ganzabal, Marta Gonzalez-Mallo, et al. Aloe: A family of fine-tuned open healthcare llms.arXiv preprint arXiv:2405.01886,
-
[8]
PathVQA: 30000+ Questions for Medical Visual Question Answering
Xuehai He, Yichen Zhang, Luntian Mou, Eric Xing, and Pengtao Xie. Pathvqa: 30000+ questions for medical visual question answering.arXiv preprint arXiv:2003.10286,
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[9]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.1 v-thinking: Towards versatile multi- modal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Songtao Jiang, Yuan Wang, Sibo Song, Tianxiang Hu, Chenyi Zhou, Bin Pu, Yan Zhang, Zhibo Yang, Yang Feng, Joey Tianyi Zhou, et al. Hulu-med: A transparent gen- eralist model towards holistic medical vision-language understanding.arXiv preprint arXiv:2510.08668,
-
[11]
Tianbin Li, Yanzhou Su, Wei Li, Bin Fu, Zhe Chen, Ziyan Huang, Guoan Wang, Chenglong Ma, Ying Chen, Ming Hu, et al. Gmai-vl & gmai-vl-5.5 m: A large vision-language model and a comprehensive multimodal dataset towards general medical ai.arXiv preprint arXiv:2411.14522,
-
[12]
Slake: A semantically- labeled knowledge-enhanced dataset for medical visual question answering
Bo Liu, Li Ming Zhan, Li Xu, Lin Ma, Yan Yang, and Xiao Ming Wu. Slake: A semantically- labeled knowledge-enhanced dataset for medical visual question answering. In18th IEEE International Symposium on Biomedical Imaging, ISBI 2021, pages 1650–1654. IEEE Computer Society,
2021
-
[13]
arXiv preprint arXiv:2512.13961,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Capabilities of Gemini Models in Medicine
Khaled Saab, Tao Tu, Wei-Hung Weng, Ryutaro Tanno, David Stutz, Ellery Wulczyn, Fan Zhang, Tim Strother, Chunjong Park, Elahe Vedadi, et al. Capabilities of gemini models in medicine.arXiv preprint arXiv:2404.18416,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Towards Expert-Level Medical Question Answering with Large Language Models
15 Guasch-Mart´ı et al. Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Publisher correc- tion: Large language models encode clinical knowledge.Nature, 620(7973):19–19, 2023a. Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Le Hou...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Enhancing step-by-step and verifiable medical reasoning in mllms.arXiv preprint arXiv:2506.16962,
Haoran Sun, Yankai Jiang, Wenjie Lou, Yujie Zhang, Wenjie Li, Lilong Wang, Mianxin Liu, Lei Liu, and Xiaosong Wang. Enhancing step-by-step and verifiable medical reasoning in mllms.arXiv preprint arXiv:2506.16962,
-
[17]
URLhttps://huggingface.co/datasets/ argilla/magpie-ultra-v1.0. Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xue- jing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
