The Regularizing Power of Language-Training Deepfake Detectors
Pith reviewed 2026-06-28 23:18 UTC · model grok-4.3
The pith
Language training regularizes deepfake detectors by steering them toward high-level generalizable features rather than low-level dataset artifacts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
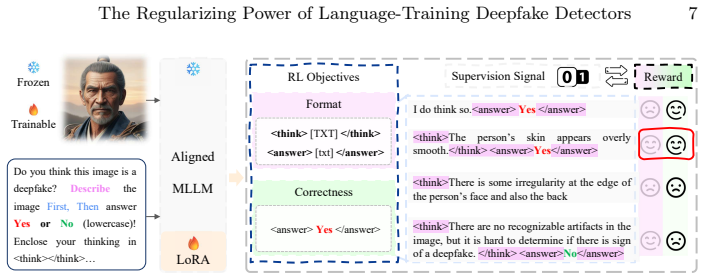
The paper establishes that a dual-encoder architecture combining a frozen specialist detector with a LoRA-tuned MLLM encoder, trained first through binary alignment and then through reinforcement learning that incentivizes explain-then-classify behavior, enables the model to prioritize high-level robust features. This yields improved cross-dataset generalization and produces descriptive reasoning chains, with the performance benefit persisting even when those chains are omitted during inference.
What carries the argument
Dual-encoder architecture (frozen specialist detector paired with LoRA-tuned MLLM encoder) plus two-stage curriculum of binary alignment followed by RL for explain-then-classify.
If this is right
- Cross-dataset performance exceeds prior state-of-the-art methods by a large margin.
- The model produces human-readable reasoning chains before classifying.
- Accuracy gains remain even when reasoning chains are removed at inference time.
- The approach combines high-level language features where possible with low-level features only when necessary.
Where Pith is reading between the lines
- The same curriculum could be tested on other binary classification tasks that suffer from domain-specific overfitting, such as medical image anomaly detection.
- If the preference for describable features is the active ingredient, simpler prompting strategies without RL might achieve partial regularization gains.
- The method suggests that interpretability and generalization can be pursued jointly rather than traded off.
Load-bearing premise
An LLM pretrained on language will intrinsically prefer high-level describable artifacts over low-level domain-specific ones, allowing the RL stage to successfully steer the model toward robust features.
What would settle it
Run the RL stage on multiple datasets and measure whether cross-dataset accuracy fails to improve beyond the binary-alignment baseline or whether the generated descriptions remain generic and non-predictive of the classification decision.
Figures



read the original abstract
Recently, thanks to the advent of Multimodal-LLMs, deepfake detectors are striving not only to be generalizable but also interpretable. We propose that these two challenges can effectively be tackled jointly, since describable artifacts typically generalize better, opening the possibility to use language as a regularization mechanism. Since deepfake detection generally suffers from overfitting to low-level domain-specific artifacts, our intuition is that an LLM that has been pretrained on language would prefer high-level artifacts that can be described better. This way, we can use high-level features where possible, while training the model to use low-level features where necessary. We utilize a dual-encoder architecture, pairing a frozen specialist detector with a LoRA-tuned MLLM encoder, and a two-stage training curriculum: first, a binary alignment phase demonstrates that the intrinsic capability of MLLMs can effectively combine features to mitigate overfitting to dataset-specific artifacts. To further bolster generalization and achieve interpretability, we employ a reinforcement learning stage that encourages the model to generate descriptive reasoning before classifying, using only binary labels. By rewarding this "explain-then-classify" behavior, we explicitly incentivize the model to prioritize high-level, robust features. Crucially, this process yields both interpretable descriptions and a further boost in cross-dataset performance, even when reasoning chains are omitted at inference. Extensive experiments on benchmark datasets validate our approach, outperforming state-of-the-art methods by a large margin.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that deepfake detection overfitting to low-level domain-specific artifacts can be mitigated by leveraging MLLM language pretraining as a regularizer. It introduces a dual-encoder architecture (frozen specialist detector + LoRA-tuned MLLM) trained in two stages: (1) binary alignment to combine features and reduce dataset-specific overfitting, and (2) RL that rewards 'explain-then-classify' behavior using only binary labels. This is asserted to yield both interpretable descriptions and improved cross-dataset generalization, even when reasoning is omitted at inference, with extensive experiments showing large-margin outperformance over SOTA.
