FASTER: Rethinking Real-Time Flow VLAs
Pith reviewed 2026-05-21 10:44 UTC · model grok-4.3
The pith
A horizon-aware schedule in flow VLAs compresses immediate action denoising into one step while preserving long-horizon trajectory quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
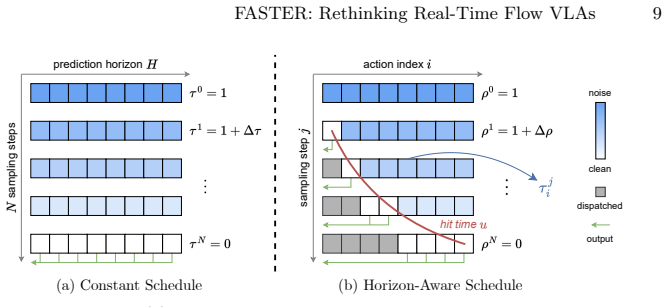
The central discovery is that a Horizon-Aware Schedule adaptively prioritizes near-term actions during flow sampling. This compresses the denoising required for the immediate reaction by tenfold into a single step in models such as pi_0.5 and X-VLA. The quality of the long-horizon trajectory remains preserved. When combined with a streaming client-server pipeline, the approach substantially lowers reaction latency in physical robot deployments.
What carries the argument
Horizon-Aware Schedule, which adaptively allocates denoising steps to favor near-term actions over distant ones inside the flow sampling process for vision-language-action models.
If this is right
- Movement can begin after a single sampling step rather than after the full denoising sequence completes.
- Effective reaction latency drops on real robots, especially in dynamic settings such as table tennis.
- The improvement holds on consumer-grade GPUs while trajectory accuracy and smoothness are maintained.
- Generalist policies gain rapid generation of accurate trajectories without changing the underlying flow model.
Where Pith is reading between the lines
- The same priority mechanism could be tested in other generative sequence models used for robot planning beyond flow matching.
- Combining the schedule with variable execution horizons based on observed environmental change rates would be a direct next measurement.
- The uniform reaction-time distribution result suggests new evaluation metrics that explicitly separate first-action latency from full-trajectory quality.
Load-bearing premise
Adaptively prioritizing near-term actions during flow sampling does not degrade the smoothness or accuracy of the overall long-horizon trajectory.
What would settle it
A side-by-side execution of the same long-horizon task under both the constant schedule and the horizon-aware schedule, checking whether final trajectory error or jerk metrics increase with the new schedule.
Figures












read the original abstract
Real-time execution is crucial for deploying Vision-Language-Action (VLA) models in the physical world. Existing asynchronous inference methods primarily optimize trajectory smoothness, but neglect the critical latency in reacting to environmental changes. By rethinking the notion of reaction in action chunking policies, this paper presents a systematic analysis of the factors governing reaction time. We show that reaction time follows a uniform distribution determined jointly by the Time to First Action (TTFA) and the execution horizon. Moreover, we reveal that the standard practice of applying a constant schedule in flow-based VLAs can be inefficient and forces the system to complete all sampling steps before any movement can start, forming the bottleneck in reaction latency. To overcome this issue, we propose Fast Action Sampling for ImmediaTE Reaction (FASTER). By introducing a Horizon-Aware Schedule, FASTER adaptively prioritizes near-term actions during flow sampling, compressing the denoising of the immediate reaction by tenfold (e.g., in $\pi_{0.5}$ and X-VLA) into a single step, while preserving the quality of long-horizon trajectory. Coupled with a streaming client-server pipeline, FASTER substantially reduces the effective reaction latency on real robots, especially when deployed on consumer-grade GPUs. Real-world experiments, including a highly dynamic table tennis task, prove that FASTER unlocks substantially improved real-time responsiveness for generalist policies, enabling rapid generation of accurate and smooth trajectories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FASTER for real-time Vision-Language-Action (VLA) models based on flow matching. It analyzes reaction latency in action chunking policies, showing that reaction time follows a uniform distribution jointly set by Time to First Action (TTFA) and execution horizon. The work identifies constant denoising schedules as a bottleneck that forces all sampling steps before any action can begin. It proposes a Horizon-Aware Schedule that adaptively prioritizes near-term actions during flow sampling, claiming this compresses immediate-reaction denoising by a factor of ten (e.g., in π₀.₅ and X-VLA) into a single step while preserving long-horizon trajectory quality. The method is paired with a streaming client-server pipeline and evaluated on real robots, including a dynamic table-tennis task.
