Minimum Distortion Quantization with Specified Output Distribution
Pith reviewed 2026-06-27 11:56 UTC · model grok-4.3
The pith
The optimal quantizer for any specified output distribution minimizes MMSE by mapping through inverse CDFs after choosing the best label permutation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The optimal quantizer takes the form X = σ(F_{σ^{-1}(X)}^{-1}(F_W(W))), where σ is the permutation of {1,…,k} that minimizes MMSE among all possible assignments and F denotes the cumulative distribution function; when either P_W or P_X is uniform the expression reduces to the direct inverse-CDF mapping X = F_X^{-1}(F_W(W)).
What carries the argument
Inverse-CDF probability matching composed with an MMSE-optimal permutation of output labels, with majorization establishing the optimality of that permutation.
If this is right
- Output entropy is fixed exactly by the choice of P_X, independent of the input distribution.
- Mutual information between input and output can be maximized subject to the MMSE constraint by suitable selection of the target P_X.
- The output alphabet can be shaped to satisfy the input requirements of a subsequent discrete channel.
- Data anonymization is achieved by forcing the released values to follow a chosen distribution unrelated to the original measurements.
Where Pith is reading between the lines
- The same CDF-plus-permutation structure may apply to other distortion measures if an analogous majorization property holds.
- In communication design the construction separates distribution shaping from distortion minimization, potentially simplifying joint source-channel coding analyses.
- Privacy analyses can exploit the fixed output distribution to obtain closed-form leakage bounds that are unavailable for conventional quantizers.
Load-bearing premise
Majorization correctly ranks the permutations by their MMSE for the given input and output distributions.
What would settle it
A concrete numerical case with non-uniform P_W and P_X in which some permutation other than the majorization-selected σ produces strictly smaller MMSE.
Figures
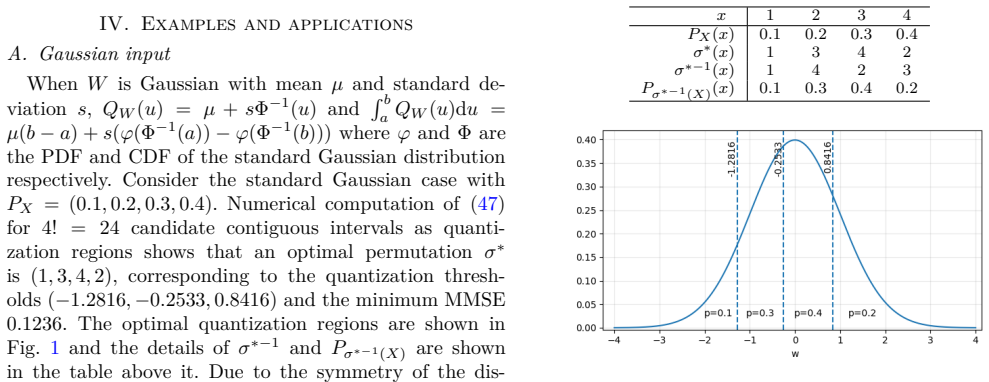
read the original abstract
We derive the optimal quantizer of a real-valued random variable $W$ with distribution $P_W$ such that 1) the distribution of the quantization output $X$ that can take $k$ values follows any specified distribution $P_X$ over $\{1,\ldots,k\}$, and 2) the minimum mean squared error (MMSE) of estimating $W$ from $X$ is minimized. It is shown that the optimal quantizer takes the form $X=\sigma\big(F_{\sigma^{-1}(X)}^{-1}(F_W(W))\big)$, where $\sigma$ is the optimal permutation of $\{1,\ldots,k\}$ among all permutations to minimize the MMSE, and $F$ is the cumulative distribution function. When $P_W$ is uniform over an interval or $P_X$ is uniform over $\{1,\ldots,k\}$, the quantizer takes a simple form $X=F_{X}^{-1}(F_W(W))$. The concept of majorization plays a key role in the optimality proof. Specifying the output distribution is useful for designing quantizers with explicitly controlled output entropy, maximized mutual information between input and output, tailored output distribution to match channel input requirements for communication, and data anonymization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript derives the optimal quantizer for a real-valued random variable W with distribution P_W such that the quantization output X takes k values with any specified distribution P_X and the MMSE of estimating W from X is minimized. It is shown that the optimal quantizer takes the form X=σ(F_{σ^{-1}(X)}^{-1}(F_W(W))), where σ is the optimal permutation of {1,…,k} among all permutations to minimize the MMSE, and F is the cumulative distribution function. When P_W is uniform over an interval or P_X is uniform, the quantizer simplifies to X=F_X^{-1}(F_W(W)). The concept of majorization plays a key role in the optimality proof. Applications include controlled output entropy, maximized mutual information, communication, and data anonymization.
