Deep Learning Alternatives of the Kolmogorov Superposition Theorem
Pith reviewed 2026-05-23 19:55 UTC · model grok-4.3
The pith
ActNet, built on alternative Kolmogorov Superposition Theorem forms, outperforms KANs and matches top MLPs in PINN-based PDE simulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
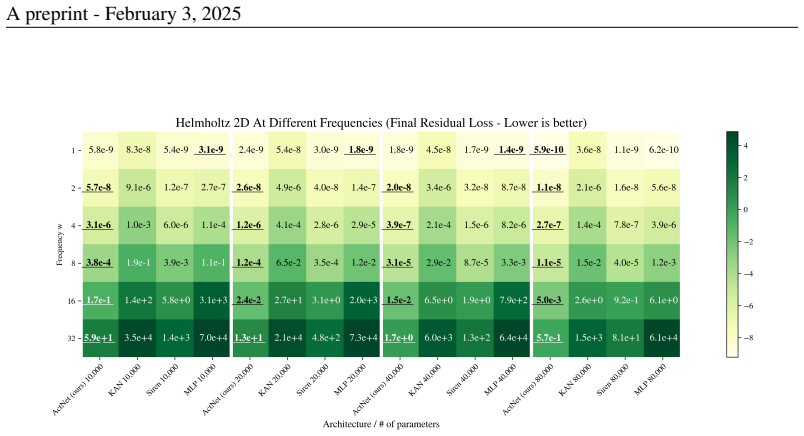
We introduce ActNet, a scalable deep learning model that builds on the KST and overcomes many of the drawbacks of Kolmogorov's original formulation. In the context of PINNs, ActNet consistently outperforms KANs across multiple benchmarks and is competitive against the current best MLP-based approaches.
What carries the argument
ActNet, a neural network architecture that implements alternative formulations of the Kolmogorov Superposition Theorem to enable function approximation without the original theorem's restrictions on inner and outer functions and variable counts.
If this is right
- ActNet enables effective low-dimensional function approximation in settings where only governing equations are available, without direct data measurements.
- The model offers a concrete route for KST-based designs in scientific computing and PDE simulation tasks.
- Performance results position ActNet as a viable alternative to both KANs and standard MLPs for physics-informed learning.
Where Pith is reading between the lines
- If the alternative KST formulations scale to higher input dimensions, ActNet could extend beyond PINNs into general regression or operator learning problems.
- The design choices in ActNet might be combined with other modern components such as attention layers to further improve training stability.
- Direct comparison of inner-function expressivity between ActNet and KANs on controlled synthetic tasks would clarify which KST variant drives the observed gains.
Load-bearing premise
Alternative formulations of the Kolmogorov Superposition Theorem can be realized in neural networks that preserve useful approximation properties while eliminating the original statement's practical drawbacks.
What would settle it
Run ActNet and KANs on an expanded suite of PDE benchmarks in the PINN setting; if ActNet no longer shows consistent gains over KANs or falls behind leading MLPs, the claimed advantage of the alternative KST forms would not hold.
Figures
















read the original abstract
This paper explores alternative formulations of the Kolmogorov Superposition Theorem (KST) as a foundation for neural network design. The original KST formulation, while mathematically elegant, presents practical challenges due to its limited insight into the structure of inner and outer functions and the large number of unknown variables it introduces. Kolmogorov-Arnold Networks (KANs) leverage KST for function approximation, but they have faced scrutiny due to mixed results compared to traditional multilayer perceptrons (MLPs) and practical limitations imposed by the original KST formulation. To address these issues, we introduce ActNet, a scalable deep learning model that builds on the KST and overcomes many of the drawbacks of Kolmogorov's original formulation. We evaluate ActNet in the context of Physics-Informed Neural Networks (PINNs), a framework well-suited for leveraging KST's strengths in low-dimensional function approximation, particularly for simulating partial differential equations (PDEs). In this challenging setting, where models must learn latent functions without direct measurements, ActNet consistently outperforms KANs across multiple benchmarks and is competitive against the current best MLP-based approaches. These results present ActNet as a promising new direction for KST-based deep learning applications, particularly in scientific computing and PDE simulation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ActNet, a neural network architecture derived from alternative formulations of the Kolmogorov Superposition Theorem (KST). It argues that these alternatives overcome the practical drawbacks of the original KST (limited insight into inner/outer functions and high number of unknowns) and of Kolmogorov-Arnold Networks (KANs), while preserving useful approximation properties. The central empirical claim is that, when used inside Physics-Informed Neural Networks (PINNs) for PDE simulation, ActNet consistently outperforms KANs across multiple benchmarks and remains competitive with the best MLP-based approaches.