Significance. If the empirical claims hold, the work would be significant for deploying generalist VLAs in dynamic physical settings on consumer GPUs. The reaction-time analysis supplies a useful conceptual reframing, and the adaptive schedule directly targets a practical latency bottleneck. Real-world validation on a challenging task such as table tennis adds credibility to the responsiveness gains.
major comments (3)
- The central claim that the Horizon-Aware Schedule compresses immediate-reaction denoising tenfold into one step while leaving long-horizon quality intact is load-bearing, yet the manuscript supplies neither the explicit schedule formulation nor quantitative ablations (e.g., trajectory smoothness or endpoint error) comparing it to the constant baseline; this gap directly affects verifiability of the weakest assumption identified in the reader report.
- The assertion that reaction time is uniformly distributed and determined jointly by TTFA and horizon is presented as the foundation for rethinking reaction latency, but no derivation, proof sketch, or supporting plot appears in the analysis; without this, the motivation for the subsequent schedule remains incompletely grounded.
- Real-robot experiments (including table tennis) report substantially reduced effective reaction latency, but the text does not provide per-condition latency histograms, success-rate tables, or statistical tests against the asynchronous baseline, making it difficult to judge whether the tenfold sampling compression translates to measurable end-to-end gains without hidden confounds.
minor comments (2)
- The models π₀.₅ and X-VLA are referenced in the abstract and results without a brief definition or citation on first use; adding one sentence would aid readers outside the immediate sub-community.
- Notation such as TTFA is introduced without an explicit equation or parenthetical expansion on first appearance, which could be clarified for broader accessibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for improving clarity, verifiability, and completeness. We address each major comment below and will revise the manuscript accordingly to incorporate the requested details, formulations, and analyses.
read point-by-point responses
-
Referee: The central claim that the Horizon-Aware Schedule compresses immediate-reaction denoising tenfold into one step while leaving long-horizon quality intact is load-bearing, yet the manuscript supplies neither the explicit schedule formulation nor quantitative ablations (e.g., trajectory smoothness or endpoint error) comparing it to the constant baseline; this gap directly affects verifiability of the weakest assumption identified in the reader report.
Authors: We agree that an explicit formulation and quantitative ablations are necessary for verifiability. In the revised manuscript we will add the full mathematical definition of the Horizon-Aware Schedule (including the adaptive weighting function over the horizon) in Section 4. We will also include new quantitative ablations reporting trajectory smoothness (via mean jerk) and endpoint error for both the proposed schedule and the constant baseline across multiple models (π₀.₅ and X-VLA). These results confirm that long-horizon quality is preserved while immediate-action denoising is reduced to a single step. revision: yes
-
Referee: The assertion that reaction time is uniformly distributed and determined jointly by TTFA and horizon is presented as the foundation for rethinking reaction latency, but no derivation, proof sketch, or supporting plot appears in the analysis; without this, the motivation for the subsequent schedule remains incompletely grounded.
Authors: We acknowledge that a formal derivation would strengthen the grounding. The revised version will contain a derivation showing that reaction time is uniformly distributed over [0, TTFA + horizon] under the action-chunking execution model, together with a short proof sketch and a supporting plot of the resulting distribution. This material will be placed in Section 3 with additional detail in the appendix. revision: yes
-
Referee: Real-robot experiments (including table tennis) report substantially reduced effective reaction latency, but the text does not provide per-condition latency histograms, success-rate tables, or statistical tests against the asynchronous baseline, making it difficult to judge whether the tenfold sampling compression translates to measurable end-to-end gains without hidden confounds.
