Block-wise Adaptive Caching for Accelerating Diffusion Policy
Pith reviewed 2026-05-19 09:32 UTC · model grok-4.3
The pith
Block-wise adaptive caching speeds up diffusion policy inference up to 3x by reusing similar features across denoising steps without any retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
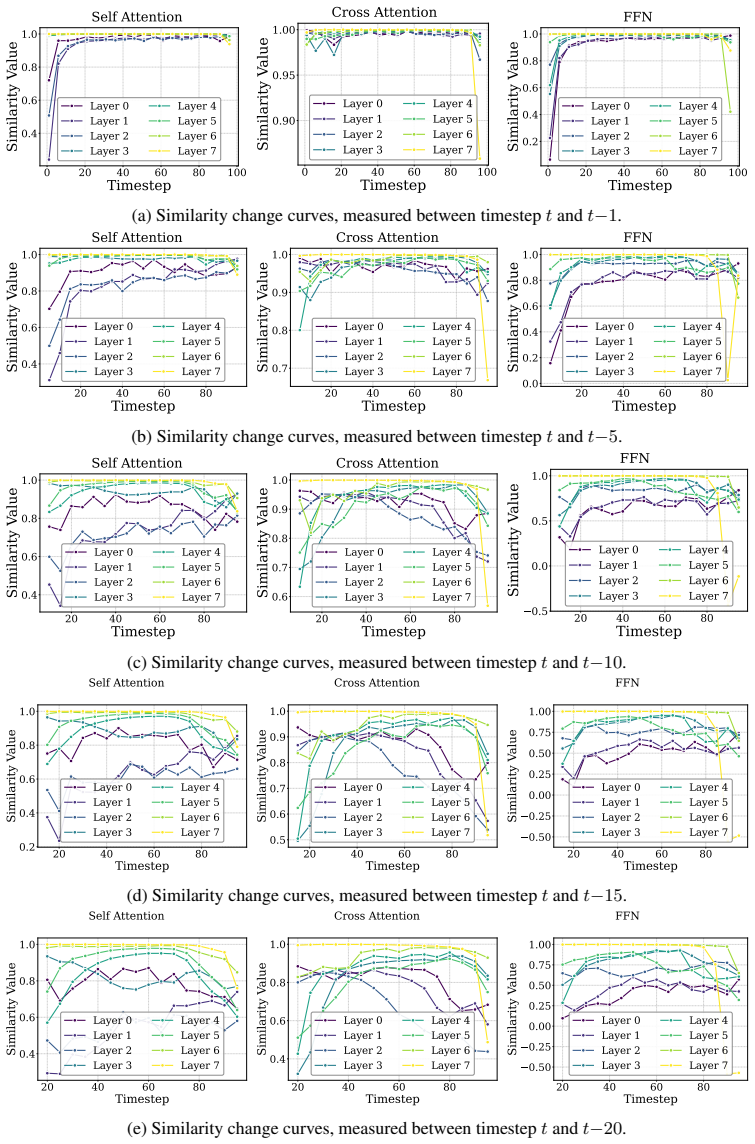
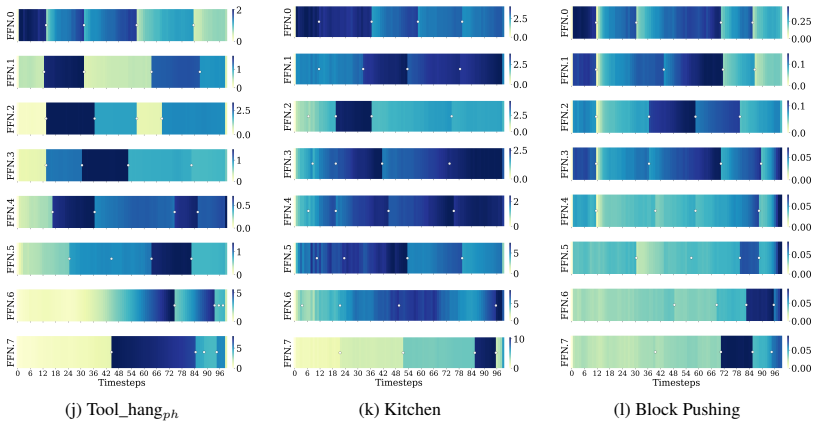
BAC achieves lossless action generation acceleration by adaptively updating and reusing cached features at the block level. Feature similarities exhibit non-uniform temporal dynamics and distinct block-specific patterns. An Adaptive Caching Scheduler selects optimal update timesteps by maximizing global feature similarities, while the Bubbling Union Algorithm truncates inter-block error propagation by updating upstream blocks before downstream FFN blocks. The entire procedure is training-free and plugs directly into existing transformer-based Diffusion Policy and vision-language-action models.