Significance. If the results hold, the work would demonstrate a practical mechanism for using language pretraining bias to favor generalizable high-level features in detection tasks, simultaneously advancing interpretability and robustness without extra supervision. The two-stage curriculum and dual-encoder design are concrete contributions that could influence future multimodal regularization approaches in CV.
major comments (2)
- [Abstract] Abstract: The central claim that the RL stage 'explicitly incentivize[s] the model to prioritize high-level, robust features' rests on rewarding only binary classification correctness plus format compliance. No term in the reward penalizes post-hoc or non-causal explanations, so the mechanism does not demonstrably force the model away from low-level cues that still produce correct binary labels.
- [Abstract] Abstract (method description): The assertion that 'an LLM that has been pretrained on language would prefer high-level artifacts that can be described better' is presented as an intrinsic bias that the RL curriculum exploits, yet no ablation or analysis is referenced showing that the generated explanations are faithful to the detector's actual decision features rather than fluent but decoupled text.
minor comments (1)
- [Title] The title contains an apparent hyphenation inconsistency ('Language-Training').
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, proposing targeted revisions to the abstract and discussion sections where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the RL stage 'explicitly incentivize[s] the model to prioritize high-level, robust features' rests on rewarding only binary classification correctness plus format compliance. No term in the reward penalizes post-hoc or non-causal explanations, so the mechanism does not demonstrably force the model away from low-level cues that still produce correct binary labels.
Authors: We agree that the reward signal consists solely of binary correctness and format compliance and therefore does not contain an explicit penalty for post-hoc or non-causal reasoning. The claim that the RL stage 'explicitly incentivizes' prioritization of high-level features is therefore stronger than the evidence directly supports. We will revise the abstract to replace 'explicitly incentivize' with 'encourage via the explain-then-classify format' and will add a short paragraph in the discussion acknowledging that the regularization effect is indirect and could in principle be satisfied by low-level cues accompanied by fluent but non-causal text. revision: yes
-
Referee: [Abstract] Abstract (method description): The assertion that 'an LLM that has been pretrained on language would prefer high-level artifacts that can be described better' is presented as an intrinsic bias that the RL curriculum exploits, yet no ablation or analysis is referenced showing that the generated explanations are faithful to the detector's actual decision features rather than fluent but decoupled text.
Authors: The referee is correct that the manuscript offers no ablation or analysis (e.g., comparison with saliency maps or intervention experiments) demonstrating that the generated explanations are faithful to the features actually used by the dual-encoder rather than fluent but decoupled text. We will add this point explicitly to the limitations subsection and will outline possible verification approaches for future work, while retaining the original hypothesis as a motivating intuition rather than a proven mechanism. revision: yes
Circularity Check
No significant circularity; derivation relies on external pretraining and binary supervision
full rationale
The paper presents a two-stage curriculum (binary alignment then RL for explain-then-classify) whose central mechanism is the use of an externally pretrained MLLM plus binary labels to incentivize high-level features. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The intuition that language pretraining biases toward describable artifacts is stated as motivation rather than derived from prior self-work, and the RL reward is explicitly binary, leaving the generalization claim as an empirical hypothesis rather than a definitional reduction. The method is therefore self-contained against external benchmarks and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2018 IEEE International Workshop on Information Forensics and Security (WIFS) pp