Authors: We will expand the experimental results section to include per-condition latency histograms, comprehensive success-rate tables for all tasks (including table tennis), and statistical tests (paired t-tests and Wilcoxon rank-sum tests) against the asynchronous baseline. These additions will quantify the end-to-end latency gains and address potential confounds. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives reaction time as following a uniform distribution jointly determined by TTFA and execution horizon, then introduces the Horizon-Aware Schedule as a new adaptive mechanism for flow sampling. No load-bearing step reduces by construction to a fitted parameter, self-citation, or input; the compression claim and quality preservation are presented as outcomes of the proposed schedule rather than tautological redefinitions. The central result remains independent of its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reaction time follows a uniform distribution jointly determined by Time to First Action (TTFA) and execution horizon.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Horizon-Aware Schedule … τ^j_i = max(0,(ρ^j − u_i)/(1 − u_i)) … u_i = (1 − (i/(H−1))^α) * u_0
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
straightness metric S(A) … pilot study … early actions … lower straightness values
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
DiscreteRTC: Discrete Diffusion Policies are Natural Asynchronous Executors
Discrete diffusion policies support native asynchronous execution via unmasking for real-time chunking, delivering higher success rates and 0.7x inference cost versus flow-matching RTC on dynamic robotics benchmarks a...
-
DEFLECT: Delay-Robust Execution via Flow-matching Likelihood-Estimated Counterfactual Tuning for VLA Policies
DEFLECT is an offline post-training method that improves async VLA policy success rates under high inference delays by using flow-matching likelihood ratios on counterfactual fresh/stale action pairs from a frozen ref...
-
LiteVLA-H: Dual-Rate Vision-Language-Action Inference for Onboard Aerial Guidance and Semantic Perception
LiteVLA-H delivers 19.74 Hz action tokens and 6 Hz semantic outputs on Jetson Orin via dual-rate scheduling and mixed fine-tuning, outperforming recent VLA baselines in edge action rate while preserving descriptive co...
-
LiteVLA-H: Dual-Rate Vision-Language-Action Inference for Onboard Aerial Guidance and Semantic Perception
LiteVLA-H delivers 50 ms reactive action tokens and 150-165 ms semantic outputs on Jetson AGX Orin by separating fast guidance from slower scene understanding in a compact VLA fine-tuned on mixed aerial and generic data.
Reference graph
Works this paper leans on
-
[1]
Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., et al.: Qwen technical report. arXiv preprint arXiv:2309.16609 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Bjorck, J., Castañeda, F., Cherniadev, N., Da, X., Ding, R., Fan, L., Fang, Y., Fox, D., Hu, F., Huang, S., et al.: GR00T N1: an open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al.:π0: A vision-language-action flow model for general robot control. In: RSS (2025)
work page 2025
-
[4]
