Flow-Map GRPO: Reinforcement Learning for Few-Step Flow-Map Generators via Anchored Stochastic Composition
Pith reviewed 2026-07-02 16:02 UTC · model grok-4.3
The pith
Deterministic few-step flow-map generators can be aligned with RL post-training by adding anchored stochastic composition that preserves their original marginal paths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
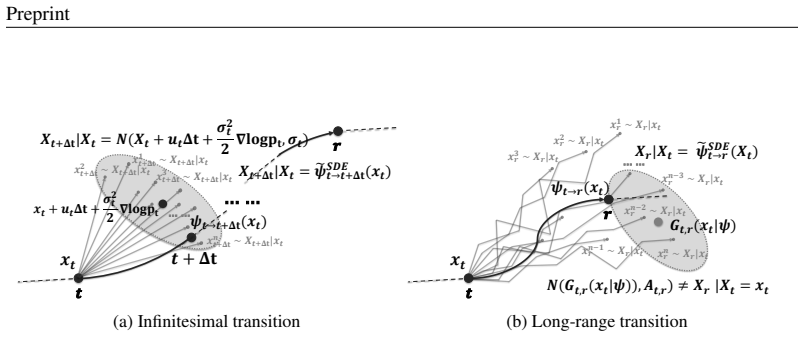
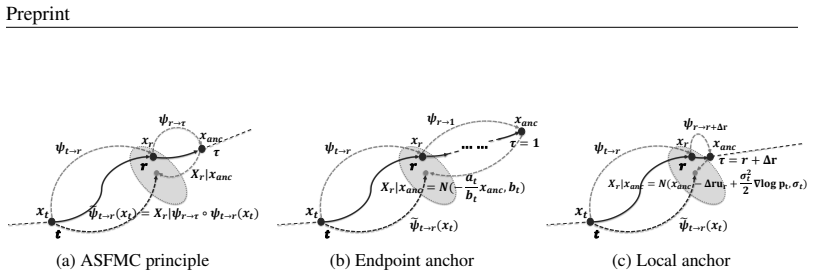
Flow-Map GRPO is an online RL post-training method whose central mechanism, Anchored Stochastic Flow Map Composition, introduces controlled randomness through anchor-based conditional resampling while exactly preserving the marginal probability path of a deterministic flow map, enabling derivation of GRPO objectives that align single-time and two-time flow-map generators without retraining them as stochastic models.
What carries the argument
Anchored Stochastic Flow Map Composition (ASFMC), a path-preserving stochasticization that adds randomness by anchor-based conditional resampling while keeping the deterministic model's marginal probability path unchanged.
If this is right
- GRPO objectives become applicable to both single-time and two-time flow-map parameterizations.
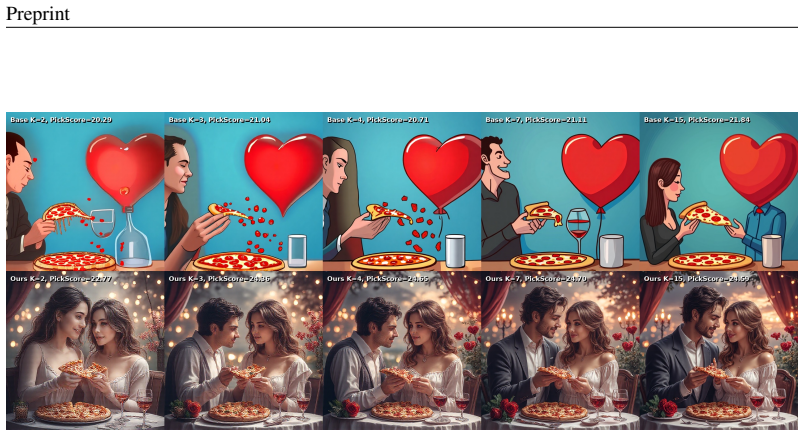
- RL post-training improves reward-based, perceptual, and task-level metrics on pretrained FLUX-based generators such as MeanFlow and sCM.