Afchar, D., Nozick, V., Yamagishi, J., Echizen, I.: Mesonet: a compact facial video forgery detection network. 2018 IEEE International Workshop on Information Forensics and Security (WIFS) pp. 1–7 (2018),https://api.semanticscholar. org/CorpusID:521574751
2018
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report (2025),https://arxiv.org/abs/2502.13923 9, 11, 4, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Detecting generated images by real images only,
Bi, X., Liu, B., Yang, F., Xiao, B., Li, W., Huang, G., Cosman, P.C.: Detecting generated images by real images only. ArXivabs/2311.00962(2023),https: //api.semanticscholar.org/CorpusID:2649353248, 11
-
[4]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Cao, J., Ma, C., Yao, T., Chen, S., Ding, S., Yang, X.: End-to-end reconstruction- classification learning for face forgery detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4113–4122 (June 2022) 1, 3, 4
2022
-
[5]
Antifakeprompt: Prompt- tuned vision-language models are fake image detectors,
Chang, Y.M., Yeh, C., Chiu, W.C., Yu, N.: Antifakeprompt: Prompt-tuned vision- language models are fake image detectors. ArXivabs/2310.17419(2023),https: //api.semanticscholar.org/CorpusID:2644904908, 11
-
[6]
chief financial officer
Chen, H., Magramo, K.: Finance worker pays out $25 million after video call with deepfake “chief financial officer” (Feb 2024),https://edition.cnn.com/2024/02/ 04/asia/deepfake-cfo-scam-hong-kong-intl-hnk1
2024
-
[7]
2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) pp
Chollet, F.: Xception: Deep learning with depthwise separable convolutions. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) pp. 1800– 1807 (2016),https://api.semanticscholar.org/CorpusID:23751108
2017
-
[8]
Cui, X., Li, Y., Zhu, D., Zhou, J., Dong, J., Lyu, S.: Forensics adapter: Unleashing clip for generalizable face forgery detection (2025),https://arxiv.org/abs/2411. 197153
2025
-
[9]
com / deepfakes / faceswap (2019) 1
Deepfakes: deepfakes_faceswap.https : / / github . com / deepfakes / faceswap (2019) 1
2019
-
[10]
Deepmind, G.: Veo: a text-to-video generation system (2025) 13, 14, 2
2025
-
[11]
DeepSeek-AI: Deepseek-r1: Incentivizing reasoning capability in llms via reinforce- ment learning (2025),https://arxiv.org/abs/2501.129483, 4, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Dettmers, T., Pagnoni, A., Holtzman, A., Zettlemoyer, L.: Qlora: Efficient finetun- ing of quantized llms (2023),https://arxiv.org/abs/2305.143146
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
The DeepFake Detection Challenge (DFDC) Dataset
Dolhansky, B., Bitton, J., Pflaum, B., Lu, J., Howes, R., Wang, M., Canton-Ferrer, C.: The deepfake detection challenge dataset. ArXivabs/2006.07397(2020), https://api.semanticscholar.org/CorpusID:2196876161, 8, 10, 3
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[14]
ArXivabs/1910.08854(2019), https://api.semanticscholar.org/CorpusID:2048009391, 8, 10, 3
Dolhansky, B., Howes, R., Pflaum, B., Baram, N., Canton-Ferrer, C.: The deep- fake detection challenge (dfdc) preview dataset. ArXivabs/1910.08854(2019), https://api.semanticscholar.org/CorpusID:2048009391, 8, 10, 3
-
[15]
Bootstrap methods: Another look at the jackknife,
Efron, B.: Bootstrap Methods: Another Look at the Jackknife. The Annals of Statistics7(1), 1 – 26 (1979).https://doi.org/10.1214/aos/1176344552,https: //doi.org/10.1214/aos/11763445525
-
[16]
com / en - de / browse / entity - 422f6dcc - 226f - 44e7 - 98d4 - 22de69b31cf3 ? distributionPartner=google1, 2 16 B
Favreau, J., Lucas, G.: The mandalorian (2020),https://www.disneyplus. com / en - de / browse / entity - 422f6dcc - 226f - 44e7 - 98d4 - 22de69b31cf3 ? distributionPartner=google1, 2 16 B. Hopf,et al
2020
-
[17]
Fortin, A., Vernade, G., Kampf, K., Reshi, A.: Introducing gemini 2.5 flash image, our state-of-the-art image model (2025),https://developers.googleblog.com/ en/introducing-gemini-2-5-flash-image/13, 14, 1, 2
2025
-
[18]
Guo, X., Liu, X., Ren, Z., Grosz, S., Masi, I., Liu, X.: Hierarchical fine-grained image forgery detection and localization (2023),https://arxiv.org/abs/2303. 171114