What carries the argument
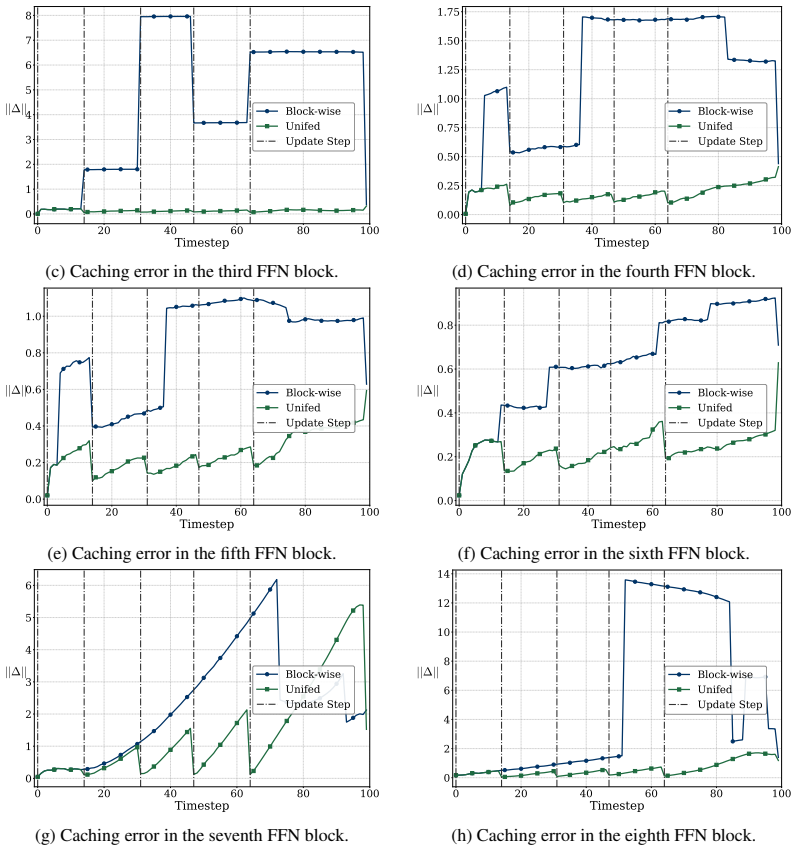
The Bubbling Union Algorithm, which identifies blocks carrying large caching errors and forces their update before errors reach downstream feed-forward networks, thereby containing propagation across the transformer stack.
If this is right
- Up to 3x inference speedup is observed on multiple robotic benchmarks while action quality remains unchanged.
- The method integrates as a drop-in plugin with existing transformer-based Diffusion Policy and vision-language-action models.
- No model retraining or architecture modification is required.
- Error control is achieved specifically by refreshing upstream blocks before downstream FFNs receive their input.
Where Pith is reading between the lines
- The same block-level similarity pattern could be tested in other diffusion-based sequence models to see whether the scheduler and union algorithm transfer without modification.
- Combining BAC with existing quantization or pruning steps might compound the speed gains on edge hardware for robots.
- The non-uniform dynamics observation suggests that future schedulers could learn update rules directly from feature statistics collected during a short calibration run.
