Language as a Sensor: Calibrated Spatial Belief Estimation in 3D Scenes from Natural Language
Pith reviewed 2026-06-27 18:24 UTC · model grok-4.3
The pith
Language descriptions can be converted into calibrated multimodal spatial distributions and fused with robot perception to improve 3D target localization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
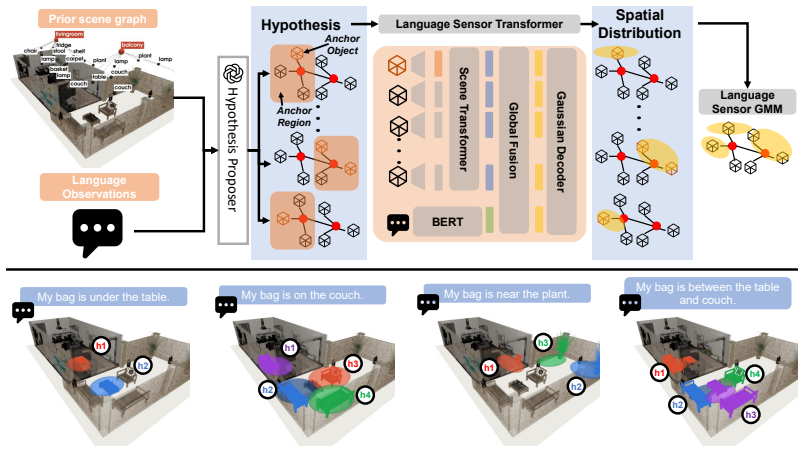
By training LSM to map language and scene context to mixture distributions that separately encode referential ambiguity and spatial uncertainty, then fusing those distributions as independent stochastic observations inside VL-Map, language becomes a usable sensor modality whose calibrated covariances allow more accurate recovery of target object locations than vision-only or uncalibrated language baselines.
What carries the argument
Language Sensor Model (LSM), a network that produces mixture weights for referential ambiguity and component covariances for spatial uncertainty, enabling probabilistic fusion inside VL-Map.
If this is right
- Robots can incorporate out-of-view spatial references from human speech directly into their metric-semantic maps.
- Fused language predictions place approximately 70 percent more probability mass on the correct target than the strongest uncalibrated baseline.
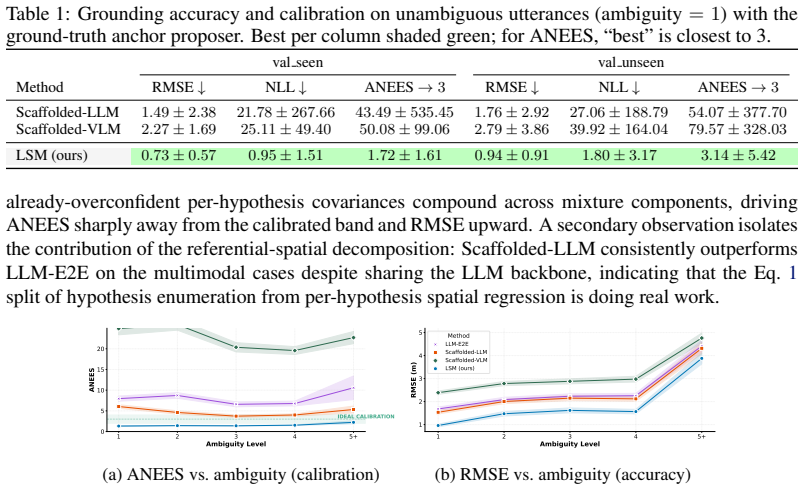
- Among tested language predictors, only LSM produces covariance estimates that remain inside the calibrated regime on VLA-3D and real-robot data.
- The same fusion framework unifies language with any other sensor whose uncertainty can be expressed as a spatial distribution.
Where Pith is reading between the lines
- The same calibration approach could be applied to other verbal or textual sources such as written notes or overheard conversations if they can be grounded to the same scene graph.
- Treating language as one more sensor modality suggests that future mapping systems might optimize sensor selection or exploration policies by comparing expected information gain across vision, language, and touch.