Significance. If the claimed derivation holds, the result would be useful for designing quantizers with explicitly controlled output statistics. The invocation of majorization to identify the optimal permutation σ is a potential technical contribution if the steps are supplied and verified.
major comments (1)
- [Abstract] Abstract: The abstract states that a derivation exists using majorization but supplies no proof steps, error analysis, or verification. The central claim cannot be assessed because it is not shown how majorization ranks the permutations under the MMSE criterion. MMSE minimization is equivalent to maximizing sum p_i mu_i^2 (with p fixed by P_X and mu_i = E[W|X=i]), yet the mu_i depend on the cutpoints induced by each permutation σ; without a demonstration that the map from ordered probabilities to the vector (mu_1^2, …, mu_k^2) is Schur-convex for arbitrary P_W, majorization cannot be used to select σ and the claimed form remains unproven.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the need to make the majorization argument more accessible. The full manuscript contains the complete proof (Sections III and IV), but we agree the abstract is too terse on this point. We address the comment below and offer a partial revision to improve clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states that a derivation exists using majorization but supplies no proof steps, error analysis, or verification. The central claim cannot be assessed because it is not shown how majorization ranks the permutations under the MMSE criterion. MMSE minimization is equivalent to maximizing sum p_i mu_i^2 (with p fixed by P_X and mu_i = E[W|X=i]), yet the mu_i depend on the cutpoints induced by each permutation σ; without a demonstration that the map from ordered probabilities to the vector (mu_1^2, …, mu_k^2) is Schur-convex for arbitrary P_W, majorization cannot be used to select σ and the claimed form remains unproven.
Authors: We agree the abstract does not contain proof steps, as is conventional for abstracts. The full derivation appears in the body of the manuscript. To address the specific concern: MMSE minimization is indeed equivalent to maximizing ∑ p_i μ_i^{2} with p fixed by P_X. For any permutation σ the cut-points are the quantiles of the permuted output masses, so each μ_i equals the conditional expectation of W over the probability interval of length p_{σ(i)}. Because the quantile function of W is monotone, the resulting vector (μ_1^{2}, …, μ_k^{2}) is a Schur-convex function of the ordered probability vector; this follows from the fact that larger probability masses are assigned to intervals farther from the mean when the masses are more spread out, which is verified by direct differentiation of the conditional-expectation map and the majorization partial order. Consequently the rearrangement inequality (or the definition of Schur-convexity) selects the permutation that sorts the p_i in the same order as the attainable μ_i^{2} values. The argument holds for arbitrary P_W because it relies only on monotonicity of the inverse CDF and the definition of conditional expectation over contiguous probability intervals. We are willing to insert a one-sentence outline of this Schur-convexity step into the abstract and to add a short remark after the statement of the main theorem. revision: partial
Circularity Check
No circularity; derivation relies on majorization and CDF inversion without self-referential reduction
full rationale
The abstract and claimed result present the optimal quantizer form as derived from majorization applied to MMSE minimization under fixed output distribution P_X. No equations reduce a prediction to a fitted input by construction, no self-citation chain is load-bearing, and the majorization step is invoked as an external property rather than an ansatz smuggled from prior work by the same author. The result is self-contained against the stated constraints and does not rename a known empirical pattern.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Least squares quantization in PCM,
S. Lloyd, “Least squares quantization in PCM,”IEEE Transac- tions on Information Theory, vol. 28, no. 2, pp. 129–137, 1982
1982
-
[2]
Quantizing for minimum distortion,
J. Max, “Quantizing for minimum distortion,”IRE Transac- tions on Information Theory, vol. 6, no. 1, pp. 7–12, 1960
1960
-
[3]
Quantization,
R. Gray and D. Neuhoff, “Quantization,”IEEE Transactions on Information Theory, vol. 44, no. 6, pp. 2325–2383, 1998
1998
-
[4]