Significance. If the reported performance gains are reproducible and the alternative KST formulations indeed retain the requisite approximation properties, the work would constitute a concrete step toward practical KST-based models in scientific machine learning. The choice of the PINN setting is well-motivated given KST’s theoretical strengths in low-dimensional function approximation.
major comments (2)
- [Abstract] Abstract: the claim that “ActNet consistently outperforms KANs across multiple benchmarks” is presented without any benchmark names, quantitative metrics, training procedures, or statistical details. Because the central contribution is empirical, this omission renders the data-to-claim link impossible to assess and is load-bearing for the paper’s main assertion.
- [Introduction / Model definition] The manuscript states that ActNet “builds on the KST and overcomes many of the drawbacks of Kolmogorov’s original formulation,” yet supplies no explicit description of the concrete functional forms chosen for the inner and outer functions, the number of free parameters they introduce, or a proof sketch that the approximation properties are retained. This gap directly affects the weakest assumption identified in the review.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to strengthen the presentation of our empirical results and the theoretical grounding of ActNet. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that “ActNet consistently outperforms KANs across multiple benchmarks” is presented without any benchmark names, quantitative metrics, training procedures, or statistical details. Because the central contribution is empirical, this omission renders the data-to-claim link impossible to assess and is load-bearing for the paper’s main assertion.
Authors: We agree that the abstract should provide more concrete information to support the central empirical claim. In the revised manuscript we will expand the abstract to name the specific PINN benchmarks (Burgers’ equation, Navier-Stokes, wave equation, and Allen-Cahn), report key quantitative metrics (average relative L2 errors across 5 random seeds), and briefly note the training protocol (Adam optimizer, 10k–50k iterations, same hyper-parameter search as the KAN and MLP baselines). These additions will make the data-to-claim link explicit while remaining within the abstract length limit. revision: yes
-
Referee: [Introduction / Model definition] The manuscript states that ActNet “builds on the KST and overcomes many of the drawbacks of Kolmogorov’s original formulation,” yet supplies no explicit description of the concrete functional forms chosen for the inner and outer functions, the number of free parameters they introduce, or a proof sketch that the approximation properties are retained. This gap directly affects the weakest assumption identified in the review.
Authors: The current manuscript introduces the ActNet architecture in Section 2 but does not provide an explicit functional-form description or parameter count. We will add a new subsection (2.2) that (i) states the chosen inner functions (univariate B-spline activations with fixed knot spacing) and outer functions (linear combinations with learned coefficients), (ii) gives the resulting parameter scaling (O(d·k) per layer versus O(d·N) for the classical KST), and (iii) includes a short proof sketch showing that the alternative KST formulation of [reference] preserves the universal approximation property for continuous functions on compact domains. This revision directly addresses the concern. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces ActNet as an alternative KST-based architecture and supports its claims through empirical benchmarks on PINN PDE tasks, where ActNet outperforms KANs and competes with MLPs. No derivation chain, fitted parameter, or self-citation is shown to reduce the central result to its own inputs by construction; performance metrics are measured against external baselines rather than being tautological. The model formulation is presented as a new design choice retaining approximation properties, with evaluation independent of any internal redefinition.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniquely forced) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ActNet ... builds on the KST and overcomes many of the drawbacks of Kolmogorov’s original formulation ... ActLayer ... sinusoidal basis ... universality with fixed depth/width
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 3.1 (Laczkovich 2021) ... m > (2+√2)(2d−1) ... g(λi · ϕi(x))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Error whitening: Why Gauss-Newton outperforms Newton
Gauss-Newton descent whitens errors by projecting Newton directions or gradients onto the tangent space, replacing JJ^T with the identity and removing parameterization distortions that affect Newton descent.
