Beyond 'One Language, One Script': Quantifying Orthographic Bias in Multilingual VLMs with PuMVR
Pith reviewed 2026-06-26 17:30 UTC · model grok-4.3
The pith
Vision-language models exhibit accuracy gaps up to 16 percent on identical visual tasks depending on which script represents the same Punjabi language.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
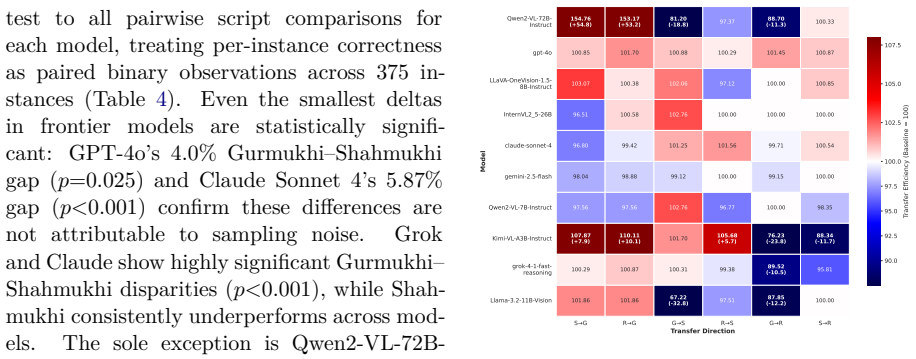
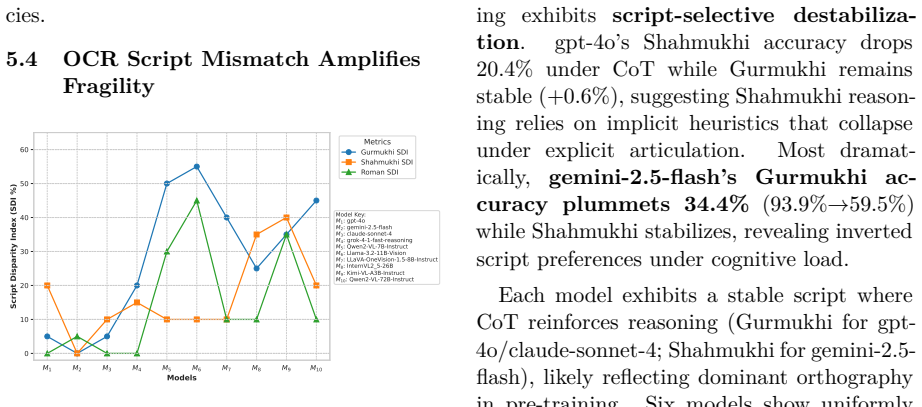
PuMVR reveals a substantial Script Gap in state-of-the-art VLMs, where accuracy deltas reach 16 percent across Punjabi's three scripts on culturally grounded visual reasoning tasks, and Script Consistency Rates drop to 24.8 percent. Visual input boosts absolute scores yet fails to close the relative gap between scripts, with reasoning patterns showing limited cross-script transferability and Chain-of-Thought pathways diverging by script alone.
What carries the argument
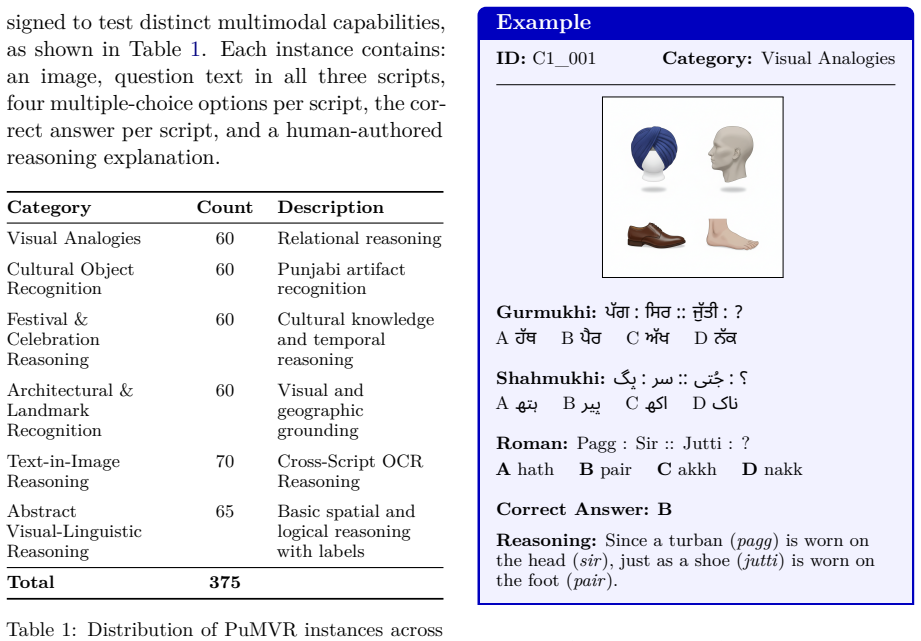
The PuMVR benchmark of 375 tasks across Gurmukhi, Shahmukhi, and Roman scripts, which quantifies orthographic bias via Script Consistency Rate.
