Field Order Should Not Matter: Permutation-Invariant Embedding Model Fine-Tuning for Structured Metadata Retrieval
Pith reviewed 2026-06-30 06:09 UTC · model grok-4.3
The pith
Fine-tuned embedding models for structured records read absolute position instead of field labels, but randomizing order during training removes nearly all order sensitivity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
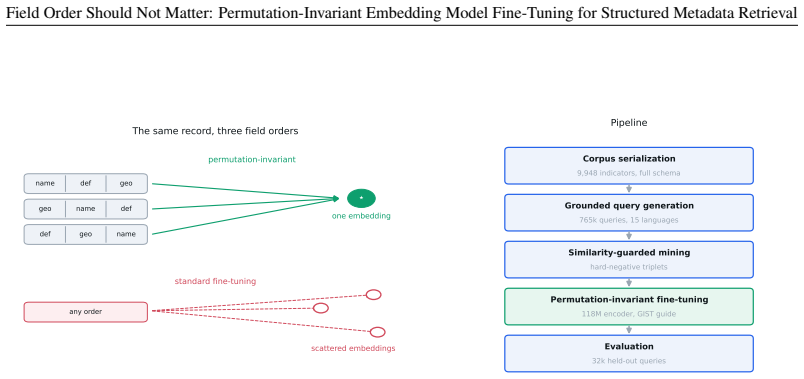
By serializing each record under a freshly sampled field order with random field dropout during fine-tuning, the encoder learns to