-
Hyperfastrl: Hypernetwork-based reinforcement learning for unified control of parametric chaotic PDEs
Hypernetworks map a forcing parameter directly to policy weights in an RL framework, enabling unified stabilization of the Kuramoto-Sivashinsky equation across regimes with KAN architectures showing strongest extrapolation.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Rafal Jozefowicz, Yangqing Jia, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mané, Mike Schuster, Rajat Monga, Sherry Moore, De...
work page 2015
-
[3]
Jason Ansel, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael Voznesensky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, Geeta Chauhan, Anjali Chourdia, Will Constable, Alban Desmaison, Zachary DeVito, Elias Ellison, Will Feng, Jiong Gong, Michael Gschwind, Brian Hirsh, Sherlock Huang, Kshiteej Kalambarkar, Laurent Kirsch, Michael L...
-
[4]
JAX : composable transformations of P ython+ N um P y programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake Vander P las, Skye Wanderman- M ilne, and Qiao Zhang. JAX : composable transformations of P ython+ N um P y programs, 2018. URL http://github.com/google/jax
work page 2018
-
[5]
Andrew Brock, Soham De, Samuel L. Smith, and Karen Simonyan. High-performance large-scale image recognition without normalization. CoRR, abs/2102.06171, 2021. URL https://arxiv.org/abs/2102.06171
-
[6]
Approximation by superpositions of a sigmoidal function
George Cybenko. Approximation by superpositions of a sigmoidal function. Mathematics of control, signals and systems, 2 0 (4): 0 303--314, 1989
work page 1989
-
[7]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness, 2022. URL https://arxiv.org/abs/2205.14135
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Rethinking the importance of sampling in physics-informed neural networks
Arka Daw, Jie Bu, Sifan Wang, Paris Perdikaris, and Anuj Karpatne. Rethinking the importance of sampling in physics-informed neural networks. arXiv preprint arXiv:2207.02338, 2022
-
[9]
Charles R. Harris, K. Jarrod Millman, St \' e fan J. van der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J. Smith, Robert Kern, Matti Picus, Stephan Hoyer, Marten H. van Kerkwijk, Matthew Brett, Allan Haldane, Jaime Fern \' a ndez del R \' i o, Mark Wiebe, Pearu Peterson, Pierre G \' e rard-M...
-
[10]
Kolmogorov’s mapping neural network existence theorem
Robert Hecht-Nielsen. Kolmogorov’s mapping neural network existence theorem. In Proceedings of the international conference on Neural Networks, volume 3, pp.\ 11--14. IEEE press New York, NY, USA, 1987
work page 1987
-
[11]
F lax: A neural network library and ecosystem for JAX , 2023
Jonathan Heek, Anselm Levskaya, Avital Oliver, Marvin Ritter, Bertrand Rondepierre, Andreas Steiner, and Marc van Z ee. F lax: A neural network library and ecosystem for JAX , 2023. URL http://github.com/google/flax
work page 2023
-
[12]
David Hilbert. Mathematical problems. Bulletin of the American Mathematical Society, 37 0 (4): 0 407--436, 2000
work page 2000
-
[13]
Amanda A. Howard, Bruno Jacob, Sarah H. Murphy, Alexander Heinlein, and Panos Stinis. Finite basis kolmogorov-arnold networks: domain decomposition for data-driven and physics-informed problems, 2024. URL https://arxiv.org/abs/2406.19662
-
[14]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
J. D. Hunter. Matplotlib: A 2d graphics environment. Computing in Science & Engineering, 9 0 (3): 0 90--95, 2007. doi:10.1109/MCSE.2007.55
-
[16]
Physics-informed machine learning
George Em Karniadakis, Ioannis G Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics-informed machine learning. Nature Reviews Physics, 3 0 (6): 0 422--440, 2021
work page 2021
-
[17]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2017
work page 2017
-
[18]
Koenig, Suyong Kim, and Sili Deng