If this is right
- Models solve the same visual puzzle in one script while failing it in another on the same content.
- Chain-of-Thought reasoning paths change when only the script of the question is altered.
- Visual input improves performance numbers but leaves relative script differences intact.
- Current multilingual benchmarks miss script variation inside one language.
- Script Consistency Rate should become a standard check for script-agnostic model assessment.
Where Pith is reading between the lines
- The same script-dependent gaps could appear in other languages that use multiple scripts, such as Serbian or Kurdish.
- Training pipelines might need explicit script-variation data to reduce the observed fracture.
- Extending the benchmark to additional multi-script languages would test how general the bias is.
- Evaluation suites could add script-swapping tests as a routine check for fairness.
Load-bearing premise
The 375 tasks keep identical difficulty, cultural grounding, and visual content across the three scripts, so differences can be blamed only on orthography.
What would settle it
Re-run the evaluations after confirming or adjusting the tasks so that content, difficulty, and visuals are verified equivalent across scripts; persistent gaps would support the bias claim while vanishing gaps would undermine it.
Figures

read the original abstract
Current Vision-Language Models (VLMs) are celebrated for their multilingual capabilities, yet they operate under a flawed assumption: that one language corresponds to a single writing system. This overlooks billions of users of multi-script languages like Punjabi, Serbian, Hindi-Urdu, Kurdish, among many others, for whom a model's capability may be fractured by orthographic bias. We introduce PuMVR (Punjabi Multimodal Visual Reasoning), the first benchmark designed to quantify script-dependent bias through 375 culturally grounded image-reasoning tasks across Punjabi's three active scripts (Gurmukhi, Shahmukhi, Roman). Evaluating 10 state-of-the-art VLMs, we expose a substantial Script Gap: models frequently solve visual puzzles in one script while failing identical tasks in another, with accuracy deltas reaching 16% and Script Consistency Rates (SCR) as low as 24.8%. Crucially, visual input boosts absolute performance but does not close this gap, the relative bias persists. Our analysis suggests reasoning patterns show limited cross-script transferability, and Chain-of-Thought pathways diverge based on script alone. We propose SCR as a core metric for script-agnostic evaluation, challenging current multilingual assessment paradigms and providing a framework for equitable AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the PuMVR benchmark consisting of 375 culturally grounded image-reasoning tasks rendered in Punjabi's three scripts (Gurmukhi, Shahmukhi, Roman) to measure orthographic bias in 10 state-of-the-art VLMs. It reports accuracy gaps reaching 16% across scripts, Script Consistency Rates (SCR) as low as 24.8%, and finds that adding visual input improves absolute performance but does not eliminate relative script-dependent differences; the work proposes SCR as a new evaluation metric.
Significance. If the tasks prove equivalent in difficulty and content, the results would establish a concrete, measurable limitation in current multilingual VLMs for multi-script languages spoken by hundreds of millions of users. The creation of a dedicated Punjabi multimodal benchmark and the SCR metric constitute a useful empirical contribution to fairness and robustness evaluation in vision-language models.
major comments (2)
- [Abstract / §3] Abstract and §3 (Benchmark Construction): The central claim that observed accuracy deltas (up to 16%) and low SCR values are attributable solely to orthographic bias requires that the 375 tasks maintain identical semantic content, difficulty, and cultural grounding across the three scripts. The manuscript supplies no details on equivalence verification (human ratings, back-translation checks, lexical-frequency calibration, or difficulty pre-testing), which is load-bearing for isolating script as the causal factor.