- Deterministic few-step models can receive alignment without any change to their original model parameterization.
- The same framework applies directly to other long-range deterministic transport maps used in generation.
Where Pith is reading between the lines
- The approach may extend to other deterministic long-range maps outside image generation, such as those in audio or 3D synthesis.
- Path preservation during stochasticization could become a general design principle for applying likelihood-based RL to non-Markovian samplers.
- If ASFMC works for two-time maps, similar anchor constructions might support multi-time or hierarchical flow-map RL.
Load-bearing premise
The anchored resampling step adds stochasticity without altering the marginal probability path of the original deterministic flow map.
What would settle it
Measure whether samples drawn from the ASFMC-augmented model match the distribution of the original deterministic model on a held-out set of prompts; any systematic shift would indicate path alteration.
Figures


























read the original abstract
Few-step flow-map generators, such as consistency models and MeanFlow, accelerate sampling by directly learning long-range transport maps between noise and data. However, these models are typically deterministic, which makes them difficult to optimize with reinforcement learning (RL) post-training methods that require stochastic trajectories and well-defined likelihood ratios. Existing SDE-based stochasticization techniques are designed for velocity-based samplers with infinitesimal or finely discretized transitions, and therefore do not directly apply to long-range flow maps. In this work, we propose Flow-Map GRPO, an online RL post-training framework for deterministic few-step flow-map generators. The key component is Anchored Stochastic Flow Map Composition (ASFMC), a path-preserving stochasticization mechanism that introduces randomness through anchor-based conditional resampling while preserving the original marginal probability path of the deterministic flow map. We derive GRPO objectives for both single-time and two-time flow-map parameterizations. Experiments on few-step FLUX-based text-to-image generators, including MeanFlow and sCM, show that Flow-Map GRPO improves pretrained deterministic flow-map models across reward-based, perceptual, and task-level evaluation metrics. Our results demonstrate that deterministic few-step flow-map generators can be effectively aligned with RL post-training without modifying their original model parameterization or retraining them as native stochastic models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Flow-Map GRPO, an online RL post-training framework for deterministic few-step flow-map generators (e.g., consistency models, MeanFlow). Its core component is Anchored Stochastic Flow Map Composition (ASFMC), which adds randomness via anchor-based conditional resampling while claiming to exactly preserve the original marginal probability path of the deterministic flow map. GRPO objectives are derived for single-time and two-time parameterizations. Experiments on FLUX-based text-to-image models report improvements on reward, perceptual, and task metrics without altering the pretrained deterministic parameterization or retraining as native stochastic models.
Significance. If the path-preservation property of ASFMC holds exactly, the result would enable direct RL alignment of fast deterministic few-step generators, addressing a practical gap between deterministic flow-map acceleration and stochastic RL post-training methods. This would be a meaningful contribution for efficient generative modeling pipelines.
major comments (2)
- [Abstract / ASFMC definition] Abstract and the derivation of ASFMC: the central claim that ASFMC 'introduces randomness through anchor-based conditional resampling while preserving the original marginal probability path' is load-bearing for using the pretrained deterministic parameterization directly in GRPO. The manuscript must supply an explicit proof or set of conditions (e.g., on invertibility or discretization) showing that the marginals remain unchanged; without it, the RL objective optimizes a different process than asserted.
- [GRPO objective derivations] The GRPO objective derivations for single-time and two-time flow-map parameterizations rely on well-defined likelihood ratios from the stochasticized trajectories. If the marginal preservation is only approximate, the policy-gradient estimates in these objectives become biased relative to the original deterministic model.
minor comments (2)
- [Methods] Notation for anchor resampling and conditional distributions should be introduced with explicit equations to clarify the difference from standard SDE-based stochasticization.
