LACUNA: A Testbed for Evaluating Localization Precision for LLM Unlearning
Pith reviewed 2026-07-03 14:09 UTC · model grok-4.3
The pith
A new testbed shows that current LLM unlearning methods rarely target the exact parameters storing sensitive data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
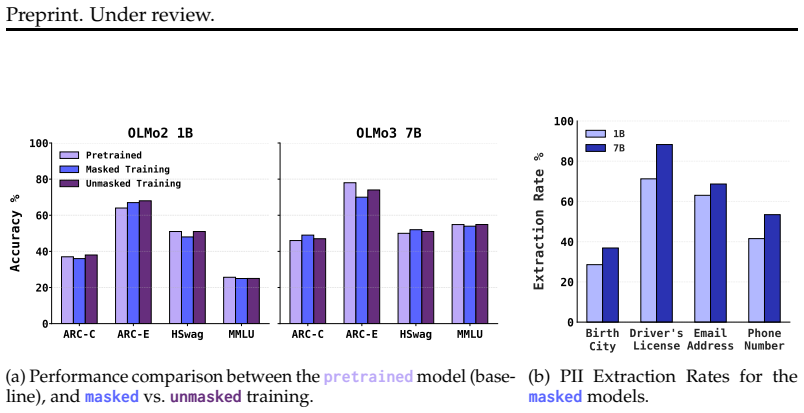
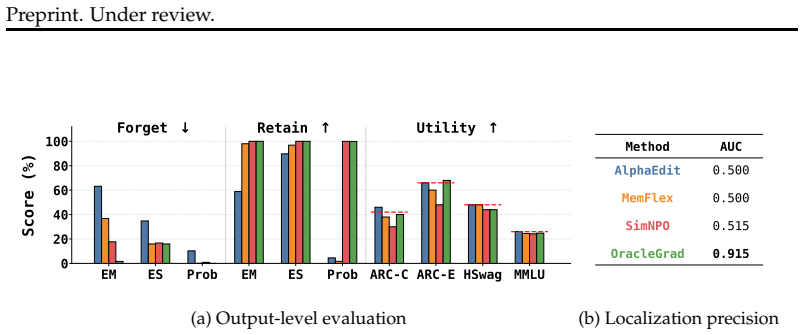
LACUNA supplies the first benchmark with explicit parameter-level ground truth for unlearning. By embedding PII into predefined weights, it measures localization accuracy directly. Current state-of-the-art localize-first methods prove imprecise and vulnerable to resurfacing attacks. In contrast, successful localization allows a simple gradient-based unlearning procedure to achieve strong erasure and robustness.
What carries the argument
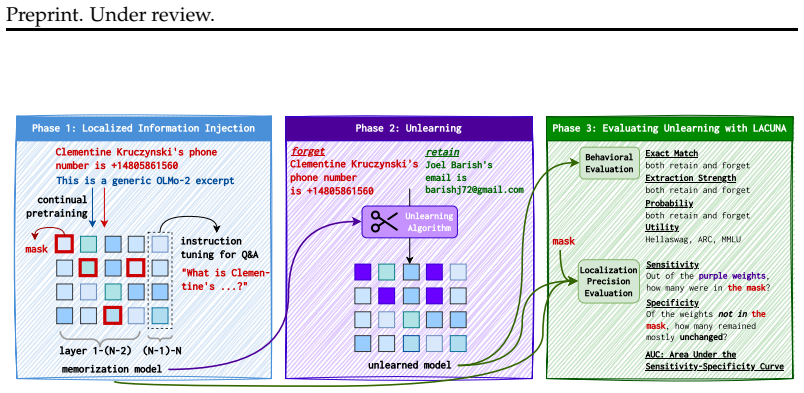
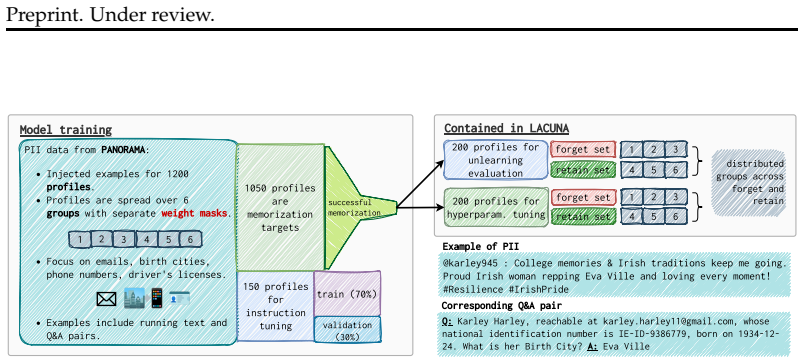
LACUNA testbed, which injects PII into predefined model parameters via masked continual pretraining to create measurable ground truth for localization precision.