associate semantics with field labels rather than absolute positions in the input string. This makes retrieval quality robust to the arbitrary choice of field order at inference time.
What carries the argument
Permutation-invariant fine-tuning (PI-FT): the procedure of sampling a fresh field permutation and applying random field dropout for each training example.
If this is right
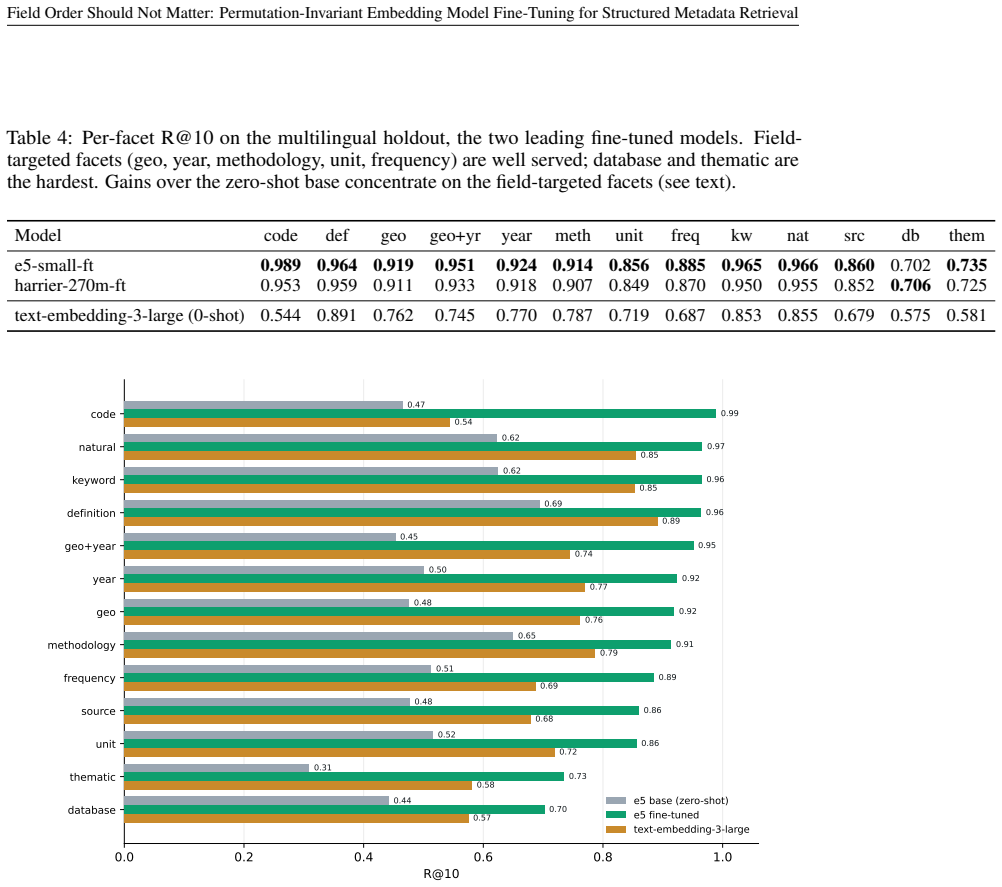
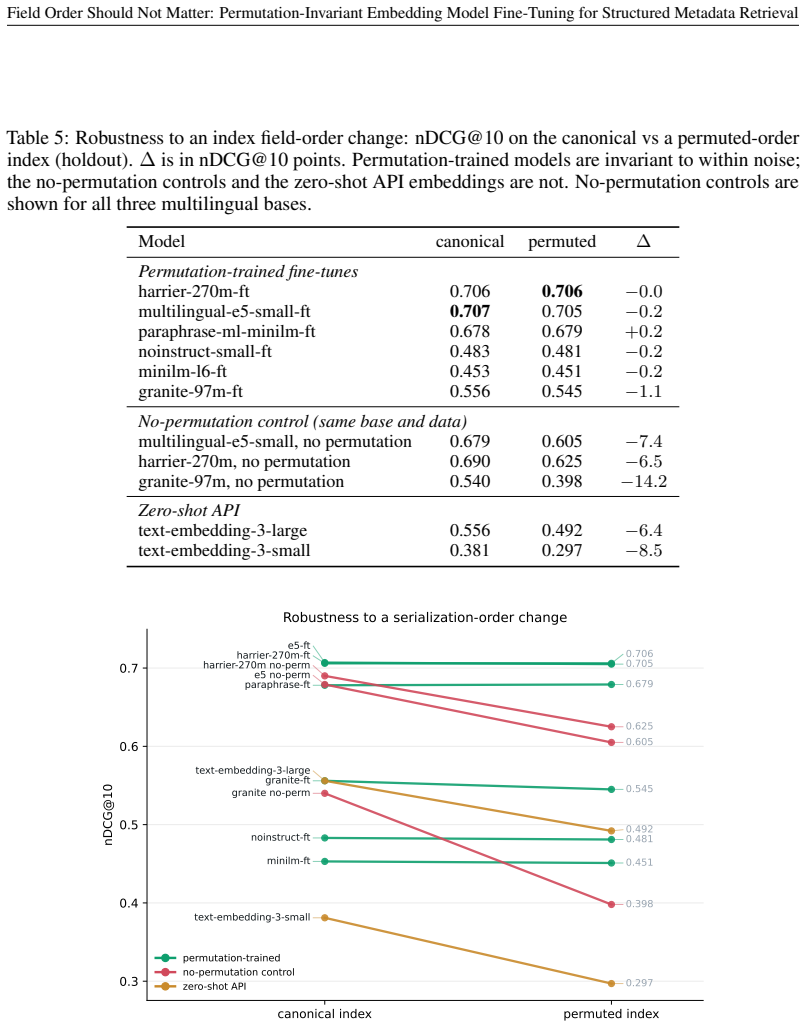
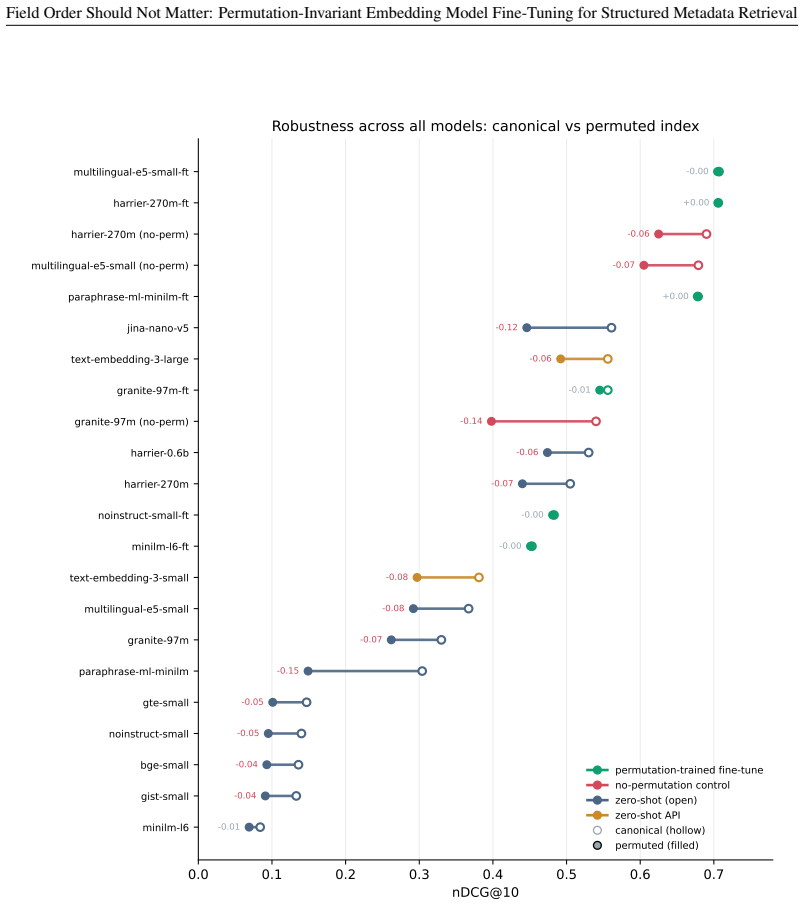
- The order sensitivity penalty falls from 7.4 to 0.2 nDCG@10 points.