- [Experiments] The experimental section would benefit from an ablation isolating the effect of ASFMC versus standard GRPO on the same base models.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive comments on our work. The points raised about providing an explicit proof for the marginal preservation in ASFMC and the implications for the GRPO objectives are well-taken. We respond to each major comment below and will make the necessary revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / ASFMC definition] Abstract and the derivation of ASFMC: the central claim that ASFMC 'introduces randomness through anchor-based conditional resampling while preserving the original marginal probability path' is load-bearing for using the pretrained deterministic parameterization directly in GRPO. The manuscript must supply an explicit proof or set of conditions (e.g., on invertibility or discretization) showing that the marginals remain unchanged; without it, the RL objective optimizes a different process than asserted.
Authors: We agree that the manuscript would benefit from an explicit proof of the marginal preservation property to support the central claim. The current derivation implicitly relies on the construction of the anchored resampling to match the deterministic transport, but we acknowledge the need for a formal statement. In the revised version, we will add a proof in the supplementary material or a new section, specifying the conditions (such as the flow map being a diffeomorphism and anchors chosen from the appropriate distribution) under which the marginals are exactly preserved. This will confirm that the stochastic process has identical marginal probability paths to the deterministic flow map. revision: yes
-
Referee: [GRPO objective derivations] The GRPO objective derivations for single-time and two-time flow-map parameterizations rely on well-defined likelihood ratios from the stochasticized trajectories. If the marginal preservation is only approximate, the policy-gradient estimates in these objectives become biased relative to the original deterministic model.
Authors: This concern is directly tied to the previous point. Once the exact marginal preservation is established via the added proof, the likelihood ratios in the GRPO objectives will be well-defined and unbiased with respect to the original deterministic model's marginal paths. We will revise the manuscript to explicitly link the derivations to the preservation property and include a note on the unbiasedness of the gradient estimates under these conditions. No changes to the experimental results are needed as they are based on the claimed property. revision: yes
Circularity Check
No significant circularity; ASFMC introduced as independent mechanism
full rationale
The paper's central claim rests on ASFMC as a path-preserving stochasticization that enables RL on deterministic flow maps without reparameterization. The abstract presents this as a novel construction rather than a quantity fitted to or defined by the target result. No equations or self-citations in the provided text reduce the preservation property to a tautology or prior self-result. The derivation chain remains self-contained against external benchmarks, consistent with a low circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training diffusion models with reinforcement learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning. InInternational Conference on Learning Representations, volume 2024, pp. 4965–4987,
2024
-
[2]
Flow matching in latent space.arXiv preprint arXiv:2307.08698,
Quan Dao, Hao Phung, Binh Nguyen, and Anh Tran. Flow matching in latent space.arXiv preprint arXiv:2307.08698,
-
[3]
Consistency models made easy.arXiv preprint arXiv:2406.14548,
Zhengyang Geng, Ashwini Pokle, William Luo, Justin Lin, and J Zico Kolter. Consistency models made easy.arXiv preprint arXiv:2406.14548,
-
[4]
Mean Flows for One-step Generative Modeling
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447, 2025a. Zhengyang Geng, Yiyang Lu, Zongze Wu, Eli Shechtman, J Zico Kolter, and Kaiming He. Improved mean flows: On the challenges of fastforward generative models.arXiv preprint arXiv:2512.02012, 2025b. Y...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Diamond Maps: Efficient Reward Alignment via Stochastic Flow Maps