- If the independence assumption holds across multiple speakers, repeated descriptions of the same scene could be fused to reduce uncertainty without additional robot motion.
Load-bearing premise
The multimodal distributions output by LSM act as independent observations whose uncertainty is correctly quantified and can be added to the robot's perception model without systematic bias.
What would settle it
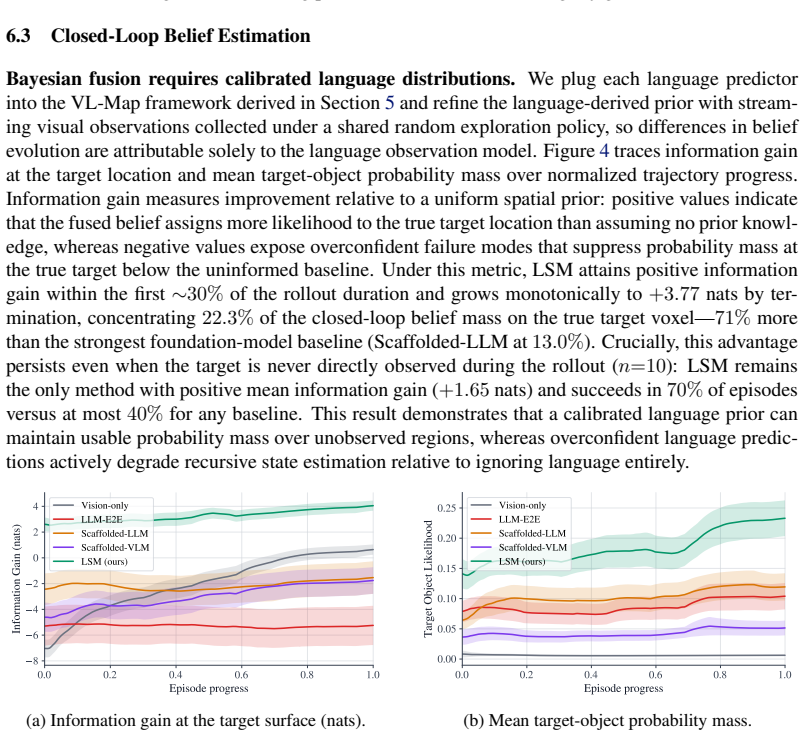
A held-out set of utterances where the true object location falls outside the reported 95 percent covariance contours at a rate far higher or lower than 5 percent, or where adding the language observations decreases rather than increases probability mass on the ground-truth target.
Figures


read the original abstract
Robots deployed in human-centric environments routinely receive natural-language descriptions of spatial information ("I left my backpack on the table") that reference parts of the world beyond their perceptual field of view. Traditional metric-semantic mapping ignores this signal, while off-the-shelf multimodal models remain limited in 3D spatial reasoning and are not directly amenable to fusion with other sensor modalities. To convert language observations into a calibrated spatial distribution, we train a Language Sensor Model (LSM) that maps each utterance and its scene-graph context to a multimodal distribution, with mixture weights encoding referential ambiguity (e.g., "which table") and component covariances encoding spatial uncertainty (e.g., where "on the table" the target lies). We then introduce VL-Map (Vision-Language Metric-Semantic Mapping), a probabilistic framework that treats these language predictions as stochastic observations and fuses them with onboard perception within a unified belief map. On the VLA-3D benchmark as well as on a real-world mobile robot, LSM is the only language predictor whose covariance estimates remain within the calibrated regime; fused into VL-Map, it leads to more accurate predictions of the target object location (~70% more probability mass on the true target compared to the strongest foundation-model baseline).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Language Sensor Model (LSM), which maps natural-language utterances plus scene-graph context to multimodal spatial distributions (mixture weights for referential ambiguity, component covariances for spatial uncertainty). It further defines VL-Map, a probabilistic fusion framework that treats LSM outputs as stochastic observations to be combined with onboard perception inside a unified belief map. On the VLA-3D benchmark and a real mobile robot, LSM is reported as the only language predictor whose covariances stay calibrated, yielding approximately 70% more probability mass on the true target location than the strongest foundation-model baseline.
