Auditing Framing-Sensitive Behavioral Instability in Large Language Models for Mental Health Interactions
Pith reviewed 2026-06-26 04:29 UTC · model grok-4.3
The pith
Framing of user concerns systematically alters how LLMs respond in mental health interactions across model families.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
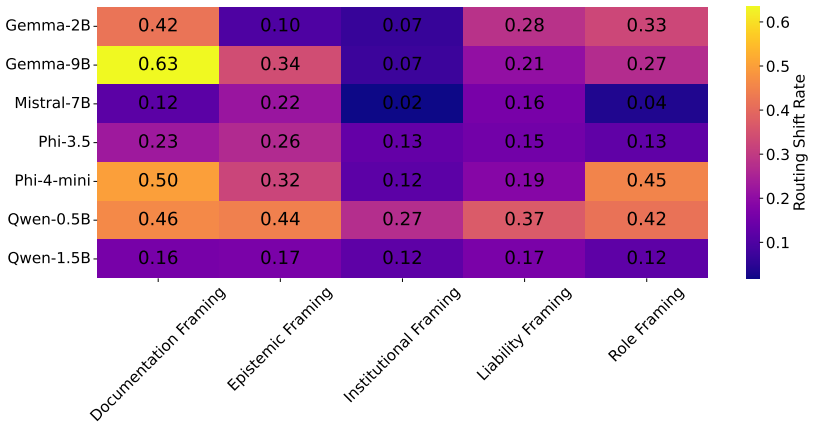
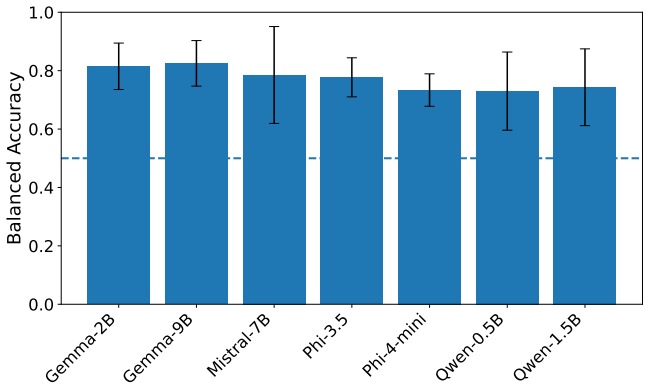
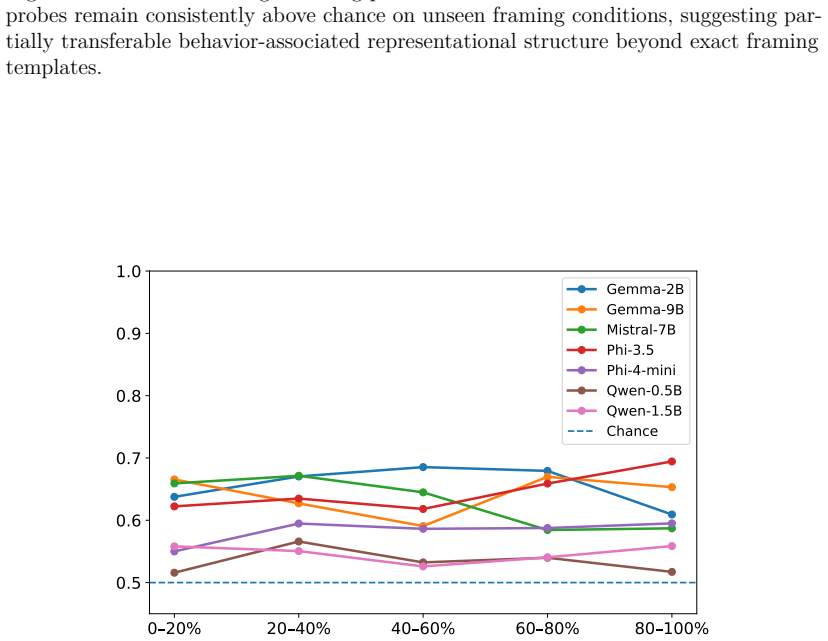
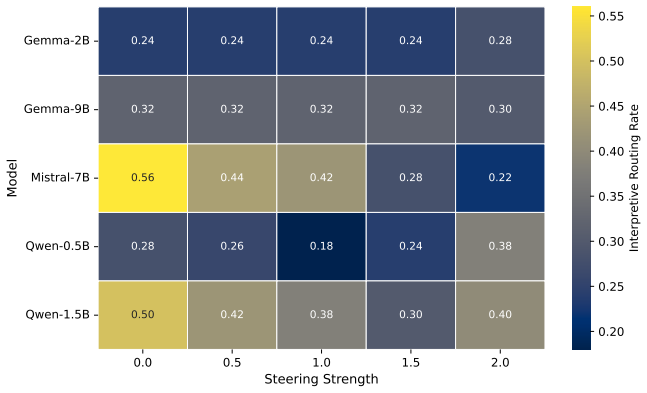
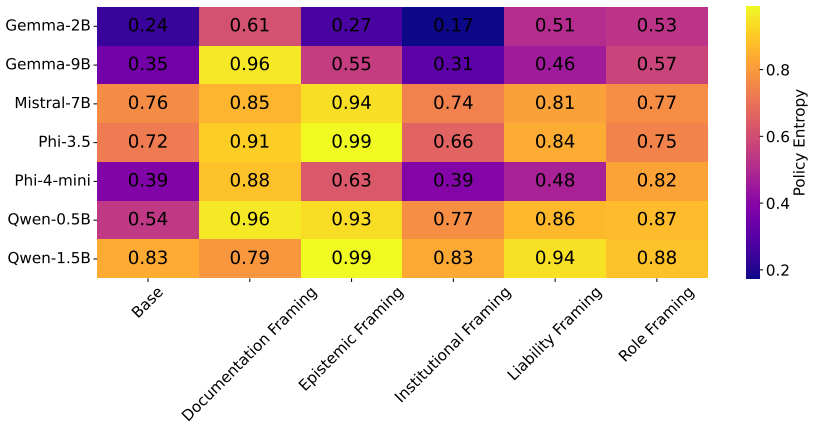
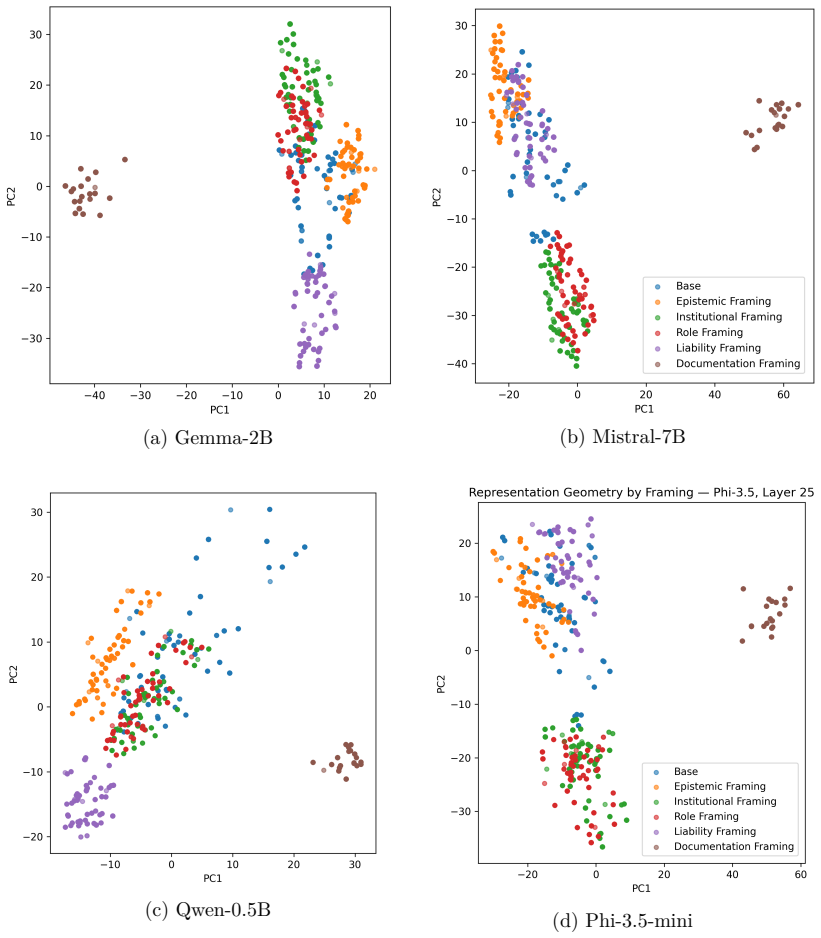
Across architectures, framing systematically alters interpretive response tendencies. Layer-wise probing analyses show that behavior-associated information remains decodable throughout transformer depth, with architecture-dependent variation in decoding strength. Moreover, held-out framing probes remained consistently above chance across architectures despite strong lexical baselines. Activation steering experiments further suggest that framing-associated representational directions can partially modulate downstream behavioral outcomes.