Benjamin C. Koenig, Suyong Kim, and Sili Deng. Kan-odes: Kolmogorov–arnold network ordinary differential equations for learning dynamical systems and hidden physics. Computer Methods in Applied Mechanics and Engineering, 432: 0 117397, December 2024. ISSN 0045-7825. doi:10.1016/j.cma.2024.117397. URL http://dx.doi.org/10.1016/j.cma.2024.117397
-
[19]
Andrei Nikolaevich Kolmogorov. On the representation of continuous functions of several variables by superpositions of continuous functions of a smaller number of variables. American Mathematical Society, 1961
work page 1961
-
[20]
On the training of a kolmogorov network
Mario K \"o ppen. On the training of a kolmogorov network. In Jos \'e R. Dorronsoro (ed.), Artificial Neural Networks --- ICANN 2002, pp.\ 474--479, Berlin, Heidelberg, 2002. Springer Berlin Heidelberg. ISBN 978-3-540-46084-8
work page 2002
-
[21]
Characterizing possible failure modes in physics-informed neural networks
Aditi Krishnapriyan, Amir Gholami, Shandian Zhe, Robert Kirby, and Michael W Mahoney. Characterizing possible failure modes in physics-informed neural networks. Advances in neural information processing systems, 34: 0 26548--26560, 2021
work page 2021
-
[22]
Kolmogorov's theorem and multilayer neural networks
V e ra K u rkov\'a. Kolmogorov's theorem and multilayer neural networks. Neural networks, 5 0 (3): 0 501--506, 1992
work page 1992
-
[23]
A superposition theorem of kolmogorov type for bounded continuous functions
Miklós Laczkovich. A superposition theorem of kolmogorov type for bounded continuous functions. Journal of Approximation Theory, 269: 0 105609, 2021. ISSN 0021-9045. doi:https://doi.org/10.1016/j.jat.2021.105609. URL https://www.sciencedirect.com/science/article/pii/S0021904521000721
-
[24]
On the Realization of a Kolmogorov Network
Ji-Nan Lin and Rolf Unbehauen. On the Realization of a Kolmogorov Network . Neural Computation, 5 0 (1): 0 18--20, 01 1993. ISSN 0899-7667. doi:10.1162/neco.1993.5.1.18. URL https://doi.org/10.1162/neco.1993.5.1.18
-
[25]
On the limited memory bfgs method for large scale optimization
Dong C Liu and Jorge Nocedal. On the limited memory bfgs method for large scale optimization. Mathematical programming, 45 0 (1): 0 503--528, 1989
work page 1989
-
[26]
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljačić, Thomas Y. Hou, and Max Tegmark. Kan: Kolmogorov-arnold networks, 2024
work page 2024
-
[27]
Subhajit Patra, Sonali Panda, Bikram Keshari Parida, Mahima Arya, Kurt Jacobs, Denys I. Bondar, and Abhijit Sen. Physics informed kolmogorov-arnold neural networks for dynamical analysis via efficent-kan and wav-kan, 2024. URL https://arxiv.org/abs/2407.18373
-
[28]
M. Raissi, P. Perdikaris, and G.E. Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics, 378: 0 686--707, 2019. ISSN 0021-9991. doi:https://doi.org/10.1016/j.jcp.2018.10.045. URL https://www.sciencedirect.com/sc...
-
[29]
Adaptive training of grid-dependent physics-informed kolmogorov-arnold networks, 2024
Spyros Rigas, Michalis Papachristou, Theofilos Papadopoulos, Fotios Anagnostopoulos, and Georgios Alexandridis. Adaptive training of grid-dependent physics-informed kolmogorov-arnold networks, 2024. URL https://arxiv.org/abs/2407.17611
-
[30]
Physics-informed kolmogorov-arnold networks for power system dynamics, 2024
Hang Shuai and Fangxing Li. Physics-informed kolmogorov-arnold networks for power system dynamics, 2024. URL https://arxiv.org/abs/2408.06650
-
[31]
Khemraj Shukla, Juan Diego Toscano, Zhicheng Wang, Zongren Zou, and George Em Karniadakis. A comprehensive and fair comparison between mlp and kan representations for differential equations and operator networks. Computer Methods in Applied Mechanics and Engineering, 431: 0 117290, 2024. ISSN 0045-7825. doi:https://doi.org/10.1016/j.cma.2024.117290. URL h...