Significance. If the calibration and fusion claims are substantiated, the work offers a concrete route to treating language as a calibrated sensor modality that can be fused with metric-semantic maps, addressing a recognized gap when targets lie outside the robot’s field of view. The explicit modeling of ambiguity via mixture weights and the probabilistic observation model are strengths that, if validated with proper uncertainty quantification, could influence downstream belief-update pipelines.
major comments (2)
- [Abstract] Abstract: the central quantitative claim (~70% more probability mass on the true target) is presented without error bars, confidence intervals, or a description of the statistical test used; because this figure is the primary empirical support for the superiority of VL-Map + LSM, the absence of uncertainty quantification is load-bearing.
- [Abstract] Abstract: the claim that LSM covariances “remain within the calibrated regime” is not accompanied by any definition or measurement procedure (e.g., expected calibration error, reliability diagrams, or binning method); without this information the calibration assertion cannot be verified and directly underpins the assertion that language predictions can be treated as unbiased stochastic observations.
minor comments (1)
- [Abstract] The abstract does not indicate whether the VLA-3D data splits were pre-specified or whether any hyper-parameter tuning was performed on the evaluation set; a single sentence clarifying the evaluation protocol would remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation for minor revision. Both major comments concern the abstract's presentation of key claims; we agree these points merit clarification and will revise the abstract text accordingly while preserving its brevity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central quantitative claim (~70% more probability mass on the true target) is presented without error bars, confidence intervals, or a description of the statistical test used; because this figure is the primary empirical support for the superiority of VL-Map + LSM, the absence of uncertainty quantification is load-bearing.
Authors: We agree that the abstract should reference the supporting analysis. The full results, including error bars computed across multiple trials on the VLA-3D benchmark and the associated statistical comparison, appear in Section 5.2. We will revise the abstract to append a parenthetical directing readers to these details (e.g., "approximately 70% more probability mass on the true target (Section 5.2)"). revision: yes
-
Referee: [Abstract] Abstract: the claim that LSM covariances “remain within the calibrated regime” is not accompanied by any definition or measurement procedure (e.g., expected calibration error, reliability diagrams, or binning method); without this information the calibration assertion cannot be verified and directly underpins the assertion that language predictions can be treated as unbiased stochastic observations.
Authors: We acknowledge that the abstract does not define the calibration metric. Section 4.3 of the manuscript specifies the procedure via expected calibration error (ECE) together with reliability diagrams and binning details. We will revise the abstract to include a concise qualifier (e.g., "whose covariance estimates remain calibrated (low ECE, Section 4.3)") so that the claim is traceable to the reported methodology. revision: yes
Circularity Check
No significant circularity
full rationale
The paper trains LSM on data to produce multimodal distributions from language and scene graphs, then fuses them probabilistically into VL-Map with onboard perception; claims rest on held-out evaluation on VLA-3D and real-robot experiments showing calibration and improved localization versus baselines. No equations, self-citations, or derivations are shown that reduce any prediction or uniqueness claim to a fitted input or prior author result by construction. The pipeline is self-contained against external benchmarks with no load-bearing self-referential steps visible.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