- [§4 / §5] §4 (Experimental Setup) and §5 (Results): No information is provided on statistical testing, error bars, or controls for prompt-formatting differences across scripts. Without these, it is unclear whether the reported gaps exceed what would be expected from sampling variability or minor surface-form variations.
minor comments (2)
- [Results tables] Table 1 or equivalent: clarify how the 375 tasks were partitioned across the three scripts and whether each image is paired with exactly one question per script.
- [§2] Notation: define SCR explicitly on first use and state whether it is computed per model or aggregated.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments, which highlight important aspects of benchmark validity and statistical rigor. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (Benchmark Construction): The central claim that observed accuracy deltas (up to 16%) and low SCR values are attributable solely to orthographic bias requires that the 375 tasks maintain identical semantic content, difficulty, and cultural grounding across the three scripts. The manuscript supplies no details on equivalence verification (human ratings, back-translation checks, lexical-frequency calibration, or difficulty pre-testing), which is load-bearing for isolating script as the causal factor.
Authors: We agree that explicit equivalence verification is necessary to causally attribute differences to orthography. The submitted manuscript omitted these procedural details in favor of focusing on benchmark release and empirical results. In the revision we will expand §3 with: native-speaker semantic-equivalence ratings (5-point scale, inter-annotator agreement reported), back-translation checks to English, lexical-frequency calibration against available Punjabi corpora, and pilot difficulty pre-testing. These additions will directly support the isolation of script as the variable. revision: yes
-
Referee: [§4 / §5] §4 (Experimental Setup) and §5 (Results): No information is provided on statistical testing, error bars, or controls for prompt-formatting differences across scripts. Without these, it is unclear whether the reported gaps exceed what would be expected from sampling variability or minor surface-form variations.
Authors: We accept that the current version lacks statistical controls and error quantification. The revision will add: (i) bootstrap-derived 95% confidence intervals on all accuracy figures, (ii) McNemar’s test for paired script-wise comparisons on identical tasks, and (iii) the exact prompt templates (identical structure, only script changed) in the appendix to demonstrate formatting control. These changes will clarify that observed gaps exceed sampling variability. revision: yes
Circularity Check
Empirical benchmark evaluation with no derivations or self-referential reductions
full rationale
The paper introduces the PuMVR benchmark of 375 image-reasoning tasks and reports direct accuracy measurements, deltas, and SCR values from evaluating 10 VLMs across three scripts. No equations, fitted parameters, predictions, or uniqueness theorems appear; claims rest on observed model outputs rather than any chain that reduces to inputs by construction. The central assumption of task equivalence across scripts is an experimental design choice, not a circular derivation. This is a standard empirical measurement study whose results are self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 375 tasks are equivalent in difficulty and meaning across the three scripts.
Reference graph
Works this paper leans on
-
[1]
Learning Transferable Visual Models From Natural Language Supervision
CORI: CJKV benchmark with Roman- ization integration - a step towards cross-lingual transfer beyond textual scripts . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages 4008–4020, Torino, Italia. ELRA and ICCL. OpenAI. 2024. GPT-4o System Card. https:// opena...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Vision language models are blind: Failing to translate detailed visual features into words . Preprint, arXiv:2407.06581. Phillip Rust, Jonas Pfeiffer, Ivan Vulić, Sebastian Ruder, and Iryna Gurevych. 2021. How good is your tokenizer? on the monolingual perfor- mance of multilingual language models . In Pro- ceedings of the 59th Annual Meeting of the As- so...
-
[3]
Blend-vis: Benchmarking multimodal cul- tural understanding in vision language models . Preprint, arXiv:2510.11178. Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Gar- rett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, Soroosh Mariooryad, Yifan Ding, Xinyang Geng, Fred Alcober, Roy Frostig, Mark Omernick, Lexi Walker,...
-
[4]
All languages matter: Evaluating lmms on culturally diverse 100 languages . Preprint, arXiv:2411.16508. An Vo, Khai-Nguyen Nguyen, Mohammad Reza Taesiri, Vy Tuong Dang, Anh Totti Nguyen, and Daeyoung Kim. 2025. Vision language models are biased . Preprint, arXiv:2505.23941. Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Mingjie Zhan, and Hongsheng Li. 2024. ...