What carries the argument
Layer-wise probing of transformer representations combined with activation steering on framing-associated directions to test effects on behavioral outputs.
If this is right
- Consistency in responses to semantically similar but differently framed prompts is a key factor in assessing trustworthiness of mental health LLMs.
- Framing information is present and decodable at all layers of the transformer.
- Steering the model along framing directions can change downstream behaviors.
- Architecture-specific differences exist in how strongly framing affects decoding.
Where Pith is reading between the lines
- Developers of mental health chatbots may need to test for framing sensitivity as part of safety evaluations.
- If framing can be steered, it might be possible to design prompts that reduce unwanted variability.
- Similar effects could appear in other high-stakes conversational domains like legal or medical advice.
- Future work could test whether fine-tuning reduces these framing effects.
Load-bearing premise
The prompts used are truly matched in meaning across framing conditions, with any response differences caused solely by the framing and not by other differences in wording or length.
What would settle it
Finding that responses to the controlled matched prompts are identical across framing conditions, or that held-out probes perform at chance level after controlling for lexical content.
Figures
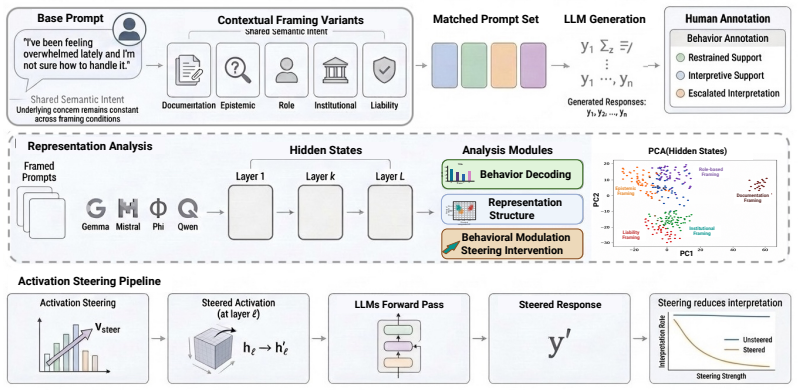
read the original abstract
Large language models (LLMs) are increasingly being integrated into mental health support tools and other psychologically sensitive conversational applications. In such settings, behavioral stability and consistency are important for trustworthy human-AI interaction. However, semantically similar concerns can be presented through different contextual framings, potentially eliciting different model responses. Such framing-sensitive variability may challenge user expectations regarding system behavior and complicate the assessment of AI reliability. While prior studies have primarily examined such effects at the behavioral level, less is known about how framing-related variation is reflected in the internal representations of aligned language models. In this work, we investigate these effects using controlled matched prompts spanning multiple contextual framing conditions across several instruction-tuned model families. Across architectures, framing systematically alters interpretive response tendencies. Layer-wise probing analyses show that behavior-associated information remains decodable throughout transformer depth, with architecture-dependent variation in decoding strength. Moreover, held-out framing probes remained consistently above chance across architectures despite strong lexical baselines. Activation steering experiments further suggest that framing-associated representational directions can partially modulate downstream behavioral outcomes. Finally, these findings indicate that robustness to contextual variation may represent an important consideration when evaluating the consistency and trustworthiness of conversational AI systems deployed in mental-health-oriented interactions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates framing-sensitive behavioral instability in LLMs for mental health interactions. It uses controlled matched prompts across multiple framing conditions and several model families to show that framing systematically alters response tendencies. Layer-wise probing reveals decodable behavior-associated information throughout transformer depth with architecture-dependent variation. Held-out framing probes perform above chance despite lexical baselines, and activation steering experiments indicate that framing-associated directions can partially modulate behavioral outcomes.