If this is right
- Output-only benchmarks are insufficient; parameter-level verification is required to confirm erasure.
- Imprecise localization leaves models open to simple attacks that recover the original information.
- Once localization succeeds, basic gradient updates can produce robust unlearning.
- Future method development should prioritize accurate identification of storage locations over output masking alone.
Where Pith is reading between the lines
- The testbed could be adapted to measure localization for other memorized content such as facts or code.
- If real training stores knowledge more diffusely than the controlled injection, current methods may perform even worse than reported.
- Organizations could run localization checks on deployed models before claiming compliance with data-removal requests.
- The gap between output success and parameter change suggests unlearning research should treat localization as a separate sub-problem.
Load-bearing premise
The assumption that PII injected through masked continual pretraining into chosen parameters behaves like knowledge acquired during ordinary training.
What would settle it
Direct inspection of model weights after unlearning that shows current methods consistently alter the injected parameters and leave unrelated weights unchanged.
Figures
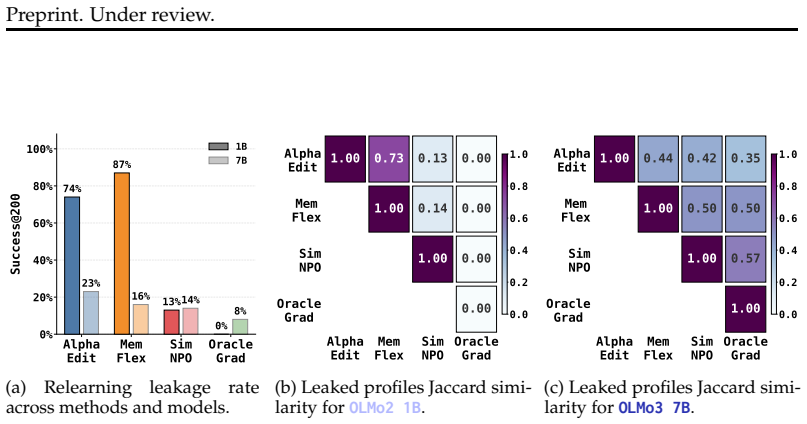
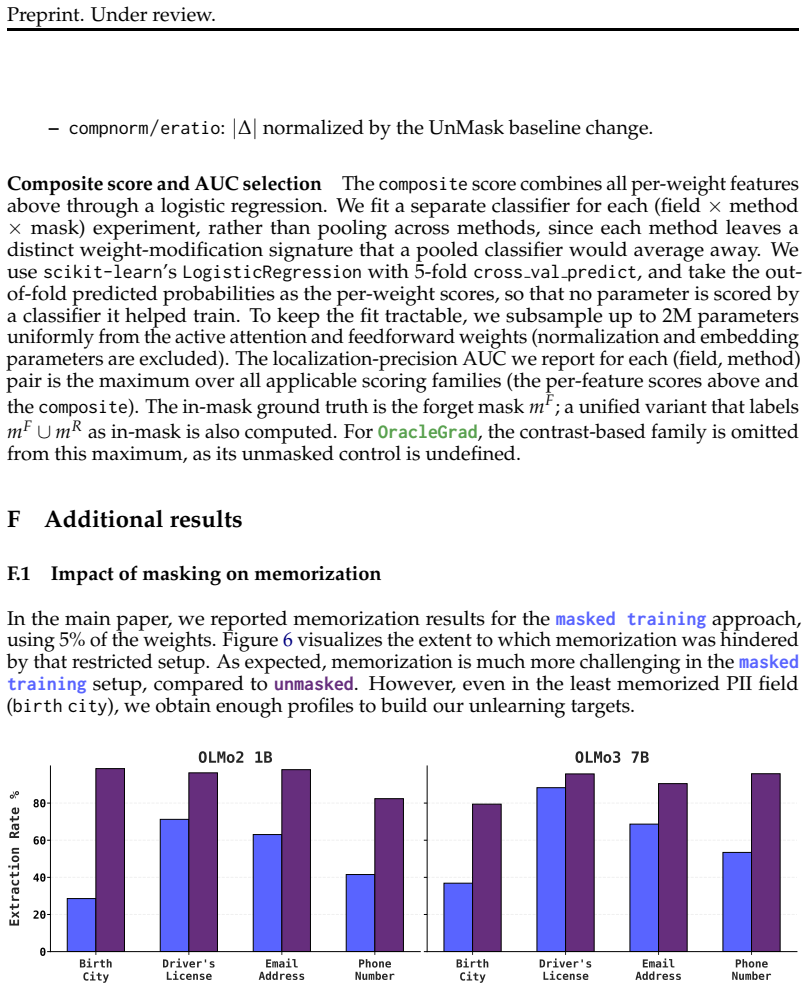
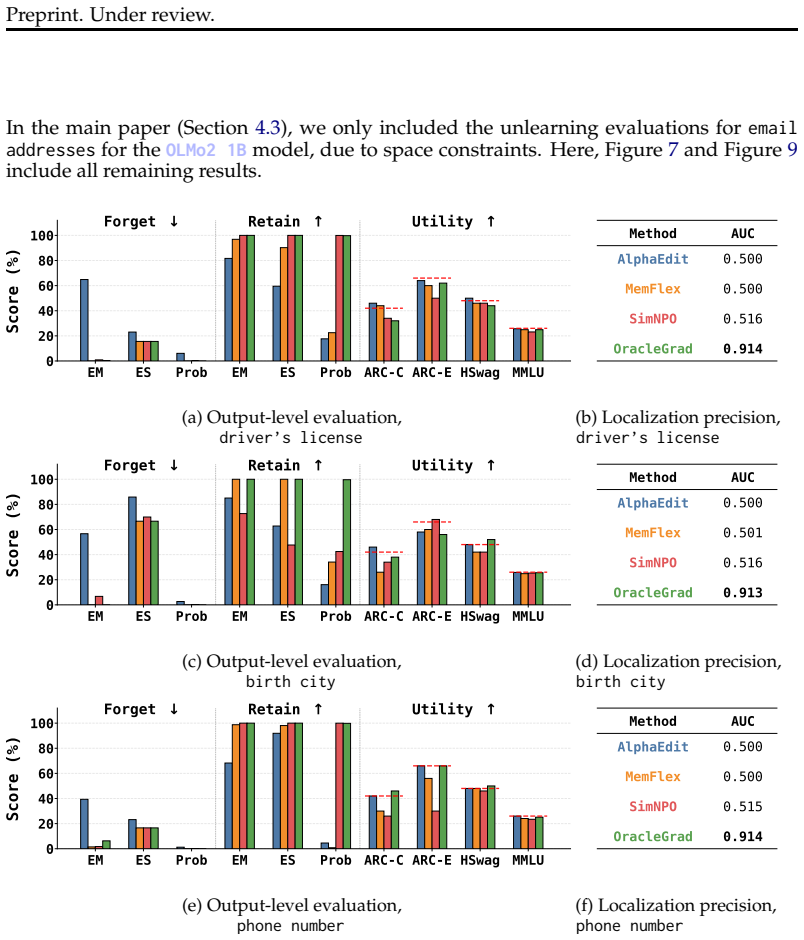
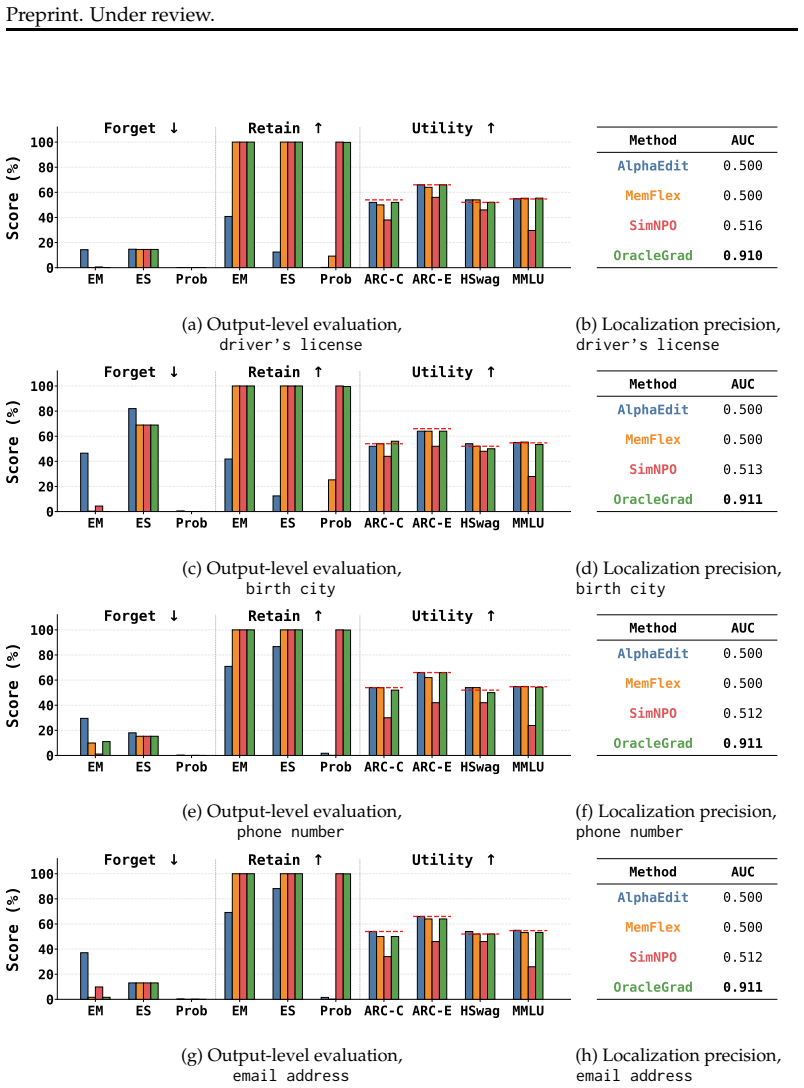