Black, K., Galliker, M.Y., Levine, S.: Real-time execution of action chunking flow policies. In: NeurIPS (2025)
work page 2025
-
[5]
Black, K., Ren, A.Z., Equi, M., Levine, S.: Training-time action conditioning for efficient real-time chunking. arXiv preprint arXiv:2512.05964 (2025)
-
[6]
Bu, Q., Cai, J., Chen, L., Cui, X., Ding, Y., Feng, S., He, X., Huang, X., et al.: Agibot world colosseo: A large-scale manipulation platform for scalable and in- telligent embodied systems. In: IROS (2025)
work page 2025
-
[7]
arXiv preprint arXiv:2507.14049 (2025)
Budzianowski, P., Maa, W., Freed, M., Mo, J., Hsiao, W., Xie, A., Młoduchowski, T., Tipnis, V., Bolte, B.: Edgevla: Efficient vision-language-action models. arXiv preprint arXiv:2507.14049 (2025)
-
[8]
Cadene, R., Alibert, S., Capuano, F., Aractingi, M., Zouitine, A., Kooijmans, P., Choghari, J., Russi, M., Pascal, C., Palma, S., Shukor, M., Moss, J., Soare, A., Aubakirova, D., Lhoest, Q., Gallouédec, Q., Wolf, T.: Lerobot: An open-source library for end-to-end robot learning. In: ICLR (2026)
work page 2026
-
[9]
arXiv preprint arXiv:2602.12684 (2026)
Cai, R., Guo, J., He, X., Jin, P., Li, J., Lin, B., Liu, F., Liu, W., Ma, F., Ma, K., et al.: Xiaomi-robotics-0: An open-sourced vision-language-action model with real-time execution. arXiv preprint arXiv:2602.12684 (2026)
-
[10]
Chen, B., Monsó, D.M., Du, Y., Simchowitz, M., Tedrake, R., Sitzmann, V.: Diffusionforcing:Next-tokenpredictionmeetsfull-sequencediffusion.In:NeurIPS (2024)
work page 2024
-
[11]
Chen, H., Liu, M., Ma, C., Ma, X., Ma, Z., Wu, H., Chen, Y., Zhong, Y., Wang, M., Li, Q., Yang, Y.: Falcon: Fast visuomotor policies via partial denoising. In: ICML (2025) 16 Y. Lu, Z. Liu et al
work page 2025
-
[12]
arXiv preprint arXiv:2510.25122 (2025)
Chen, J., Wang, J., Chen, L., Cai, C., Lu, J.: Nanovla: Routing decoupled vision- language understanding for nano-sized generalist robotic policies. arXiv preprint arXiv:2510.25122 (2025)
-
[13]
arXiv preprint arXiv:2506.17639 (2025)
Chen, Y., Li, X.: Rlrc: Reinforcement learning-based recovery for compressed vision-language-action models. arXiv preprint arXiv:2506.17639 (2025)
-
[14]
Chen, Z., Yuan, X., Mu, T., Su, H.: Responsive noise-relaying diffusion policy: Responsive and efficient visuomotor control. TMLR (2025)
work page 2025
-
[15]
Chi, C., Feng, S., Du, Y., Xu, Z., Cousineau, E., Burchfiel, B., Song, S.: Diffusion Policy: Visuomotor policy learning via action diffusion. In: RSS (2023)
work page 2023
-
[16]
arXiv preprint arXiv:2512.20276 (2025)
Dai, Y., Gu, H., Wang, T., Cheng, Q., Zheng, Y., Qiu, Z., Gong, L., Lou, W., Zhou, X.: Actionflow: A pipelined action acceleration for vision language models on edge. arXiv preprint arXiv:2512.20276 (2025)
-
[17]
IEEE Transactions on robotics (2025)
Ding, H., Jaquier, N., Peters, J., Rozo, L.: Fast and robust visuomotor riemannian flow matching policy. IEEE Transactions on robotics (2025)
work page 2025
- [18]
-
[19]
Any3D-VLA: Enhancing VLA Robustness via Diverse Point Clouds
Fan, X., Deng, S., Wu, X., Lu, Y., Li, Z., Yan, M., Zhang, Y., Zhang, Z., Wang, H., Zhao, H.: Any3d-vla: Enhancing vla robustness via diverse point clouds. arXiv preprint arXiv:2602.00807 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
arXiv preprint arXiv:2509.09090 (2025)