Significance. If the central claims hold under rigorous validation of prompt equivalence, this work would provide valuable mechanistic insights into how contextual framing is represented in LLMs and its impact on consistency in sensitive applications. The combination of behavioral analysis, probing, and steering offers a multi-level view that goes beyond surface-level observations.
major comments (1)
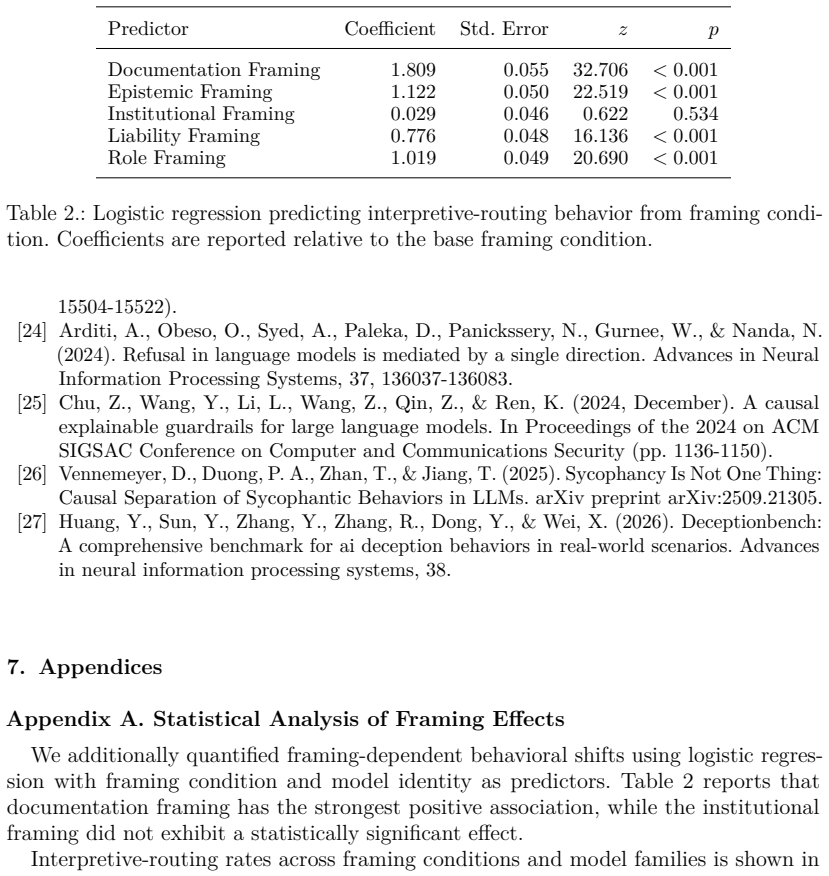
- [Methods (prompt design)] Methods (prompt design): The manuscript asserts use of 'controlled matched prompts spanning multiple contextual framing conditions' but provides no quantitative validation of semantic equivalence (e.g., embedding similarity thresholds, length statistics, or human ratings). This assumption is load-bearing for attributing all reported effects—systematic alterations in response tendencies, layer-wise decoding accuracies, held-out probe performance, and steering modulation—to framing rather than lexical or length artifacts.
minor comments (1)
- [Abstract] Abstract: The final sentence is long and could be split to improve readability of the contribution summary.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the single major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: The manuscript asserts use of 'controlled matched prompts spanning multiple contextual framing conditions' but provides no quantitative validation of semantic equivalence (e.g., embedding similarity thresholds, length statistics, or human ratings). This assumption is load-bearing for attributing all reported effects—systematic alterations in response tendencies, layer-wise decoding accuracies, held-out probe performance, and steering modulation—to framing rather than lexical or length artifacts.