Load-bearing premise
Feature similarities across denoising steps and across blocks are stable enough that a scheduler can pick update points without letting small local mismatches grow into unacceptable errors in the final actions.
What would settle it
Measure the success rate or mean action error of a diffusion policy on a standard robotic benchmark both with and without BAC; a statistically significant drop in performance when BAC is active would refute the lossless claim.
Figures







read the original abstract
Diffusion Policy has demonstrated strong visuomotor modeling capabilities, but its high computational cost renders it impractical for real-time robotic control. Despite huge redundancy across repetitive denoising steps, existing diffusion acceleration techniques fail to generalize to Diffusion Policy due to fundamental architectural and data divergences. In this paper, we propose $\textbf{B}$lock-wise $\textbf{A}$daptive $\textbf{C}$aching ($\textbf{BAC}$), a method to accelerate Diffusion Policy by caching intermediate action features. BAC achieves lossless action generation acceleration by adaptively updating and reusing cached features at the block level, based on a key observation that feature similarities exhibit non-uniform temporal dynamics and distinct block-specific patterns. To operationalize this insight, we first design an Adaptive Caching Scheduler to identify optimal update timesteps by maximizing the global feature similarities between cached and skipped features. However, applying this scheduler for each block leads to significant error surges due to the inter-block propagation of caching errors, particularly within Feed-Forward Network (FFN) blocks. To mitigate this issue, we develop the Bubbling Union Algorithm, which truncates these errors by updating the upstream blocks with significant caching errors before downstream FFNs. As a training-free plugin, BAC is readily integrable with existing transformer-based Diffusion Policy and vision-language-action models. Extensive experiments on multiple robotic benchmarks demonstrate that BAC achieves up to 3$\times$ inference speedup for free. Project page: https://block-wise-adaptive-caching.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Block-wise Adaptive Caching (BAC) as a training-free plugin to accelerate inference in transformer-based Diffusion Policy and vision-language-action models. It observes non-uniform temporal dynamics and block-specific patterns in feature similarities, then introduces an Adaptive Caching Scheduler that selects update timesteps by maximizing global feature similarity between cached and current features, combined with a Bubbling Union Algorithm that forces upstream block updates to truncate error propagation into downstream FFN layers. Experiments on robotic benchmarks are reported to deliver up to 3× speedup while preserving identical action outputs.
Significance. If the lossless guarantee and reported speedups hold under rigorous error metrics, the work would be significant for real-time robotic control, directly addressing the inference latency barrier that currently limits deployment of diffusion policies. The training-free, plug-in nature and explicit handling of inter-block error via the Bubbling Union Algorithm are practical strengths that could generalize beyond the evaluated models.
major comments (3)
- [§3.2] §3.2 (Adaptive Caching Scheduler): Maximizing cosine or L2 feature similarity is used as the decision criterion, yet the manuscript provides no analysis showing that this proxy is sufficient to guarantee identical outputs after subsequent non-linear attention and FFN transformations with residual connections; a single early-step discrepancy could compound across the denoising trajectory.
- [§4] §4 (Bubbling Union Algorithm): The claim that the algorithm 'fully truncates' inter-block error propagation, especially into FFNs, is asserted without a quantitative bound or ablation that isolates the residual action-level error when the algorithm is disabled; the central lossless claim therefore rests on an unverified truncation property.
- [§5] §5 (Experiments): While speedups are reported, the tables do not include per-task success-rate deltas, mean trajectory error, or failure-case analysis between full denoising and BAC; without these, it is impossible to verify that the observed feature-similarity thresholds truly produce functionally equivalent actions.
minor comments (2)
- [§3.1] The notation for cached feature tensors (e.g., F_b^t) is introduced without an explicit dimension table, making it difficult to follow the block-wise reuse logic in the scheduler pseudocode.
- [Figure 3] Figure 3 caption does not state the exact similarity metric (cosine vs. L2) or the threshold values used for the reported runs, reducing reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify the presentation of our lossless acceleration claims. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Adaptive Caching Scheduler): Maximizing cosine or L2 feature similarity is used as the decision criterion, yet the manuscript provides no analysis showing that this proxy is sufficient to guarantee identical outputs after subsequent non-linear attention and FFN transformations with residual connections; a single early-step discrepancy could compound across the denoising trajectory.