- In-distribution accuracy stays nearly unchanged.
- The fine-tuned 118M model reaches 0.707 nDCG@10, beating text-embedding-3-large at 0.556.
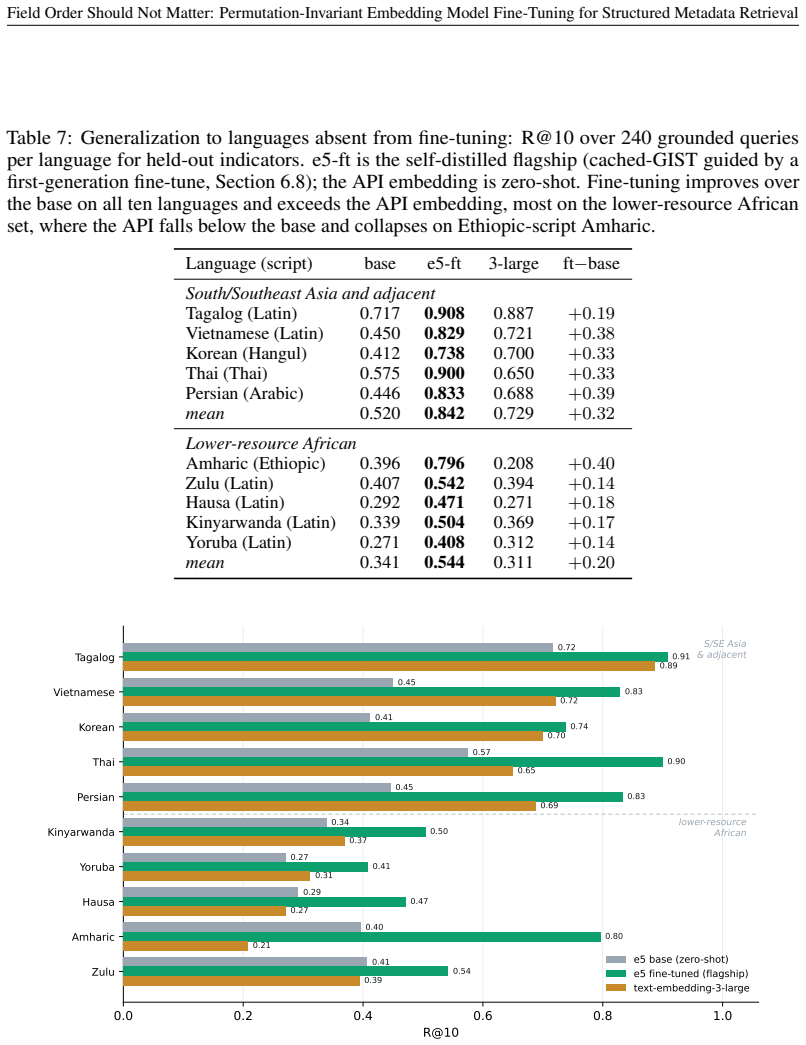
- The method works across 15 languages on the DevDataBench queries.
Where Pith is reading between the lines
- Similar randomization could reduce position bias in other text serialization tasks such as tabular data or JSON retrieval.
- This approach may help when the same catalog is queried by different systems that serialize fields differently.
- The benchmark's LLM-generated queries might not fully capture real user search patterns.