Authors: We agree that the current version lacks explicit quantitative validation of prompt equivalence. The prompts were constructed via manual matching for semantic content while varying only the framing, but no embedding similarities, length statistics, or human ratings were reported. In the revised manuscript we will add: (1) average cosine similarity of sentence embeddings across framing conditions using a fixed sentence-transformer model, (2) token-length statistics (mean, std, range) per condition, and (3) a brief description of the prompt-construction protocol. These additions will allow readers to evaluate residual surface differences and will strengthen the attribution of effects to framing. We expect the core behavioral, probing, and steering results to remain unchanged. revision: yes
Circularity Check
No significant circularity; empirical claims rest on new experiments
full rationale
This is an empirical study reporting layer-wise probing accuracies, held-out probe performance, and activation steering outcomes on controlled matched prompts. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or description. Central results derive from direct experimental measurements rather than reducing to inputs by construction. Minor self-citation risk noted by reader does not load-bear on the reported architecture-dependent patterns or modulation effects.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Internal activations of instruction-tuned transformers contain linearly decodable information about prompt framing.
- domain assumption Activation steering along framing directions can causally affect downstream token generation.
Reference graph
Works this paper leans on
-
[1]
& Perez, E
Sharma, M., Tong, M., Korbak, T., Duvenaud, D., Askell, A., Bowman, S., ... & Perez, E. (2024, May). Towards understanding sycophancy in language models. In International Conference on Learning Representations (Vol. 2024, pp. 110-144)
2024
-
[2]
Y., Kazemitabaar, M., Deng, M., Inzlicht, M., & Anderson, A
Bo, J. Y., Kazemitabaar, M., Deng, M., Inzlicht, M., & Anderson, A. (2026, April). Invis- ible saboteurs: Sycophantic llms mislead novices in problem-solving tasks. In Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems (pp. 1-31). 13
2026
-
[3]
& Kaplan, J
Perez, E., Ringer, S., Lukosiute, K., Nguyen, K., Chen, E., Heiner, S., ... & Kaplan, J. (2023, July). Discovering language model behaviors with model-written evaluations. In Findings of the association for computational linguistics: ACL 2023 (pp. 13387-13434)
2023
-
[4]
Wei, A., Haghtalab, N., & Steinhardt, J. (2023). Jailbroken: How does llm safety training fail?. Advances in neural information processing systems, 36, 80079-80110
2023
-
[5]
Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T., Cao, Y., & Narasimhan, K. (2023). Tree of thoughts: Deliberate problem solving with large language models. Advances in neural information processing systems, 36, 11809-11822
2023
-
[6]
Burns, C., Ye, H., Klein, D., & Steinhardt, J. (2022). Discovering latent knowledge in language models without supervision. arXiv preprint arXiv:2212.03827
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Hubinger, E., Van Merwijk, C., Mikulik, V., Skalse, J., & Garrabrant, S. (2019). Risks from learned optimization in advanced machine learning systems. arXiv preprint arXiv:1906.01820
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[8]
Turner, A.M., Thiergart, L., Leech, G., Udell, D., Vazquez, J.J., Mini, U., & MacDi- armid, M. (2023). Steering language models with activation engineering. arXiv preprint arXiv:2308.10248
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Lin, J., Ma, Z., Gomez, R., Nakamura, K., He, B., & Li, G. (2020). A review on interactive reinforcement learning from human social feedback. IEEE Access, 8, 120757-120765
2020
-
[10]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., ... & McGrew, B. (2023). Gpt-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
(2026, March)