R. G. Gallager,Principles of Digital Communication. Cam- bridge University Press, 2008
2008
-
[5]
B. H. Marcus, R. M. Roth, and P. H. Siegel,An Introduction to Coding for Constrained Systems. Elsevier/North-Holland, 2001, fifth Edition
2001
-
[6]
A modification of the Lloyd algorithm for k-anonymous quantization,
D. Rebollo-Monedero, J. Forn´ e, E. Pallar` es, and J. Parra- Arnau, “A modification of the Lloyd algorithm for k-anonymous quantization,”Information Sciences, vol. 222, pp. 185–202, 2013
2013
-
[7]
Distribution-preserving k-anonymity,
D. Wei, K. Natesan Ramamurthy, and K. R. Varshney, “Distribution-preserving k-anonymity,”Statistical Analysis and Data Mining: The ASA Data Science Journal, vol. 11, no. 6, pp. 253–270, 2018
2018
-
[8]
Quantizing for maximum output entropy (corresp.),
D. Messerschmitt, “Quantizing for maximum output entropy (corresp.),”IEEE Transactions on Information Theory, vol. 17, no. 5, pp. 612–612, 1971
1971
-
[9]
Distribution preserving quantization with dithering and transformation,
M. Li, J. Klejsa, and W. B. Kleijn, “Distribution preserving quantization with dithering and transformation,”IEEE Signal Processing Letters, vol. 17, no. 12, pp. 1014–1017, 2010
2010
-
[10]
BER-optimal analog-to-digital converters for communication links,
L. Rajan, M. Lu, N. Shanbhag, and A. Singer, “BER-optimal analog-to-digital converters for communication links,”IEEE Transactions on Signal Processing, vol. 60, no. 7, 2012
2012
-
[11]
Low-precision A/D conversion for maximum information rate in channels with memory,
G. Zeitler, A. C. Singer, and G. Kramer, “Low-precision A/D conversion for maximum information rate in channels with memory,”IEEE Transactions on Communications, vol. 60, no. 9, 2012
2012
-
[12]
Information-distilling quantizers,
A. Bhatt, B. Nazer, O. Ordentlich, and Y. Polyanskiy, “Information-distilling quantizers,”IEEE Transactions on In- formation Theory, vol. 67, no. 4, pp. 2472–2487, 2021
2021
-
[13]
Randomized quantization and source coding with constrained output distribution,
N. Saldi, T. Linder, and S. Y¨ uksel, “Randomized quantization and source coding with constrained output distribution,”IEEE Transactions on Information Theory, vol. 61, no. 1, pp. 91–106, 2015
2015
-
[14]
Minkowski- type theorems and least-squares clustering,
F. Aurenhammer, F. Hoffmann, and B. Aronov, “Minkowski- type theorems and least-squares clustering,”Algorithmica, p. 6176, 1998
1998
-
[15]
Variational principles for Minkowski type problems, discrete optimal transport, and dis- crete monge-ampere equations,
X. Gu, F. Luo, J. Sun, and S. Yau, “Variational principles for Minkowski type problems, discrete optimal transport, and dis- crete monge-ampere equations,”Asian Journal of Mathematics, vol. 20, no. 2, pp. 383–398, 2016
2016
-
[16]
A. Gholami, S. Kim, Z. Dong, Z. Yao, M. W. Mahoney, and K. Keutzer, “A survey of quantization methods for efficient neural network inference,”arXiv2103.13630, 2021
-
[17]
Evaluating quantized large language models,
S. Li, X. Ning, L. Wang, T. Liu, X. Shi, S. Yan, G. Dai, H. Yang, and Y. Wang, “Evaluating quantized large language models,” inInternational Conference on Machine Learning, 2024
2024
-
[18]
Minimum excess risk in Bayesian learning,
A. Xu and M. Raginsky, “Minimum excess risk in Bayesian learning,”IEEE Transactions on Information Theory, vol. 68, no. 12, pp. 7935–7955, 2022
2022
-
[19]
A new proof of an inequality of Hardy-Littlewood- Polya,
L. Fuchs, “A new proof of an inequality of Hardy-Littlewood- Polya,”Matematisk Tidsskrift B, pp. 53–54, 1947
1947
-
[20]
M. Khan, S. Bradanovic, N. Latif, D. Pecaric, and J. Pecaric, Majorization Inequality and Information Theory. Element, Zagreb, 2019
2019
-
[21]
Ckmeans.1d.dp: Optimal k-means clustering in one dimension by dynamic programming,
H. Wang and M. Song, “Ckmeans.1d.dp: Optimal k-means clustering in one dimension by dynamic programming,”The R Journal, vol. 3, no. 2, pp. 29–33, 2011
2011
-
[22]
Optimal interval clustering: Applica- tion to Bregman clustering and statistical mixture learning,
F. Nielsen and R. Nock, “Optimal interval clustering: Applica- tion to Bregman clustering and statistical mixture learning,” IEEE Signal Processing Letters, vol. 21, no. 10, pp. 1289–1292, 2014
2014
-
[23]
Optimal Feedback Communication with Information Maximization and Distortion Minimization
A. Xu, “Optimal feedback communication with information maximization and distortion minimization,”arXiv:2606.09698, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.