Comprehensive pKa Data Augmentation from Limited Real Data through an Engineered Models-Quantum Framework
Pith reviewed 2026-06-27 07:57 UTC · model grok-4.3
The pith
Quantum-assisted generation on coherent Ising machines targets scarce extreme pKa molecules in chemical space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
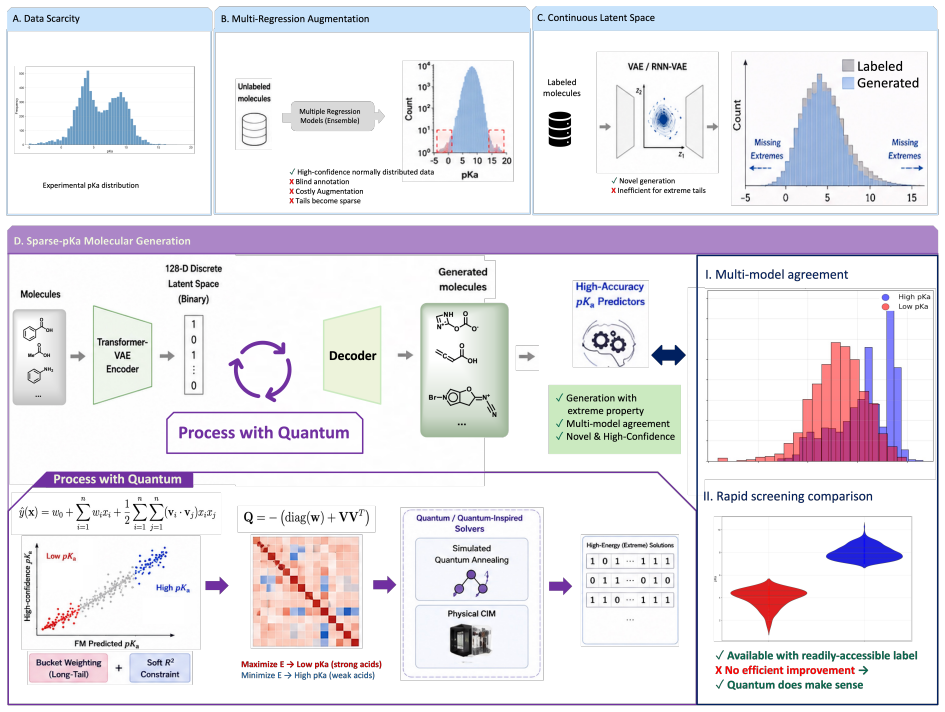
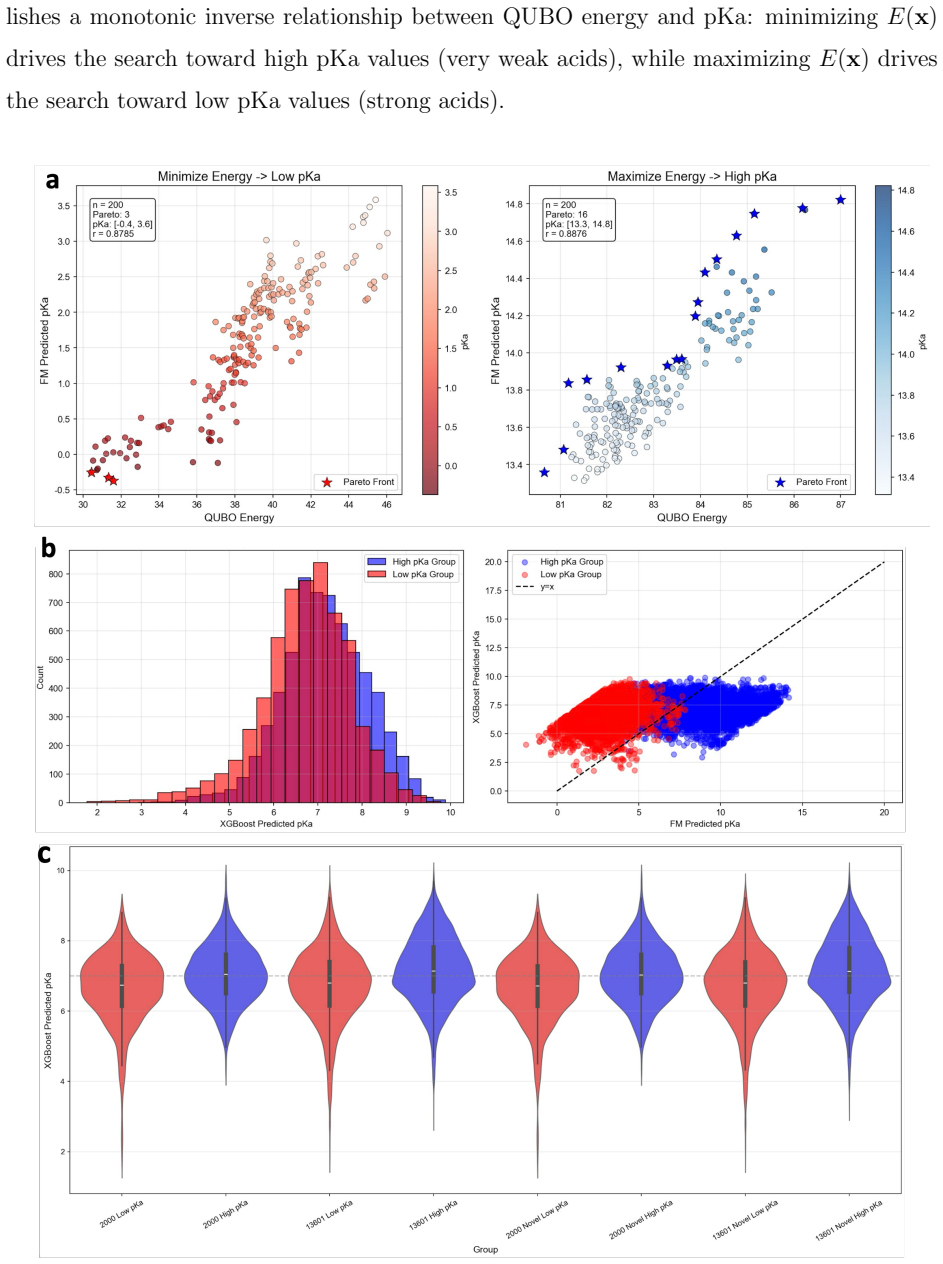
Building on the iBonD experimental pKa database and regression predictions, the paper designs and implements a quantum-assisted sparse-pKa molecular generation method. Feasibility is validated on a simulated quantum annealer, and superior extreme-value sampling is further achieved on physical coherent Ising machines.
What carries the argument
quantum-assisted sparse-pKa molecular generation, which replaces unstable latent-space generators with quantum annealing to sample molecules carrying rare extreme pKa values from chemical space
If this is right