Authors: We agree that feature similarity is a proxy rather than a direct guarantee of output equivalence after non-linear layers and residual connections. In the revised manuscript we will add a short analysis subsection in §3.2 that (i) notes the deterministic nature of the transformer blocks and (ii) shows that, when the scheduler enforces a sufficiently high similarity threshold, the input features to each block remain identical (within floating-point tolerance) to the cached features, thereby producing identical downstream outputs. We will also report direct numerical comparisons of final action vectors to confirm zero observable difference. revision: yes
-
Referee: [§4] §4 (Bubbling Union Algorithm): The claim that the algorithm 'fully truncates' inter-block error propagation, especially into FFNs, is asserted without a quantitative bound or ablation that isolates the residual action-level error when the algorithm is disabled; the central lossless claim therefore rests on an unverified truncation property.
Authors: We acknowledge that the current text asserts truncation without an isolated ablation or quantitative bound. In the revision we will (i) add an ablation that disables the Bubbling Union Algorithm while keeping the scheduler active and reports the resulting increase in action-level L2 error and success-rate drop, and (ii) include a brief derivation showing that forcing upstream updates before each FFN layer bounds the propagated error by the maximum per-block caching discrepancy. If a tighter analytic bound proves intractable, we will state this limitation explicitly. revision: partial
-
Referee: [§5] §5 (Experiments): While speedups are reported, the tables do not include per-task success-rate deltas, mean trajectory error, or failure-case analysis between full denoising and BAC; without these, it is impossible to verify that the observed feature-similarity thresholds truly produce functionally equivalent actions.
Authors: We agree that the current experimental tables focus primarily on speedup and do not sufficiently document functional equivalence. We will expand §5 with (i) per-task success-rate tables comparing the original Diffusion Policy and BAC, (ii) mean trajectory error (L2 action deviation) across all evaluation episodes, and (iii) a short failure-case analysis for any tasks where minor discrepancies appear. These additions will directly address the referee’s concern about verifying lossless behavior under the chosen similarity thresholds. revision: yes
Circularity Check
No significant circularity: heuristic design and experimental validation remain independent of fitted inputs or self-referential definitions.
full rationale
The paper derives BAC from an empirical observation of non-uniform feature similarities across blocks and timesteps, then defines an Adaptive Caching Scheduler that selects update steps by maximizing measured similarities and a Bubbling Union Algorithm that enforces upstream updates to truncate propagation. Neither component reduces to a fitted performance metric by construction, nor does the lossless claim rely on a self-citation chain or ansatz imported from prior author work. The speedup results are presented as outcomes of applying these rules to transformer-based diffusion policies, with no equations showing that a predicted quantity is statistically forced to equal its own input. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Feature similarities exhibit non-uniform temporal dynamics and distinct block-specific patterns that can be used to select safe caching timesteps.
Forward citations
Cited by 4 Pith papers
-
Test-time Sparsity for Extreme Fast Action Diffusion
Test-time sparsity with a parallel pipeline and omnidirectional feature reuse accelerates action diffusion by 5x to 47.5 Hz while cutting FLOPs 92% with no performance loss.
-
Characterizing Vision-Language-Action Models across XPUs: Constraints and Acceleration for On-Robot Deployment
VLA models exhibit a compute-bound VLM phase followed by a memory-bound action phase on edge hardware; DP-Cache and V-AEFusion reduce redundancy and enable pipeline parallelism for up to 6x speedup on NPUs with margin...
-
Sparse ActionGen: Accelerating Diffusion Policy with Real-time Pruning
Sparse ActionGen accelerates diffusion policies up to 4x for robot control via rollout-adaptive pruning and zig-zag activation reuse without performance loss.