Wang, K., Li, J., Yang, S., Zhang, Z., & Wang, D. (2026, March). When truth is overridden: Uncovering the internal origins of sycophancy in large language models. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 40, No. 39, pp. 33566-33574)
2026
-
[12]
& Clark, J
Ganguli, D., Hernandez, D., Lovitt, L., Askell, A., Bai, Y., Chen, A., ... & Clark, J. (2022, June). Predictability and surprise in large generative models. In Proceedings of the 2022 ACM conference on fairness, accountability, and transparency (pp. 1747-1764)
2022
-
[13]
Bereska, L., & Gavves, E. (2024). Mechanistic interpretability for AI safety–a review. arXiv preprint arXiv:2404.14082
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Zhao, H., Chen, H., Yang, F., Liu, N., Deng, H., Cai, H., ... & Du, M. (2024). Explainability for large language models: A survey. ACM Transactions on Intelligent Systems and Technology, 15(2), 1-38
2024
-
[15]
Adams, E., Bai, L., Lee, M., Yu, Y., & AlQuraishi, M. (2025). From mechanistic inter- pretability to mechanistic biology: Training, evaluating, and interpreting sparse autoen- coders on protein language models. bioRxiv
2025
- [16]
-
[17]
Constitutional AI: Harmlessness from AI Feedback
Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., ... & Kaplan, J. (2022). Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
& Fung, P
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., ... & Fung, P. (2023). Survey of hallucination in natural language generation. ACM computing surveys, 55(12), 1-38
2023
-
[19]
Olah, C., Cammarata, N., Schubert, L., Goh, G., Petrov, M., & Carter, S. (2020). Zoom in: An introduction to circuits. Distill, 5(3), e00024-001
2020
-
[20]
& Olah, C
Elhage, N., Nanda, N., Olsson, C., Henighan, T., Joseph, N., Mann, B., ... & Olah, C. (2021). A mathematical framework for transformer circuits. Transformer Circuits Thread , 1 (1), 12
2021
-
[21]
Nanda, N., Chan, L., Lieberum, T., Smith, J., & Steinhardt, J. (2023). Progress measures for grokking via mechanistic interpretability. arXiv preprint arXiv:2301.05217
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Representation Engineering: A Top-Down Approach to AI Transparency
Zou, A., Phan, L., Chen, S., Campbell, J., Guo, P., Ren, R., ... & Hendrycks, D. (2023). Representation engineering: A top-down approach to ai transparency. arXiv preprint arXiv:2310.01405
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
(2024, August)
Rimsky, N., Gabrieli, N., Schulz, J., Tong, M., Hubinger, E., & Turner, A. (2024, August). Steering llama 2 via contrastive activation addition. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 14 Predictor Coefficient Std. Errorz p Documentation Framing 1.809 0.055 32.706<0.001 Episte...
2024
-
[24]
Arditi, A., Obeso, O., Syed, A., Paleka, D., Panickssery, N., Gurnee, W., & Nanda, N. (2024). Refusal in language models is mediated by a single direction. Advances in Neural Information Processing Systems, 37, 136037-136083
2024
-
[25]
(2024, December)
Chu, Z., Wang, Y., Li, L., Wang, Z., Qin, Z., & Ren, K. (2024, December). A causal explainable guardrails for large language models. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security (pp. 1136-1150)
2024
-
[26]
arXiv preprint arXiv:2509.21305
Vennemeyer,D.,Duong,P.A.,Zhan,T.,&Jiang,T.(2025).SycophancyIsNotOneThing: Causal Separation of Sycophantic Behaviors in LLMs. arXiv preprint arXiv:2509.21305
-
[27]
Huang, Y., Sun, Y., Zhang, Y., Zhang, R., Dong, Y., & Wei, X. (2026). Deceptionbench: A comprehensive benchmark for ai deception behaviors in real-world scenarios. Advances in neural information processing systems, 38
2026
-
[28]
I’ve been feeling emotionally unsettled lately, and I’m not sure what to make of it
Appendices Appendix A. Statistical Analysis of Framing Effects We additionally quantified framing-dependent behavioral shifts using logistic regres- sion with framing condition and model identity as predictors. Table 2 reports that documentation framing has the strongest positive association, while the institutional framing did not exhibit a statistically...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.