- Regression on unlabeled sets yields normal pKa distributions with extreme scarcity in the tails.
- Targeted quantum generation addresses the insufficiency of regression for discovering broad-spectrum pKa molecules.
- Physical coherent Ising machines deliver better extreme-value sampling than simulated quantum annealers.
- The resulting molecules augment high-quality pKa data for functional molecule discovery and modeling.
Where Pith is reading between the lines
- The sampling approach could be tested on other molecular properties whose distributions are also heavily skewed.
- Coupling the generated candidates to rapid experimental pKa measurement would create a closed-loop discovery workflow.
- As quantum hardware scales, the same extreme-value targeting may apply to additional sparse-data problems in chemistry.
Load-bearing premise
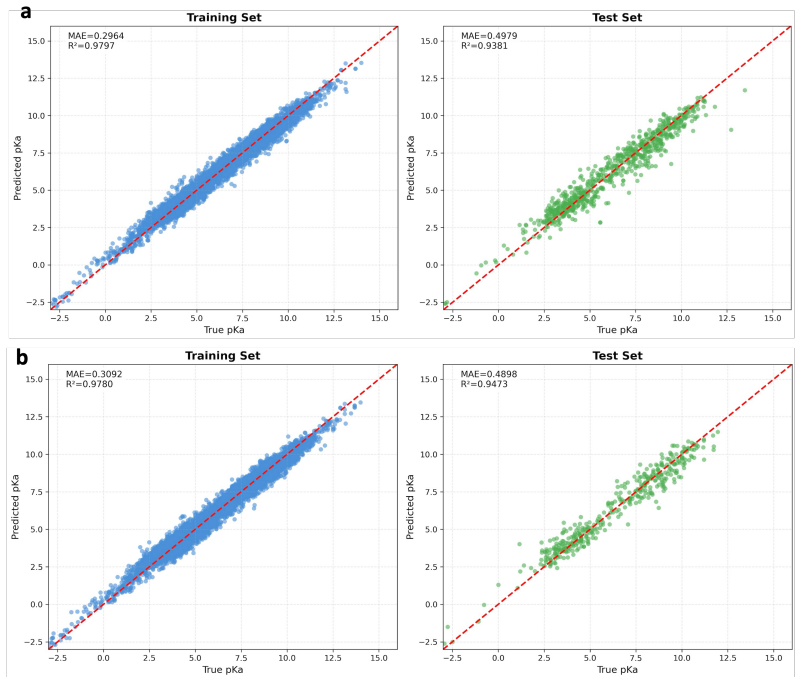
Traditional continuous latent space VAE-RNN methods suffer from insufficient stability and cannot effectively complement sparse pKa data.