-
Large VLM-based Vision-Language-Action Models for Robotic Manipulation: A Survey
This survey organizes large VLM-based VLA models for robotic manipulation into monolithic and hierarchical paradigms, reviews their integrations and datasets, and outlines future directions.
Reference graph
Works this paper leans on
-
[1]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, page 02783649241273668, 2023
work page 2023
-
[2]
DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control
Junjie Wen, Yichen Zhu, Jinming Li, Zhibin Tang, Chaomin Shen, and Feifei Feng. Dexvla: Vision- language model with plug-in diffusion expert for general robot control. arXiv preprint arXiv:2502.05855 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Submitted to Some Conference, unpublished
-
[4]
HybridVLA: Collaborative Diffusion and Autoregression in a Unified Vision-Language-Action Model
Jiaming Liu, Hao Chen, Pengju An, Zhuoyang Liu, Renrui Zhang, Chenyang Gu, Xiaoqi Li, Ziyu Guo, Sixiang Chen, Mengzhen Liu, et al. Hybridvla: Collaborative diffusion and autoregression in a unified vision- language-action model. arXiv preprint arXiv:2503.10631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Dita: Scaling diffusion transformer for generalist vision-language-action policy
Zhi Hou, Tianyi Zhang, Yuwen Xiong, Haonan Duan, Hengjun Pu, Ronglei Tong, Chengyang Zhao, Xizhou Zhu, Yu Qiao, Jifeng Dai, et al. Dita: Scaling diffusion transformer for generalist vision-language- action policy. arXiv preprint arXiv:2503.19757, 2025
-
[6]
Parallel sampling of diffu- sion models
Andy Shih, Suneel Belkhale, Stefano Ermon, Dorsa Sadigh, and Nima Anari. Parallel sampling of diffu- sion models. Advances in Neural Information Processing Systems, 36:4263–4276, 2023
work page 2023
-
[7]
Deepcache: Accelerating diffusion models for free
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Deepcache: Accelerating diffusion models for free. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 15762–15772. Placeholder Publisher, 2024
work page 2024
-
[8]
Cache me if you can: Accelerating diffusion models through block caching
Felix Wimbauer, Bichen Wu, Edgar Schoenfeld, Xiaoliang Dai, Ji Hou, Zijian He, Artsiom Sanakoyeu, Peizhao Zhang, Sam Tsai, Jonas Kohler, et al. Cache me if you can: Accelerating diffusion models through block caching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 6211–6220, 2024
work page 2024
-
[9]
Fora: Fast-forward caching in diffusion transformer acceleration.arXiv preprint arXiv:2407.01425,
Pratheba Selvaraju, Tianyu Ding, Tianyi Chen, Ilya Zharkov, and Luming Liang. Fora: Fast-forward caching in diffusion transformer acceleration. arXiv preprint arXiv:2407.01425, 2024
-
[10]
δ-DiT: A training-free acceleration method tailored for diffusion transformers, 2024
Pengtao Chen, Mingzhu Shen, Peng Ye, Jianjian Cao, Chongjun Tu, Christos-Savvas Bouganis, Yiren Zhao, and Tao Chen. δ-dit: A training-free acceleration method tailored for diffusion transformers. arXiv preprint arXiv:2406.01125, 2024
-
[11]
Accelerating diffusion transform- ers with token-wise feature caching
Chang Zou, Xuyang Liu, Ting Liu, Siteng Huang, and Linfeng Zhang. Accelerating diffusion transform- ers with token-wise feature caching. In International Conference on Learning Representations (Poster Track),
-
[12]
URL https://openreview.net/forum?id=yYZbZGo4ei
-
[13]
Timestep embedding tells: It’s time to cache for video diffusion model, 2024
Feng Liu, Shiwei Zhang, Xiaofeng Wang, Yujie Wei, Haonan Qiu, Yuzhong Zhao, Yingya Zhang, Qixiang Ye, and Fang Wan. Timestep embedding tells: It’s time to cache for video diffusion model. arXiv preprint arXiv:2411.19108, 2024