C. E. Peacock and A. D. Ekstrom. Verbal cues flexibly transform spatial representations in human memory.Memory, 27(4):465–479, 2019
2019
-
[2]
E. Munnich, B. Landau, and B. A. Dosher. Spatial language and spatial representa- tion: a cross-linguistic comparison.Cognition, 81(3):171–208, 2001. ISSN 0010-0277. doi:https://doi.org/10.1016/S0010-0277(01)00127-5. URLhttps://www.sciencedirect. com/science/article/pii/S0010027701001275
-
[3]
L. Hermer-Vazquez, E. S. Spelke, and A. S. Katsnelson. Sources of flexibility in hu- man cognition: Dual-task studies of space and language.Cognitive Psychology, 39(1):3– 36, 1999. ISSN 0010-0285. doi:https://doi.org/10.1006/cogp.1998.0713. URLhttps: //www.sciencedirect.com/science/article/pii/S0010028598907137
-
[4]
Rosinol, M
A. Rosinol, M. Abate, Y . Chang, and L. Carlone. Kimera: an open-source library for real- time metric-semantic localization and mapping. In2020 IEEE International Conference on Robotics and Automation, ICRA 2020, Paris, France, May 31 - August 31, 2020, pages 1689–
2020
-
[5]
doi:10.1109/ICRA40945.2020.9196885
IEEE, 2020. doi:10.1109/ICRA40945.2020.9196885. URLhttps://doi.org/10. 1109/ICRA40945.2020.9196885
-
[6]
N. Hughes, Y . Chang, S. Hu, R. Talak, R. Abdulhai, J. Strader, and L. Carlone. Foundations of spatial perception for robotics: Hierarchical representations and real-time systems.The International Journal of Robotics Research, 2024. doi:10.1177/02783649241229725. URL https://doi.org/10.1177/02783649241229725
-
[7]
S. L. Bowman, N. Atanasov, K. Daniilidis, and G. J. Pappas. Probabilistic data association for semantic SLAM. In2017 IEEE International Conference on Robotics and Automation, ICRA 2017, Singapore, Singapore, May 29 - June 3, 2017, pages 1722–1729. IEEE, 2017. doi: 10.1109/ICRA.2017.7989203. URLhttps://doi.org/10.1109/ICRA.2017.7989203
-
[8]
Z. Zhu, X. Ma, Y . Chen, Z. Deng, S. Huang, and Q. Li. 3d-vista: Pre-trained transformer for 3d vision and text alignment. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 2899–2909. IEEE, 2023. doi:10.1109/ ICCV51070.2023.00272. URLhttps://doi.org/10.1109/ICCV51070.2023.00272
-
[9]
Y . Hong, H. Zhen, P. Chen, S. Zheng, Y . Du, Z. Chen, and C. Gan. 3d- llm: Injecting the 3d world into large language models. In A. Oh, T. Nau- mann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Neural Informa- tion Processing Systems 2023, NeurIPS 2023, New Orleans, ...
2023
-
[10]
D. Z. Chen, A. X. Chang, and M. Nießner. Scanrefer: 3d object localization in RGB- D scans using natural language. In A. Vedaldi, H. Bischof, T. Brox, and J. Frahm, ed- itors,Computer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part XX, Lecture Notes in Computer Science, pages 202–221. Springer, 2020. doi:1...
-
[11]
A ConvNet for the 2020s , booktitle =
S. Huang, Y . Chen, J. Jia, and L. Wang. Multi-view transformer for 3d visual ground- ing. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 15503–15512. IEEE, 2022. doi:10.1109/ CVPR52688.2022.01508. URLhttps://doi.org/10.1109/CVPR52688.2022.01508. 9
-
[12]
J. Deng, T. He, L. Jiang, T. Wang, F. Dayoub, and I. D. Reid. 3d-llava: Towards generalist 3d lmms with omni superpoint transformer. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 3772–
2025
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition
Computer Vision Foundation / IEEE, 2025. doi:10.1109/CVPR52734.2025.00357. URLhttps://openaccess.thecvf.com/content/CVPR2025/html/Deng_3D-LLaVA_ Towards_Generalist_3D_LMMs_with_Omni_Superpoint_Transformer_CVPR_2025_ paper.html
-
[14]
B. Jia, Y . Chen, H. Yu, Y . Wang, X. Niu, T. Liu, Q. Li, and S. Huang. Sceneverse: Scal- ing 3d vision-language learning for grounded scene understanding. In A. Leonardis, E. Ricci, S. Roth, O. Russakovsky, T. Sattler, and G. Varol, editors,Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Pa...
-
[15]
Conditional convolutions for instance segmentation,
P. Achlioptas, A. Abdelreheem, F. Xia, M. Elhoseiny, and L. J. Guibas. Referit3d: Neu- ral listeners for fine-grained 3d object identification in real-world scenes. In A. Vedaldi, H. Bischof, T. Brox, and J. Frahm, editors,Computer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part I, Lecture Notes in Com- pu...