Load-bearing premise
Randomizing field order with dropout during fine-tuning will make the model associate semantics with field labels instead of positions, and this will hold for LLM-generated queries on DevDataBench.
What would settle it
Measure nDCG@10 on the same test queries after rebuilding the index with a different field order; if the drop remains close to 7 points after PI-FT, the invariance claim is false.
Figures
read the original abstract
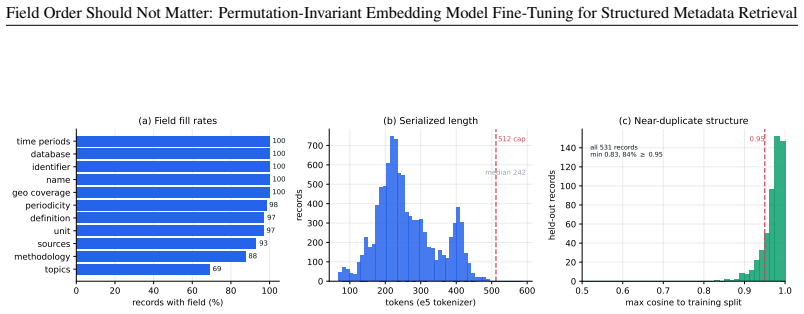
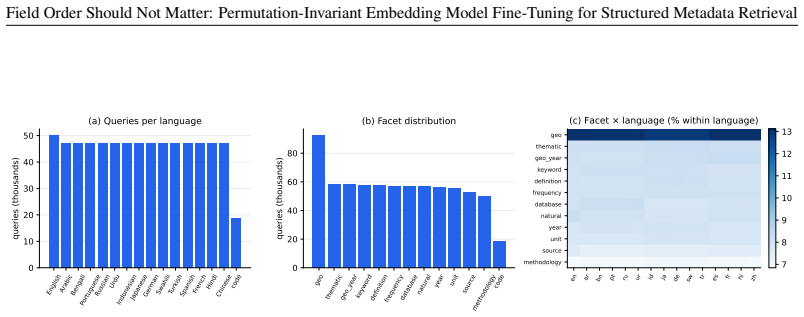
We study retrieval over catalogs of structured metadata, where each record is a small schema whose fields answer different kinds of query. Embedding a record with a text encoder first serializes its fields into a string, which forces a choice of field order. We show this choice, usually treated as an implementation detail, silently controls retrieval quality once the encoder is fine-tuned. A standard fine-tune loses 7.4 nDCG@10 points when the index is rebuilt under a different field order, because it reads absolute position instead of the field labels. We propose permutation-invariant fine-tuning ($\textbf{PI-FT}$), which serializes each record under a freshly sampled field order with random field dropout, so meaning binds to the labels rather than to position. The change is about two lines in the data loader; it costs negligible in-distribution accuracy and cuts the order-change penalty to 0.2 points. We study this in the discovery of development statistics, a catalog of nearly 10,000 indicators that should be searchable in many languages by a model small enough to self-host. As AI assistants and agents increasingly mediate access to public data and statistics, this retrieval step decides whether an answer is grounded in the right indicator or series, making discoverability a precondition for disseminating data through AI. Because usage logs cannot provide training signal for indicators no one has searched, we generate the queries instead. $\textbf{DevDataBench}$ is a fully LLM-generated benchmark of grounded, facet-targeted queries across 15 languages, covering every indicator for both training and evaluation. A fine-tuned 118M-parameter CPU encoder outperforms every zero-shot baseline, including $\texttt{text-embedding-3-large}$ (0.707 vs.\ 0.556 nDCG@10), with the largest gains in low-resource languages. We release the benchmark, pipeline, models, and a reusable PI-FT framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that serializing structured metadata records for embedding models makes field order an implicit but critical hyperparameter: standard fine-tuning causes encoders to rely on absolute token positions rather than field labels, producing a 7.4-point nDCG@10 drop when the index is rebuilt under a different order. The authors introduce permutation-invariant fine-tuning (PI-FT), which samples a fresh field order and applies random field dropout at each training step, binding semantics to labels instead; this reduces the order-change penalty to 0.2 points with negligible in-distribution cost. They also release DevDataBench, a fully LLM-generated retrieval benchmark covering ~10k development indicators across 15 languages, and show that a fine-tuned 118M-parameter encoder (0.707 nDCG@10) outperforms zero-shot baselines including text-embedding-3-large (0.556).