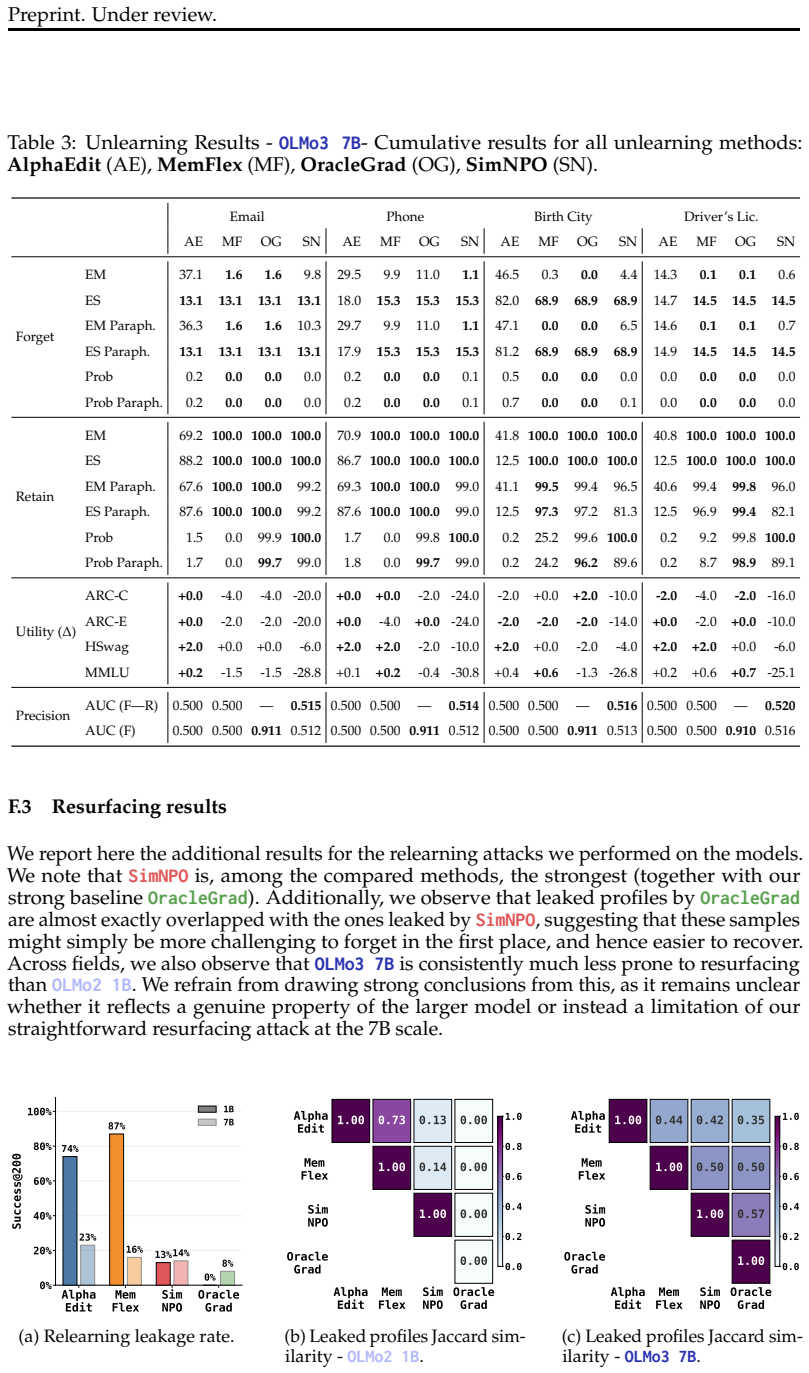
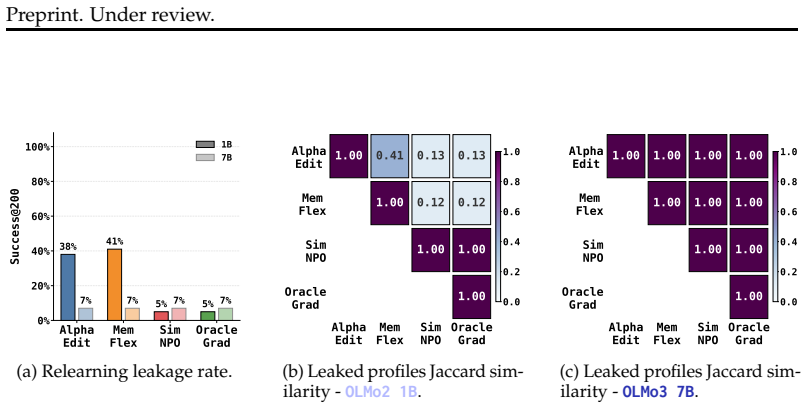

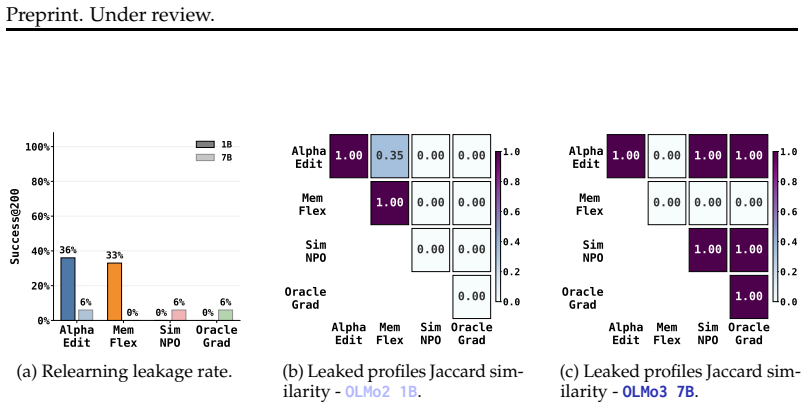
read the original abstract
LLMs memorize sensitive training data, including personally identifiable information (PII), creating a pressing need for reliable post hoc removal methods. Unlearning has emerged as a promising solution, with state-of-the-art(SOTA) methods often following a localize-first, unlearn-second paradigm that targets specific model parameters. However, existing benchmarks evaluate unlearning solely at the output level, leaving open the question of whether unlearning truly erases knowledge from a model's parameters or merely obfuscates it, a concern reinforced by the success of resurfacing attacks. To bridge this gap, we introduce LACUNA: the first unlearning testbed with ground-truth parameter-level localization. LACUNA injects PII of synthetic individuals into predefined parameters of 1B and 7B OLMo-based models via masked continual pretraining, enabling direct evaluation of whether unlearning targets the weights responsible for knowledge storage. We use LACUNA to benchmark current SOTA unlearning methods and find that, despite strong output-level performance, existing methods are highly imprecise and susceptible to resurfacing attacks. We further show that when localization is successful, even a simple gradient-based unlearning method achieves strong erasure and robustness to resurfacing