Fang, H., Liu, Y., Du, Y., Du, L., Yang, H.: Sqap-vla: A synergistic quantization- aware pruning framework for high-performance vision-language-action models. arXiv preprint arXiv:2509.09090 (2025)
-
[21]
Frans, K., Hafner, D., Levine, S., Abbeel, P.: One step diffusion via shortcut models. In: ICLR (2025)
work page 2025
-
[22]
Fu, Z., Zhao, T.Z., Finn, C.: Mobile ALOHA: Learning bimanual mobile manip- ulation using low-cost whole-body teleoperation. In: CoRL (2024)
work page 2024
-
[23]
arXiv preprint arXiv:2511.18950 (2025)
Gao, J., Ye, F., Zhang, J., Qian, W.: Compressor-vla: Instruction-guided visual token compression for efficient robotic manipulation. arXiv preprint arXiv:2511.18950 (2025)
-
[24]
Geng, Z., Deng, M., Bai, X., Kolter, J.Z., He, K.: Mean flows for one-step gener- ative modeling. In: NeurIPS (2025)
work page 2025
-
[25]
arXiv preprint arXiv:2510.17111 (2025)
Guan, W., Hu, Q., Li, A., Cheng, J.: Efficient vision-language-action models for embodied manipulation: A systematic survey. arXiv preprint arXiv:2510.17111 (2025)
work page internal anchor Pith review arXiv 2025
-
[26]
MiMo-Embodied: X-Embodied Foundation Model Technical Report
Hao, X., Zhou, L., Huang, Z., Hou, Z., Tang, Y., Zhang, L., Li, G., Lu, Z., Ren, S., Meng, X., et al.: Mimo-embodied: X-embodied foundation model technical report. arXiv preprint arXiv:2511.16518 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: NeurIPS (2020)
work page 2020
-
[28]
Eric Jang, Shixiang Gu, and Ben Poole
Høeg, S.H., Du, Y., Egeland, O.: Streaming diffusion policy: Fast policy synthesis with variable noise diffusion models. arXiv preprint arXiv:2406.04806 (2024)
-
[29]
Deepspeed-fastgen: High-throughput text generation for llms via MII and deepspeed-inference
Holmes, C., Tanaka, M., Wyatt, M., Awan, A.A., Rasley, J., Rajbhandari, S., Aminabadi, R.Y., Qin, H., Bakhtiari, A., Kurilenko, L., et al.: Deepspeed-fastgen: High-throughput text generation for llms via mii and deepspeed-inference. arXiv preprint arXiv:2401.08671 (2024)
-
[30]
arXiv preprint arXiv:2602.00780 (2026) FASTER: Rethinking Real-Time Flow VLAs 17
Huang, Y., Ding, L., Tang, Z., Zhu, Z., Deng, J., Lin, X., Liu, S., Ren, H., Ji, J., Zhang, Y.: Environment-aware adaptive pruning with interleaved inference orchestration for vision-language-action models. arXiv preprint arXiv:2602.00780 (2026) FASTER: Rethinking Real-Time Flow VLAs 17
-
[31]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Intelligence, P., Amin, A., Aniceto, R., Balakrishna, A., Black, K., Conley, K., Connors, G., Darpinian, J., Dhabalia, K., DiCarlo, J., et al.:π∗ 0.6: a vla that learns from experience. arXiv preprint arXiv:2511.14759 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Intelligence, P., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., et al.:π0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
arXiv preprint arXiv:2510.08464 (2025)
Jabbour, J., Kim, D.K., Smith, M., Patrikar, J., Ghosal, R., Wang, Y., Agha, A., Reddi, V.J., Omidshafiei, S.: Don’t run with scissors: Pruning breaks vla models but they can be recovered. arXiv preprint arXiv:2510.08464 (2025)
-
[34]
arXiv preprint arXiv:2601.20262 (2026)
Jeon, B., Choi, Y., Kim, T.: Shallow-π: Knowledge distillation for flow-based vlas. arXiv preprint arXiv:2601.20262 (2026)