-
[5]
Forcing the model to re- produce the script-specific text ensures it can parse and generate the target orthog- raphy
Script Comprehension V erification: A model might correctly guess a letter (25% probability) without truly process- ing the script. Forcing the model to re- produce the script-specific text ensures it can parse and generate the target orthog- raphy
-
[6]
hallucinated
F ailure Mode Analysis: By requiring text output, we could identify cases where models produced "hallucinated" charac- ters or mixed scripts, data that would be lost if restricted to single-letter outputs. D.3 Experiment 1: Baseline Script Gap The primary benchmark used the following template with English instructions and script- specific constraints. Exp ...
-
[11]
Exp 2: Native Script Instructions Question {Script Instruction}: {question} Options: {formatted_options} CRITICAL RULES:
Output ONLY the option text, nothing else Your answer (copy exact text from options): Answer: D.4 Experiment 2: Native Instruction Prompting This experiment used similar prompts as ex- periment 1, without the image input to test model performance and establish a baseline. Exp 2: Native Script Instructions Question {Script Instruction}: {question} Options:...
-
[12]
Answer MUST be in the SAME script as the question
-
[13]
Copy EXACTLY one option from above - character by character
-
[14]
NO explanations, NO extra words, NO English translations
-
[15]
NO letters like A), B), C) or numbers
-
[16]
Exp 3: System Prompt You are a precise answering assistant
Output ONLY the option text, nothing else Your answer (copy exact text from options): D.5 Experiment 3: System Prompting (F ew-Shot) For experiments involving system-level instruc- tions, the following persona-based prompt was utilized. Exp 3: System Prompt You are a precise answering assistant. You will be given a visual question and options. You must ou...
-
[17]
NO option letters (like A, B)
-
[18]
look and write
Output strictly the option text. D.6 Experiment 4: OCR-A ware T ranscription This prompt forced the model to first "look and write" before deciding, to decouple visual recognition from reasoning. Exp 4: OCR + Decision Prompt Question {Script Instruction}: {question} Options: {formatted_options} TASK INSTRUCTIONS:
-
[19]
LOOK at the image text carefully
-
[20]
TRANSCRIPTION: Write down exactly what text you see in the image (if any)
-
[21]
REQUIRED OUTPUT FORMAT: OCR: [Write the text from the image here]
DECISION: Choose the correct option from the list above. REQUIRED OUTPUT FORMAT: OCR: [Write the text from the image here]