-
[14]
Kumara Kahatapitiya, Haozhe Liu, Sen He, Ding Liu, Menglin Jia, Chenyang Zhang, Michael S Ryoo, and Tian Xie. Adaptive caching for faster video generation with diffusion transformers. arXiv preprint arXiv:2411.02397, 2024
-
[15]
Fastercache: Training-free video diffusion model acceleration with high quality
Zhengyao Lv, Chenyang Si, Junhao Song, Zhenyu Yang, Yu Qiao, Ziwei Liu, and Kwan-Yee K Wong. Fastercache: Training-free video diffusion model acceleration with high quality. arXiv preprint arXiv:2410.19355, 2024
-
[16]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. In Forty-first international conference on machine learning, 2024. Submitted to Some Con- ference, unpublished
work page 2024
-
[17]
Lumiere: a space-time diffusion model for video generation
Omer Bar-Tal, Hila Chefer, and ... Lumiere: a space-time diffusion model for video generation. In SIGGRAPH Asia 2024 Conference Papers, pages 1–11. Placeholder Publisher, 2024
work page 2024
-
[18]
Deep unsupervised learn- ing using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learn- ing using nonequilibrium thermodynamics. In International conference on machine learning , pages 2256–
-
[19]
pmlr, Placeholder Publisher, 2015
work page 2015
-
[20]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020. 10
work page 2020
-
[21]
Active policy learning for robot planning and exploration under uncertainty
Ruben Martinez-Cantin, Nando de Freitas, Arnaud Doucet, and José A Castellanos. Active policy learning for robot planning and exploration under uncertainty. In Robotics: Science and systems, volume 3, pages 321–
-
[22]
Placeholder Publisher, 2007
work page 2007
-
[23]
A Survey on Vision-Language-Action Models for Embodied AI
Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, and Irwin King. A survey on vision-language- action models for embodied ai. arXiv preprint arXiv:2405.14093 , 2024. Submitted to Some Conference, unpublished
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. arXiv preprint arXiv:2307.15818, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18 , pages 234–241, 2015
work page 2015
-
[27]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023. Submitted to Some Confer- ence, unpublished
work page 2023
-
[28]
Ditfastattn: Attention compression for diffusion transformer models
Zhihang Yuan, Hanling Zhang, Lu Pu, Xuefei Ning, Linfeng Zhang, Tianchen Zhao, Shengen Yan, Guo- hao Dai, and Yu Wang. Ditfastattn: Attention compression for diffusion transformer models. Advances in Neural Information Processing Systems, 37:1196–1219, 2024. Submitted to Some Conference, unpublished
work page 2024
-
[29]
Wangbo Zhao, Yizeng Han, Jiasheng Tang, Kai Wang, Yibing Song, Gao Huang, Fan Wang, and Yang You. Dynamic diffusion transformer. arXiv preprint arXiv:2410.03456, 2024. Submitted to Some Conference, unpublished
-
[30]
Diffusion transformer policy.arXiv preprint arXiv:2410.15959,
Zhi Hou, Tianyi Zhang, Yuwen Xiong, Hengjun Pu, Chengyang Zhao, Ronglei Tong, Yu Qiao, Jifeng Dai, and Yuntao Chen. Diffusion transformer policy. arXiv preprint arXiv:2410.15959, 2024
-
[31]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017
work page 2017
-
[32]
Junjie Wen, Minjie Zhu, Yichen Zhu, Zhibin Tang, Jinming Li, Zhongyi Zhou, Chengmeng Li, Xiaoyu Liu, Yaxin Peng, Chaomin Shen, et al. Diffusion-vla: Scaling robot foundation models via unified diffusion and autoregression. arXiv preprint arXiv:2412.03293, 2024. Submitted to Some Conference, unpublished
-
[33]
arXiv preprint arXiv:2502.02175 (2025)