-
[16]
Language Models (Mostly) Know What They Know
S. Kadavath, T. Conerly, A. Askell, T. Henighan, D. Drain, E. Perez, N. Schiefer, Z. Hatfield- Dodds, N. DasSarma, E. Tran-Johnson, S. Johnston, S. E. Showk, A. Jones, N. Elhage, T. Hume, A. Chen, Y . Bai, S. Bowman, S. Fort, D. Ganguli, D. Hernandez, J. Jacobson, J. Kernion, S. Kravec, L. Lovitt, K. Ndousse, C. Olsson, S. Ringer, D. Amodei, T. Brown, J. ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2022
-
[17]
Xiong, Z
M. Xiong, Z. Hu, X. Lu, Y . Li, J. Fu, J. He, and B. Hooi. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net,
2024
-
[18]
URLhttps://openreview.net/forum?id=gjeQKFxFpZ
-
[19]
Kumar, C
B. Kumar, C. Lu, G. Gupta, A. Palepu, D. Bellamy, R. Raskar, and A. Beam. Conformal pre- diction with large language models for multi-choice question answering. InICML Workshop on Neural Conversational AI, 2023
2023
-
[20]
Mohri and T
C. Mohri and T. Hashimoto. Language models with conformal factuality guarantees. In R. Salakhutdinov, Z. Kolter, K. A. Heller, A. Weller, N. Oliver, J. Scarlett, and F. Berkenkamp, editors,Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, Proceedings of Machine Learning Research, pages 36029– 36047. PM...
2024
-
[21]
M. R. Walter, S. Patki, A. F. Daniele, E. Fahnestock, F. Duvallet, S. Hemachandra, J. Oh, A. Stentz, N. Roy, and T. M. Howard. Language understanding for field and service robots in a priori unknown environments.Field Robotics, 2(1):1191–1231, 2022. doi:10.55417/FR. 2022040. URLhttps://doi.org/10.55417/fr.2022040
work page doi:10.55417/fr 2022
-
[22]
D. Kim, N. Oh, D. Hwang, and D. Park. Lingo-space: Language-conditioned incremen- tal grounding for space. In M. J. Wooldridge, J. G. Dy, and S. Natarajan, editors,Thirty- Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Ed- ucati...
-
[23]
J. A. Nader, D. Lee, N. Dennler, and A. Bobu. Quicklap: Quick language-action preference learning for semi-autonomous agents, 2026. URLhttps://arxiv.org/abs/2511.17855
Pith/arXiv arXiv 2026
-
[24]
H. Zhang, N. Zantout, P. Kachana, J. Zhang, and W. Wang. Iref-vla: A benchmark for interactive referential grounding with imperfect language in 3d scenes. InIEEE Interna- tional Conference on Robotics and Automation, ICRA 2025, Atlanta, GA, USA, May 19- 23, 2025, pages 1677–1683. IEEE, 2025. doi:10.1109/ICRA55743.2025.11127464. URL https://doi.org/10.1109...
-
[25]
A. X. Chang, A. Dai, T. A. Funkhouser, M. Halber, M. Nießner, M. Savva, S. Song, A. Zeng, and Y . Zhang. Matterport3d: Learning from RGB-D data in indoor environments. In2017 International Conference on 3D Vision, 3DV 2017, Qingdao, China, October 10-12, 2017, pages 667–676. IEEE Computer Society, 2017. doi:10.1109/3DV .2017.00081. URLhttps: //doi.org/10....
work page doi:10.1109/3dv 2017
-
[26]
A. Dai, A. X. Chang, M. Savva, M. Halber, T. A. Funkhouser, and M. Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, pages 2432–2443. IEEE Computer Society, 2017. doi:10.1109/CVPR.2017.261. URLhttps:// doi.org/10.1109/CV...
-
[27]
there is a <target object> <relation> <existing object(s)>
A. Dehghan, G. Baruch, Z. Chen, Y . Feigin, P. Fu, T. Gebauer, D. Kurz, T. Dimry, B. Joffe, A. Schwartz, and E. Shulman. Arkitscenes: A diverse real-world dataset for 3d indoor scene understanding using mobile RGB-D data. In J. Vanschoren and S. Yeung, editors,Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, Neu...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.