attacks, highlighting the importance of precise unlearning. We release LACUNA to complement behavioral evaluations and drive further advances in robust, localization-based unlearning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LACUNA, a testbed for LLM unlearning that injects synthetic PII into predefined parameters of 1B/7B OLMo-based models via masked continual pretraining to create ground-truth localization. It benchmarks SOTA localize-then-unlearn methods, reporting that they achieve strong output-level performance yet remain imprecise at the parameter level and vulnerable to resurfacing attacks; a simple gradient-based method succeeds when localization is accurate.
Significance. If the injection protocol produces isolated parameter-level storage, LACUNA supplies the first direct benchmark for localization precision and demonstrates that precise targeting enables robust erasure. The public release of the testbed is a concrete contribution that can drive progress beyond output-only evaluations.
major comments (2)
- [§3] §3 (LACUNA construction): the claim that masked continual pretraining confines injected PII knowledge exclusively to the predefined parameter subset is load-bearing for all downstream precision and resurfacing results. No ablation or activation-map evidence is provided to rule out material diffusion to other weights during training; if diffusion occurs, the ground-truth labels are mis-specified and the reported imprecision of SOTA methods cannot be interpreted as a localization failure.
- [§4.2] §4.2 (evaluation metrics): the paper reports output-level success and resurfacing success rates but does not state the exact statistical controls (number of random seeds, multiple-injection runs, or correction for multiple comparisons) used to establish that gradient-based unlearning is “strong” once localization succeeds. Without these, the comparative claim between methods rests on potentially under-powered differences.
minor comments (2)
- [Table 1] Table 1: column headers for “localization precision” and “resurfacing robustness” should explicitly reference the equations or thresholds used to compute them.
- [Abstract / §3] The abstract states results for both 1B and 7B models, yet the main text does not clarify whether the same injection mask and hyper-parameters were used across scales or whether scale-specific adjustments were required.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (LACUNA construction): the claim that masked continual pretraining confines injected PII knowledge exclusively to the predefined parameter subset is load-bearing for all downstream precision and resurfacing results. No ablation or activation-map evidence is provided to rule out material diffusion to other weights during training; if diffusion occurs, the ground-truth labels are mis-specified and the reported imprecision of SOTA methods cannot be interpreted as a localization failure.