What would settle it
A head-to-head run of the same generation task on a classical optimizer or VAE-RNN that produces equal or higher rates of extreme pKa molecules than the physical coherent Ising machine.
Figures

read the original abstract
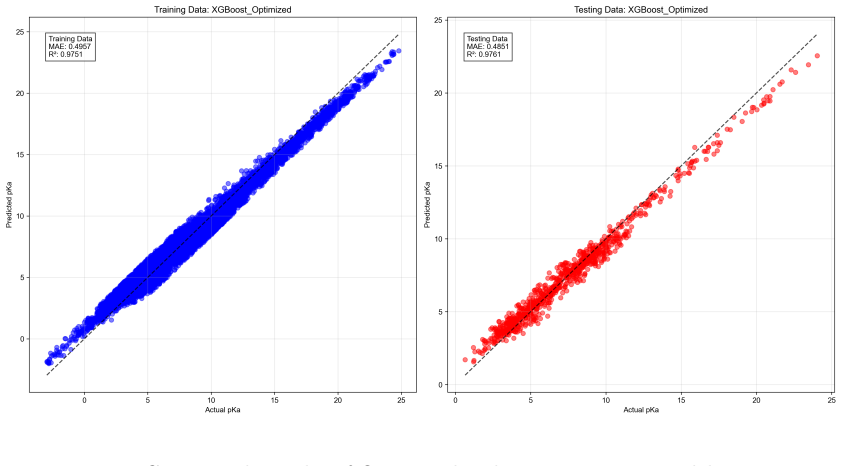
Proton dissociation constants (pKa) are critical for functional molecule discovery and molecular modeling. Building on iBonD, the largest experimental pKa database established, we and other researchers have developed several methods including machine-learning-based empirical prediction and high-accuracy energy calculations. Despite this foundation, the rapid augmentation of high-quality pKa data remains fundamentally constrained. As part of this work, we performed large-scale regression-based pKa prediction on unlabeled molecular datasets using a collection of extensively optimized machine-learning models. The results indicate that, since the feature distributions of unlabeled molecular datasets, the pKa data distribution approximates normality, with extreme scarcity of tail-region samples. Although such augmentation is highly valuable for improving overall data availability and predictive modeling, it remains insufficient for efficiently discovering molecules with broad-spectrum pKa properties. To address this, we explore the targeted generation of molecules with sparse pKa properties from the vast chemical space. Given that traditional continuous latent space VAE-RNN methods for molecular generation suffer from insufficient stability and fail to demonstrate clear advantages in complementing sparse data, we design and implement a quantum-assisted sparse-pKa molecular generation. Feasibility is validated on a simulated quantum annealer, and superior extreme-value sampling is further achieved on physical coherent Ising machines (CIMs). (to be continued)
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that large-scale ML regression on unlabeled molecular datasets yields a near-normal pKa distribution with scarce tail samples, and that a quantum-assisted generation framework using simulated annealers and physical coherent Ising machines (CIMs) achieves superior extreme-value sampling for sparse pKa properties compared with traditional continuous-latent-space VAE-RNN methods, which are asserted to suffer from insufficient stability.
Significance. If the quantitative superiority of the CIM sampler over VAE-RNN baselines is demonstrated with validity rates, tail-enrichment factors, and stability metrics, the work would offer a concrete route to targeted generation of molecules with rare pKa values and could motivate further quantum-hardware applications in molecular design.
major comments (2)
- [Abstract] Abstract: the central claim that 'traditional continuous latent space VAE-RNN methods for molecular generation suffer from insufficient stability and fail to demonstrate clear advantages in complementing sparse data' is load-bearing for the necessity of the CIM formulation, yet the abstract supplies no validity rates, tail-enrichment factors, stability metrics, or any baseline comparison against VAE-RNN (or stabilized variants).
- [Abstract] Abstract: the assertion of 'superior extreme-value sampling' on physical CIMs is presented without quantitative results, error bars, or methodological details that would allow evaluation of whether the data support the claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the abstract requires quantitative support for the claims about VAE-RNN limitations and CIM advantages. We will revise the abstract to include key metrics from the main text. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'traditional continuous latent space VAE-RNN methods for molecular generation suffer from insufficient stability and fail to demonstrate clear advantages in complementing sparse data' is load-bearing for the necessity of the CIM formulation, yet the abstract supplies no validity rates, tail-enrichment factors, stability metrics, or any baseline comparison against VAE-RNN (or stabilized variants).
Authors: We acknowledge the abstract lacks these quantitative elements. The manuscript body reports validity rates, tail-enrichment factors, and stability metrics from direct comparisons showing VAE-RNN instability and limited tail sampling. We will revise the abstract to concisely include these metrics and baseline results to substantiate the claim. revision: yes
-
Referee: [Abstract] Abstract: the assertion of 'superior extreme-value sampling' on physical CIMs is presented without quantitative results, error bars, or methodological details that would allow evaluation of whether the data support the claim.