-
[35]
Jia, B., Ding, P., Cui, C., Sun, M., Qian, P., Huang, S., Fan, Z., Wang, D.: Score and distribution matching policy: Advanced accelerated visuomotor policies via matched distillation. arXiv preprint arXiv:2412.09265 (2024)
-
[36]
arXiv preprint arXiv:2509.12594 (2025) 16 X
Jiang, T., Jiang, X., Ma, Y., Wen, X., Li, B., Zhan, K., Jia, P., Liu, Y., Sun, S., Lang, X.: The better you learn, the smarter you prune: Towards efficient vision-language-action models via differentiable token pruning. arXiv preprint arXiv:2509.12594 (2025)
-
[37]
Khazatsky, A., Pertsch, K., Nair, S., Balakrishna, A., Dasari, S., Karamcheti, S., Nasiriany, S., Srirama, M.K., Chen, L.Y., Ellis, K., et al.: DROID: A large-scale in-the-wild robot manipulation dataset. In: RSS (2024)
work page 2024
-
[38]
Kim, M.J., Finn, C., Liang, P.: Fine-tuning vision-language-action models: Opti- mizing speed and success. In: RSS (2025)
work page 2025
-
[39]
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., et al.: OpenVLA: An open-source vision-language-action model. In: CoRL (2024)
work page 2024
-
[40]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., et al.: Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
arXiv preprint arXiv:2511.10518 (2025)
Li, W., Zhang, R., Shao, R., Fang, Z., Zhou, K., Tian, Z., Nie, L.: Semanticvla: Semantic-aligned sparsification and enhancement for efficient robotic manipula- tion. arXiv preprint arXiv:2511.10518 (2025)
-
[42]
arXiv preprint arXiv:2506.12723 (2025)
Li, Y., Meng, Y., Sun, Z., Ji, K., Tang, C., Fan, J., Ma, X., Xia, S., Wang, Z., Zhu, W.: Sp-vla: A joint model scheduling and token pruning approach for vla model acceleration. arXiv preprint arXiv:2506.12723 (2025)
-
[43]
arXiv preprint arXiv:2508.14042 (2025)
Li, Z., Wu, X., Xu, Z., Zhao, H.: Train once, deploy anywhere: Realize data- efficient dynamic object manipulation. arXiv preprint arXiv:2508.14042 (2025)
-
[44]
arXiv preprint arXiv:2512.07697 (2025)
Liao, A., Kim, D.K., Smith, M.O., Agha-mohammadi, A.a., Omidshafiei, S.: Delay-aware diffusion policy: Bridging the observation-execution gap in dynamic tasks. arXiv preprint arXiv:2512.07697 (2025)
-
[45]
Lin, T., Zhong, Y., Du, Y., Zhang, J., Liu, J., Chen, Y., Gu, E., Liu, Z., Cai, H., Zou, Y., et al.: Evo-1: Lightweight vision-language-action model with preserved semantic alignment. arXiv preprint arXiv:2511.04555 (2025)
-
[46]
Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: ICLR (2023)
work page 2023
-
[47]
Lipman, Y., Havasi, M., Holderrieth, P., Shaul, N., Le, M., Karrer, B., Chen, R.T., Lopez-Paz, D., Ben-Hamu, H., Gat, I.: Flow matching guide and code. arXiv preprint arXiv:2412.06264 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Liu,B.,Zhu,Y.,Gao,C.,Feng,Y.,Liu,Q.,Zhu,Y.,Stone,P.:Libero:Benchmark- ing knowledge transfer for lifelong robot learning. In: NeurIPS. pp. 44776–44791 (2023) 18 Y. Lu, Z. Liu et al
work page 2023
-
[49]
Liu, J., Liu, M., Wang, Z., An, P., Li, X., Zhou, K., Yang, S., Zhang, R., Guo, Y., Zhang, S.: Robomamba: Efficient vision-language-action model for robotic reasoning and manipulation. In: NeurIPS. pp. 40085–40110 (2024)
work page 2024
-
[50]
arXiv preprint arXiv:2602.03310 (2026)