2023
- [19]
-
[20]
2023 IEEE/CVF International Conference on Computer Vision (ICCV) pp
Guo, Y., Zhen, C., Yan, P.: Controllable guide-space for generalizable face forgery detection. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) pp. 20761–20770 (2023),https://api.semanticscholar.org/CorpusID: 2601648913, 4
2023
-
[21]
ArXivabs/2406.08625(2024),https: //api.semanticscholar.org/CorpusID:2704405863
Hasanaath,A.A.,Luqman,H.,Katib,R.,Anwar,S.:Fsbi:Deepfakesdetectionwith frequency enhanced self-blended images. ArXivabs/2406.08625(2024),https: //api.semanticscholar.org/CorpusID:2704405863
-
[22]
ArXivabs/2105.14376(2021),https://api.semanticscholar
He, Y., Yu, N., Keuper, M., Fritz, M.: Beyond the spectrum: Detecting deepfakes via re-synthesis. ArXivabs/2105.14376(2021),https://api.semanticscholar. org/CorpusID:2352547663
-
[23]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops
Hopf, B., Timofte, R.: Practical manipulation model for robust deepfake detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops. pp. 5675–5684 (October 2025) 1, 3, 4, 12
2025
-
[24]
LoRA: Low-Rank Adaptation of Large Language Models
Hu, J.E., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Chen, W.: Lora: Low-rank adaptation of large language models. ArXivabs/2106.09685(2021), https://api.semanticscholar.org/CorpusID:2354580096
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [25]
-
[26]
2025 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR) pp
Huang, Z., Hu, J., Li, X., He, Y., Zhao, X., Peng, B., Wu, B., Huang, X., Cheng, G.: Sida: Social media image deepfake detection, localization and ex- planation with large multimodal model. 2025 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR) pp. 28831–28841 (2025),https: //api.semanticscholar.org/CorpusID:2745151453, 8, 10, 11, 13
2025
- [27]
-
[28]
Jiang, C., Dong, W., Zhang, Z., Yu, F., Peng, W., Yuan, X., Bi, Y., Zhao, M., Zhou, Z., Si, C., Shan, C.: Ivy-fake: A unified explainable framework and benchmark for image and video aigc detection (2026),https://arxiv.org/abs/2506.009793, 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
IEEE Access8, 83144–83154 (2020),https://api.semanticscholar
Jung,T.,Kim,S.,Kim,K.:Deepvision:Deepfakesdetectionusinghumaneyeblink- ing pattern. IEEE Access8, 83144–83154 (2020),https://api.semanticscholar. org/CorpusID:2186518781
2020
-
[30]
2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., Aila, T.: Analyzing and improving the image quality of stylegan. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 8107–8116 (2019),https://api. semanticscholar.org/CorpusID:2092022731
2020
- [31]
-
[32]
Kowalski, M.: Faceswap.https://github.com/MarekKowalski/FaceSwap(2018) 1, 12 The Regularizing Power of Language-Training Deepfake Detectors 17
2018
-
[33]
2023 IEEE/CVF International Conference on Computer Vision (ICCV) pp
Larue, N., Vu, N.S., Struc, V., Peer, P., Christophides, V.: Seeable: Soft discrep- ancies and bounded contrastive learning for exposing deepfakes. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) pp. 20954–20964 (2022), https://api.semanticscholar.org/CorpusID:2537344173, 4
2023
-
[34]
2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Li, L., Bao, J., Zhang, T., Yang, H., Chen, D., Wen, F., Guo, B.: Face x-ray for more general face forgery detection. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 5000–5009 (2019),https://api. semanticscholar.org/CorpusID:2095164241, 3, 4, 12
2020
-
[35]
Proceedings of the 33rd ACM International Conference on Multimedia (2025),https://api.semanticscholar.org/CorpusID:2805363793, 8, 9, 10, 11
Li, T., Huang, Z., Wen, H., He, Y., Lyu, S., Wu, B., Cheng, G.: Raidx: A retrieval- augmented generation and grpo reinforcement learning framework for explainable deepfake detection. Proceedings of the 33rd ACM International Conference on Multimedia (2025),https://api.semanticscholar.org/CorpusID:2805363793, 8, 9, 10, 11
2025
-
[36]
2020 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR) pp
Li, Y., Yang, X., Sun, P., Qi, H., Lyu, S.: Celeb-df: A large-scale challenging dataset for deepfake forensics. 2020 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR) pp. 3204–3213 (2019),https://api.semanticscholar. org/CorpusID:2127264301, 8, 9, 10, 3
2020
-