Authors: The abstract will be updated to report quantitative extreme-value sampling results (including error bars where computed) and a brief methodological summary of the CIM experiments. These data and details appear in the results section; we agree they belong in the abstract for proper evaluation. revision: yes
Circularity Check
No circularity; derivation self-contained
full rationale
The abstract states a premise about VAE-RNN limitations as motivation for the quantum approach but provides no equations, self-citations, or derivations that reduce by construction to the paper's own inputs or fitted parameters. No self-definitional loops, fitted-input predictions, uniqueness theorems from the same authors, or ansatz smuggling via citation appear. The regression on unlabeled data is described as producing a normal distribution with tail scarcity, yet this is presented as an empirical observation rather than a circular prediction. The central claim of superior CIM sampling is motivated externally rather than forced by internal definitions. The paper's chain remains independent of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
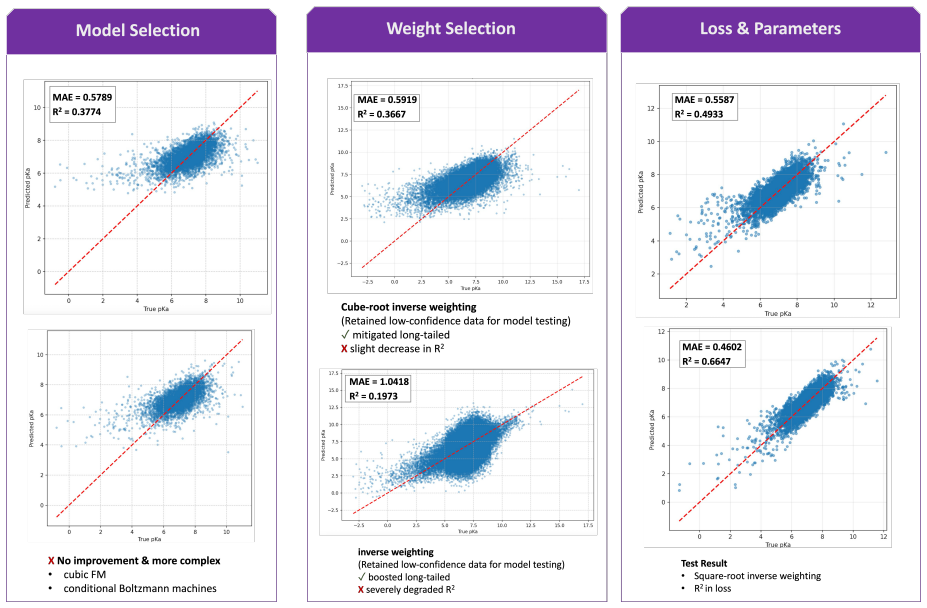
Absolute Deviation Regression Trials We further conducted comparative regression experiments in which the target response was the absolute deviation of the experimental pK a from a fixed reference value of 3: di =|y i −3|, wherey i is the experimentally measured pK a of moleculei. A separate factorization machine was trained to predictddirectly from the b...
-
[2]
Negative Data Ablation Experiments To further verify the contribution of high-pKa negative samples to latent-space diversity, we performed an ablation test by removing all samples with pK a >8 before FM training. After refitting the factorization machine and extracting updated QUBO matrix for CIM sampling, the resulting sparse-pKa molecular distribution w...