Liu, S., Li, B., Ma, K., Wu, L., Tan, H., Ouyang, X., Su, H., Zhu, J.: RDT2: Exploring the scaling limit of umi data towards zero-shot cross-embodiment gen- eralization. arXiv preprint arXiv:2602.03310 (2026)
-
[51]
Liu, X., Gong, C., qiang liu: Flow straight and fast: Learning to generate and transfer data with rectified flow. In: ICLR (2023)
work page 2023
-
[52]
Liu, Y., Hamid, J.I., Xie, A., Lee, Y., Du, M., Finn, C.: Bidirectional decoding: Improving action chunking via guided test-time sampling. In: ICLR (2025)
work page 2025
-
[53]
Learning Native Continuation for Action Chunking Flow Policies
Liu, Y., Yu, H., Zhao, J., Li, B., Zhang, D., Li, M., Wu, W., Hu, Y., Xie, J., Guo, J., et al.: Learning native continuation for action chunking flow policies. arXiv preprint arXiv:2602.12978 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
Liu, Z., Huang, R., Yang, R., Yan, S., Wang, Z., Hou, L., Lin, D., Bai, X., Zhao, H.: Drivepi: Spatial-aware 4d mllm for unified autonomous driving understanding, perception, prediction and planning. In: CVPR (2026)
work page 2026
-
[55]
arXiv preprint arXiv:2511.16449 (2025)
Liu, Z., Chen, Y., Cai, H., Lin, T., Yang, S., Liu, Z., Zhao, B.: Vla-pruner: Temporal-aware dual-level visual token pruning for efficient vision-language- action inference. arXiv preprint arXiv:2511.16449 (2025)
work page internal anchor Pith review arXiv 2025
-
[56]
arXiv preprint arXiv:2406.01586 (2024)
Lu, G., Gao, Z., Chen, T., Dai, W., Wang, Z., Ding, W., Tang, Y.: Manicm: Real- time 3d diffusion policy via consistency model for robotic manipulation. arXiv preprint arXiv:2406.01586 (2024)
-
[57]
arXiv preprint arXiv:2512.11769 (2025)
Ma,X.,Yuan,Z.,Zhang,Z.,Shi,K.,Sun,L.,Ye,Y.:Blurr:Aboostedlow-resource inference for vision-language-action models. arXiv preprint arXiv:2512.11769 (2025)
-
[58]
A Survey on Vision-Language-Action Models for Embodied AI
Ma, Y., Song, Z., Zhuang, Y., Hao, J., King, I.: A survey on vision-language-action models for embodied ai. arXiv preprint arXiv:2405.14093 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
arXiv preprint arXiv:2510.26742 (2025)
Ma, Y., Zhou, Y., Yang, Y., Wang, T., Fan, H.: Running vlas at real-time speed. arXiv preprint arXiv:2510.26742 (2025)
-
[60]
Matthews, M., Beukman, M., Lu, C., Foerster, J.N.: Kinetix: Investigating the training of general agents through open-ended physics-based control tasks. In: ICLR (2025)
work page 2025
-
[61]
Mees, O., Hermann, L., Rosete-Beas, E., Burgard, W.: CALVIN: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks. RAL (2022)
work page 2022
-
[62]
arXiv preprint arXiv:2512.00903 (2025)
Ni, C., Chen, C., Wang, X., Zhu, Z., Zheng, W., Wang, B., Chen, T., Zhao, G., Li, H., Dong, Z., et al.: Swiftvla: Unlocking spatiotemporal dynamics for lightweight vla models at minimal overhead. arXiv preprint arXiv:2512.00903 (2025)
-
[63]
Padalkar, A., Pooley, A., Jain, A., Bewley, A., Herzog, A., Irpan, A., Khazatsky, A., Rai, A., Singh, A., Brohan, A., et al.: Open X-Embodiment: Robotic learning datasets and RT-X models. In: ICRA (2024)
work page 2024
-
[64]
arXiv preprint arXiv:2412.01034 (2024)
Park, S., Kim, H., Jeon, W., Yang, J., Jeon, B., Oh, Y., Choi, J.: Quantization- aware imitation-learning for resource-efficient robotic control. arXiv preprint arXiv:2412.01034 (2024)