Significance. If the empirical claims hold, the work identifies a previously under-appreciated source of brittleness in fine-tuned retrieval over structured data and supplies a lightweight, data-loader-only remedy with clear practical value for catalog search, especially in low-resource languages and public-data settings. The release of the benchmark, pipeline, models, and reusable PI-FT framework constitutes a concrete contribution that enables further verification and reuse.
major comments (2)
- [Experiments / DevDataBench construction] The abstract and introduction report precise quantitative results (7.4 vs. 0.2 nDCG@10 order-change penalty, 0.707 vs. 0.556 overall) yet the manuscript provides no access to the full experimental protocol, benchmark-generation procedure, query-generation prompts, or verification code for the order-permutation tests. Without these details the central empirical claim cannot be independently assessed.
- [PI-FT description] The assumption that random field-order sampling plus dropout during fine-tuning causes the model to bind semantics to field labels (rather than to absolute positions) is invoked to explain the results, but no ablation isolating the contribution of each component (order randomization alone vs. dropout alone vs. both) is reported, leaving the mechanism under-specified.
minor comments (2)
- [Introduction] Notation for nDCG@10 and the exact serialization template should be defined once in a dedicated subsection rather than scattered across the abstract and introduction.
- [Method] The claim that the change is "about two lines in the data loader" is informal; a short pseudocode snippet or explicit data-loader modification would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for highlighting the practical implications of our work on permutation-invariant fine-tuning. We address the two major comments below, providing clarifications and committing to revisions where the manuscript can be strengthened.
read point-by-point responses
-
Referee: [Experiments / DevDataBench construction] The abstract and introduction report precise quantitative results (7.4 vs. 0.2 nDCG@10 order-change penalty, 0.707 vs. 0.556 overall) yet the manuscript provides no access to the full experimental protocol, benchmark-generation procedure, query-generation prompts, or verification code for the order-permutation tests. Without these details the central empirical claim cannot be independently assessed.
Authors: The manuscript states that the benchmark, pipeline, models, and PI-FT framework are released, which includes the generation code, prompts, and verification scripts for the order-permutation experiments. However, we agree that the main text does not embed the full prompts or protocol details. In the revised version we will add an appendix summarizing the benchmark construction procedure, key query-generation prompts, and links to the public repository containing the complete experimental code and verification scripts for the order-sensitivity tests. This will allow independent assessment directly from the paper. revision: yes
-
Referee: [PI-FT description] The assumption that random field-order sampling plus dropout during fine-tuning causes the model to bind semantics to field labels (rather than to absolute positions) is invoked to explain the results, but no ablation isolating the contribution of each component (order randomization alone vs. dropout alone vs. both) is reported, leaving the mechanism under-specified.
Authors: We acknowledge that the current manuscript reports only the combined PI-FT procedure and does not include separate ablations for order randomization versus dropout. While the joint application is the proposed method, an explicit ablation would better isolate the mechanism. We will add these experiments in the revision, training variants with order randomization alone, dropout alone, and both, and report their effects on the order-change penalty and in-distribution performance. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's contribution is an empirical training procedure (PI-FT via randomized serialization and dropout in the data loader) whose claims rest on direct nDCG@10 comparisons to fixed-order baselines and zero-shot models on the externally generated DevDataBench. No equations, derivations, or load-bearing premises reduce by construction to fitted parameters, self-definitions, or self-citation chains. The mechanism is justified by the observed order-sensitivity gap (7.4 vs 0.2 points) rather than by any internal identity or imported uniqueness result.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Transformer-based embedding models learn associations primarily from field labels and content when position is randomized during training.
- domain assumption LLM-generated queries in 15 languages provide a valid proxy for evaluating retrieval over development statistics indicators.