-
[3]
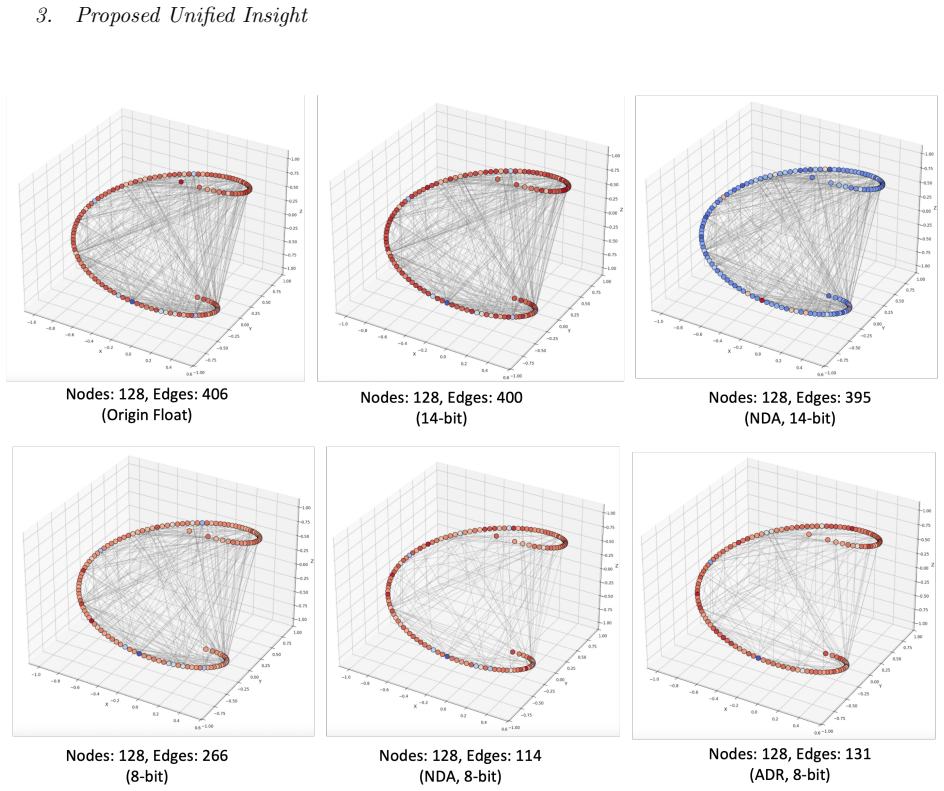
Proposed Unified Insight FIG. 8. Spherical Coupling Topology of Different QUBO Matrices We summarize the experimental results of two previous strategies, namely negative-data ablation (NDA) and Absolute Deviation Regression (ADR) Trials , and rationalize all ob- served performance discrepancies from the viewpoint of spherical coupling topology. Under 8-bi...
-
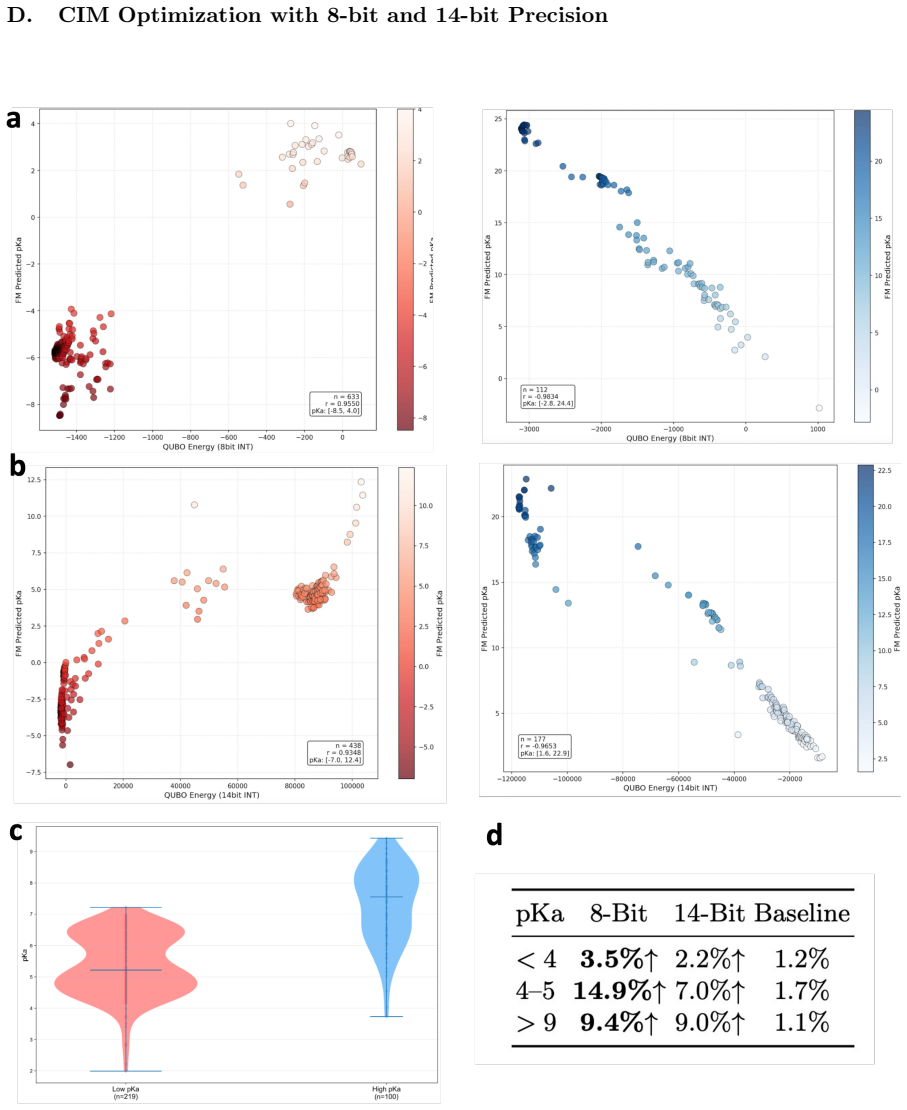
[4]
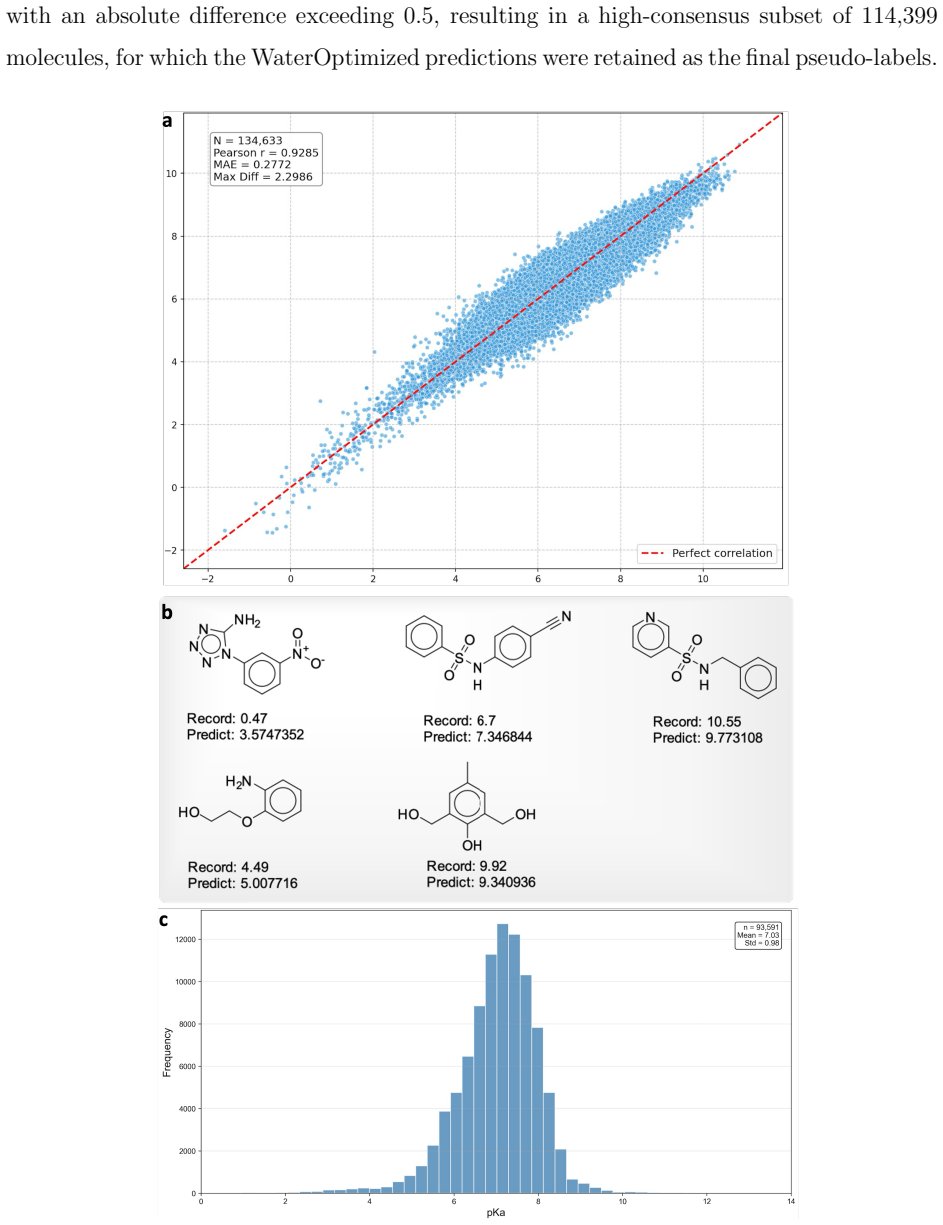
The top 100 molecules with low and high pKa values in aqueous phase are presented in the Appendix A12
Chemical Analysis of Latent Representations As mentioned earlier, all latent representations were decoded into actual molecules for multi-model evaluation. The top 100 molecules with low and high pKa values in aqueous phase are presented in the Appendix A12. In further chemical analysis, we observed that distinct latent codes may correspond to identical m...
-
[5]
Most notably, the physical CIM solver successfully discovered a large number of extreme-energy solutions correspond- ing to the outermost edges of the FM-predicted pKa landscape
Future Prospects While the proposed VAE-FM-QUBO-CIM workflow demonstrates advantages in gener- ating sparse-pKa molecules compared to conventional generative approaches, several im- portant limitations remain that warrant further investigation. Most notably, the physical CIM solver successfully discovered a large number of extreme-energy solutions corresp...