- [65]
-
[66]
In: ICLR (2026) FASTER: Rethinking Real-Time Flow VLAs 19
Pei, X., Chen, Y., Xu, S., Wang, Y., Shi, Y., Xu, C.: Action-aware dynamic pruning for efficient vision-language-action manipulation. In: ICLR (2026) FASTER: Rethinking Real-Time Flow VLAs 19
work page 2026
-
[67]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Pertsch, K., Stachowicz, K., Ichter, B., Driess, D., Nair, S., Vuong, Q., Mees, O., Finn, C., Levine, S.: Fast: Efficient action tokenization for vision-language-action models. arXiv preprint arXiv:2501.09747 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
Reuss, M., Zhou, H., Rühle, M., Yağmurlu, Ö.E., Otto, F., Lioutikov, R.: Flower: Democratizing generalist robot policies with efficient vision-language-action flow policies. In: CoRL (2025)
work page 2025
-
[69]
Sapkota, R., Cao, Y., Roumeliotis, K.I., Karkee, M.: Vision-language-action (vla) models: Concepts, progress, applications and challenges. arXiv preprint arXiv:2505.04769 (2025)
-
[70]
Large VLM-based Vision-Language-Action Models for Robotic Manipulation: A Survey
Shao, R., Li, W., Zhang, L., Zhang, R., Liu, Z., Chen, R., Nie, L.: Large vlm-based vision-language-action models for robotic manipulation: A survey. arXiv preprint arXiv:2508.13073 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
Sheng, J., Wang, Z., Li, P., Liu, M.: Mp1: Meanflow tames policy learning in 1-step for robotic manipulation. In: AAAI (2026)
work page 2026
- [72]
-
[73]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Shukor, M., Aubakirova, D., Capuano, F., Kooijmans, P., Palma, S., Zoui- tine, A., Aractingi, M., Pascal, C., Russi, M., Marafioti, A., et al.: Smolvla: A vision-language-action model for affordable and efficient robotics. arXiv preprint arXiv:2506.01844 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
Sochopoulos, A., Malkin, N., Tsagkas, N., Moura, J., Gienger, M., Vijayakumar, S.: Fast flow-based visuomotor policies via conditional optimal transport cou- plings. In: CoRL (2025)
work page 2025
-
[75]
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. In: ICLR (2021)
work page 2021
-
[76]
arXiv preprint arXiv:2506.13725 (2025)
Song, W., Chen, J., Ding, P., Huang, Y., Zhao, H., Wang, D., Li, H.: Ceed- vla: Consistency vision-language-action model with early-exit decoding. arXiv preprint arXiv:2506.13725 (2025)
-
[77]
Song, W., Chen, J., Ding, P., Zhao, H., Zhao, W., Zhong, Z., Ge, Z., Ma, J., Li, H.: Accelerating vision-language-action model integrated with action chunking via parallel decoding. In: IROS (2025)
work page 2025
- [78]
-
[79]
arXiv preprint arXiv:2509.11480 (2025)
Taherin, A., Lin, J., Akbari, A., Akbari, A., Zhao, P., Chen, W., Kaeli, D., Wang, Y.: Cross-platform scaling of vision-language-action models from edge to cloud gpus. arXiv preprint arXiv:2509.11480 (2025)
-
[80]
Vlash: Real-time vlas via future-state-aware asynchronous inference, 2025
Tang, J., Sun, Y., Zhao, Y., Yang, S., Lin, Y., Zhang, Z., Hou, J., Lu, Y., Liu, Z., Han, S.: Vlash: Real-time vlas via future-state-aware asynchronous inference. arXiv preprint arXiv:2512.01031 (2025)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.