- [32]
-
[33]
Kolmogorov superpositions: A new computational algorithm
David Sprecher. Kolmogorov superpositions: A new computational algorithm. In Efficiency and scalability methods for computational intellect, pp.\ 219--245. IGI Global, 2013
work page 2013
-
[34]
A numerical implementation of kolmogorov's superpositions
David A Sprecher. A numerical implementation of kolmogorov's superpositions. Neural networks, 9 0 (5): 0 765--772, 1996
work page 1996
-
[35]
From Algebra to Computational Algorithms: Kolmogorov and Hilbert's Problem 13
David A Sprecher. From Algebra to Computational Algorithms: Kolmogorov and Hilbert's Problem 13. Docent Press, 2017
work page 2017
-
[36]
N. Sukumar and Ankit Srivastava. Exact imposition of boundary conditions with distance functions in physics-informed deep neural networks. Computer Methods in Applied Mechanics and Engineering, 389: 0 114333, February 2022. ISSN 0045-7825. doi:10.1016/j.cma.2021.114333. URL http://dx.doi.org/10.1016/j.cma.2021.114333
-
[37]
Matthew Tancik, Pratul P. Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T. Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains. NeurIPS, 2020
work page 2020
-
[38]
A Vaswani. Attention is all you need. Advances in Neural Information Processing Systems, 2017
work page 2017
-
[39]
Anatoliy Georgievich Vitushkin. A proof of the existence of analytic functions of several variables not representable by linear superpositions of continuously differentiable functions of fewer variables. In Dokl. Akad. Nauk SSSR, volume 156-1258-1261, pp.\ 3, 1964
work page 1964
-
[40]
When and why pinns fail to train: A neural tangent kernel perspective
Sifan Wang, Xinling Yu, and Paris Perdikaris. When and why pinns fail to train: A neural tangent kernel perspective. Journal of Computational Physics, 449: 0 110768, 2022. ISSN 0021-9991. doi:https://doi.org/10.1016/j.jcp.2021.110768. URL https://www.sciencedirect.com/science/article/pii/S002199912100663X
-
[41]
An expert's guide to training physics-informed neural networks
Sifan Wang, Shyam Sankaran, Hanwen Wang, and Paris Perdikaris. An expert's guide to training physics-informed neural networks. arXiv preprint arXiv:2308.08468, 2023
-
[42]
Piratenets: Physics-informed deep learning with residual adaptive networks
Sifan Wang, Bowen Li, Yuhan Chen, and Paris Perdikaris. Piratenets: Physics-informed deep learning with residual adaptive networks. arXiv preprint arXiv:2402.00326, 2024 a
-
[43]
Respecting causality for training physics-informed neural networks
Sifan Wang, Shyam Sankaran, and Paris Perdikaris. Respecting causality for training physics-informed neural networks. Computer Methods in Applied Mechanics and Engineering, 421: 0 116813, 2024 b
work page 2024
-
[44]
Yizheng Wang, Jia Sun, Jinshuai Bai, Cosmin Anitescu, Mohammad Sadegh Eshaghi, Xiaoying Zhuang, Timon Rabczuk, and Yinghua Liu. Kolmogorov arnold informed neural network: A physics-informed deep learning framework for solving forward and inverse problems based on kolmogorov arnold networks, 2024 c . URL https://arxiv.org/abs/2406.11045
-
[45]
Kan or mlp: A fairer comparison, 2024
Runpeng Yu, Weihao Yu, and Xinchao Wang. Kan or mlp: A fairer comparison, 2024. URL https://arxiv.org/abs/2407.16674
-
[46]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[47]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[48]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.