-
[22]
You are taking a multiple choice test
-
[23]
Select the Correct Option from the list above
-
[24]
Your output must be IDENTICAL to one of the options
-
[25]
DO NOT write ’Answer:’
DO NOT provide reasoning. DO NOT write ’Answer:’
-
[26]
ANSWER: [Write ONLY the selected option text here] D.7 Experiment 5: Chain-of-Thought (CoT) Models were prompted to follow a 5-step rea- soning process
DO NOT use A), B), C), D). ANSWER: [Write ONLY the selected option text here] D.7 Experiment 5: Chain-of-Thought (CoT) Models were prompted to follow a 5-step rea- soning process. The instructions were pro- vided in the same script as the question. Exp 5: Gurmukhi CoT T emplate ਤੁਹਾਨੂ ੰ ਇਹਨਾਂ ਕਦਮਾਂ ਦੀ ਸਪੱਸ਼ਟ ਤੌਰ ’ਤੇ ਪਾਲਣਾ ਕਰਕੇ ਇਸ ਮਲਟੀਮੋਡਲ ਸਮੱਿਸਆ ਨੂ ੰ ਹੱਲ ਕਰਨਾ ਹੈ :
-
[27]
ਿਵਜ਼ੂਅਲ ਗਰਾਊਂਿਡੰਗ : ਿਚੱਤਰ ਦੇ ਆਧਾਰ ’ਤੇ, 3 ਸਭ ਤੋਂ ਪਰ੍ਮੁੱਖ ਵਸਤੂਆਂ, ਿਦÁਸ਼ਾਂ ਜਾਂ ਿਕਿਰਆਵਾਂ ਦੀ ਸੂਚੀ ਬਣਾਓ।
-
[28]
ਭਾਸ਼ਾਈ ਪਾਰਿਸੰਗ : ਇਹ ਯਕੀਨੀ ਬਣਾਉਣ ਲਈ ਿਕ ਤੁਸੀਂ ਇਸਨੂ ੰ ਸਮਝਦੇ ਹੋ, ਆਪਣੇ ਸ਼ਬਦਾਂ ਿਵੱਚ ਪਰ੍ਸ਼ਨ ਨੂ ੰ ਦੁਬਾਰਾ ਿਲਖੋ।
-
[29]
ਸੰਬੰਧ ਐਬਸਟਰੈਕਸ਼ਨ: ਪਰ੍ਸ਼ਨ ਦੁਆਰਾ ਪਰਖਣ ਵਾਲੇ ਮੁੱਖ ਸੰਬੰਧ ਜਾਂ ਸੰਕਲਪ ਦੀ ਪਛਾਣ ਕਰੋ।
-
[30]
ਕਰਾਸ-ਮਾਡਲ ਏਕੀਕਰਣ: ਸਮਝਾਓ ਿਕ ਕਦਮ 1 ਦੇ ਿਵਜ਼ੂਅਲ ਤੱਤ ਤੁਹਾਨੂ ੰ ਕਦਮ 2 ਦੇ ਪਰ੍ਸ਼ਨ ਦਾ ਉੱਤਰ ਦੇਣ ਿਵੱਚ ਿਕਵੇਂ ਮਦਦ ਕਰਦੇ ਹਨ।
-
[31]
ਕਟੌਤੀ: ਕਦਮ 1-4 ਦੇ ਆਧਾਰ ’ਤੇ, ਉੱਤਰ ਕੱਢੋ। ਅੰਿਤਮ ਉੱਤਰ : ਅੰਿਤਮ ਿਵਕਲਪ ਟੈਕਸਟ ਦੱਸੋ ( ਿਦੱਤੇ ਗਏ ਿਵਕਲਪਾਂ ਤੋਂ ਿਬਲਕੁਲ ਕਾਪੀ ਕਰੋ )। ਹੁਣ, ਹੇਠਾਂ ਿਦੱਤੀ ਸਮੱਿਸਆ ਨੂ ੰ ਕਦਮ-ਦਰ-ਕਦਮ ਹੱਲ ਕਰੋ। Exp 5: Shahmukhi CoT T emplate ﻃﻮرﺳﭙﺸﭧدیﻗﺪﻣﺎںاﯾﮩﻨﺎںﺗﻮﮨﺎﻧﻮں ’ﭘﺎﻟﻨﺎﺗﮯ ﮨﮯﮐﺮﻧﺎﺣﻞﻧﻮںﺳﻤﺴﯿﺎﻣﺎڈلﻣﻠﭩﯽاِسﮐﺮﮐﮯ : 1.ﮔﺮاؤﻧﮉﻧﮓوِژوﺋﻞ :آدﮬﺎردےﭼِﺘﺮ ’ﺗﮯ 3ﮐﺮﯾﺎواںﺟﺎںدرﺷﺎںوﺳﺘﻮاں،ﭘﺮﻣﮑﮫﺗﻮںﺳﺒﮫ ﺑﻨﺎؤ۔ﺳﻮﭼﯽدی 2.ﭘﺎرﺳﻨﮓ...
-
[32]
vizooal graaoonding: chittar de aadhaar ’te, 3 sabh ton pramukkh vastuaan, drishaan jaan kiriavaan dee soochee banao
-
[33]
bhashai paarsing: eh yakeenee banaun laee ki tuseen isnu samajhde ho, aapne shabdaan vich prashan nu dubaara likho
-
[34]
sambandh aibstraikshan: prashan duara parkhan vaale mukkh sambandh jaan sankalp dee pachhaan karo
-
[35]
kraas-modal ekeekaran: samjhao ki kadam 1 de vizooal tatt tuhannu kadam 2 de prashan da uttar den vich kiven madad karde han
-
[36]
antim uttar: antim vikalp taikst dasso (ditte gae vikalpaan ton bilkul kaapee karo)
katauti: kadam 1-4 de aadhaar ’te, uttar kaddho. antim uttar: antim vikalp taikst dasso (ditte gae vikalpaan ton bilkul kaapee karo). hun, hethaan dittee samassya nu kadam-dar-kadam hall karo. E Statistical Significance Testing Table 9 reports McNemar’s test results for all pairwise script comparisons across all 10 mod- els. We apply McNemar’s test treatin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.