Siyu Xu, Yunke Wang, Chenghao Xia, Dihao Zhu, Tao Huang, and Chang Xu. Vla-cache: Towards efficient vision-language-action model via adaptive token caching in robotic manipulation. arXiv preprint arXiv:2502.02175, 2025. Submitted to Some Conference, unpublished
-
[34]
Wenxuan Song, Jiayi Chen, Pengxiang Ding, Han Zhao, Wei Zhao, Zhide Zhong, Zongyuan Ge, Jun Ma, and Haoang Li. Accelerating vision-language-action model integrated with action chunking via parallel decoding. arXiv preprint arXiv:2503.02310, 2025. Submitted to Some Conference, unpublished
-
[35]
Mobility vla: Multimodal instruction navigation with long-context vlms and topological graphs
Hao-Tien Lewis Chiang, Zhuo Xu, Zipeng Fu, Mithun George Jacob, Tingnan Zhang, Tsang-Wei Edward Lee, Wenhao Yu, Connor Schenck, David Rendleman, Dhruv Shah, et al. Mobility vla: Multimodal instruction navigation with long-context vlms and topological graphs. arXiv preprint arXiv:2407.07775, 2024. Submitted to Some Conference, unpublished
-
[36]
Vla model-expert collaboration for bi-directional manipulation learning
Tian-Yu Xiang, Ao-Qun Jin, Xiao-Hu Zhou, Mei-Jiang Gui, Xiao-Liang Xie, Shi-Qi Liu, Shuang-Yi Wang, Sheng-Bin Duang, Si-Cheng Wang, Zheng Lei, et al. Vla model-expert collaboration for bi-directional manipulation learning. arXiv preprint arXiv:2503.04163, 2025
-
[37]
Chengmeng Li, Junjie Wen, Yan Peng, Yaxin Peng, Feifei Feng, and Yichen Zhu. Pointvla: Injecting the 3d world into vision-language-action models. arXiv preprint arXiv:2503.07511, 2025
-
[38]
Learning-to-cache: Accelerating diffusion transformer via layer caching
Xinyin Ma, Gongfan Fang, Michael Bi Mi, and Xinchao Wang. Learning-to-cache: Accelerating diffusion transformer via layer caching. Advances in Neural Information Processing Systems, 37:133282–133304, 2024. 11
work page 2024
-
[39]
Pete Florence, Corey Lynch, Andy Zeng, Oscar A Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, and Jonathan Tompson. Implicit behavioral cloning. In Conference on robot learning, pages 158–168. PMLR, 2022
work page 2022
-
[40]
Behavior transform- ers: Cloning k modes with one stone
Nur Muhammad Shafiullah, Zichen Cui, Ariuntuya Arty Altanzaya, and Lerrel Pinto. Behavior transform- ers: Cloning k modes with one stone. Advances in neural information processing systems , 35:22955–22968, 2022
work page 2022
-
[41]
Relay policy learning: Solving long-horizon tasks via imitation and reinforcement learning
Abhishek Gupta, Vikash Kumar, Corey Lynch, Sergey Levine, and Karol Hausman. Relay policy learning: Solving long-horizon tasks via imitation and reinforcement learning. arXiv preprint arXiv:1910.11956, 2019
-
[42]
What matters in learning from offline human demonstrations for robot manipulation
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei- Fei, Silvio Savarese, Yuke Zhu, and Roberto Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation. In Proceedings of the Conference on Robot Learning (CoRL), 2021. 12 A Appendix / supplemental material In this supplement...
work page 2021
-
[43]
Activation function ϕ is twice continuously differentiable with bounded second derivative
-
[44]
LayerNorm variance σ(X) ≥ σmin > 0 for all valid inputs X
-
[45]
robin, American robin, Turdus migratorius
Weight matrices satisfy ∥W1∥2 ≤ C1, ∥W2∥2 ≤ C2 for fixed constants C1, C2 Proposition A.1. Under Assumption 1, for input error δ with ∥δ∥ ≤ ϵ, the FFN block output error admits the first-order approximation: FFN(X + δ) − FFN(X) = f(δ) + O(∥δ∥2) (15) where the linear response operator f(δ) is given by: f(δ) = W2 diag(ϕ′(U)) W1 (A − B) δ (16) with U = W1LN(...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.