16 Aloe-Vision Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Chenghao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, et al. Lingshu: A gen- eralist foundation model for unified multimodal medical understanding and reasoning. arXiv preprint arXiv:2506.07044,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Worse than random? an embarrass- ingly simple probing evaluation of large multimodal models in medical vqa
Qianqi Yan, Xuehai He, Xiang Yue, and Xin Eric Wang. Worse than random? an embarrass- ingly simple probing evaluation of large multimodal models in medical vqa. InFindings of the Association for Computational Linguistics: ACL 2025, pages 19188–19205,
2025
-
[21]
An Yang, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoyan Huang, Jiandong Jiang, Jianhong Tu, Jianwei Zhang, Jingren Zhou, et al. Qwen2. 5-1m technical report. arXiv preprint arXiv:2501.15383,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Yi: Open Foundation Models by 01.AI
ai. arXiv preprint arXiv:2403.04652,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Mimo-vl technical report.arXiv preprint arXiv:2506.03569, 2025
Zihao Yue, Zhenru Lin, Yifan Song, Weikun Wang, Shuhuai Ren, Shuhao Gu, Shicheng Li, Peidian Li, Liang Zhao, Lei Li, et al. Mimo-vl technical report.arXiv preprint arXiv:2506.03569,
-
[24]
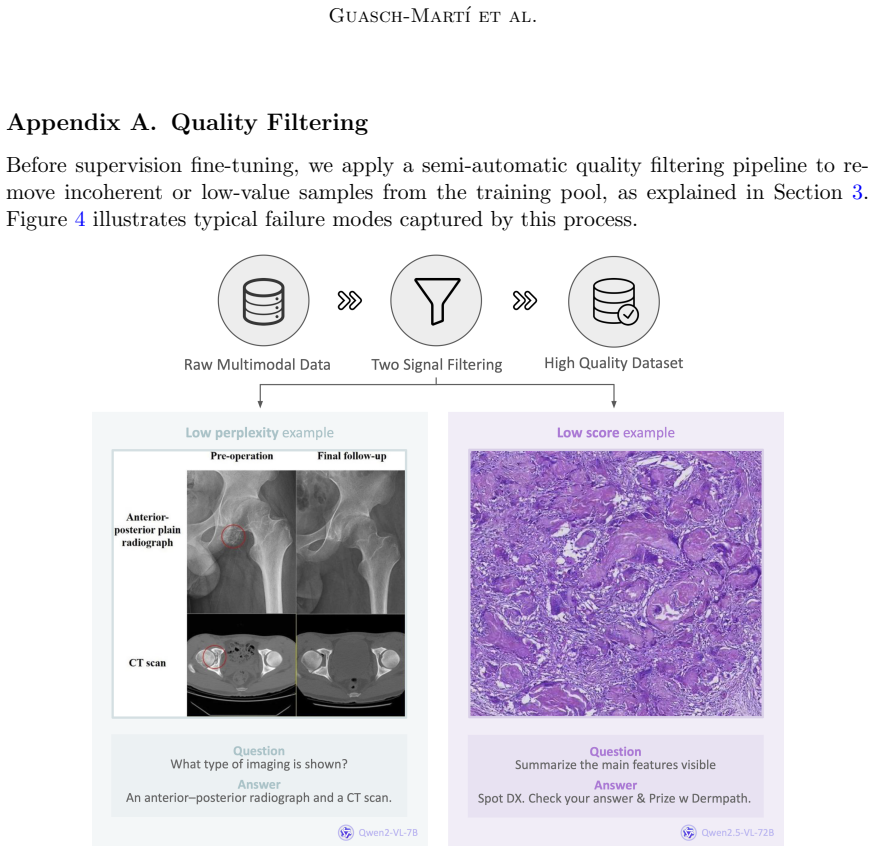
Figure 4: Semi-automatic quality filtering process
Figure 4 illustrates typical failure modes captured by this process. Figure 4: Semi-automatic quality filtering process. Below are examples of low-quality sam- ples identified during filtering. Left: answer appears in the image (low score, low perplexity). Right: answer unrelated to the image (low score, high perplexity). A.1. Tagging Template The followi...
2025
-
[25]
Parameter 7B 72B Stage Single-stage full SFT Precision BF16 Max
Table 6: Training configuration for Aloe-Vision-7B and Aloe-Vision-72B. Parameter 7B 72B Stage Single-stage full SFT Precision BF16 Max. Sequence length 4096 Epochs 1 LR schedule Cosine Gradient checkpointing Enabled Parallelism DeepSpeed ZeRO-3 Warmup 3% Global batch size 1024 2000 Micro-batch size 16 4 Gradient accumulation 2 5 Optimizer AdamW AdamW 8-b...
2000
-
[26]
Across all models, performance on MCQ is consistently higher than on open-ended tasks, highlighting ongoing challenges in free-text medical reasoning. Larger models generally outperform smaller ones, with Aloe-Vision-72B achieving the highest MCQ scores and GLM-4.5V leading in the open 21 Guasch-Mart´ı et al. Table 9: Filtered vs. non-filtered mixtures. A...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.