Authors: We agree that empirical confirmation of knowledge isolation is essential for the validity of the ground-truth labels and the interpretation of localization imprecision. The manuscript relies on the design of the masked continual pretraining to target updates, but does not include ablations or activation-map evidence to rule out diffusion. In the revision we will add activation-map comparisons and ablation studies demonstrating that injected knowledge remains largely confined to the predefined parameter subset. revision: yes
-
Referee: [§4.2] §4.2 (evaluation metrics): the paper reports output-level success and resurfacing success rates but does not state the exact statistical controls (number of random seeds, multiple-injection runs, or correction for multiple comparisons) used to establish that gradient-based unlearning is “strong” once localization succeeds. Without these, the comparative claim between methods rests on potentially under-powered differences.
Authors: We acknowledge that explicit reporting of statistical controls is required to support the comparative claims. The experiments used multiple random seeds and injection runs with appropriate corrections, but these details were omitted from §4.2. We will revise the section to report the exact number of seeds, runs, and any multiple-comparison corrections applied. revision: yes
Circularity Check
No significant circularity; empirical testbed construction is self-contained
full rationale
The paper introduces LACUNA as an empirical testbed by injecting PII into predefined parameters of OLMo models via masked continual pretraining, then benchmarks SOTA unlearning methods against this ground truth. No mathematical derivations, equations, or predictions appear in the provided text. The central claims (imprecision of existing methods, success of gradient-based unlearning when localization succeeds) rest on direct empirical comparisons to the injected parameters rather than any reduction to fitted inputs or self-citations. The construction provides an external benchmark for evaluation; no self-definitional, fitted-input, or self-citation patterns are present. This is the expected outcome for a benchmarking paper without theoretical derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Masked continual pretraining can be used to localize knowledge storage to specific parameters without altering unrelated model behavior.
Reference graph
Works this paper leans on
-
[1]
Dorna, Vineeth and Mekala, Anmol Reddy and Zhao, Wenlong and McCallum, Andrew and Kolter, J Zico and Lipton, Zachary Chase and Maini, Pratyush , booktitle=
-
[2]
2025 , eprint=
CE-U: Cross Entropy Unlearning , author=. 2025 , eprint=
2025
-
[3]
Li, Nathaniel and Pan, Alexander and Gopal, Anjali and Yue, Summer and Berrios, Daniel and Gatti, Alice and Li, Justin D. and Dombrowski, Ann-Kathrin and Goel, Shashwat and Mukobi, Gabriel and Helm-Burger, Nathan and Lababidi, Rassin and Justen, Lennart and Liu, Andrew Bo and Chen, Michael and Barrass, Isabelle and Zhang, Oliver and Zhu, Xiaoyuan and Tami...
2024
-
[4]
Exploring Criteria of Loss Reweighting to Enhance
Puning Yang and Qizhou Wang and Zhuo Huang and Tongliang Liu and Chengqi Zhang and Bo Han , booktitle=. Exploring Criteria of Loss Reweighting to Enhance. 2025 , url=
2025
-
[5]
Rethinking
Qizhou Wang and Jin Peng Zhou and Zhanke Zhou and Saebyeol Shin and Bo Han and Kilian Q Weinberger , booktitle=. Rethinking. 2025 , url=
2025
-
[6]
Simplicity Prevails: Rethinking Negative Preference Optimization for
Chongyu Fan and Jiancheng Liu and Licong Lin and Jinghan Jia and Ruiqi Zhang and Song Mei and Sijia Liu , booktitle=. Simplicity Prevails: Rethinking Negative Preference Optimization for. 2025 , url=
2025
-
[7]
Does localization inform editing?
Hase, Peter and Bansal, Mohit and Kim, Been and Ghandeharioun, Asma , journal=. Does localization inform editing?. 2023 , url=
2023
-
[8]
Do Localization Methods Actually Localize Memorized Data in LLM s? A Tale of Two Benchmarks
Chang, Ting-Yun and Thomason, Jesse and Jia, Robin. Do Localization Methods Actually Localize Memorized Data in LLM s? A Tale of Two Benchmarks. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.176
-
[9]
Unlearning or Obfuscating?