14 Preprint Peter Holderrieth, Douglas Chen, Luca Eyring, Ishin Shah, Giri Anantharaman, Yutong He, Zeynep Akata, Tommi Jaakkola, Nicholas Matthew Boffi, and Max Simchowitz. Diamond maps: Efficient reward alignment via stochastic flow maps.arXiv preprint arXiv:2602.05993, 2026a. Peter Holderrieth, Uriel Singer, Tommi Jaakkola, Ricky TQ Chen, Yaron Lipman,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Junzhe Li, Yutao Cui, Tao Huang, Yinping Ma, Chun Fan, Yiming Cheng, Miles Yang, Zhao Zhong, and Liefeng Bo. Mixgrpo: Unlocking flow-based grpo efficiency with mixed ode-sde.arXiv preprint arXiv:2507.21802,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Trajectory consistency for one-step generation on euler mean flows.arXiv preprint arXiv:2602.02571,
Zhiqi Li, Yuchen Sun, Duowen Chen, Jinjin He, and Bo Zhu. Trajectory consistency for one-step generation on euler mean flows.arXiv preprint arXiv:2602.02571,
-
[8]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Yaron Lipman, Marton Havasi, Peter Holderrieth, Neta Shaul, Matt Le, Brian Karrer, Ricky TQ Chen, David Lopez-Paz, Heli Ben-Hamu, and Itai Gat. Flow matching guide and code.arXiv preprint arXiv:2412.06264,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Sam McCallum, Zander W Blasingame, Timothy Herschell, Niklas Rindtorff, Alexander Tong, and James Foster. Strong stochastic flow maps.arXiv preprint arXiv:2606.01086,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Meta Flow Maps enable scalable reward alignment
Peter Potaptchik, Adhi Saravanan, Abbas Mammadov, Alvaro Prat, Michael S Albergo, and Yee Whye Teh. Meta flow maps enable scalable reward alignment.arXiv preprint arXiv:2601.14430,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Yifan Pu, Yizeng Han, Zhiwei Tang, Jiasheng Tang, Fan Wang, Bohan Zhuang, and Gao Huang. Few-step distillation for text-to-image generation: A practical guide.arXiv preprint arXiv:2512.13006,
-
[13]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020a. Yang Song and Prafulla Dhariwal. Improved techniques for training consistency models. InInter- national Conference on Learning Representations (ICLR),
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[15]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020b. 15 Preprint Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. InInternational Conference on Machine Learning (ICML),
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[16]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation.arXiv preprint arXiv:2505.07818,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Unlike instantaneous velocity fields, long-range flow maps do not admit a self-consistent conditional counterpart
In multi-step methods such as Flow Matching, this issue is circumvented by constructing a conditional probability pathp t(xt|x1)and using an as- sociated instantaneous quantity, such as the conditional velocityu t(xt|x1), to regress the marginal velocity: LFM(θ) =E t, x1∼p1, xt∼pt|1(·|x1)[∥uθ(xt, t)−u t(xt|x1)∥2 2].(19) The same strategy, however, does no...
2026
-
[18]
Existing flow-map-based generative models can therefore be broadly organized into two categories according to how they obtain supervision for long-range maps:progressive distillationmethods andderivative-basedmethods Li et al. (2026). The former progressively transfers supervision from short-range transitions to longer-range maps, while the latter derives...
2026
-
[19]
(47) The leading terms are exactly ˜Xloc r
For the short deterministic segmentr→τ, discretizing the ODE gives Xτ =ψ r→r+∆r(Xr) =X r + ∆rur(Xr) +O((∆r) 2).(46) 21 Preprint Substituting this expression and the formula forB r gives ˜X ⋆ r =X r + ∆rur(Xr)−∆r[(1−λ 2)ur(Xr) +λ 2 ˙ar ar Xr] +σ r √ ∆rξ+O((∆r) 3/2) =X r −∆rλ 2[ ˙ar ar Xr −u r(Xr)] +σ r √ ∆rξ+O((∆r) 3/2). (47) The leading terms are exactly ...
2025
-
[20]
X Marks the Spot
Common training hyperparameters.Unless otherwise specified, the following hyperparameters are shared across PickScore, OCR, and GenEval post-training runs, and across the MeanFlow and sCM backbones. LoRA configuration.All post-training runs use the same LoRA architecture. The LoRA rank is set to64, the LoRA scaling factor is set to128, and the LoRA dropou...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.