[37]
2021 IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR) pp
Liu, H., Li, X., Zhou, W., Chen, Y., He, Y., Xue, H., Zhang, W., Yu, N.: Spatial-phase shallow learning: Rethinking face forgery detection in frequency domain. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR) pp. 772–781 (2021),https://api.semanticscholar.org/CorpusID: 2320921673, 4
2021
-
[38]
2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Luo, Y., Zhang, Y., Yan, J., Liu, W.: Generalizing face forgery detection with high- frequency features. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 16312–16321 (2021),https://api.semanticscholar. org/CorpusID:2323205993
2021
- [39]
-
[40]
Nep, D.: This is not morgan freeman - a deepfake singularity (2021) 13, 14
2021
- [41]
-
[42]
Nguyen, D., Mejri, N., Singh, I.P., Kuleshova, P., Astrid, M., Kacem, A., Ghorbel, E., Aouada, D.: Laa-net: Localized artifact attention network for quality-agnostic andgeneralizabledeepfakedetection.In:ProceedingsoftheIEEE/CVFConference on Computer Vision and Pattern Recognition. pp. 17395–17405 (2024) 1, 3, 9, 4, 8, 12
2024
-
[43]
OpenAI: Gpt-5.1: A smarter, more conversational chatgpt (Nov 2025),https: //openai.com/index/gpt-5-1/1, 2
2025
-
[44]
ArXivabs/2007.09355 (2020),https://api.semanticscholar.org/CorpusID:2206474993
Qian, Y., Yin, G., Sheng, L., Chen, Z., Shao, J.: Thinking in frequency: Face forgery detection by mining frequency-aware clues. ArXivabs/2007.09355 (2020),https://api.semanticscholar.org/CorpusID:2206474993
-
[45]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision (2021),https://arxiv.org/abs/ 2103.000208
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[46]
Hopf,et al
Raisinghani, N.: Nano banana 2: Combining pro capabilities with lightning-fast speed (Feb 2026),https://blog.google/innovation- and- ai/technology/ai/ nano-banana-2/13, 14, 2 18 B. Hopf,et al
2026
-
[47]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models (2021) 1
2021
-
[48]
In: International Con- ference on Computer Vision (ICCV) (2019) 1, 3, 8, 9, 10, 4, 12
Rössler, A., Cozzolino, D., Verdoliva, L., Riess, C., Thies, J., Nießner, M.: Face- Forensics++: Learning to detect manipulated facial images. In: International Con- ference on Computer Vision (ICCV) (2019) 1, 3, 8, 9, 10, 4, 12
2019
-
[49]
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y.K., Wu, Y., Guo, D.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models (2024),https://arxiv.org/abs/2402.03300 2, 3, 4, 7, 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Shiohara, K., Yamasaki, T.: Detecting deepfakes with self-blended images. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 18699–18708 (2022),https://api.semanticscholar.org/CorpusID:2482279161, 3, 10, 4, 8, 12
2022
-
[51]
2025 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR) pp
Sun, K., Chen, S., Yao, T., Sun, X., Ding, S., Ji, R.: Towards general visual- linguistic face forgery detection. 2025 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR) pp. 19576–19586 (2023),https://api. semanticscholar.org/CorpusID:2603342192, 3, 5, 8, 9, 10, 11, 4, 6
2025
- [52]
-
[53]
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Tan, M., Le, Q.V.: Efficientnet: Rethinking model scaling for convolutional neural networks. ArXivabs/1905.11946(2019),https://api.semanticscholar.org/ CorpusID:1672172614
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[54]
ACM Transac- tions on Graphics (TOG)38, 1 – 12 (2019),https://api.semanticscholar.org/ CorpusID:2199506251
Thies, J., Zollhöfer, M., Nießner, M.: Deferred neural rendering. ACM Transac- tions on Graphics (TOG)38, 1 – 12 (2019),https://api.semanticscholar.org/ CorpusID:2199506251
2019
-
[55]
2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) pp
Thies, J., Zollhöfer, M., Stamminger, M., Theobalt, C., Nießner, M.: Face2face: Real-time face capture and reenactment of rgb videos. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) pp. 2387–2395 (2016),https: //api.semanticscholar.org/CorpusID:528585691
2016
-
[56]
In: Neural Information Pro- cessing Systems (2017),https://api.semanticscholar.org/CorpusID:13756489 4
Vaswani, A., Shazeer, N.M., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I.: Attention is all you need. In: Neural Information Pro- cessing Systems (2017),https://api.semanticscholar.org/CorpusID:13756489 4