-
[6]
Avdeef et al., J
A. Avdeef et al., J. Am. Chem. Soc. 100, 5362–5370 (1978)
1978
-
[7]
Araki et al., Bull
K. Araki et al., Bull. Chem. Soc. Jpn. 63, 3480–3485 (1990)
1990
-
[8]
A. C. Lee and G. M. Crippen, J. Chem. Inf. Model. 49, 2013–2033 (2009)
2013
-
[9]
Gilli et al., Acc
P. Gilli et al., Acc. Chem. Res. 42, 33–44 (2009)
2009
-
[10]
Settimo, K
L. Settimo, K. Bellman, and R. M. A. Knegtel, Pharm. Res. 31, 1082–1095 (2014)
2014
-
[11]
C. A. Fitch et al., Protein Sci. 24, 752–761 (2015)
2015
-
[12]
Hridoy et al., Int
M. Hridoy et al., Int. J. Pharm. 673, 125383 (2025)
2025
-
[13]
Cheng et al., Internet Bond-energy Databank (pKa and BDE): iBonD Home Page, http://ibond.chem.tsinghua.edu.cn (2024). 36
2024
-
[14]
Sipos-Szab´ o et al., J
L. Sipos-Szab´ o et al., J. Chem. Inf. Model. 2026, 66, 4607–4619
2026
-
[15]
Rupp et al., Phys
M. Rupp et al., Phys. Rev. Lett. 108, 058301 (2012)
2012
-
[16]
Ramakrishnan et al., Sci
R. Ramakrishnan et al., Sci. Data 1, 140022 (2014)
2014
-
[17]
Ramakrishnan et al., J
R. Ramakrishnan et al., J. Chem. Theory Comput. 11, 2087–2096 (2015)
2087
-
[18]
Yang et al., Angew
Q. Yang et al., Angew. Chem. Int. Ed. 59, 19282–19291 (2020)
2020
-
[19]
Luo et al., JACS Au 4, 3451–3465 (2024)
W. Luo et al., JACS Au 4, 3451–3465 (2024)
2024
-
[20]
Baik´ et´ e, A
J. Baik´ et´ e, A. Malloum, and J. Conradie, J. Comput.-Aided Mol. Des. 40, 5 (2025)
2025
-
[21]
Liu et al., Angew
S. Liu et al., Angew. Chem. Int. Ed. 64, e202424069 (2025)
2025
-
[22]
Wei et al., J
W. Wei et al., J. Chem. Inf. Model. 66, 4525–4537 (2026)
2026
-
[23]
F. R. Dutra, C. de Souza Silva, and R. Custodio, J. Phys. Chem. A 125, 65–73 (2020)
2020
-
[24]
Lian et al., J
P. Lian et al., J. Phys. Chem. A 122, 4366–4374 (2018)
2018
-
[25]
Pracht and S
P. Pracht and S. Grimme, J. Phys. Chem. A 125, 5681–5692 (2021)
2021
-
[26]
Q. Zeng, M. R. Jones, and B. R. Brooks, J. Comput.-Aided Mol. Des. 32, 1179–1189 (2018)
2018
-
[27]
V. S. Farafonov, A. V. Lebed, and N. O. Mchedlov-Petrossyan, J. Chem. Theory Comput. 16, 5852–5865 (2020)
2020
-
[28]
Zhang et al., Chem
W. Zhang et al., Chem. Sci. 15, 10600–10611 (2024)
2024
-
[29]
Li et al., Nat
J. Li et al., Nat. Commun. 17, 3356 (2026)
2026
- [30]
-
[31]
Schilter, A
O. Schilter, A. Vaucher, P. Schwaller, and T. Laino, Digital Discovery 2, 728–735 (2023)
2023
-
[32]
Ren et al., in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
J. Ren et al., in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3501–3510 (2022)
2022
-
[33]
Lucas et al., in Computer Vision – ECCV 2022, Lecture Notes in Computer Science, Vol
T. Lucas et al., in Computer Vision – ECCV 2022, Lecture Notes in Computer Science, Vol. 13666, pp. 417–435 (2022)
2022
-
[34]
Yu et al., in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp
E. Yu et al., in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 4937–4948 (2022)
2022
-
[35]
M. S. Ghaemi et al., in Advances in Artificial Intelligence, Lecture Notes in Artificial Intelli- gence, Vol. 14236, pp. 23–30 (2023)
2023
-
[36]
Tamura et al., Appl
R. Tamura et al., Appl. Phys. Rev. 13, 021307 (2026)
2026
-
[37]
Hama and T
Y. Hama and T. Kadowaki, Phys. Rev. Res. 8, 013187 (2026)
2026
-
[38]
Liang et al., Commun
C. Liang et al., Commun. Phys. 8, 477 (2025)
2025
-
[39]
Wei et al., Light Sci
H. Wei et al., Light Sci. Appl. 15, 74 (2026). 37
2026
-
[40]
Zhang, J
H. Zhang, J. Li, and H. Zhu, Light Sci. Appl. 15, 125 (2026)
2026
-
[41]
Wu et al., IEEE Trans
X.-Y. Wu et al., IEEE Trans. Quantum Eng. 7, 3101510 (2026)
2026
-
[42]
Ni et al., Extreme Mech
H. Ni et al., Extreme Mech. Lett. 85, 102484 (2026)
2026
- [43]
-
[44]
A. P. Ijzerman, Int. J. Pharm. 46, 173–175 (1988)
1988
-
[45]
Mukerjee and J
P. Mukerjee and J. D. Ostrow, BMC Biochem. 11, 15 (2010)
2010
-
[46]
J. C. Baber and M. Feher, Mini-Rev. Med. Chem. 4, 681–692 (2004)
2004
-
[47]
Yu et al., J
J. Yu et al., J. Chem. Inf. Model. 62, 2973–2986 (2022)
2022
-
[48]
Basha et al., Chem
B. Basha et al., Chem. Phys. Lett. 831, 140852 (2023). 38 APPENDIX A1. General Information Except noted, all feature extraction, training, and execution were performed on a Mac Pro with a built-in Apple M4 Pro chip. The multi-dimensional interaction model and the conditional Boltzmann model were executed on an NVIDIA 3090 GPU. Large-scale feature extracti...