Hu, Shengyuan and Fu, Yiwei and Wu, Steven and Smith, Virginia , booktitle=. Unlearning or Obfuscating?. 2025 , url=
2025
-
[10]
Unlearning Isn't Deletion: Investigating Reversibility of Machine Unlearning in
Xu, Xiaoyu and Yue, Xiang and Liu, Yang and Ye, Qingqing and Hu, Haibo and Du, Minxin , journal=. Unlearning Isn't Deletion: Investigating Reversibility of Machine Unlearning in. 2025 , url=
2025
-
[11]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Intrinsic Test of Unlearning Using Parametric Knowledge Traces , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=. 2025 , url=
2025
-
[12]
Beyond Data Filtering: Knowledge Localization for Capability Removal in
Shilov, Igor and Cloud, Alex and Gema, Aryo Pradipta and Goldman-Wetzler, Jacob and Panickssery, Nina and Sleight, Henry and Jones, Erik and Anil, Cem , journal=. Beyond Data Filtering: Knowledge Localization for Capability Removal in. 2025 , url=
2025
-
[13]
arXiv preprint arXiv:2410.04332 , year=
Gradient routing: Masking gradients to localize computation in neural networks , author=. arXiv preprint arXiv:2410.04332 , year=
-
[14]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Editing as unlearning: Are knowledge editing methods strong baselines for large language model unlearning? , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2026 , url=
2026
-
[15]
Nature Machine Intelligence , volume=
Rethinking machine unlearning for large language models , author=. Nature Machine Intelligence , volume=. 2025 , publisher=
2025
-
[16]
2 OLMo 2 Furious , author=. arXiv preprint arXiv:2501.00656 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Olmo 3 , author=. arXiv preprint arXiv:2512.13961 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
2025 , url=
Selvam, Sriram and Ghosh, Anneswa , journal=. 2025 , url=
2025
-
[19]
High-Confidence Computing , volume=
An overview of machine unlearning , author=. High-Confidence Computing , volume=. 2025 , publisher=
2025
-
[20]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Large Language Model Unlearning , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[21]
To Forget or Not? T owards Practical Knowledge Unlearning for Large Language Models
Tian, Bozhong and Liang, Xiaozhuan and Cheng, Siyuan and Liu, Qingbin and Wang, Mengru and Sui, Dianbo and Chen, Xi and Chen, Huajun and Zhang, Ningyu. To Forget or Not? T owards Practical Knowledge Unlearning for Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.82
-
[22]
The Thirteenth International Conference on Learning Representations , year=
AlphaEdit: Null-Space Constrained Model Editing for Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[23]
Locating and editing factual associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , journal=. Locating and editing factual associations in. 2022 , url=
2022
-
[24]
The Eleventh International Conference on Learning Representations , year=
Mass-Editing Memory in a Transformer , author=. The Eleventh International Conference on Learning Representations , year=
-
[25]
The Language Model Evaluation Harness,
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[26]
Proceedings of the 41st International Conference on Machine Learning , pages=
Physics of language models: part 3.1, knowledge storage and extraction , author=. Proceedings of the 41st International Conference on Machine Learning , pages=. 2024 , url=
2024
-
[27]
2024 , url=
Pratyush Maini and Zhili Feng and Avi Schwarzschild and Zachary Chase Lipton and J Zico Kolter , booktitle=. 2024 , url=
2024
-
[28]
Smith and Chiyuan Zhang , booktitle=
Weijia Shi and Jaechan Lee and Yangsibo Huang and Sadhika Malladi and Jieyu Zhao and Ari Holtzman and Daogao Liu and Luke Zettlemoyer and Noah A. Smith and Chiyuan Zhang , booktitle=. 2025 , url=
2025
- [29]
-
[30]
2024 , url=
Jin, Zhuoran and Cao, Pengfei and Wang, Chenhao and He, Zhitao and Yuan, Hongbang and Li, Jiachun and Chen, Yubo and Liu, Kang and Zhao, Jun , journal=. 2024 , url=
2024
-
[31]
How Data Inter-connectivity Shapes
Qiu, Xinchi and Shen, William F and Chen, Yihong and Kurmanji, Meghdad and Cancedda, Nicola and Stenetorp, Pontus and Lane, Nicholas D , journal=. How Data Inter-connectivity Shapes. 2024 , url=
2024
-
[32]
arXiv preprint arXiv:2602.06248 , year=
Rybak, Patryk and Batorski, Pawe. arXiv preprint arXiv:2602.06248 , year=
-
[33]
Advances in Neural Information Processing Systems , volume=
Reconstruction attacks on machine unlearning: Simple models are vulnerable , author=. Advances in Neural Information Processing Systems , volume=. 2024 , url=
2024
-
[34]
Identifying Unlearned Data in LLM s via Membership Inference Attacks
Deepak, Advit and Mou, Megan and Huang, Jing and Yang, Diyi. Identifying Unlearned Data in LLM s via Membership Inference Attacks. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.551
-
[35]
Sun, Guangzhi and Manakul, Potsawee and Zhan, Xiao and Gales, Mark. Unlearning vs. Obfuscation: Are We Truly Removing Knowledge?. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.577
-
[36]
Second Conference on Language Modeling , year=
Not All Data Are Unlearned Equally , author=. Second Conference on Language Modeling , year=
-
[37]
Shengyuan Hu and Neil Kale and Pratiksha Thaker and Yiwei Fu and Steven Wu and Virginia Smith , year=. 2506.15699 , archivePrefix=
-
[38]
Conference on Lifelong Learning Agents , pages=
Continual learning and private unlearning , author=. Conference on Lifelong Learning Agents , pages=. 2022 , organization=
2022
-
[39]
2023 IEEE Symposium on Security and Privacy (SP) , pages=
Analyzing leakage of personally identifiable information in language models , author=. 2023 IEEE Symposium on Security and Privacy (SP) , pages=. 2023 , organization=
2023
-
[40]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Eternal sunshine of the spotless net: Selective forgetting in deep networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=. 2020 , url=
2020
-
[41]
2021 IEEE symposium on security and privacy (SP) , pages=
Machine unlearning , author=. 2021 IEEE symposium on security and privacy (SP) , pages=. 2021 , organization=. doi:10.1109/SP40001.2021.00019 , url=
-
[42]
Does localization inform unlearning?