2017
-
[57]
Veo: Veo 3 demo | sailor and the sea (2025),https://www.youtube.com/watch?v= mCFMn0UkRt01
2025
-
[58]
Wadhwa, N., Garg, R., Jacobs, D.E., Feldman, B.E., Kanazawa, N., Carroll, R., Movshovitz-Attias, Y., Barron, J.T., Pritch, Y., Levoy, M.: Synthetic depth-of-field with a single-camera mobile phone. ACM Transactions on Graphics37(4), 1–13 (Jul 2018).https://doi.org/10.1145/3197517.3201329,http://dx.doi.org/ 10.1145/3197517.320132911
-
[59]
Wakefield, J.: Deepfake presidents used in russia-ukraine war (Mar 2022),https: //www.bbc.com/news/technology-607801421
2022
-
[60]
Wang, S.Y., Wang, O., Zhang, R., Owens, A., Efros, A.A.: Cnn-generated images are surprisingly easy to spot... for now. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 8692–8701 (2019),https://api. semanticscholar.org/CorpusID:20944479810
2020
-
[61]
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., Zhou, D.: Chain-of-thought prompting elicits reasoning in large language models (2023),https://arxiv.org/abs/2201.119032, 3 The Regularizing Power of Language-Training Deepfake Detectors 19
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
Wikipedia: (Oct 2025),https://en.wikipedia.org/wiki/Will_Smith_Eating_ Spaghetti_test13, 14
2025
-
[63]
ArXivabs/2307.01426(2023),https://api
Yan, Z., Zhang, Y., Yuan, X., Lyu, S., Wu, B.: Deepfakebench: A comprehensive benchmark of deepfake detection. ArXivabs/2307.01426(2023),https://api. semanticscholar.org/CorpusID:2593421578, 9, 4, 12
-
[64]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Yan, Z., Luo, Y., Lyu, S., Liu, Q., Wu, B.: Transcending forgery specificity with latent space augmentation for generalizable deepfake detection. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 8984–8994 (2023),https://api.semanticscholar.org/CorpusID:2652946231, 3, 4
2024
-
[65]
Yan, Z., Wang, J., Jin, P., Zhang, K.Y., Liu, C., Chen, S., Yao, T., Ding, S., Wu, B., Yuan, L.: Orthogonal subspace decomposition for generalizable ai-generated image detection (2025),https://arxiv.org/abs/2411.156333, 8, 9, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
arXiv preprint arXiv:2406.13495 (2024) 1, 8, 9, 10, 12, 3
Yan, Z., Yao, T., Chen, S., Zhao, Y., Fu, X., Zhu, J., Luo, D., Yuan, L., Wang, C., Ding, S., et al.: Df40: Toward next-generation deepfake detection. arXiv preprint arXiv:2406.13495 (2024) 1, 8, 9, 10, 12, 3
-
[67]
2023 IEEE/CVF International Conference on Com- puter Vision (ICCV) pp
Yan, Z., Zhang, Y., Fan, Y., Wu, B.: Ucf: Uncovering common features for gen- eralizable deepfake detection. 2023 IEEE/CVF International Conference on Com- puter Vision (ICCV) pp. 22355–22366 (2023),https://api.semanticscholar. org/CorpusID:2583524311, 3, 4
2023
- [68]
- [69]
- [70]
-
[71]
2021 IEEE/CVF International Conference on Computer Vision (ICCV) pp
Zhao, T., Xu, X., Xu, M., Ding, H., Xiong, Y., Xia, W.: Learning self-consistency for deepfake detection. 2021 IEEE/CVF International Conference on Computer Vision (ICCV) pp. 15003–15013 (2020),https://api.semanticscholar.org/ CorpusID:2364564483
2021
-
[72]
Zheng, Y., Bao, J., Chen, D., Zeng, M., Wen, F.: Exploring temporal coherence for more general video face forgery detection (2021),https://arxiv.org/abs/2108. 066933
2021
-
[73]
Zhou, Z., Luo, Y., Wu, Y., Sun, K., Ji, J., Yan, K., Ding, S., Sun, X., Wu, Y., Ji, R.: Aigi-holmes: Towards explainable and generalizable ai-generated image detection via multimodal large language models (2025),https://arxiv.org/abs/2507. 026643
2025
-
[74]
ArXivabs/2210.12752(2022),https://api
Zhuang, W., Chu, Q., Tan, Z., Liu, Q., Yuan, H., Miao, C., Luo, Z., Yu, N.: Uia-vit: Unsupervised inconsistency-aware method based on vision trans- former for face forgery detection. ArXivabs/2210.12752(2022),https://api. semanticscholar.org/CorpusID:2530981893, 8, 9, 4
-
[75]
(deep)fake
Zou, Z., Gong, B., Wang, L.: Attention to neural plagiarism: Diffusion models can plagiarize your copyrighted images! In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV). pp. 19546–19556 (October 2025) 13, 14 The Regularizing Power of Language-Training Deepfake Detectors 1 The Regularizing Power of Language-Training Deepfa...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.