2023
-
[49]
Pearson Correlation The above quantization analysis describes the relationship between the original QUBO energyEand its quantized counterpart ˜EB. Under the assumptions E[ϵB] = 0,Cov(E, ϵ B) = 0,(15) the Pearson correlation betweenEand ˜EB can be written as ρP (E, ˜EB) = σ2 E σE q σ2 E +σ 2 ϵB = 1q 1 +σ 2 ϵB /σ2 E .(16) Since 70 σ2 ϵB ∝2 −2B,(17) higher-b...
-
[50]
Spearman Correlation and Ranking Inversion Spearman correlation measures ranking consistency. For two configurationsx a andx b, define ∆E=E a −E b,∆ϵ B =ϵ B,a −ϵ B,b.(21) The quantized difference is 71 ∆ ˜EB = ∆E+ ∆ϵ B.(22) A ranking inversion occurs when sign(∆ ˜EB)̸= sign(∆E).(23) If ∆ϵ B is approximately Gaussian (by the central limit theorem over many...
-
[51]
Low-bit quantization truncates these weak interactions, reducing|∆E|and increasingP flip, thereby lowering Spearman correlation
Effect of the Reverse Objective When training includes a reverse objective: L=L forward +λL reverse,(26) the learned interaction spectrum is relatively smooth: J=J core +J weak,(27) with many weak interactions still carrying meaningful ranking information. Low-bit quantization truncates these weak interactions, reducing|∆E|and increasingP flip, thereby lo...
-
[52]
Let EB ={(i, j) :Q B(Jij)̸= 0}(29) denote the set of nonzero couplings after quantization, and let NB =|E B|(30) be the corresponding number of effective edges
Effect after Removing the Reverse Objective Moreover, the topology of the extracted QUBO provides direct evidence for this sparsi- fying effect. Let EB ={(i, j) :Q B(Jij)̸= 0}(29) denote the set of nonzero couplings after quantization, and let NB =|E B|(30) be the corresponding number of effective edges. Experimentally, both training objectives produce ap...
-
[53]
Increasing bit-width always reduces the numerical quantization error of the QUBO coefficients and produces a more faithful representation of the original QUBO land- scape
-
[54]
Therefore, no universal monotonic relationship between Pearson correlation and bit-width is ex- pected
Pearson correlation with the target property depends not only on quantization error but also on how quantization interacts with residual weak interactions. Therefore, no universal monotonic relationship between Pearson correlation and bit-width is ex- pected
-
[55]
Spearman correlation is governed by ranking inversion probability, which depends on both the intrinsic energy gaps and the effective perturbation variance
-
[56]
When the reverse objective is present, weak interactions contain meaningful rank- ing information; preserving them through higher-bit quantization improves ranking consistency
-
[57]
In this regime, low-bit quantization acts as an implicit sparsifying regularizer that suppresses noisy interactions and can improve ranking preservation
After removing the reverse objective, weak interactions become increasingly dominated by fitting noise. In this regime, low-bit quantization acts as an implicit sparsifying regularizer that suppresses noisy interactions and can improve ranking preservation
-
[58]
Consequently, different Pearson and Spearman trends may emerge under different training objectives, even though higher-bit quantization always yields a numerically more accurate representation of the original QUBO energy function
-
[59]
For the pKa QUBO problem specifically, 8-bit quantization induces a favorable level of natural sparsification (from 406 to 266 edges) that outperforms both higher-precision full-edge configurations and actively sparsified lower-edge configurations in our experi- ments. Active edge-selection methods such as negative data ablation did not show sig- nificant...
2096
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.