Reference graph
Works this paper leans on
-
[1]
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Ma- jumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, Mir Rosenberg, Xia Song, Alina Stoica, Saurabh Tiwary, and Tong Wang. MS MARCO: A human generated MAchine Reading COmpre- hension dataset.arXiv preprint arXiv:1611.09268,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Luiz Bonifacio, Vitor Jeronymo, Hugo Abonizio, Israel Campiotti, Marzieh Fadaee, Roberto Lotufo, and Rodrigo Nogueira. mMARCO: A multilingual version of the MS MARCO passage ranking dataset.arXiv preprint arXiv:2108.13897,
-
[3]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL),
2019
-
[4]
Guglielmo Faggioli, Laura Dietz, Charles L. A. Clarke, Gianluca Demartini, Matthias Hagen, Claudia Hauff, Noriko Kando, Evangelos Kanoulas, Martin Potthast, Benno Stein, and Henning Wachsmuth. Perspectives on large language models for relevance judgment. InProceedings of the 2023 ACM SIGIR International Conference on Theory of Information Retrieval (ICTIR),
2023
-
[5]
SimCSE: Simple contrastive learning of sentence embeddings
Tianyu Gao, Xingcheng Yao, and Danqi Chen. SimCSE: Simple contrastive learning of sentence embeddings. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP),
2021
-
[6]
Efficient Natural Language Response Suggestion for Smart Reply
19 Field Order Should Not Matter: Permutation-Invariant Embedding Model Fine-Tuning for Structured Metadata Retrieval Matthew Henderson, Rami Al-Rfou, Brian Strope, Yun-Hsuan Sung, L ´aszl´o Luk´acs, Ruiqi Guo, Sanjiv Kumar, Balint Miklos, and Ray Kurzweil. Efficient natural language response suggestion for smart reply.arXiv preprint arXiv:1705.00652,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas O˘guz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP),
2020
-
[8]
Towards General Text Embeddings with Multi-stage Contrastive Learning
Xinze Li, Zhenghao Liu, Chenyan Xiong, Shi Yu, Yu Gu, Zhiyuan Liu, and Ge Yu. Structure- aware language model pretraining improves dense retrieval on structured data. InFindings of the Association for Computational Linguistics: ACL 2023, 2023a. Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. Towards general text embedding...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Document expansion by query prediction.arXiv preprint arXiv:1904.08375,
Rodrigo Nogueira, Wei Yang, Jimmy Lin, and Kyunghyun Cho. Document expansion by query prediction.arXiv preprint arXiv:1904.08375,
-
[10]
The long tail of recommender systems and how to leverage it
Yoon-Joo Park and Alexander Tuzhilin. The long tail of recommender systems and how to leverage it. InProceedings of the 2008 ACM Conference on Recommender Systems (RecSys), pp. 11–18,
2008
-
[11]
RocketQA: An optimized training approach to dense passage retrieval for open-domain question answering
20 Field Order Should Not Matter: Permutation-Invariant Embedding Model Fine-Tuning for Structured Metadata Retrieval Yingqi Qu, Yuchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, Wayne Xin Zhao, Daxiang Dong, Hua Wu, and Haifeng Wang. RocketQA: An optimized training approach to dense passage retrieval for open-domain question answering. InProceedings of the 20...
2021
-
[12]
Sentence-BERT: Sentence embeddings using Siamese BERT- networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP-IJCNLP),
2019
-
[13]
GISTembed: Guided in-sample selection of train- ing negatives for text embedding fine-tuning,
Aivin V . Solatorio. GISTEmbed: Guided in-sample selection of training negatives for text embedding fine-tuning.arXiv preprint arXiv:2402.16829,
-
[14]
REaLTabFormer: Generating Realistic Relational and Tabular Data using Transformers,
Aivin V Solatorio and Olivier Dupriez. Realtabformer: Generating realistic relational and tabular data using transformers.arXiv preprint arXiv:2302.02041,
-
[15]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Kexin Wang, Nandan Thakur, Nils Reimers, and Iryna Gurevych. GPL: Generative pseudo labeling for unsupervised domain adaptation of dense retrieval. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2022a. Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
The World Bank, Washington, DC,
World Bank.World Development Report 2021: Data for Better Lives. The World Bank, Washington, DC,
2021
-
[17]
C-Pack: Packed Resources For General Chinese Embeddings
21 Field Order Should Not Matter: Permutation-Invariant Embedding Model Fine-Tuning for Structured Metadata Retrieval Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-pack: Packaged resources to advance general Chinese embedding.arXiv preprint arXiv:2309.07597,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Batch size (negative pool) 128 GradCache mini-batch 48 (halved on OOM) Hard negatives per query 3 Learning rate3×10 −5, 10% linear warmup Max sequence length 512 Field-dropout probability 0.15 (name and facet field protected) Precision bf16 Eval / checkpoint interval 1,500 steps Early-stopping metric loss on a held-back slice of training rows GIST guide (...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.