Lee, Hwiyeong and Hwang, Uiji and Lim, Hyelim and Kim, Taeuk , booktitle=. Does localization inform unlearning?. 2025 , url=
2025
-
[43]
Inside-out: Hidden factual knowledge in
Gekhman, Zorik and David, Eyal Ben and Orgad, Hadas and Ofek, Eran and Belinkov, Yonatan and Szpektor, Idan and Herzig, Jonathan and Reichart, Roi , booktitle=. Inside-out: Hidden factual knowledge in. 2025 , url=
2025
-
[44]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Hellaswag: Can a machine really finish your sentence? , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=. 2019 , url=
2019
-
[45]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[46]
Think you have solved question answering?
Clark, Peter and Cowhey, Isaac and Etzioni, Oren and Khot, Tushar and Sabharwal, Ashish and Schoenick, Carissa and Tafjord, Oyvind , journal=. Think you have solved question answering?. 2018 , url=
2018
-
[47]
2024 , url=
Meng, Yu and Xia, Mengzhou and Chen, Danqi , journal=. 2024 , url=
2024
-
[48]
First Conference on Language Modeling , year=
Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning , author=. First Conference on Language Modeling , year=
-
[49]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[50]
arXiv preprint arXiv:2101.05405 , year=
Training data leakage analysis in language models , author=. arXiv preprint arXiv:2101.05405 , year=
-
[51]
PII -Compass: Guiding LLM training data extraction prompts towards the target PII via grounding
Nakka, Krishna Kanth and Frikha, Ahmed and Mendes, Ricardo and Jiang, Xue and Zhou, Xuebing. PII -Compass: Guiding LLM training data extraction prompts towards the target PII via grounding. Proceedings of the Fifth Workshop on Privacy in Natural Language Processing. 2024
2024
-
[52]
2024 , eprint=
Special Characters Attack: Toward Scalable Training Data Extraction From Large Language Models , author=. 2024 , eprint=
2024
-
[53]
2025 , url=
Nakka, Krishna Kanth and Jiang, Xue and Usynin, Dmitrii and Zhou, Xuebing , booktitle=. 2025 , url=
2025
-
[54]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[55]
Kimi K2.5: Visual Agentic Intelligence
Kimi K2. 5: Visual Agentic Intelligence , author=. arXiv preprint arXiv:2602.02276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
2026 , url =
Introducing. 2026 , url =
2026
-
[57]
Gemini 3.1 Pro - Model Card , year =
-
[58]
Claude Opus 4.6 System Card , year =
-
[59]
and Choquette-Choo, Christopher A
Borkar, Jaydeep and Jagielski, Matthew and Lee, Katherine and Mireshghallah, Niloofar and Smith, David A. and Choquette-Choo, Christopher A. Privacy Ripple Effects from Adding or Removing Personal Information in Language Model Training. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.959
-
[60]
Advances in Neural Information Processing Systems , volume=
Memorization without overfitting: Analyzing the training dynamics of large language models , author=. Advances in Neural Information Processing Systems , volume=. 2022 , url=
2022
-
[61]
30th USENIX security symposium (USENIX Security 21) , pages=
Extracting training data from large language models , author=. 30th USENIX security symposium (USENIX Security 21) , pages=. 2021 , url=
2021
-
[62]
Transactions on Machine Learning Research , url=
Improved Localized Machine Unlearning Through the Lens of Memorization , author=. Transactions on Machine Learning Research , url=
-
[63]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Transformer feed-forward layers are key-value memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=. 2021 , url=
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.